
科技報告語料處理 接著上次爬取到的科技報告數據進行處理【參考 https://www.cnblogs.com/rainbow-1/p/16725576.html】 為了建立科技報告的分類模型,現將其關鍵字和中圖分類名稱進行彙總,作為原始語料庫。 先前爬取的數據,存在數據格式不統一不規範的問題,比如分 ...
科技報告語料處理
接著上次爬取到的科技報告數據進行處理【參考 https://www.cnblogs.com/rainbow-1/p/16725576.html】
為了建立科技報告的分類模型,現將其關鍵字和中圖分類名稱進行彙總,作為原始語料庫。
先前爬取的數據,存在數據格式不統一不規範的問題,比如分類名稱為【數理科學與化學、數理科學和化學 分為了同一類】
經過簡單處理後的完整數據(mysql和txt都有,包括本文中提到的原始語料資源)可以關註我的公眾號【靠譜楊的挨踢生活】回覆【科技報告】獲取。
語料共計 359141 行。
1、標準表
分類字母序號+名稱 tech_class.json
{
"R": "醫葯、衛生",
"TB": "一般工業技術",
"Q": "生物科學",
"O": "數理科學和化學",
"S": "農業科學",
"T": "工業技術",
"TP": "自動化技術、電腦技術",
"P": "天文學、地球科學",
"TN": "無線電電子學、電信技術",
"TG": "金屬學與金屬工藝",
"TH": "機械、儀錶工業",
"TQ": "化學工業",
"C": "社會科學總論",
"X": "環境科學、安全科學",
"TU": "建築科學",
"TS": "輕工業、手工業",
"TK": "能源與動力工程",
"TM": "電工技術",
"TD": "礦業工程",
"F": "經濟",
"G": "文化、科學、教育、體育",
"TV": "水利工程",
"U": "交通運輸",
"N": "自然科學總論",
"TE": "石油、天然氣工業",
"TF": "冶金工業",
"TJ": "武器工業",
"V": "航空、航天",
"B": "哲學、宗教",
"TL": "原子能技術",
"K": "歷史、地理",
"D": "政治、法律",
"J": "藝術",
"H": "語言、文字",
"E": "軍事",
"Z": "綜合性圖書",
"I": "文學",
"A": "mks主義、ln主義、mzd思想、dxp理論"
}
僅分類名稱 tech_name.txt
醫葯、衛生
一般工業技術
生物科學
數理科學和化學
農業科學
工業技術
自動化技術、電腦技術
天文學、地球科學
無線電電子學、電信技術
金屬學與金屬工藝
機械、儀錶工業
化學工業
社會科學總論
環境科學、安全科學
建築科學
輕工業、手工業
能源與動力工程
電工技術
礦業工程
經濟
文化、科學、教育、體育
水利工程
交通運輸
自然科學總論
石油、天然氣工業
冶金工業
武器工業
航空、航天
哲學、宗教
原子能技術
歷史、地理
政治、法律
藝術
語言、文字
軍事
綜合性圖書
文學
mks主義、ln主義、mzd思想、dxp理論
分類名稱+語料數字序號 tech_order_class.json
{
"醫葯、衛生": "0",
"一般工業技術": "1",
"生物科學": "2",
"數理科學和化學": "3",
"農業科學": "4",
"工業技術": "5",
"自動化技術、電腦技術": "6",
"天文學、地球科學": "7",
"無線電電子學、電信技術": "8",
"金屬學與金屬工藝": "9",
"機械、儀錶工業": "10",
"化學工業": "11",
"社會科學總論": "12",
"環境科學、安全科學": "13",
"建築科學": "14",
"輕工業、手工業": "15",
"能源與動力工程": "16",
"電工技術": "17",
"礦業工程": "18",
"經濟": "19",
"文化、科學、教育、體育": "20",
"水利工程": "21",
"交通運輸": "22",
"自然科學總論": "23",
"石油、天然氣工業": "24",
"冶金工業": "25",
"武器工業": "26",
"航空、航天": "27",
"哲學、宗教": "28",
"原子能技術": "29",
"歷史、地理": "30",
"政治、法律": "31",
"藝術": "32",
"語言、文字": "33",
"軍事": "34",
"綜合性圖書": "35",
"文學": "36",
"mks主義、ln主義、mzd思想、dxp理論": "37"
}
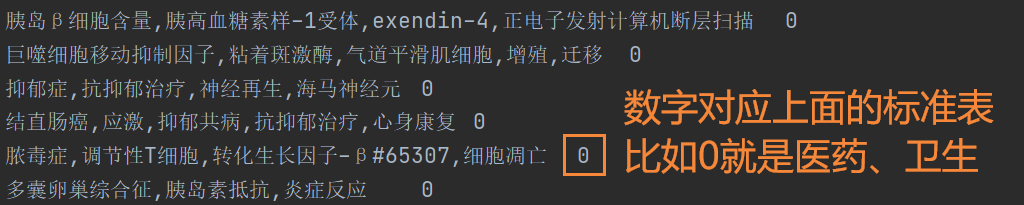
基本思路,提取各個分類報告中的【關鍵詞和中圖分類名稱】。用 \t 分隔 關鍵詞和名稱,關鍵詞中間用英文逗號分隔。
實現效果如圖:【序號是從0開始的 0 ---> 醫葯、衛生】
2、代碼
2.1、data_clean.py
提取關鍵詞和名稱,保存到tech_all.txt文件(資料庫如文首所示方式關註公眾號自行獲取)
import json
from nlp_demo.tech_clean.utils_mysql import query
def get_class_json():
f_class = open ("../tech_data/tech_name.txt", "r", encoding='utf-8')
res_dict = {}
while True:
line = f_class.readline()
if line:
# print(line)
# 按\t分隔 分開名稱和序號
temp_str_list = line.split("\t")
class_name = str(temp_str_list[0])
class_num = str(temp_str_list[1].replace("\n",""))
res_dict[class_name] = class_num
# print("-------------------------")
else:
break
