
ORC文件是以二進位的方式存儲的,不可以直接讀取,但由於ORC的自描述特性,其讀寫不依賴於 Hive Metastore 或任何其他外部元數據。本身存儲了文件數據、數據類型及編碼信息。因為文件是自包含的,所以讀取ORC文件數據無需考慮用戶使用環境。 ...
目錄
概述
本文基於上一篇文章 Hive存儲格式之RCFile詳解,RCFile的過去現在未來 撰寫,讀過上一篇文章,則更好理解以下內容。
2013年,HortonWorks在RCFile的基礎上開發出了ORC File(Optimied Row Columnar),在2015年成為Apache的頂級項目。以下簡稱ORC。
RCFile在被Facebook開源後,作為Hive之中典型的列存儲模型被廣泛使用,相比於之前的存儲格式有很大的優勢,但是同樣RCFile仍然有值得改進的地方。
ORC 做了相關優化,在Hive的使用中有更好的表現,它支持複雜數據類型、ACID支持及內置索引支持,非常適合海量數據的存儲。
ORC並不是一個單純的列式存儲格式,它也遵循了先水平分區,再垂直分區的理念,採用混合存儲結構。
除了Hive,目前也被Spark SQL,Flink,Presto,Impala等查詢引擎支持。
我上一篇中提及RCFile的兩個優化方向:
- 不同數據類型的列使用不同的壓縮方案(Facebook論文指出的優化方向-未做)
- 全局檢索性能查,提供更合理快速的檢索功能
ORC相對於RCFile提供了更優的解決方案:
- 列數據的類型感知:與RCFile之前未對列數據都統一為BLOB(binary large object-二進位大對象)數據不同,ORC可以感知列的數據類型,做出更為合理的數據壓縮選擇。
- 嵌套數據類型支持:ORC可以在列數據之中插入Struct,Union,List,Map等數據,讓數據操作更加靈活,也更加適合非結構化數據的存儲與處理。
- 謂詞下推:這個算是RCFile原先功能的補強,在元數據層面增加了很多內容,來利用謂詞下推加速處理的過程。ORC自己稱之為輕量級索引,其實就是一些相較於RCFile更為詳細的統計數據。
- 文件可切分:文件可切分,在Hive中使用ORC作為表的文件存儲格式,不僅可以節省HDFS的存儲資源,查詢任務的輸入數據量減少,使用的MapTask也就減少了。
- 記憶體管理:提供了一個memory manager來管理記憶體使用情況。
接下來我們通過以下幾部分來完整的理解一下什麼是ORC。
文件存儲結構
ORC文件是以二進位的方式存儲的,不可以直接讀取,但由於ORC的自描述特性,其讀寫不依賴於 Hive Metastore 或任何其他外部元數據。本身存儲了文件數據、數據類型及編碼信息。因為文件是自包含的,所以讀取ORC文件數據無需考慮用戶使用環境。
由於ORC的元數據使用Protocol Buffers序列化,添加新欄位不會破壞原有的數據結構。
如下圖所示,ORC引入了三個新的組件。
-
Stripe
-
File Footer
-
PostScript
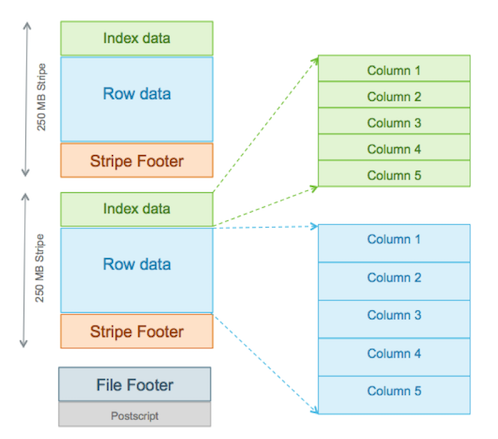
Stripe
ORC的主體由多個Stripe(也成為條帶)組成,類似於RCFile中的行組,但是其遠遠大於行組的4MB,最大可達到250M大小,更大的Stripe使ORC的數據讀取更加高效。
每個Stripe彼此獨立,這個很好理解,因為每行數據彼此獨立,而每行數據不會在多個Stripe中。
在Hive中每個Stripe通常由不同的任務處理。列存儲格式的定義特征是每一列的數據是分開存儲的,從文件中讀取數據的速度應該與讀取的列數成正比。
Stripe又包含三個部分:Index Data、Row Data和Stripe Footer。索引和數據部分都按列劃分,因此只需要讀取所需列的數據。
Index Data
索引數據部分,存儲每列的統計數據。Index Data在Stripe的最前面,因為它們只在使用謂詞下推或尋找指定行時載入。(這裡主要利用索引功能實現的,具體見下文條帶級別索引)
Row Data
實際存儲數據的單元,利用列存儲原理,對不同列可以實現不同的壓縮方案,所有的列數據可以組成行數據。
