Python中的字典 Python中的字典是另一種可變容器模型,且可存儲任意類型對象。鍵值使用冒號分割,你可以看成是一串json。 常用方法 獲取字典中的值 dict[key] 如果key不存在會報錯,建議使用dict.get(key),不存在返回None 修改和新建字典值 dict[key]=va ...
Elasticsearch 是一個分散式、RESTful 風格的搜索和數據分析引擎;本文主要介紹其基本概念。
1、概述
1.1、Elasticsearch 是什麼
Elasticsearch 是一個分散式、高擴展、高實時的搜索與數據分析引擎。它能很方便的使大量數據具有搜索、分析和探索的能力。充分利用 Elasticsearch 的水平伸縮性,能使數據在生產環境變得更有價值。Elasticsearch 的實現原理主要分為以下幾個步驟,首先用戶將數據提交到 Elasticsearch 資料庫中,再通過分詞控制器去將對應的語句分詞,將其權重和分詞結果一併存入數據,當用戶搜索數據時候,再根據權重將結果排名,打分,再將返回結果呈現給用戶。
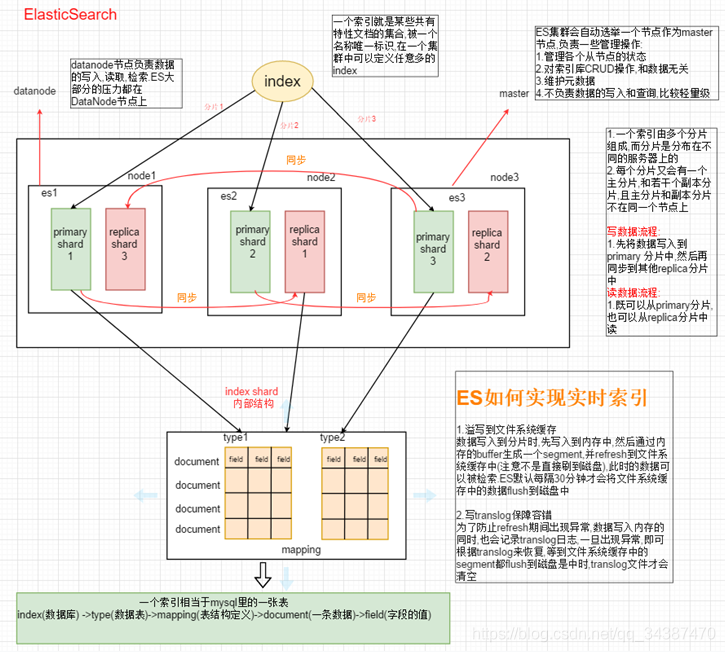
Elasticsearch 可以用於搜索各種文檔。它提供可擴展的搜索,具有接近實時的搜索,並支持多租戶。Elasticsearch 是分散式的,這意味著索引可以被分成分片,每個分片可以有 0 個或多個副本。每個節點托管一個或多個分片,並充當協調器將操作委托給正確的分片。再平衡和路由是自動完成的。相關數據通常存儲在同一個索引中,該索引由一個或多個主分片和零個或多個複製分片組成。一旦創建了索引,就不能更改主分片的數量。
1.2、Elasticsearch 索引是什麼
Elasticsearch 索引指相互關聯的文檔集合。Elasticsearch 會以 JSON 文檔的形式存儲數據。每個文檔都會在一組鍵(欄位或屬性的名稱)和它們對應的值(字元串、數字、布爾值、日期、數值組、地理位置或其他類型的數據)之間建立聯繫。
Elasticsearch 使用的是一種名為倒排索引的數據結構,這一結構的設計可以允許十分快速地進行全文本搜索。倒排索引會列出在所有文檔中出現的每個特有辭彙,並且可以找到包含每個辭彙的全部文檔。
在索引過程中,Elasticsearch 會存儲文檔並構建倒排索引,這樣用戶便可以近實時地對文檔數據進行搜索。索引過程是在索引 API 中啟動的,通過此 API 您既可向特定索引中添加 JSON 文檔,也可更改特定索引中的 JSON 文檔。
1.3、Elasticsearch 用途
Elasticsearch 在速度和可擴展性方面都表現出色,而且還能夠索引多種類型的內容,這意味著其可用於多種用例:
- 應用程式搜索
- 網站搜索
- 企業搜索
- 日誌處理和分析
- 基礎設施指標和容器監測
- 應用程式性能監測
- 地理空間數據分析和可視化
- 安全分析
- 業務分析
2、Elasticsearch 相關概念
2.1、Index(索引)
索引是具有相似結構的文檔的集合, 等同於 Solr 中的集合;每個索引有唯一的名稱, 名稱小寫。索引類似 MySQL 中 database 概念。
2.2、Document(文檔)
文檔是存儲在 ES 中的 JSON 格式的字元串, 由 field(欄位) 構成。
2.3、Field(欄位)
欄位可以是一個簡單的值(如字元串、數字、日期), 也可以是一個數組, 還可以嵌套一個對象或多個對象。欄位類似於關係資料庫中表數據的列, 每個欄位都對應一個類型. 可以指定如何分析某一欄位的值, 即對 field 指定分詞器。
2.4、Type(類型)
type 是 index 的邏輯分類, 在 ES 6.x 版本之前, 每個索引中可以定義一個或多個 type, 而在 6.X 版本之後, 一個 index 中只能定義一個 type。通常,會為具有一組共同欄位的文檔定義一個 type。
2.5、Mapping(映射)
mapping 是對欄位的定義說明,如某個欄位的數據類型、預設值、分析器、是否被索引等等;類似於 Solr 中 schema.xml 約束文件的作用。
2.6、Node(節點)
node 指的是 ES 的單個正在運行的實例。單個物理和虛擬伺服器容納多個節點,這取決於其物理資源的能力,如 RAM,存儲和處理能力。2.7、Cluster(集群)
cluster 是一個或多個 node 的集合,cluster 為整個數據提供跨所有節點的集合索引和搜索功能。2.8、Shard(分片)