print(json.dumps(res_dict,ensure_ascii=False))
class_json = json.dumps(res_dict,ensure_ascii=False)
with open("../tech_data/tech_order_class.json", "w", encoding='utf-8') as f:
f.write(class_json) # 自帶文件關閉功能,不需要再寫f.close()
f_class.close()
return
# 處理語料
"""
處理訓練集數據格式【tech_train.txt】
關鍵詞(使用英文逗號分隔) \t 分類號(從0開始)
-----
分類名稱表【tech_name.txt】
分類名稱 \t 分類號(從0開始)
"""
def get_tech_data():
with open("../tech_data/tech_class.json", "r", encoding='utf-8') as fo:
# print(fo.read())
table_name = json.loads(fo.read()) # json 轉 字典
with open("../tech_data/tech_order_class.json", "r", encoding='utf-8') as fo_1:
# print(fo.read())
tech_class = json.loads(fo_1.read()) # json 轉 字典
# print(table_name)
# 使用上面的數據 拼接字元串 拼接表名 k 是字母號 v 是名稱
for k,v in table_name.items():
order_num = None # 根據名稱找到對應的數字序號
if(k == None or v == None):
continue
for k1, v1 in tech_class.items():
# k1 是名稱 v1 是數字序號
if(v == k1):
order_num = v1 # 給序號賦值
print("正在處理的類別: " + k , v)
k = str(k)
v = str(v)
sql = "select * from tech_"+ k
# print("這是sql語句: " + sql)
# 第7個位置是 中文關鍵詞 第16個位置是中圖分類名稱
res_one_class = query(sql)
for res_one_class_item in res_one_class:
keywordsCn = str(res_one_class_item[7])
classification = str(order_num)
with open("../tech_res_data/tech_all" + ".txt","a+",encoding='utf-8') as fw:
keywordsCn = keywordsCn.replace(";",",")
keywordsCn = keywordsCn.replace(";",",")
keywordsCn = keywordsCn.replace(",,","")
keywordsCn = keywordsCn.replace(",",",")
print(keywordsCn + " --------> " + classification)
fw.write( keywordsCn + "\t" + classification + "\n")
print("============= 這是分隔符 =============")
return 0
if __name__ == '__main__':
# get_class_json() # 生成json格式的分類名稱文件
get_tech_data()
2.2、utils_mysql.py
import pymysql
"""
------------------------------------------------------------------------------------
"""
def get_conn():
"""
:return: 連接,游標
"""
# 創建連接
conn = pymysql.connect(host="127.0.0.1",
user="root",
password="reliable",
db="tech",
charset="utf8")
# 創建游標
cursor = conn.cursor() # 執行完畢返回的結果集預設以元組顯示
return conn, cursor
def close_conn(conn, cursor):
if cursor:
cursor.close()
if conn:
conn.close()
"""
-----------------------------------------------------------
"""
"""
------------------------------------------------------------------------------------
"""
def query(sql,*args):
"""
通用封裝查詢
:param sql:
:param args:
:return:返回查詢結果 ((),())
"""
conn , cursor= get_conn()
print(sql)
cursor.execute(sql)
res = cursor.fetchall()
close_conn(conn , cursor)
return res
好看請贊,養成習慣:) 本文來自博客園,作者:靠譜楊, 轉載請註明原文鏈接:https://www.cnblogs.com/rainbow-1/p/16801120.html
關於筆者: 我的主頁
文章同步51CTO,可以幫忙踩一踩 ~ 我的51CTO博客
更多日常分享盡在我的VX公眾號:靠譜楊的挨踢生活


