
一、Mysql的系統架構圖 二、Mysql存儲引擎 Mysql中的數據是通過一定的方式存儲在文件或者記憶體中的,任何方式都有不同的存儲、查找和更新機制,這意味著選擇不同的方式對於數據的存取有效率的差距。 這種不同的存儲方式在 MySQL中被稱作存儲引擎。 存儲引擎是Mysql資料庫系統的底層組件,數據 ...
Redis是典型的單線程架構,所有的讀寫操作都是在一條主線程中完成的。當Redis用於高併發場景時,這條線程就變成了它的生命線。如果出現阻塞,哪怕是很短時間,對於我們的應用來說都是噩夢。導致阻塞問題的場景大致分為內在原因和外在原因:
·內在原因包括:不合理地使用API或數據結構、CPU飽和、持久化阻塞等。
·外在原因包括:CPU競爭、記憶體交換、網路問題等
- 發現阻塞:當Redis阻塞時,線上應用服務應該最先感知到,這時應用方會收到大量Redis超時異常,比如Jedis客戶端會拋出JedisConnectionException異常。完備的簡訊監控告警
- 內在原因:
- API或數據結構使用不合理:通常Redis執行命令速度非常快,但也存在例外,如對一個包含上萬個元素的hash結構執行hgetall操作,由於數據量比較大且命令演算法複雜度是O(n),這條命令執行速度必然很慢。這個問題就是典型的不合理使用API和數據結構。對於高併發的場景我們應該儘量避免在大對象上執行演算法複雜度超過O(n)的命令
- 發現慢查詢:執行slowlog get{n}命令可以獲取最近的n條慢查詢命令,預設對於執行超過10毫秒的命令都會記錄到一個定長隊列中。
- 如何發現大對象:redis-cli-h{ip}-p{port}bigkeys。內部原理採用分段進行scan操作,把歷史掃描過的最大對象統計出來便於分析優化
- CPU飽和
單線程的Redis處理命令時只能使用一個CPU。而CPU飽和是指Redis把單核CPU使用率跑到接近100%。使用top命令很容易識別出對應Redis進程的CPU使用率。CPU飽和是非常危險的,將導致Redis無法處理更多的命令,嚴重影響吞吐量和應用方的穩定性。
使用統計命令redis-cli-h{ip}-p{port}--stat獲取當前Redis使用情況,該命令每秒輸出一行統計信息
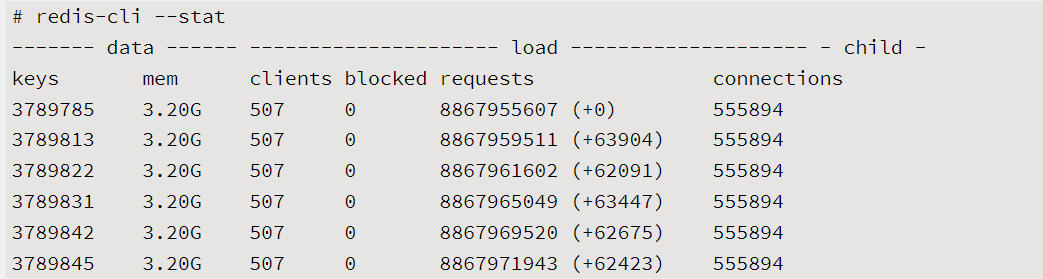
以上輸出是一個接近飽和的Redis實例的統計信息,它每秒平均處理6萬+的請求。對於這種情況,垂直層面的命令優化很難達到效果,這時就需要做集群化水平擴展來分攤OPS壓力。如果只有幾百或幾千OPS的Redis實例就接近CPU飽和是很不正常的,有可能使用了高演算法複雜度的命令。還有一種情況是過度的記憶體優化,這種情況有些隱蔽,需要我們根據info commandstats統計信息分析出命令不合理開銷時間,例如下麵的耗時統計:

查看這個統計可以發現一個問題,hset命令演算法複雜度只有O(1)但平均耗時卻達到135微秒,顯然不合理,正常情況耗時應該在10微秒以下。這是因為上面的Redis實例為了追求低記憶體使用量,過度放寬ziplist使用條件(修改了hash-max-ziplist-entries和hash-max-ziplist-value配置)。進程內的hash對象平均存儲著上萬個元素,而針對ziplist的操作演算法複雜度在O(n)到O(n2)之間。雖然採用ziplist編碼後hash結構記憶體占用會變小,但是操作變得更慢且更消耗CPU。ziplist壓縮編碼是Redis用來平衡空間和效率的優化手段,不可過度使用。
- 持久化阻塞
- fork阻塞:fork操作發生在RDB和AOF重寫時,Redis主線程調用fork操作產生共用記憶體的子進程,由子進程完成持久化文件重寫工作。如果fork操作本身耗時過長,必然會導致主線程的阻塞,可以執行info stats命令獲取到latest_fork_usec指標,表示Redis最近一次fork操作耗時,如果耗時很大,比如超過1秒,則需要做出優化調整,如避免使用過大的記憶體實例和規避fork緩慢的操作系統等。