單個 node 無法存儲大量的索引數據, ES 可以把一個索引分成多個分片, 分佈到不同的 node 上, 從而構成分散式索引。每個分片都是一個 Lucene 實例, 也就是說每個分片底層都有一個單獨的 Lucene 提供獨立的索引和檢索服務, 它們可以托管在集群的任一 node 上。
分片可以實現集群的水平擴展,提高系統的性能和吞吐量。2.9、Replica(副本)
可以為 shard 創建副本,提高數據的安全性。建立索引時, 系統會先將索引存儲在主分片(Primary Shard)中, 然後再將主分片中的索引複製到副本分片(Replica Shard)中。副本提高了系統的可用性和容錯性已經查詢時的吞吐量。
2.10、Elasticsearch 和 RDBMS 的對比
| Elasticsearch | RDBMS |
| Index(索引) | DataBase(資料庫) |
| Type(類型) | Table(表) |
| Document(文檔) | Row(行) |
| Field(欄位) | Column(列) |
| Mapping(映射) | Schema(約束) |
| Query DSL(ES 的查詢語言) | SQL(結構化查詢語言) |
3、Elasticsearch 欄位類型
| 欄位類型 | 說明 |
| text | 文本類型,會就行分詞處理 |
| keyword | 關鍵字類型,不就行分詞處理 |
| byte | -128~127 |
| short | -32768~32767 |
| integer | -2^31~2^31-1 |
| long | -2^63~2^63-1 |
| double | 64 位雙精度 |
| float | 32 位單精度 |
| half_float | 16 位半精度 |
| scaled_float | 底層基於 long 存儲,支持一個固定的精度因數;如果存儲浮點數 0.15,設置 scaling_fac-tor=100,則該類型會以一個整數 15 進行存儲,有效提高其存儲性能。 |
| date |
日期類型,json 對象沒有日期類型,表現形式如下: |
| boolean | 其取值為 "true"、"false"、true、false |
| binary | 二進位類型,用 base64 來表示 |
| array | 數組 |
| ip | 用於存儲 IPv4 或者 IPv6 的地址 |
| range datatype |
數據範圍類型,一個欄位表示一個範圍,具體包含如下類型: |
4、Elasticsearch 分詞器
| 分詞器 | 說明 |
| standard | 預設分詞器,按詞切分,小寫處理 |
| simple | 按照非字母切分(符號被過濾),小寫處理 |
| stop | 小寫處理,停用詞過濾(the ,a,is) |
| whitespace | 按照空格切分,不轉小寫 |
| keyword | 不分詞,直接將輸入當做輸出 |
| pattern | 正則表達式,預設 \W+ |
| ik_smart | ik 分詞器,只分一次,句子裡面的每個字只會出現一次 |
| ik_max_word | ik 分詞器,句子的字可以反覆出現。 |
5、Elasticsearch 邏輯架構圖

RESTful Style API:RESTful 風格介面。
Java(Netty):Java 客戶端。
Transport:集群與客戶端交互方式。
Disvcovery:節點發現及 master 選舉。Zen 屬於 ES 的特殊發現機制,也是 ES 的內置發現機制,它提供了兩種發現方式:單播和多播。EC2 是另外一種插件形式的發現機制。
Scripting:腳本功能,支持 mvel、js、python等。
3rd plugins:第三方插件。
Index Moudle:索引模塊。
Search Moudle:查詢模塊。
Mapping:映射信息。
River:用於其他數據源中獲取數據,該項功能以插件的形式存在,目前支持的數據源:RabbitMQ、ActiveMQ、CSV、FileSystem、JDBC、GitHub、Kafka 等;針對關係型資料庫提供了統一的 jdbc-river 來進行數據操作。
DistributedLucene Directory:Lucene 數據目錄。
Gateway:ElasticSearch 索引的持久化存儲方式。Gateway支持多種類型:本地文件系統(預設)、分散式文件系統 Hadoop 以及 AMZ 的 S3 雲存儲服務。
6、Elasticsearch 組件關係圖