
1.字元串capitalize函數 (capitalize vt. 資本化,用大寫字母書寫(或印刷); 把…首字母大寫;) 將字元串的首字母大寫,其它字母小寫; 用法:newstr = string.capitalize() 修改後生成一個新字元串(因為字元串是不可更改數據類型); ''.capit ...
1.字元串capitalize函數
(capitalize vt. 資本化,用大寫字母書寫(或印刷); 把…首字母大寫;)
將字元串的首字母大寫,其它字母小寫;
用法:newstr = string.capitalize() 修改後生成一個新字元串(因為字元串是不可更改數據類型);

''.capitalize() 返回為空,不會報錯;
' '.capitalize()返回空格,不會報錯;
總結一下,無論字元串中包含什麼字元,capitalize()只對字母有效,首位是字母就大寫,非首位是字母就小寫。
2.字元串內置函數lower()
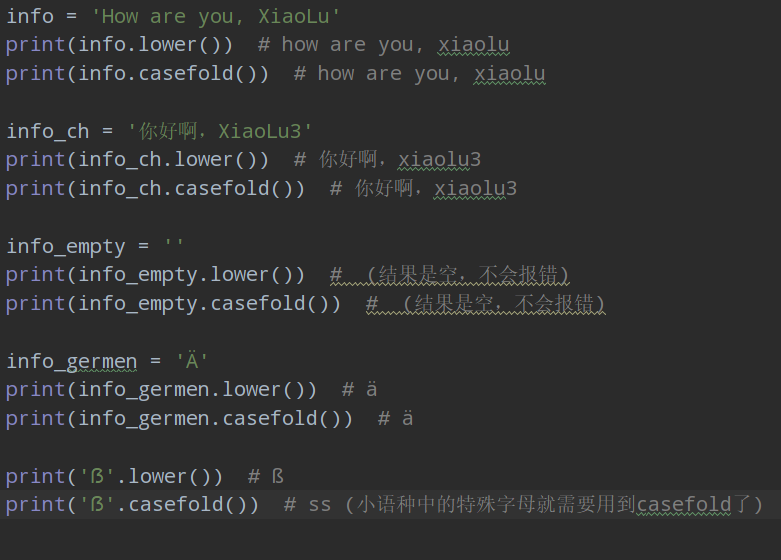
lower() 將所有字母變成小寫字母,同capitalize() 方法只對字母有效;
newstr = string.lower()同樣生成新字元串(再次加深印象,字元串是不可修改數據類型);
還有一個casefold()方法,也是將所有字母變成小寫,用法和lower()一致;
區別:casefold()可以將德語等小語種的特殊字母變成小寫,lower()只對a-z字母有效,
開發中不接觸小語種的話,二者返回結果無差別。
3.字元串內置函數upper()
將字元串中所有字母變成大寫,同樣只對字母有效;

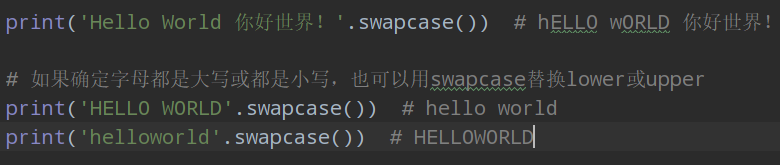
4.字元串內置函數swapcase()
swap 交換;
swapcase() 將字元串中大寫字母變小寫、小寫字母變大寫,同樣只對字母有效;
5.字元串內置函數zfill()
為字元串指定寬度,不足的位置用0填充;(不常用)
newstr = string.zfill(width) 參數width: 指定需要的寬度;

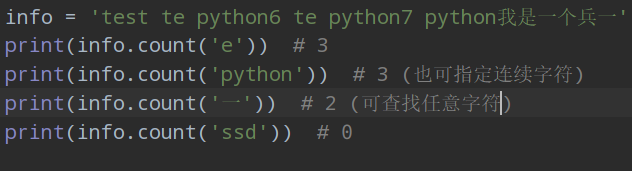
6.字元串內置函數count()
返回要查找成員的個數,int = string.count(item) 參數item是待查找的成員;(常用於對一些結果log的解析)
字元串中若沒有要查找的成員,則返回0;
7.字元串內置函數startswith()和endswith()
startswith()判斷字元串開頭是否是某成員;
endswith()判斷字元串結尾是否是某成員;
string.startswith(item)參數是待查成員、string.endswith(item) 參數是待查成員,返回值均是布爾值;

