
序言 哈嘍兄弟們,今天咱們來瞭解一下 fileinput 。 說到fileinput,可能90%的碼農表示沒用過,甚至沒有聽說過。 這不奇怪,因為在python界,既然open可以走天下,何必要fileinput呢? 但是,今天我還是要介紹fileinput這個方法,因為太奈斯了。 不止是香。是真香 ...
序言
哈嘍兄弟們,今天咱們來瞭解一下 fileinput 。
說到fileinput,可能90%的碼農表示沒用過,甚至沒有聽說過。
這不奇怪,因為在python界,既然open可以走天下,何必要fileinput呢?
但是,今天我還是要介紹fileinput這個方法,因為太奈斯了。
不止是香。是真香!
接下來,就跟著我,一起fileinput,對,就是這個feel。

正文
1、方法介紹
基本用法
先來看一下fileinput的基本功能:
-
fileinput.filename():返回當前被讀取的文件名。
—>在第一行被讀取之前,返回 None。 -
fileinput.fileno():返回以整數表示的當前文件“文件描述符”。
—>當未打開文件時(處在第一行和文件之間),返回 -1。 -
fileinput.lineno():返回已被讀取的累計行號。
—>在第一行被讀取之前,返回 0。在最後一個文件的最後一行被讀取之後,返回該行的行號。 -
fileinput.filelineno():返回當前文件中的行號。
—>在第一行被讀取之前,返回 0。
—>在最後一個文件的最後一行被讀取之後,返回此文件中該行的行號。
進階用法
-
fileinput.isfirstline():如果剛讀取的行是其所在文件的第一行則返回 True,否則返回 False。
-
fileinput.isstdin():如果最後讀取的行來自 sys.stdin 則返回 True,否則返回 False。
-
fileinput.nextfile():關閉當前文件以使下次迭代將從下一個文件(如果存在)讀取第一行;不是從該文件讀取的行將不會被計入累計行數。直到下一個文件的第一行被讀取之後文件名才會改變。
—>在第一行被讀取之前,此函數將不會生效;它不能被用來跳過第一個文件。
—>在最後一個文件的最後一行被讀取之後,此函數將不再生效。 -
fileinput.close():關閉序列。
2、 預設讀取
代碼示例
import fileinput '當 Python 腳本沒有傳入任何參數時,fileinput 預設會以 stdin 作為輸入源' for line in fileinput.input(): print(f'{line}')
運行結果
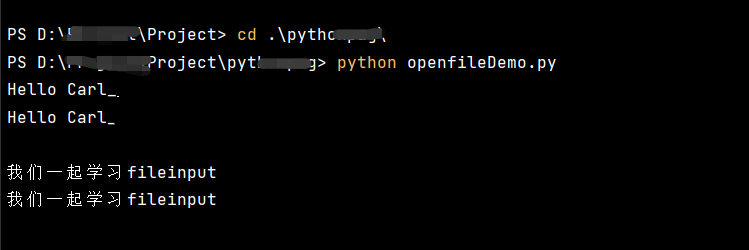
你輸入的內容,程式都會讀取並再輸出。
俗稱:復讀機
3、處理一個文件
代碼示例
import fileinput 'files 輸入打開文件的名稱即可' with fileinput.input(files=('output.txt',)) as file: for line in file: print(f'{fileinput.filename()} 第{fileinput.lineno()}行:{line}',end='')
運行結果
解析:
- fileinput 有且僅有這兩種讀取模式:‘r’,‘rb’;
- fileinput.input() 預設使用 mode=‘r’ 的模式讀取文件,如果你的文件是二進位的,可以使用mode=‘rb’ 模式。
4、處理批量文件
多文件序號連續排序
調用方法
- fileinput.lineno()方法
代碼示例