Stripe Footer
存儲了每個列的編碼,數據流目錄與位置。
message StripeFooter {
// the location of each stream
repeated Stream streams = 1;
// the encoding of each column
repeated ColumnEncoding columns = 2;
optional string writerTimezone = 3;
// one for each column encryption variant
repeated StripeEncryptionVariant encryption = 4;
}
兩個補充名詞
在數據存儲和解析的過程中還使用到了兩個比較抽象的名詞描述,分別為Row Group和Stream,這裡單獨說明一下。
Row Group
這裡的Row Group和RCFile里的行組不是同一個概念,RCFile的行組對標的是ORC中的Stripe。
Row Group是虛擬的(下文有詳細介紹),Row Group Index是索引(index)的最小單位,一個Index Data中包含多個行組。預設值為 10000 個值。每一個Row Group Index中有多少條記錄在文件的Footer中存儲。
Stream
本節以上部分是Stripe的邏輯結構,具體數據存儲還有更細粒度的單位存在,那就是Stream。在ORC文件中,每一列都存儲在多個Stream中,這些Stream在文件中彼此相鄰存儲。Stream保存了用戶真正關心的業務數據內容。
這也是ORC列式存儲的根本所在:正如開頭的架構圖一樣,一個大文件由各Stripe分割,每個Stripe負責多個行組,在一個Stripe負責的這多行範圍內,各列的數據內容以Stream的形式按列存儲。為了描述每個Stream,ORC以位元組為單位存儲Stream的類型、列ID和Stream的大小。每個Stream中存儲內容的詳細信息取決於列的類型和編碼。也就是說,在一個Stripe中的每一列都可能有多個表示不同信息的Stream,存儲內容如下所示:
message Stream {
enum Kind {
// boolean stream of whether the next value is non-null
PRESENT = 0;
// the primary data stream
DATA = 1;
// the length of each value for variable length data
LENGTH = 2;
// the dictionary blob
DICTIONARY_DATA = 3;
// deprecated prior to Hive 0.11
// It was used to store the number of instances of each value in the
// dictionary
DICTIONARY_COUNT = 4;
// a secondary data stream
SECONDARY = 5;
// the index for seeking to particular row groups
ROW_INDEX = 6;
// original bloom filters used before ORC-101
BLOOM_FILTER = 7;
// bloom filters that consistently use utf8
BLOOM_FILTER_UTF8 = 8;
// Virtual stream kinds to allocate space for encrypted index and data.
ENCRYPTED_INDEX = 9;
ENCRYPTED_DATA = 10;
// stripe statistics streams
STRIPE_STATISTICS = 100;
// A virtual stream kind that is used for setting the encryption IV.
