
一、什麼是工作流? 在闡述什麼是工作流之前,先說一下工作流和普通任務的區別,在於依賴視圖。 普通任務本身他只會有自己的dag圖,依賴視圖是無邊界的,不可控的,而工作流則是把整個工作流都展示出來,是有邊界的,可控的,這是工作流的優勢。下麵為大家介紹工作流的相關功能: 01 工作流—功能介紹 ● 虛擬節 ...
一、什麼是工作流?
在闡述什麼是工作流之前,先說一下工作流和普通任務的區別,在於依賴視圖。
普通任務本身他只會有自己的dag圖,依賴視圖是無邊界的,不可控的,而工作流則是把整個工作流都展示出來,是有邊界的,可控的,這是工作流的優勢。下麵為大家介紹工作流的相關功能:
01 工作流—功能介紹
● 虛擬節點
虛擬節點,它是不產生任何數據的空跑節點(即調度到該節點時,系統直接返回成功,不會真正執行、不會占用資源或阻塞下游節點運行),比如說任務並行執行,那麼就會用到虛擬節點。
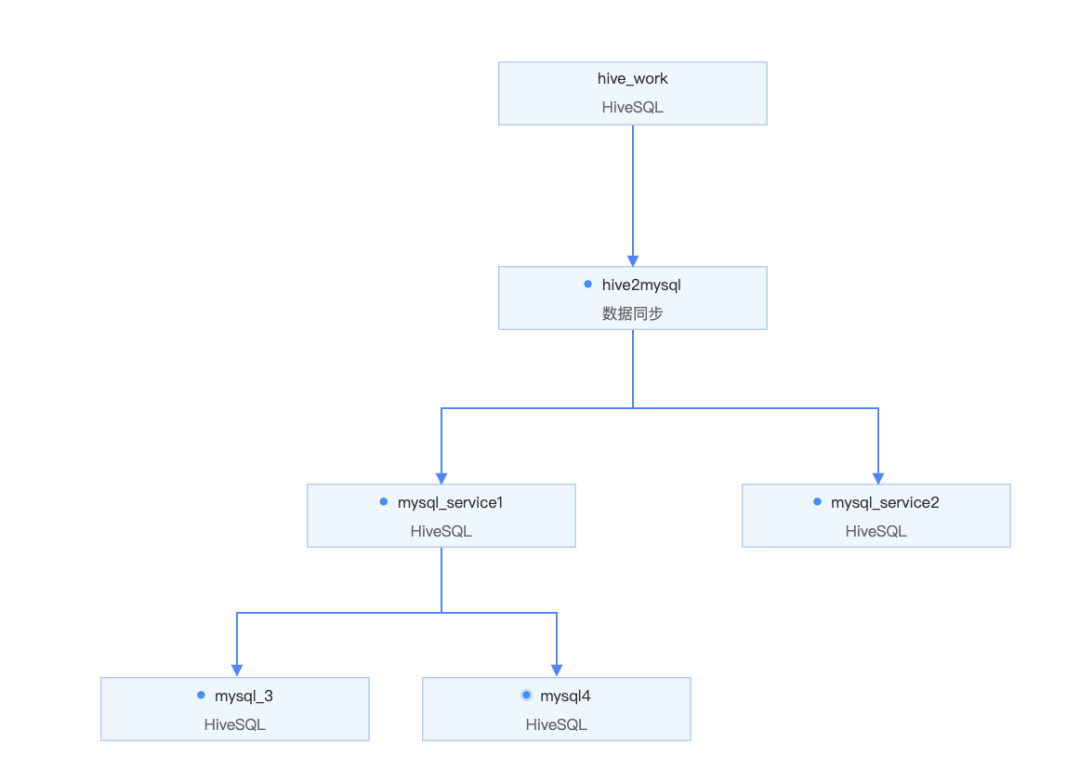
● 周期生成
指調度系統按照調度配置自動定時運行的任務。
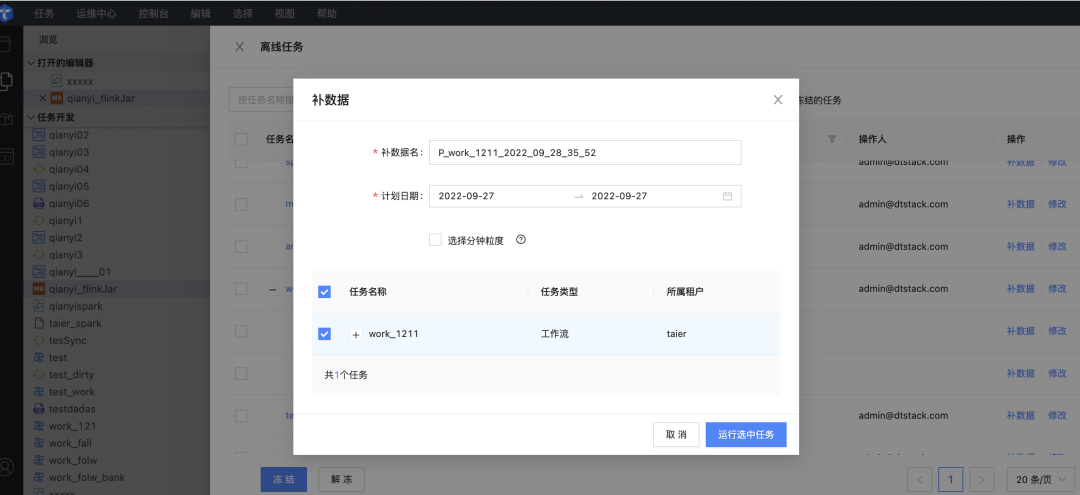
● 補數據運行