import fileinput 'files 輸入打開文件的名稱即可' with fileinput.input(files=('output.txt','input.txt')) as file: for line in file: #fileinput.lineno() 把兩個文件的整合陳一個文件對象file,需要排序輸出 print(f'{fileinput.filename()} 第{fileinput.lineno()}行: {line}', end='') # fileinput.filelineno()兩個文件單獨讀取,需要單獨排序 print(f'{fileinput.filename()} 第{fileinput.filelineno()}行: {line}', end='')
運行結果
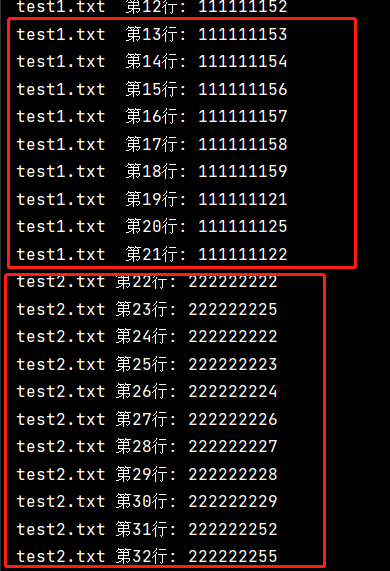
多文件序號單獨排序
調用方法
- fileinput.filelineno()方法
代碼示例
import fileinput 'files 輸入打開文件的名稱即可' with fileinput.input(files=('test1.txt','test2.txt')) as file: for line in file: # fileinput.filelineno()兩個文件單獨讀取,需要單獨排序 print(f'{fileinput.filename()} 第{fileinput.filelineno()}行: {line}', end='')
運行結果
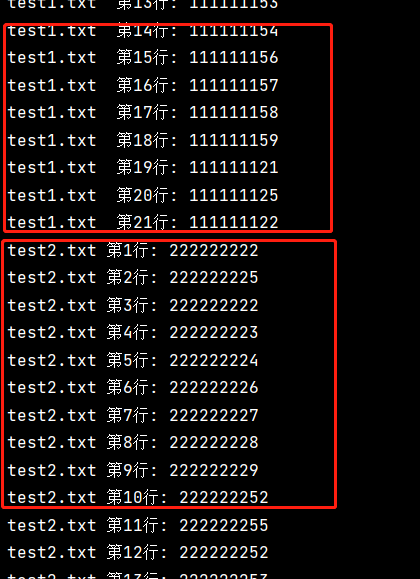
與glob配合用法
在顏值的時代,上面的輸出樣式,已經無法滿足我們的需要了,於是乎,我們就想到了glob。
代碼示例
import fileinput import glob #glob 匹配te開頭的txt文件 for line in fileinput.input(glob.glob("te*.txt")): if fileinput.isfirstline(): #輸出讀取文件 print('='*10,f'讀取文件{fileinput.filename()}','='*10) #fileinput.filelineno()方法讀取 print(str(fileinput.filelineno())+ ':'+line.upper(),end='')
運行結果
就這顏值,哪個小姐姐能不喜歡呢。
5、讀取與備份
調用方法
- fileinput.input 的backup 參數,可以指定備份的尾碼名,比如 .bak
代碼示例
import fileinput #觸發backup的動作,源文件內容被修改,對源文件進行backup with fileinput.input(files=("test1.txt",), backup=".bak",inplace=1) as file: for line in file: print(line.rstrip().replace('111111', '222222')) print(f'{fileinput.filename()} 第{fileinput.lineno()}行: {line}', end='')
運行結果

6、重定向替換
解析
- 上面的例子, 用到了 inplace參數,表示是否將標準輸出的結果寫迴文件,預設不取代。
代碼示例:
import fileinput #觸發backup的動作,源文件內容被修改,對源文件進行backup with fileinput.input(files=("test2.txt",), inplace=True) as file: print("[INFO] task is started...") for line in file: print(f'{fileinput.filename()} 第{fileinput.lineno()}行: {line}', end='') print("[INFO] task is closed...")