FILE_STATISTICS = 101;
}
required Kind kind = 1;
// the column id
optional uint32 column = 2;
// the number of bytes in the file
optional uint64 length = 3;
}
這些不同類型的Stream會分佈在ORC文件里的不同部分,每個Stream的數據會根據該列的類型使用特定的壓縮演算法保存。主要有以下幾種(Kind)。首先是下麵這5種Stream,出現在各Stripe的Row Data位置,即文章開頭架構圖的藍色部分:
- PRESENT:幾乎每一列都會使用該Stream,按位標記該值是否為NULL
- DATA:記錄數據內容本身。
- LENGTH:記錄每個成員的長度,這個是針對string類型的列或者子列才有的。
- DICTIONARY_DATA:對string類型數據採用字典編碼以後的內容(該列所有去重值)。
- SECONDARY:和DATA搭配,存儲Decimal、timestamp類型的小數部分或者納秒數部分等。
下麵兩種Stream出現在Index Data中。
- ROW_INDEX:保存Stripe中每個row group的統計信息和每個row group起始位置信息。
- BLOOM_FILTER:用於記錄當前列在該Stripe中每一個row group的布隆過濾器信息,用於謂詞下推跳過不用讀取的行組。
File Footer
文件頁腳包含文件主體的佈局,類型架構信息,行數和每個列的統計信息。通過它們可以篩選出需要讀取列的數據。
條紋信息
文件的主體被分成stripe。每個stripe都是自包含的,可以僅使用其自己的位元組以及文件的頁腳和後記來讀取。每個stripe包含整行,因此行永遠不會跨越stripe邊界。
它包含了每一個stripe的長度和偏移量,該文件的schema信息(將schema樹按照schema中的編號保存在數組中,如下圖)、整個文件的統計信息以及每一個stripe的行數。
列統計
列統計的目標是,對於每一列,記錄總數並根據類型記錄其他有用欄位。對於大多數原始類型,它記錄了最小值和最大值;對於數字類型,多了一個總和記錄。列統計信息還通過設置 hasNull 標誌記錄行組內是否有任何空值。ORC 的謂詞下推使用 hasNull 標誌來更好地支持“IS NULL”查詢。
對於整數類型(tinyint、smallint、int、bigint),列統計信息包括最小值、最大值和總和。如果計算的總和存儲大於數據本身,則不會記錄總和。
message IntegerStatistics {
optional sint64 minimum = 1;
optional sint64 maximum = 2;
optional sint64 sum = 3;
}
對於浮點類型(float、double),列統計信息包括最小值、最大值和總和。如果總和溢出雙倍,則不記錄總和。
對於字元串,記錄最小值、最大值和所有值的長度之和。
對於布爾值,統計信息包括假值和真值的計數。
對於小數,存儲最小值、最大值和總和。
日期列將最小值和最大值記錄為自 UNIX 紀元(UTC 時間為 1970 年 1 月 1 日)以來的天數。
時間戳列將最小值和最大值記錄為自 UNIX 紀元 (1/1/1970 00:00:00) 以來的毫秒數。在 ORC-135 之前,包括本地時區偏移量,它們存儲為minimum和 maximum. 在 ORC-135 之後,時間戳調整為 UTC,然後再轉換為毫秒並存儲在minimumUtc和maximumUtc中。
message TimestampStatistics {
// min,max values saved as milliseconds since epoch
optional sint64 minimum = 1;
optional sint64 maximum = 2;