8.字元串內置函數find和index
查找字元串中成員的位置,(字元串中從左以0開始標註字元的位置,空格也算一個位置);
string.find(item) 返回item的位置,成員不存在時返回-1;
string.index(item)返回item的位置,成員不存在時程式會報錯。

9.字元串內置函數strip()
去除字元串左右兩邊的指定字元;
string.strip(字元) 參數可不填,預設是空格;傳入的參數如果並不在開頭或結尾,則無效,但程式不會報錯;
'erererddtt'.strip('er') #ddtt 指定參數是‘er’,開頭所有連續重覆的er都會去掉;
lstrip(字元) 去除開頭的指定字元,rstrip(字元)去除結尾的指定字元;預設也是去除空格;

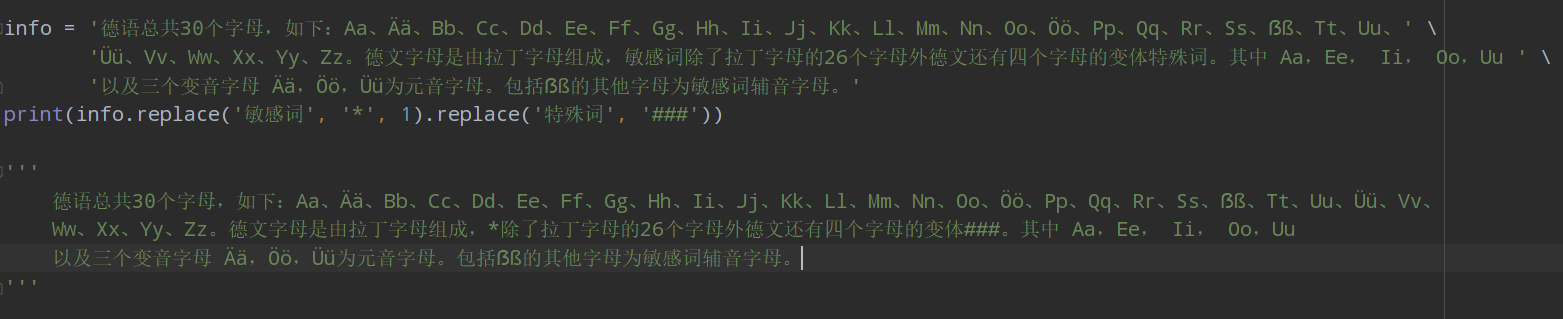
10.字元串內置函數replace()
將字元串中的舊成員替換成新成員,可以指定替換的個數;
string.replace(old, new, max)舊成員,新成員,替換個數(可以不指定,預設是全部替換);
常用於一些敏感辭彙的替換,如下:
11.字元串的一些判斷類型的內置函數
isspace() 判斷字元串是否僅有空格組成,booltype = string.isspace(), (僅由空格組成的字元串,並不是空字元串);
istitle() 判斷字元串是否是標題類型,booltype = string.istitle()
(標題類型:英文字元串由不同單片語成,每個單詞首字母要是大寫,其餘字母都是小寫就是標題類型);
isupper() 和 islower() 判斷字元串中的字母是否都是大寫或小寫 ;
以上方法只檢測字元串中的字母,對其它字元不做判斷;