運行結果
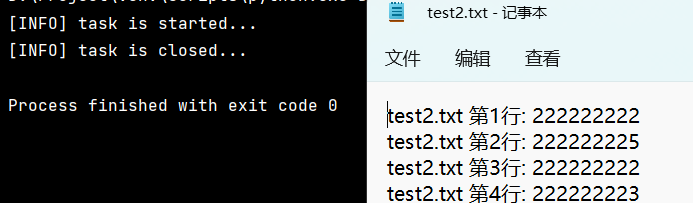
註
通過運行結果,可以看到:
- 在 for 迴圈體內的 print 內容會寫回到原文件中了。
- 而在 for 迴圈體外的 print 則沒有變化。
7、進階
openhook含義解析
- 在 fileinput.input() 中有一個 openhook 的參數,它支持用戶傳入自定義的對象讀取方法;
- 如果沒有傳入任何勾子,fileinput 預設使用的是 open 函數;
方法介紹
fileinput 內置了兩種勾子
1、fileinput.hook_compressed(filename, mode)
- 使用 gzip 和 bz2 模塊透明地打開 gzip 和 bzip2 壓縮的文件(通過擴展名 ‘.gz’ 和 ‘.bz2’ 來識別);
- 如果文件擴展名不是 ‘.gz’ 或 ‘.bz2’,文件會以正常方式打開(即使用 open() 並且不帶任何解壓操作);
- 使用示例: fi = fileinput.FileInput(openhook=fileinput.hook_compressed)
2、fileinput.hook_encoded(encoding, errors=None)
- 返回一個通過 open() 打開每個文件的鉤子,使用給定的 encoding 和 errors 來讀取文件。
- 使用示例: fi = fileinput.FileInput(openhook=fileinput.hook_encoded(“utf-8”, “surrogateescape”))
示例實戰
假如我想要使用 fileinput 來讀取網路上的文件,思路:
- 先使用 requests 下載文件到本地
- 再使用 open 去讀取它;
def online_open(url, mode): import requests r = requests.get(url) filename = url.split("/")[-1] with open(filename,'w') as f1: f1.write(r.content.decode("utf-8")) f2 = open(filename,'r') return f2
直接將這個函數傳給 openhook 即可:
import fileinput file_url = 'https://www.csdn.net/robots.txt' with fileinput.input(files=(file_url,), openhook=online_open) as file: for line in file: print(line, end="")
代碼整合:
def online_open(url, mode): import requests r = requests.get(url) filename = url.split("/")[-1] with open(filename,'w') as f1: f1.write(r.content.decode("utf-8")) f2 = open(filename,'r') return f2 import fileinput file_url = 'https://www.csdn.net/robots.txt' with fileinput.input(files=(file_url,), openhook=online_open) as file: for line in file: print(line, end="") # Python學習交流群 279199867
運行結果
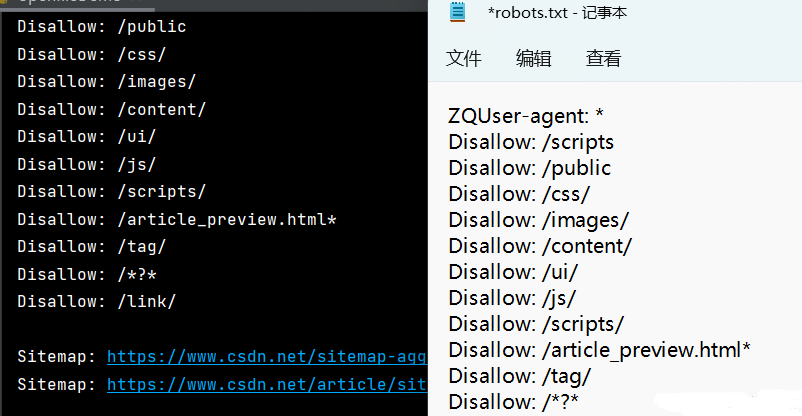
總結
關於fileinput的介紹,也就介紹到這裡。
fileinput本身是對 open 函數的再次封裝,所以在讀取的cc部分,就比open顯得更專業,更優雅,這也是僅限於讀取的方面。
在寫的方面,相對於open,就不是那麼的強悍。
歸根結底,fileinput還是一個不錯的方法。值得你擁有。
最後,再給大家推薦一套Python爬蟲教程:代碼總是學完就忘記?100個爬蟲實戰項目!讓你沉迷學習丨學以致用丨下一個Python大神就是你!