// min,max values saved as milliseconds since UNIX epoch
optional sint64 minimumUtc = 3;
optional sint64 maximumUtc = 4;
}
二進位列存儲所有值的總位元組數。
元數據
元數據(Metadata)包括用戶元數據和文件元數據,用戶元數據通常作為秘鑰使用,這裡不做闡述了。
文件元數據部分包含條帶級別粒度的列統計信息。這些統計信息可以根據每個條帶的謂詞下推過濾數據。
類型信息
ORC文件中的所有行具有相同的架構,定義的類型是如同下圖的嵌套模式,其中複合類型在其下具有子列。

等效的Hive DDL是:
create table orc_temp(
myInt int,
myMap map<string,struct<myStirng:string,myDouble:double>>,
myTime timestamp
)
類型樹通過前序遍歷被展平到一個列表中,其中每個類型都被分配了下一個id。
複雜數據類型
對於複雜數據類型,比如Map,ORC文件會將一個複雜數據類型欄位解析成多個子欄位。下表中列舉了ORC文件中對於複雜數據類型的解析:
| 數據類型 | 子列 |
|---|---|
| Array | 一個包含所有數組元素的單個子列 |
| Map | 兩個子列,一個key子列,一個value子列 |
| Struct | 每一個屬性對應一個子列 |
| Union | 每一個屬性對應一個子列 |
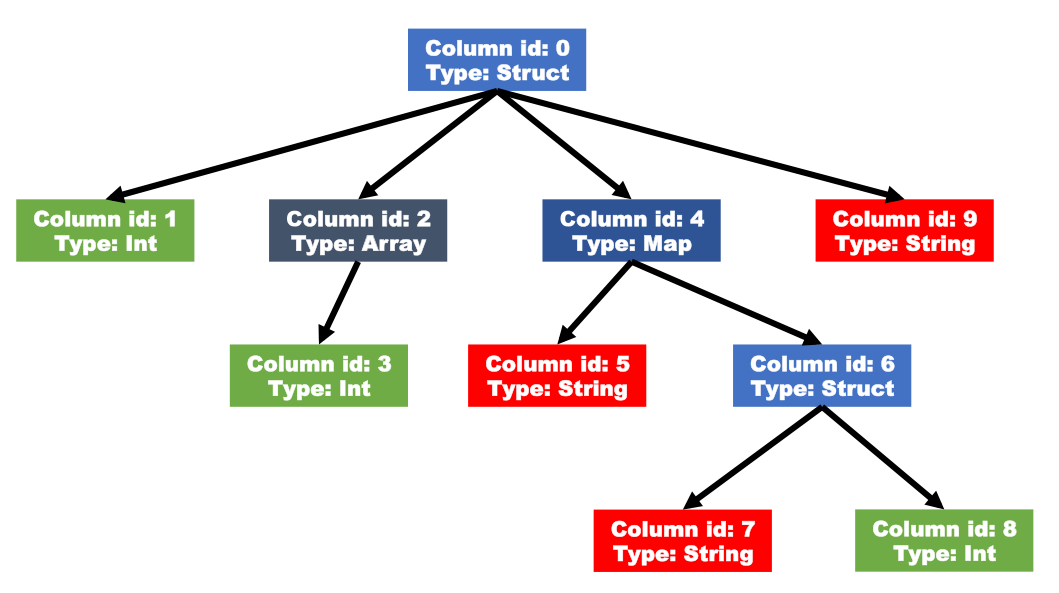
等效的DDL
CREATE TABLE tbl (
col1 Int,
col2 Array<Int>,
col4 Map<String,
Struct<col7:String,col8:Int>
>,
col9 String
)
Postscript
文件的最後一個位元組保存著PostScript的長度,它的長度不會超過256位元組,PostScript提供瞭解釋文件其餘部分的必要信息,包括文件的 Footer 和 Metadata 部分的長度、文件的版本以及使用的一般壓縮類型(例如 none、zlib 或 snappy)、文件內部每個壓縮塊的最大長度(每次分配記憶體的大小)以及一些版本信息。
數據讀取
orc文件結構對數據的查找和索引本質上是三層過濾結合位置指針來實現的:文件級、Stripe級、Row級。這樣可以把最終實際要掃描讀取的數據減少到部分Stripe的部分Row,不用全掃整個文件。也就是先從文件末尾往前讀文件元數據,再跳著讀Stripe元數據,最終讀需要的Stripe中的部分數據。
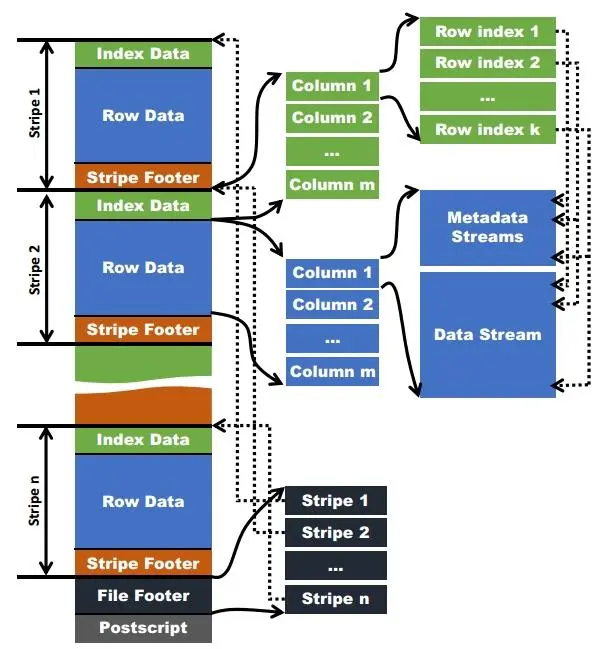
位置指針
在讀取ORC文件時,讀取器需要知道兩種位置,才能執行有效的數據讀取操作。
首先,由於條帶中的一列具有多個邏輯索引組(Row Group Index),因此ORC文件的讀取器需要知道元數據流和數據流中每個索引組的起點。在上圖中,指向元數據流和數據流的圓虛線表示這種位置指針。
其次,一個ORC文件可以包含多個Stripe,而這個ORC文件的一個HDFS塊可以包含多個Stripe。為了有效地定位Stripe的起點,需要定位Stripe的位置指針。這些指針存儲在ORC文件的文件頁腳中(圓角虛線指向上圖中條紋的起點)。
三層過濾
文件級
在ORC文件的末尾(文件頁腳)會記錄文件級別的統計信息,會記錄整個文件中每列的統計信息。這些信息主要用於查詢的優化,也可以為一些簡單的聚合查詢比如max, min, sum輸出結果。
Stripe級
ORC文件會保存每個欄位Stripe級別的統計信息,每個條帶中的每列的值的統計信息,ORC reader使用這些統計信息來確定對於一個查詢語句來說,需要讀入哪些Stripe中的記錄。例如,如果查詢要查找年齡超過 100 歲的人,則 SARG 將為“年齡 > 100”,並且只會讀取年齡超過 100 歲的條帶。