12.字元串的編碼格式
將世界各種語言翻譯成電腦可讀懂字元的過程,就是編碼;
電腦可識別字元和語言字元的對照表,就是一個個不同的編碼格式;
常見編碼格式:gbk中文編碼、ASCII英文;(在開發過程中,指定對應的編碼格式,就可以輸出對應語言的信息了,否則會輸出亂碼)
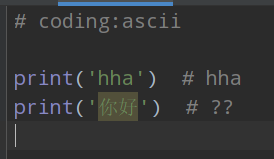
日語、法語、中文等,都有自己獨立的編碼格式,若想在中文腳本中使用法語,就會比較麻煩,這就需要一個全部語言都通用的編碼格式,
所以就出現了我們常用的國際通用編碼格式utf-8。 # coding:utf-8
13.字元串的格式化
一個固定的字元串中,某些元素是根據變數的值而改變的字元串,這種書寫方式,就是字元串的格式化;
使用場景:統一發送郵件、短消息、app推送等內容時,信息內容模板相同、只有個人信息不同,為了方便就可以使用字元串的格式化;
幾種不同的格式化方法:
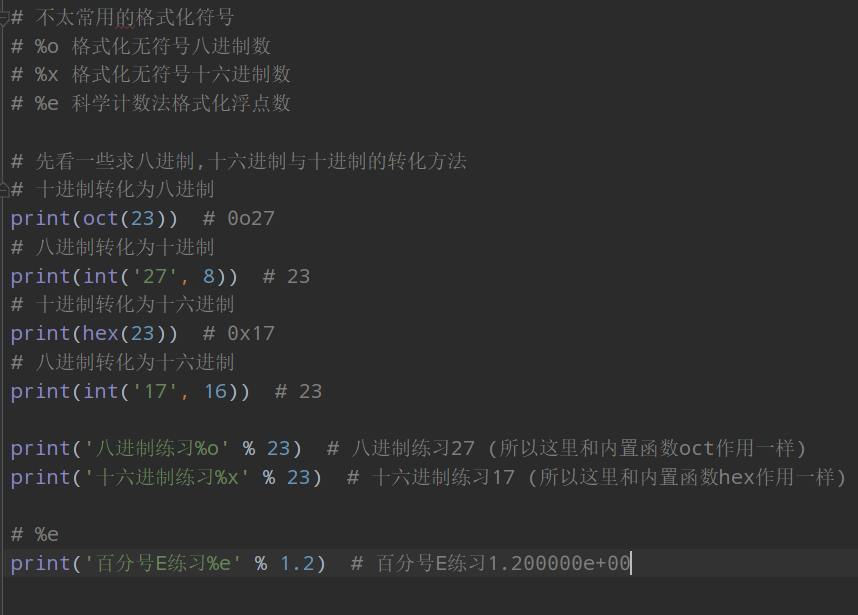
用%格式化字元串
'my name is %s, i love %s' % ('xiao lu', 'python')

print('i am %s') # i am %s 未指定%s對應的值列印時,不會報錯,會帶著%s直接列印出來;
%s是通用的格式化字元,還有其它多種格式化符號;
%d 格式化整型、%f 格式化字元串、%u 格式化無符號整型(正整型)(官方描述)、%c 格式化成數字對應的字元;

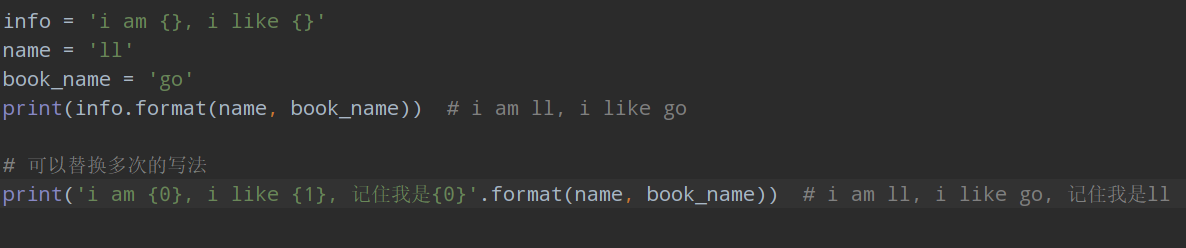
使用format函數
'hello {},我的手機號是{}'.format('xiao lu', 1234567890)
使用f''方法

14.字元串的轉義字元
python字元串中通過一些特殊字元來表示換行、回車、後退、tab鍵等功能,這些就是轉義字元;
\n 換行 \t 橫向製表符(間隔符、tab) \b 退格符(游標前移一個,會刪除前一個) \r 回車
\a 響鈴 \v縱向製表符(列印會出現一個男性符號) \f 翻頁 (列印會出現一個女性符號)
\' 轉義字元中的單引號 \''轉義字元中的雙引號 \\轉義斜杠;

比較常用的就是\n \t \\ \' \'' , 其它不太常用,且不同編譯環境,一些轉義字元的效果不一定會顯示出來,不用糾結。

