
hi,我是桑小榆,坐在電腦桌旁肝了幾小時的linux服務實現負載均衡等等,乘著還有點時間把消息中間件的內容整理了下,比如現有ActiveMQ、RabbitMQ、RocketMQ、Kafka等常見的消息中間件的各有千秋,以及運用較多的RabbitMQ為例出現的高頻知識內容。 公司生產環境用的是什麼消息 ...
hi,我是桑小榆,坐在電腦桌旁肝了幾小時的linux服務實現負載均衡等等,乘著還有點時間把消息中間件的內容整理了下,比如現有ActiveMQ、RabbitMQ、RocketMQ、Kafka等常見的消息中間件的各有千秋,以及運用較多的RabbitMQ為例出現的高頻知識內容。
公司生產環境用的是什麼消息中間件?
你可以說下你們公司選用的是什麼消息中間件,比如用的是RabbitMQ,然後可以初步給一些你對不同MQ中間件技術的選型分析。
ActiveMQ:然後你可以說說RabbitMQ,他的好處在於可以支撐高併發、高吞吐、性能很高,同時有非常完善便捷的後臺管理界面可以使用。
另外,他還支持集群化、高可用部署架構、消息高可靠支持,功能較為完善。
RabbitMQ:國內各大互聯網公司落地大規模RabbitMQ集群支撐自身業務的案例較多,國內各種中小型互聯網公司RabbitMQ的實踐也比較多。
RabbitMQ的開源社區很活躍,較高頻率的迭代版本,來修複發現的bug以及進行各種優化,因此綜合考慮過後,公司採取了RabbitMQ。
RabbitMQ也有一點缺陷,就是他自身是基於erlang語言開發的,所以導致較為難以分析裡面的源碼,也較難進行深層次的源碼定製和改造,畢竟需要較為扎實的erlang語言功底才可以。
RocketMQ:RocketMQ,是阿裡開源的,經過阿裡的生產環境的超高併發、高吞吐的考驗,性能卓越,同時還支持分散式事務等特殊場景。
RocketMQ是基於Java語言開發的,適合深入閱讀源碼,有需要可以站在源碼層面解決線上生產問題,包括源碼的二次開發和改造。
Kafka:Kafka提供的消息中間件的功能明顯較少一些,相對上述幾款MQ中間件要少很多。
Kafka的優勢在於專為超高吞吐量的實時日誌採集、實時數據同步、實時數據計算等場景來設計。
Kafka在大數據領域中配合實時計算技術(比如Spark Streaming、Storm、Flink)使用的較多。但是在傳統的MQ中間件使用場景中較少採用。
Kafka、ActiveMQ、RabbitMQ、RocketMQ有什麼優缺點?
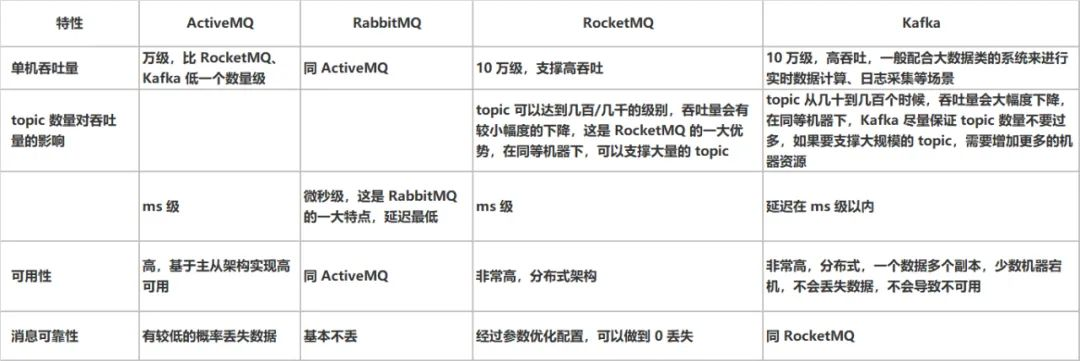
綜上,各種對比之後,有如下建議:
一般的業務系統要引入MQ,最早大家都用ActiveMQ,但是現在確實大家用的不多了,沒經過大規模吞吐量場景的驗證,社區也不是很活躍,並不是很推薦;後來大家開始用RabbitMQ,但是確實erlang語言阻止了大量的Java工程師去深入研究和掌控它,對公司而言,幾乎處於不可控的狀態,但是確實人家是開源的,比較穩定的支持,活躍度也高;
不過現在確實越來越多的公司會去用RocketMQ,確實很不錯,畢竟是阿裡出品,但社區可能有突然黃掉的風險,目前RocketMQ已捐給Apache,但 GitHub上的活躍度其實不算高,對自己公司技術實力有絕對自信的,推薦用RocketMQ,否則回去老老實實用RabbitMQ吧,人家有活躍的開源社區,絕對不會黃。
所以中小型公司,技術實力較為一般,技術挑戰不是特別高,用RabbitMQ 是不錯的選擇;大型公司,基礎架構研發實力較強,用RocketMQ是很好的選擇。
如果是大數據領域的實時計算、日誌採集等場景,用Kafka是業內標準的,絕對沒問題,社區活躍度很高,絕對不會黃,何況幾乎是全世界這個領域的事實性規範。
解耦、非同步、削峰是什麼?