Row 級
為了進一步的避免讀入不必要的數據,在邏輯上將一個column的index(Index Data部分)以一個給定的值(預設為10000,可由參數配置)分割為多個index組(Row Group Index),存儲統計信息和行組索引開始的位置。
Hive查詢引擎會將where條件中的約束傳遞給ORC reader,這些reader根據組級別的統計信息,過濾掉不必要的數據。如果該值設置的太小,就會保存更多的統計信息,用戶需要根據自己數據的特點權衡一個合理的值。
關於虛擬的Row Group,這10000個值的Row group Index映射到數據里,就是一個個的Row Group。反向看起來好像是Row Group的存在產生了Row group Index。但實際上Row Group是不存在的。為了便於理解,有些文章里也會說在Stripe之下還會有一個Row Group的存在。
數據讀取
看了以上三級文件結構,就能很好的理解整個ORC的數據讀取流程了。
讀取文件元數據:讀取 ORC 文件是從尾部開始的。第一次讀取16KB的大小,儘量的將Postscript和Footer數據都讀入記憶體。
讀取Stripe元數據:處理Stripe時首先從Footer中獲取每一個Stripe的起始位置和長度、每一個Stripe的Footer數據(元數據,記錄了index和data的的長度)。在初始化階段獲取所有的元數據以後,會得到一個指定讀取哪些列的編號構成的Boolean數組。如果不指定則讀取所有的列。
讀取Row Group級元數據:接下來通過傳遞SearchArgument參數指定過濾條件,根據元數據首先讀取每個stripe中的index信息,而後根據index中的統計信息以及SearchArgument參數讀取的row group編號,獲取到所要讀取數據範圍包含了哪些row group,在對應的row group中讀取需要的數據。
讀取數據處理:經過這兩層的過濾,需要讀取的數據只是整個Stripe多個小段的區間,而後ORC會儘量合併多個離散的區間儘量減少I/O次數。下一步再根據Index中保存的下一個row group的位置信息開始該Stripe中的下一個需要讀取的row group中進行數據讀取。

使用ORC文件格式時,用戶可使用HDFS的每個block存儲ORC文件的一個stripe。對於一個ORC文件來講,stripe的大小通常須要設置得比HDFS的block小,若是不這樣的話,一個stripe就會分別在HDFS的多個block上,當讀取這種數據時就會發生遠程讀數據的行為。若是設置stripe的只保存在一個block上的話,若是當前block上的剩餘空間不足以存儲下一個strpie,ORC的writer接下來會將數據打散保存在block剩餘的空間上,直到這個block存滿為止。這樣,下一個stripe又會從下一個block開始存儲。
因為ORC中使用了更加精確的索引信息,使得在讀取數據時能夠指定從任意一行開始讀取,更細粒度的統計信息使得讀取ORC文件跳過整個row group,ORC預設會對任何一塊數據和索引信息使用ZLIB壓縮(可更改),所以ORC文件占用的存儲空間也更小。
索引
ORC文件在Row級過濾中使用的索引具體分為兩種。行組索引和布隆過濾器。後者為支持更好的使用謂詞下推過濾數據。布隆過濾器流與行組索引交錯。這種佈局便於在單次讀取操作中同時讀取布隆過濾器流和行索引流。

行組索引
行組索引(Row Group Index)由每個原始列的 ROW_INDEX 流組成,每個原始列被行組索引覆蓋。行組可調節,預設為 10,000 行。存儲列的每個流的位置以及該行組的統計信息。
索引流被放置在條帶的前面,因為在預設的流式傳輸情況下,它們不需要被讀取。它們僅在使用謂詞下推或讀者尋找特定行時載入。
message RowIndexEntry {
repeated uint64 positions = 1 [packed=true];