當業務變更,可以使用補數據功能。如修改了某個任務的代碼,可將本月的數據按照新的代碼重新跑一遍,立即生成所需數據。
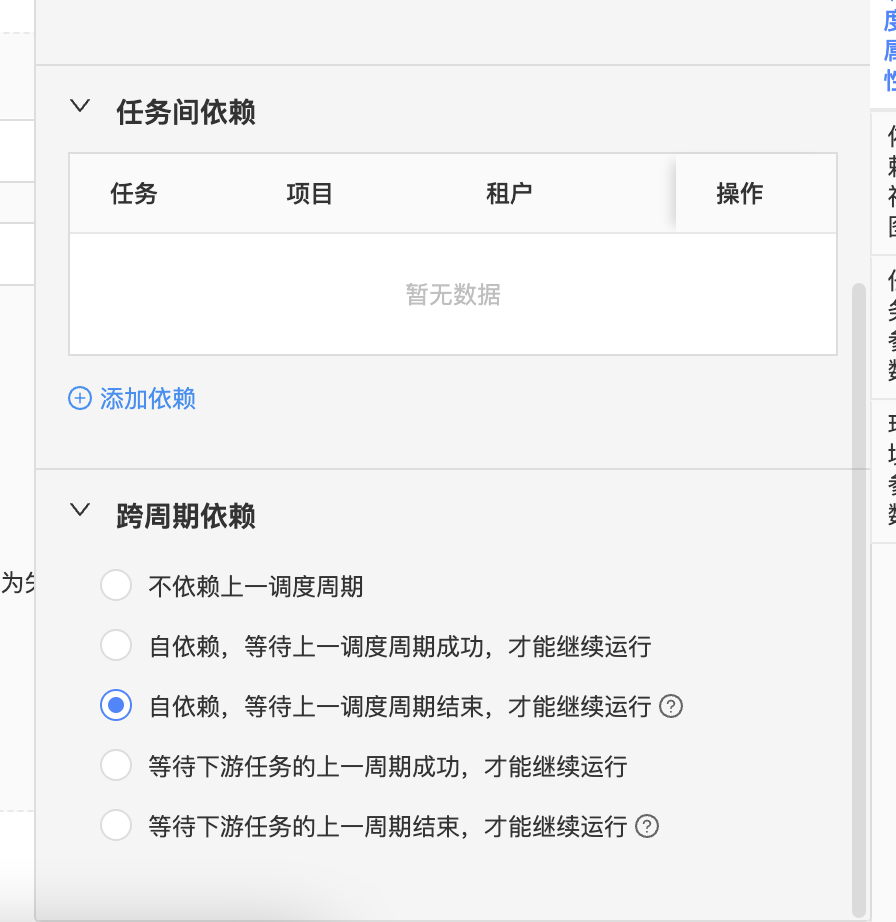
● 調度屬性
工作流中的子任務依賴於父任務的周期調度屬性,父任務修改後,子任務同步修改,以工作流的周期調度屬性作為各個子節點的周期調度時間。
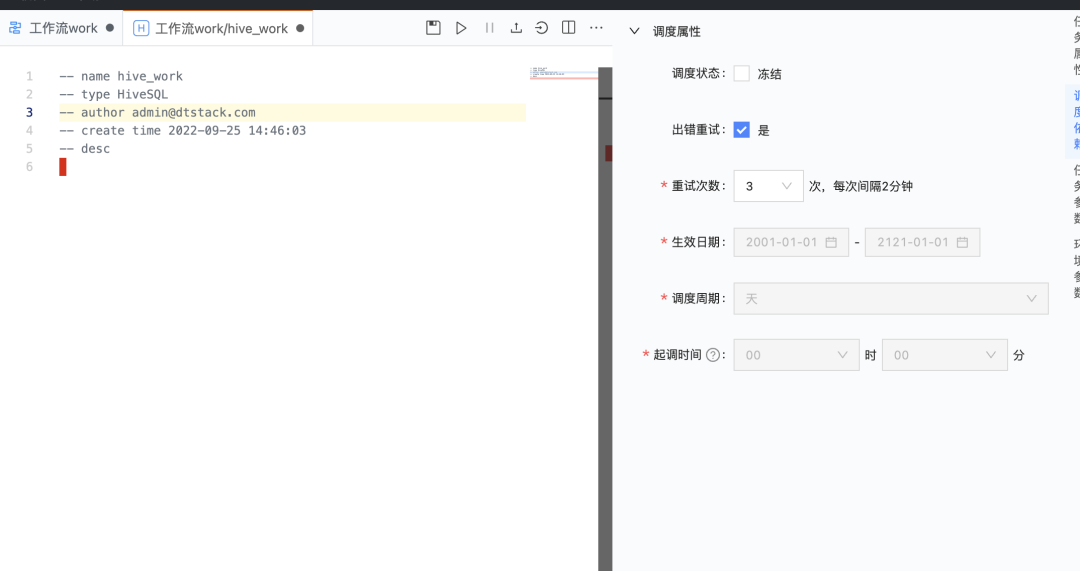
● 工作流所在目錄
修改工作流目錄同步修改工作流下的子任務目錄。
02 工作流—依賴成環
具體實現:
任務完成依賴的關係,key為當前節點,value為該節點的所有父節點Map < long list> nodeMap。
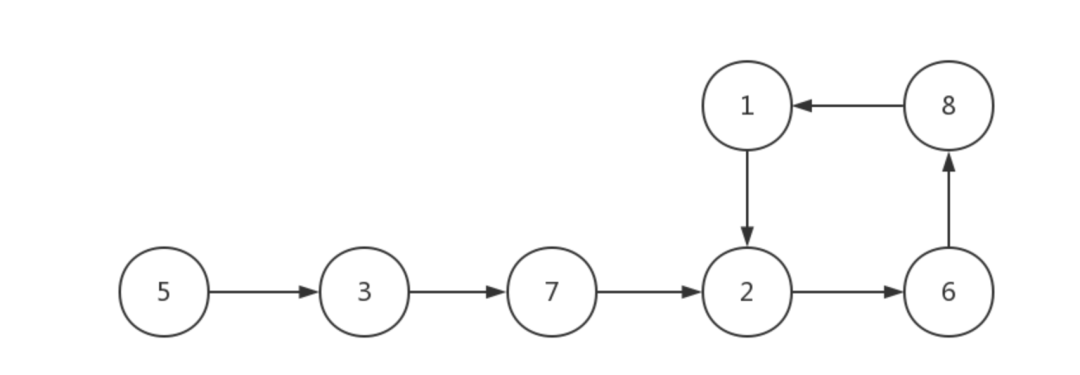
遍歷nodeMap,以此遍歷單集合中的每一個節點。每遍歷一個新節點,就從頭檢查新節點之前的所有節點,用新節點和此節點之前所有節點依次做比較。如果發現新節點和之前的某個節點相同,則說明該節點被遍歷過兩次,鏈表有環。如果之前的所有節點中不存在與新節點相同的節點,就繼續遍歷下一個新節點,繼續重覆剛纔的操作。
二、Taier工作流周期實例運行
瞭解完工作流的功能介紹後,我們來為大家分享Taier工作流周期實例運行:
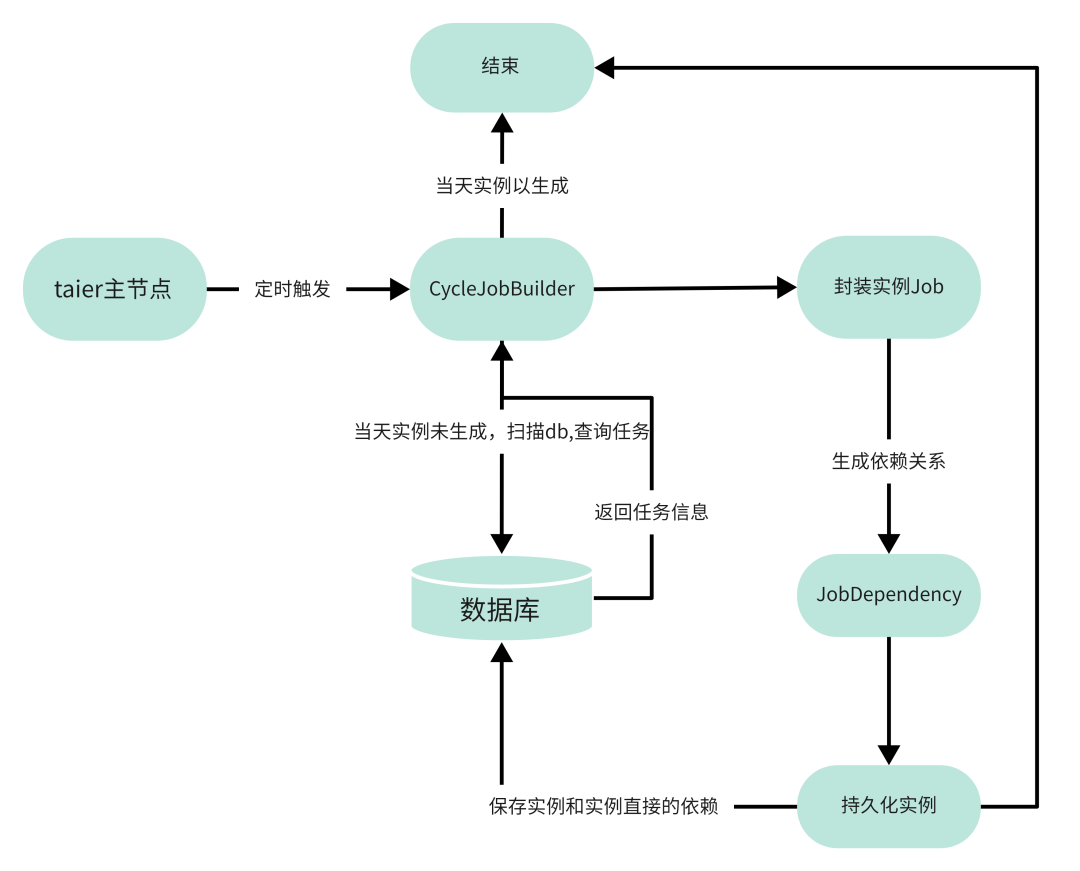
01 Taier—周期實例生成
Taier主節點在啟動的時候,會開啟一個定時器,定時器會不停的去判斷當日的實例是否已經生成。如果沒有生成,就會觸發事件給CycleJobBuilder生成實例,再通過JobDependency封裝實例之間的依賴關係。
● CycleJobBuilder
用於生成周期實例。掃描資料庫任務表並且獲取zk上所有的Taier節點,把封裝後的實例分配到每一臺Taier節點上。
● JobDependency
用於生成job之間的依賴關係。
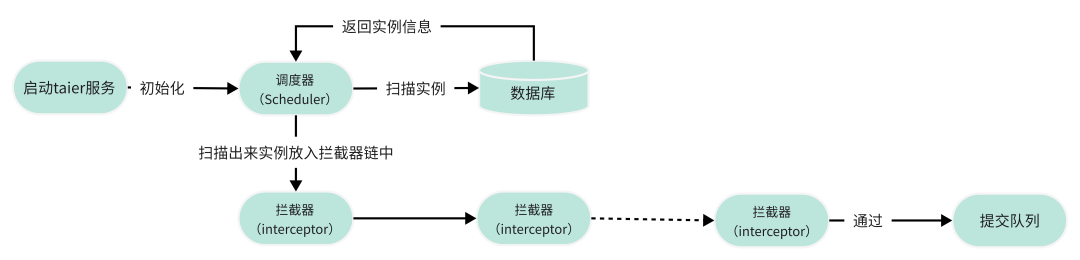
02 Taier—調度流程
在啟動Taier服務時,會啟動配置的所有調度器,並且開始掃描實例,並提交。
03 Taier—工作流任務狀態修改邏輯
任務提交攔截器處理:
1、工作流下無子任務更新為完成狀態
2、工作流下任務都是完成狀態,任務提交隊列可以移除
3、同時更新工作流engine_job狀態,工作流只有四種狀態,成功/失敗/取消/提交中:
(1) 所有子任務狀態為運行成功時,工作流狀態更新為成功
(2) 工作流狀態根據子任務的運行狀態來確定,失敗狀態存在優先順序:運行失敗>提交失敗>上游失敗
a.子任務存在運行失敗時,工作流狀態更新為運行失敗
b.子任務不存在運行失敗時,存在提交失敗,工作流狀態更新為提交失敗
c.子任務不存在運行失敗時,不存在提交失敗,存在上游失敗時,工作流狀態更新為上游失敗
(3) 子任務存在取消狀態時,工作流狀態更新為取消
(4) 若子任務中同時存在運行失敗或取消狀態,工作流狀態更新為失敗狀態
(5) 其他工作流更新為運行中狀態
三、Taier1.3即將上線功能
新增功能
· ChunJun的嚮導模式數據源增強 hive1、hive2、hive3、sparkThrift、oracle、mysql、postgresql、sqlserver 、es7
· flink on standalone、python.shell、spark jar 、pyspark支持
· 自定義任務類型 web界面配置抽取
· windows開發環境適配
袋鼠雲開源框架釘釘技術交流qun(30537511),歡迎對大數據開源項目有興趣的同學加入交流最新技術信息,開源項目庫地址:https://github.com/DTStack/Taier