解耦:A系統發送數據到BCD三個系統,通過介面調用發送。如果E系統也要這個數據呢?那如果C系統現在不需要了呢?A系統負責人幾乎崩潰…A系統跟其它各種複雜的系統嚴重耦合,A系統產生一條比較關鍵的數據,很多系統都需要A系統將這個數據發送過來。
如果使用MQ,A系統產生一條數據,發送到MQ裡面去,哪個系統需要數據自己去MQ裡面消費。如果新系統需要數據,直接從MQ里消費即可;如果某個系統不需要這條數據了,就取消對MQ消息的消費即可。
這樣下來,A系統壓根不需要去考慮要給誰發送數據,不需要維護這個代碼,也不需要考慮人家是否調用成功、失敗超時等情況。
非同步:A系統接收一個請求,需要在自己本地寫庫,還需要在BCD三個系統寫庫,自己本地寫庫要3ms,BCD三個系統分別寫庫要300ms、450ms、200ms。最終請求總延時是 3 + 300 + 450 + 200 = 953ms,接近1s,用戶體驗會非常不好。用戶通過瀏覽器發起請求。如果使用MQ,那麼A系統連續發送3條消息到MQ隊列中,假如耗時5ms,A 系統從接受一個請求到返迴響應給用戶,總時長是 3 + 5 = 8ms。
削峰:減少高峰時期對伺服器壓力。
消息隊列有什麼缺點
降低可用性:系統可用性降低本來系統運行好好的,現在你非要加入個消息隊列進去,那消息隊列掛了,你的系統不是涼了。因此,系統可用性會降低;
系統複雜度提高:加入了消息隊列,要多考慮很多方面的問題,比如:一致性問題、如何保證消息不被重覆消費、如何保證消息可靠性傳輸等。因此,需要考慮的東西更多,複雜性增大。
一致性問題:A系統處理完了直接返回成功了,用戶以為你這個請求就成功了;實際上是,要是BCD三個系統那裡,BD兩個系統寫庫成功了,結果C系統寫庫失敗了,咋整?你這數據就不一致了。
RabbitMQ一般用在什麼場景
服務間非同步通信
順序消費
定時任務
請求削峰
簡單說RabbitMQ有哪些角色
Broker:簡單來說就是消息隊列伺服器實體。
Exchange:消息交換機,它指定消息按什麼規則,路由到哪個隊列。
Queue:消息隊列載體,每個消息都會被投入到一個或多個隊列
Binding:綁定,它的作用就是把exchange和queue按照路由規則綁定起來。
Routing Key:路由關鍵字,exchange根據這個關鍵字進行消息投遞。
Virtual Host:vhost可以理解為虛擬broker,即mini-RabbitMQ server。
其內部均含有獨立的queue、exchange和binding等,但最最重要的是,其擁有獨立的許可權系統,可以做到 vhost 範圍的用戶控制。
當然,從RabbitMQ的全局角度,vhost可以作為不同許可權隔離的手段,一個典型的例子就是不同的應用可以跑在不同的 vhost 中。
Producer:消息生產者,就是投遞消息的程式Consumer:消息消費者,就是接受消息的程式。
Channel:消息通道,在客戶端的每個連接里,可建立多個channel,每個channel代表一個會話任務
RabbitMQ有幾種工作模式
1.simple模式(即最簡單的收發模式)
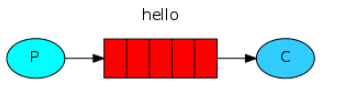
消息產生消息,將消息放入隊列消息的消費者(consumer)監聽消息隊列,如果隊列中有消息,就消費掉,消息被拿走後,自動從隊列中刪除(隱患消息可能沒有被消費者正確處理,已經從隊列中消失了,造成消息的丟失,這裡可以設置成手動的ack,但如果設置成手動ack,處理完後要及時發送ack消息給隊列,否則會造成記憶體溢出)。
2.work工作模式(資源的競爭)

消息產生者將消息放入隊列消費者可以有多個,消費者1,消費者2同時監聽同一個隊列,消息被消費。C1 C2共同爭搶當前的消息隊列內容,誰先拿到誰負責消費消息(隱患:高併發情況下,預設會產生某一個消息被多個消費者共同使用,可以設置一個開關(syncronize)保證一條消息只能被一個消費者使用)。