optional ColumnStatistics statistics = 2;
}
message RowIndex {
repeated RowIndexEntry entry = 1;
}
對於具有多個流的列,每個流中的位置序列是連接的。
因為字典是隨機訪問的,即使只讀取部分條帶,也必須讀取整個字典。
布隆過濾器
從 Hive 1.2.0 開始,Bloom Filters 被添加到 ORC 索引中。謂詞下推可以利用布隆過濾器更好地修剪不滿足過濾條件的行組。布隆過濾器索引由通過“orc.bloom.filter.columns”表屬性指定的每一列的 BLOOM_FILTER 流組成。
布隆過濾器的具體使用參見上篇--什麼是謂詞下推篇中的列式存儲中的謂詞下推(RF演算法)。
事務支持
在 Hive 中以原子方式向表中添加數據的唯一方法是添加新分區。更新或刪除分區中的數據需要刪除舊分區並將其與新數據一起添加回來,並且不可能以原子方式進行。
為了數據可靠性得到保證,需要實現保證原子性、一致性、隔離性和持久性的 ACID 事務。ORC支持 ACID 事務,支持流式攝取到 Hive 表中,查詢要麼看到所有事務,要麼看不到任何事務。
HDFS 是一次寫入文件系統,而 ORC 是一次寫入文件格式,不支持編輯文件。
Hive在 ORC File基礎上,基於“base file+delta file”的模型實現了對ACID的支持,即數據首先被寫入一個 base file中,之後的修改數據被寫入一個 delta file,Hive將定期合併這兩個文件。
但需要註意的是, Hive ORC ACID並不是為OLTP場景設計的,它能較好地支持一個事務中更新上百萬(甚至更多)條記錄,但難以應對一小時內上百萬個事務的場景。
壓縮
ORC文件使用了一個兩級壓縮方案。流首先由特定於流類型的數據編碼方案進行編碼。然後,可以使用一個可選的通用數據壓縮方案(zlib 或 snappy)來進一步壓縮該流。
上文提到對於一個列,它被存儲在一個或多個流中。根據流的類型,我們可以將流分為四種基本類型。根據其類型,每個流有自己的數據編碼方案。下麵介紹了這四種流的類型。
- 位元組流:一個位元組流基本上存儲一個位元組序列,它不編碼數據。
- 運行長度位元組流:一個運行長度位元組流存儲一個位元組序列。對於一個相同的位元組序列,它存儲重覆的位元組和出現的情況。
- 整數流:一個整數流存儲一個整數序列。它可以用運行長度編碼和增量編碼來編碼這些整數。整數子序列的特定編碼方案是根據其模式確定的。
- 比特流:一個位欄位流用於存儲一個布爾值的序列。在這個流中,一個位表示一個布爾值。在底層,位欄位流由運行長度位元組流支持。
對於Int列,將使用一個比特流和一個整數流。比特流用於記錄一個值是否為空。整數流用於記錄此Int列的整數值。
對於二進位數據,ORC 使用三個流 ,比特流、位元組流 和 整數流,它們存儲每個值的長度。
對於字元串列,ORC寫入器將首先檢查使用字典編碼是否可以有效地通過評估字典中不同條目的數量與編碼值的數量的比率是否大於可配置的閾值(預設閾值為0.8)來有效地存儲數據。
如果小於0.8,ORC寫入器將使用字典編碼方案,該列將存儲在一個比特流、一個位元組流和兩個整數流中。與Int列一樣,比特流也用於記錄一個值是否為空。位元組流用於存儲字典。一個整數流用於存儲字典中每個詞條的長度。第二個整數流用於存儲此列的值。
如果字典中不同條目目的數量與編碼值的數量大於閾值,ORC編寫器將知道有許多不同的值,使用字典編碼不能有效地存儲數據。因此,它將自動存儲此列,而不需要進行字典編碼。ORC寫入器將使用位元組流來存儲此字元串列的值,並使用整數流來存儲每個值的長度,而不是將字典和將值存儲為對字典的索引。
在ORC文件中,可以進一步對ORC文件使用通用的編解碼器壓縮流(ZLIB、Snappy)。對於一個流,通用編解碼器將這個流壓縮為多個小壓縮單元。壓縮單元的預設大小為256KB。