- AOF刷盤阻塞:當我們開啟AOF持久化功能時,文件刷盤的方式一般採用每秒一次,後臺線程每秒對AOF文件做fsync操作。當硬碟壓力過大時,fsync操作需要等待,直到寫入完成。如果主線程發現距離上一次的fsync成功超過2秒,為了數據安全性它會阻塞直到後臺線程執行fsync操作完成。 #運維提示:硬碟壓力可能是Redis進程引起的,也可能是其他進程引起的,可以使用iotop查看具體是哪個進程消耗過多的硬碟資源。
- HugePage寫操作阻塞:子進程在執行重寫期間利用Linux寫時複製技術降低記憶體開銷,因此只有寫操作時Redis才複製要修改的記憶體頁。對於開啟Transparent HugePages的操作系統,每次寫命令引起的複製記憶體頁單位由4K變為2MB,放大了512倍,會拖慢寫操作的執行時間,導致大量寫操作慢查詢。
- 外在原因
- CPU競爭:
-
進程競爭
:Redis是典型的CPU密集型應用,不建議和其他多核CPU密集型服務部署在一起。當其他進程過度消耗CPU時,將嚴重影響Redis吞吐量。可以通過top、sar等命令定位到CPU消耗的時間點和具體進程 -
綁定CPU
:部署Redis時為了充分利用多核CPU,通常一臺機器部署多個實例。常見的一種優化是把Redis進程綁定到CPU上,用於降低CPU頻繁上下文切換的開銷
2.記憶體交換:
記憶體交換(swap)對於Redis來說是非常致命的,Redis保證高性能的一個重要前提是所有的數據在記憶體中。如果操作系統把Redis使用的部分記憶體換出到硬碟,由於記憶體與硬碟讀寫速度差幾個數量級,會導致發生交換後的Redis性能急劇下降。
1)查詢Redis進程號:
# redis-cli -p 6383 info server | grep process_id process_id:4476
2)根據進程號查詢記憶體交換信息:
# cat /proc/4476/smaps | grep Swap Swap: 0 kB
Swap: 0 kB
Swap: 4 kB
如果交換量都是0KB或者個別的是4KB,則是正常現象,說明Redis進程記憶體沒有被交換。預防記憶體交換的方法有:
·保證機器充足的可用記憶體。
·確保所有Redis實例設置最大可用記憶體(maxmemory),防止極端情況下Redis記憶體不可控的增長。
·降低系統使用swap優先順序,如echo10>/proc/sys/vm/swappiness
3.網路問題
- 連接拒絕:網路閃斷,一般發生在網路割接或者帶寬耗盡的情況,對於網路閃斷的識別比較困難,常見的做法可以通過sar-n DEV查看本機歷史流量是否正常
-
Redis連接拒絕
Redis通過maxclients參數控制客戶端最大連接數,預設10000。當Redis連接數大於maxclients時會拒絕新的連接進入,info stats的rejected_connections統計指標記錄所有被拒絕連接的數量 - 連接溢出:進程使用的資源做限制
- 連接溢出:backlog隊列溢出、系統對於特定埠的TCP連接使用backlog隊列保存。Redis預設的長度為511,通過tcp-backlog參數設置。如果Redis用於高併發場景為了防止緩慢連接占用,可適當增大這個設置,但必須大於操作系統允許值才能生效。
- 網路延遲:網路帶寬不穩定
總結:
1)客戶端最先感知阻塞等Redis超時行為,加入日誌監控報警工具可快速定位阻塞問題,同時需要對Redis進程和機器做全面監控。 2)阻塞的內在原因:確認主線程是否存在阻塞,檢查慢查詢等信息,發現不合理使用API或數據結構的情況,如keys、sort、hgetall等。關註CPU使用率防止單核跑滿。當硬碟IO資源緊張時,AOF追加也會阻塞主線程。 3)阻塞的外在原因:從CPU競爭、記憶體交換、網路問題等方面入手排查是否因為系統層面問題引起阻塞。