3.publish/subscribe發佈訂閱(共用資源)

每個消費者監聽自己的隊列;生產者將消息發給broker,由交換機將消息轉發到綁定此交換機的每個隊列,每個綁定交換機的隊列都將接收到消息。
4.routing路由模式
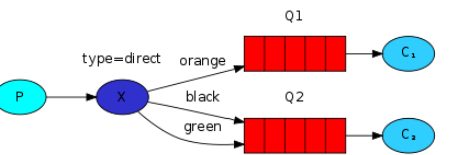
消息生產者將消息發送給交換機按照路由判斷,路由是字元串(info)當前產生的消息攜帶路由字元(對象的方法),交換機根據路由的key,只能匹配上路由key對應的消息隊列,對應的消費者才能消費消息;根據業務功能定義路由字元串從系統的代碼邏輯中獲取對應的功能字元串,將消息任務扔到對應的隊列中。
業務場景:error通知;EXCEPTION;錯誤通知的功能;傳統意義的錯誤通知;客戶通知;利用key路由,可以將程式中的錯誤封裝成消息傳入到消息隊列中,開發者可以自定義消費者,實時接收錯誤;
5.topic 主題模式(路由模式的一種)
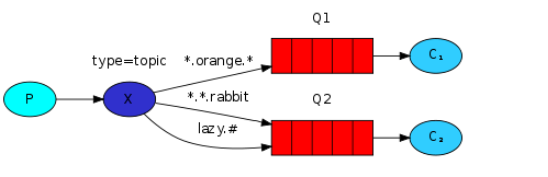
#:匹配一個或多個詞舉例:queue.#等於:queue.1/queue.qu.q.m/queue.qu.後面多個單詞匹配
*:匹配不多不少恰好1個詞舉例:queue.*等於:queue.que/queue.qu .後面一個單詞
路由功能添加模糊匹配。消息產生者產生消息,把消息交給交換機交換機根據key的規則模糊匹配到對應的隊列,由隊列的監聽消費者接收消息消費
如何保證RabbitMQ消息的順序性?
將原來的一個queue拆分成多個queue,每個queue都有一個自己的consumer。該種方案的核心是生產者在投遞消息的時候根據業務數據關鍵值(例如訂單ID哈希值對訂單隊列數取模)來將需要保證先後順序的同一類數據(同一個訂單的數據)發送到同一個queue當中。
一個queue就一個consumer,在consumer中維護多個記憶體隊列,根據業務數據關鍵值(例如訂單ID哈希值對記憶體隊列數取模)將消息加入到不同的記憶體隊列中,然後多個真正負責處理消息的線程去各自對應的記憶體隊列當中獲取消息進行消費。
消息怎麼路由?
消息提供方->路由->一至多個隊列消息發佈到交換器時,消息將擁有一個路由鍵(routing key),在消息創建時設定。
通過隊列路由鍵,可以把隊列綁定到交換器上。
消息到達交換器後,RabbitMQ會將消息的路由鍵與隊列的路由鍵進行匹配(針對不同的交換器有不同的路由規則);
常用的交換器主要分為一下三種:
fanout:如果交換器收到消息,將會廣播到所有綁定的隊列上。
direct:如果路由鍵完全匹配,消息就被投遞到相應的隊列。
topic:可以使來自不同源頭的消息能夠到達同一個隊列。
使用topic交換器時,可以使用通配符。
如何保證消息不被重覆消費?
題型分析:為什麼會出現消息重覆?
消息重覆的原因有兩個:1.生產時消息重覆,2.消費時消息重覆。
分析重覆消費原因:生產時消息重覆由於生產者發送消息給MQ,在MQ確認的時候出現了網路波動,生產者沒有收到確認,實際上MQ已經接收到了消息。這時候生產者就會重新發送一遍這條消息。
生產者中如果消息未被確認,或確認失敗,我們可以使用定時任務+(redis/db)來進行消息重試。
消費時消息重覆。消費者消費成功後,再給MQ確認的時候出現了網路波動,MQ沒有接收到確認,為了保證消息被消費,MQ就會繼續給消費者投遞之前的消息。這時候消費者就接收到了兩條一樣的消息。
解決方案:讓每個消息攜帶一個全局的唯一ID,即可保證消息的冪等性消費者獲取到消息後先根據id去查詢redis/db是否存在該消息。如果不存在,則正常消費,消費完畢後寫入redis/db。如果存在,則證明消息被消費過,直接丟棄。