ORC存儲格式支持三種通用壓縮格式,NONE,ZLIB和snappy壓縮,預設為ZLIB壓縮,即不設置壓縮格式則為ZLIB壓縮格式,可以通過"orc.compress"="NONE"來設置其餘兩種壓縮格式。
關於以上四種類型的編碼詳解,感興趣的人可以去ORC官網具體查看。
記憶體管理
當ORC文件的寫入器寫入數據時,它會緩衝記憶體中的整個Stripe。因此,ORC寫入器的記憶體占用是Stripe的大小。由於Stripe的預設大小很大,當有許多用戶同時寫入多個映射或減少任務中的ORC文件時(例如,當用戶使用動態分區,並且分區列有許多不同的值時),此任務可能會耗盡記憶體。為了綁定這些併發寫入器的記憶體消耗,ORC文件中提供了一個記憶體管理器。在“映射”或“減少”任務中,記憶體管理器會設置一個閾值,以限制此任務中的寫入者可以使用的最大記憶體量。然後,每個新寫入器都以其Stripe大小(已設置的Stripe大小)註冊到此記憶體管理器。
當寫入器使用的記憶體總量(設置的Stripe大小總數)超過記憶體閾值時,記憶體管理器將以記憶體閾值與註冊的Stripe大小總數的比值縮小這些寫入器中使用的實際Stripe大小。當寫入器關閉時,記憶體管理器將從註冊的Stripe大小中減去此寫入器的註冊Stripe大小。如果註冊的總條帶大小低於閾值,則所有寫入器的實際條帶大小將被設置為其原始條帶大小。使用這種控制機制,來約束任務中ORC文件的活動寫入器的記憶體。
Hive中使用ORC
Hive使用
在建Hive表的時候指定文件的存儲格式。
CREATE TABLE ... STORED AS ORC
ALTER TABLE ... [PARTITION partition_spec] SET FILEFORMAT ORC
SET hive.default.fileformat=Orc
示例
-- 建表
create table lubian_orc(
id int,
name string,
extra string
) comment 'orc格式測試表'
stored as orc;
-- 寫入數據
insert overwrite table lubian_orc
select id,name,extra from lubian_text
大多情況下,還是建議在Hive中將文本文件轉成ORC格式(以上),使用程式生成ORC文件,例如Java,屬於特殊需求場景,感興趣可以在orc官網找對應api做一些測試。
Hive參數設置
所有關於ORCFile的參數都是在Hive QL語句的TBLPROPERTIES欄位裡面出現
| 參數名 | 預設值 | 說明 |
|---|---|---|
| hive.exec.orc.memory.pool | 0.5 | 每個寫入任務使用記憶體最大比例 |
| hive.exec.orc.default.stripe.size | 256M | stripe的預設大小 |
| hive.exec.orc.default.block.size | 25610241024 | orc文件在文件系統中的預設block大小,從hive-0.14開始 |
| hive.exec.orc.dictionary.key.size.threshold | 0.8 | String類型欄位使用字典編碼的閾值,大於該閾值,不使用字典編碼 |
| hive.exec.orc.default.row.index.stride | 10000 | stripe中的分組大小 |
| hive.exec.orc.default.compress | ZLIB | ORC文件的預設壓縮方式 |
| hive.exec.orc.skip.corrupt.data | false | 遇到錯誤數據的處理方式,false直接拋出異常,true則跳過該記錄 |
更多參數參考官網
以上,就是關於ORC文件格式的詳細說明瞭,如果覺得不錯,點個贊再走吧。
按例,歡迎點擊此處關註我的個人公眾號,交流更多知識。
後臺回覆關鍵字 hive,隨機贈送一本魯邊備註版珍藏大數據書籍。

