
mysql服務端整體架構 主要分為兩部分,server層和存儲引擎 server層包括連接器、查詢緩存、分析器、優化器、執行器等,涵蓋mysql的大多數核心服務過功能,以及所有的內置函數,所有跨存儲引擎的功能都在這一層實現,比如存儲過程,觸發器,視圖等 存儲引擎層負責數據等存儲和讀取,其架構模式是插 ...
mysql服務端整體架構
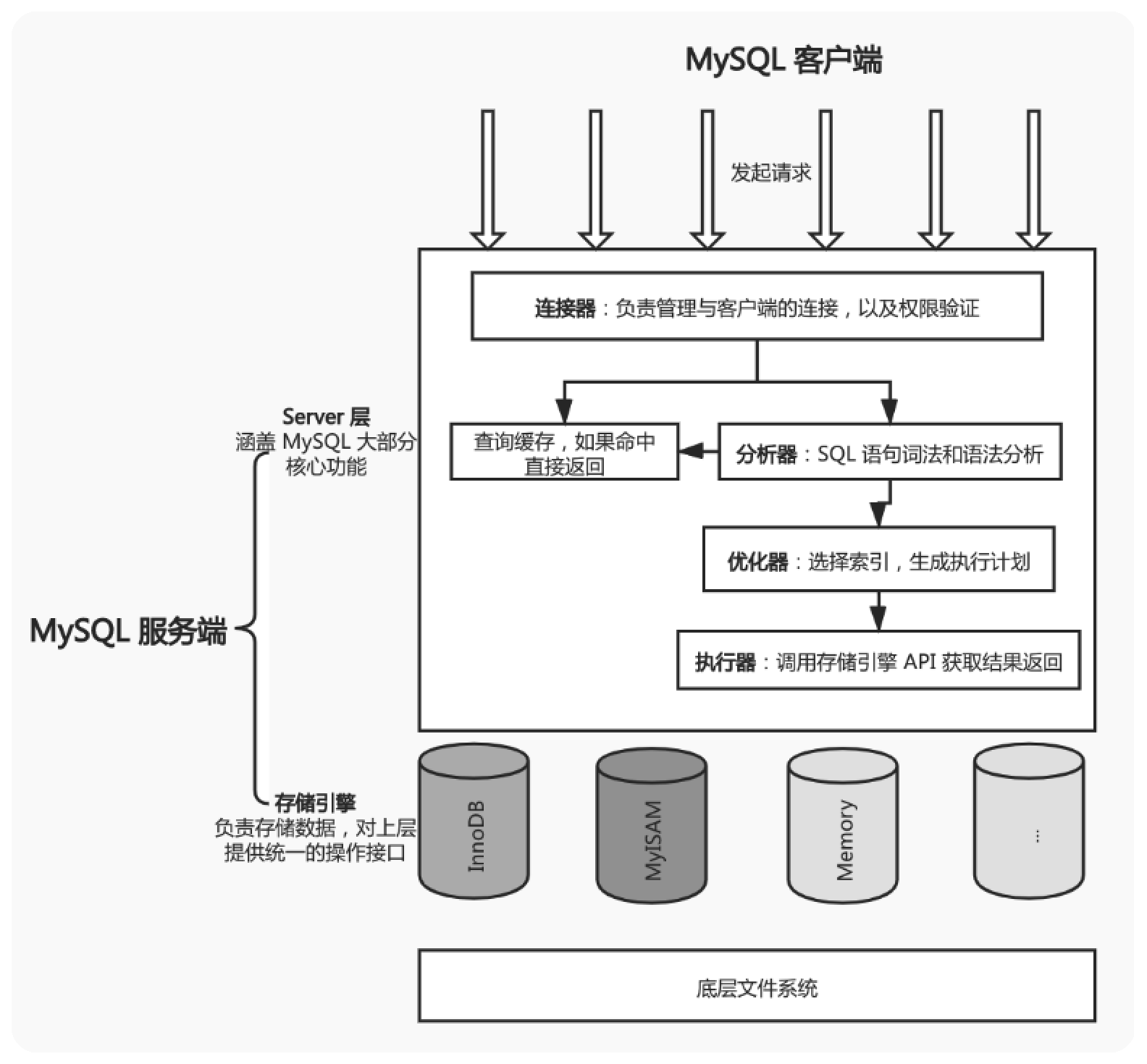
主要分為兩部分,server層和存儲引擎
- server層包括
連接器、查詢緩存、分析器、優化器、執行器等,涵蓋mysql的大多數核心服務過功能,以及所有的內置函數,所有跨存儲引擎的功能都在這一層實現,比如存儲過程,觸發器,視圖等 - 存儲引擎層負責數據等存儲和讀取,其架構模式是插件式的,支持
InnoDB、MyISAM等多個引擎。從mysql5.5.5版本開始InnoDB成為了預設引擎。
MySql查詢流程
由mysql客戶端發起請求,連接器負責與客戶端連接驗證許可權,連接成功之後開始查詢緩存(當緩存開啟時),如果命中則直接返回數據,如果沒有命中則交由分析器進行sql詞法和語法分析,然後交給優化器進行選擇索引生成執行計劃,最後交給執行器去調用存儲引擎的API獲取結果並返回
查詢緩存
當 MySQL 服務端拿到一條 SQL 查詢語句後,首先會查詢緩存,看之前是不是執行過這條語句。如果執行過,會緩存在記憶體中,這個時候直接返回之前緩存的查詢結果給客戶端即可;如果在緩存中沒有找到對應的記錄,就會繼續後面的操作,並且在最終執行完成後,將查詢結果保存到查詢緩存。
註:MySQL 8.0 版本開始將不再支持查詢緩存功能。
可以通過show variables like '%query_cache%';語句查看系統查詢緩存的設置
query_cache_type 為 OFF 表示預設關閉。你可以在配置文件中配置該值來決定是否啟用查詢緩存。
分析器
如果查詢緩存沒有啟用或者沒有命中,就開始真正執行 SQL 查詢語句了。
MySQL 會通過分析器對 SQL 語句做詞法分析,以確定到底要做什麼,比如 select 表示查詢語句,update 表示更新語句等,表名是什麼,查詢的欄位有哪些,查詢的條件是什麼。
優化器
如果 SQL 語句詞法和語法分析都沒有問題,接下來,會經由優化器生成執行計劃,這裡面主要的工作是數據表包含索引的時候,判定是否使用索引,以及使用哪些索引效率最高(掃描行數最少),我們可以在執行一個 SQL 查詢語句之前通過 explain 語句查看它的執行計劃:
執行器
根據執行計劃執行sql查詢語句時,會先驗證許可權,有相應許可權才會繼續執行,否則會報許可權錯誤
具體的查詢操作是通過存儲引擎提供的API介面完成的。執行器調用這些介面可以完成諸如讀取下一行記錄、插入記錄、更新記錄之類的日常資料庫操作,執行 SQL 查詢返回所有滿足條件的結果集也是如此。
SQL更新語句執行流程與日誌寫入
和sql查詢語句一樣,MySql客戶端提交SQL更新語句前,先要通過連接器建立連接,連接器驗證許可權等相關操作,然後交給分析器進行詞法和語法分析後由執行器負責具體的執行。(修改、刪除語句也是一樣)
當一張數據表有更新的時候,對應的查詢緩存數據就會被清空。
與查詢流程不一樣的是,更新還涉及到日誌的寫入,redo log(重做日誌)和binlog(歸檔日誌)
日誌寫入
MySql的設計者引入了WAL技術(Write-Ahead Logging),即先寫日誌,在寫磁碟。
比如InnoDB引擎,當有記錄需要更新的時候,InnoDB就會先把記錄寫到redolog裡邊,並更新記憶體,這時候更新操作就算是完成,等InnoDB空閑的時候,在將這個操作更新到磁碟裡邊。這樣做就是因為如果每次更新操作都要寫到磁碟的話,整個IO成本會非常高。
redo log
redo Log 是InnoDB引擎提供的日誌系統,bindlog可以一直追加寫入,負責資料庫全量數據的備份和恢復,資料庫集群的主從同步也是基於binlog實現的。
binlog
binlog是屬於MySql Server層面的,所有存儲引擎都可以共用它
在 InnoDB 引擎出現之前,MySQL 預設的存儲引擎是 MyISAM,那個時候為了實現數據備份和恢復,使用的是 binlog,不過 binlog 是一個歸檔日誌,不具備資料庫崩潰重啟後的數據恢復功能
兩個日誌的寫入流程
- 執行器通過 API 介面將更新數據傳遞給存儲引擎執行更新操作;
- 存儲引擎在拿到更新數據後,先將其更新到記憶體,同時將這個更新操作記錄到 redo log,此時 redo log 處於
prepare狀態,然後告知執行器執行完成了,隨時可以提交事務; - 執行器生成這個操作的 binlog,並把 binlog 寫入磁碟(寫入時機可以配置,對於事務操作而言,都是在事務提交時才會持久化寫入的,相關細節我們後面講資料庫數據一致性的時候會詳細介紹);
- 執行器調用引擎的提交事務介面,引擎把剛剛寫入的 redo log 改成
commit狀態,更新完成。

在上述步驟中,將 redo log 的寫入拆成了兩個步驟:prepare 和 commit,這就是「兩階段提交」。
如果不使用兩階段提交,會導致兩份日誌恢復的數據不一致:比如先寫 redo log,binlog 還沒有寫入,資料庫崩潰重啟;或者先寫 binlog,redo 還沒有寫入資料庫崩潰重啟,都將造成恢複數據的不一致。
而使用兩階段提交後,就可以保證兩份日誌恢復的數據一致:只有 binlog 寫入成功的情況下,才會提交 redo log,否則 redo log 處於 prepare 狀態,事務會回滾,這樣一來,就保證了數據的一致性。
本文來自博客園,作者:穎小主,轉載請註明原文鏈接:https://www.cnblogs.com/yingxiaozhu/p/16411644.html


