
導讀: 本文主要介紹了快手的精排模型實踐,包括快手的推薦系統,以及結合快手業務展開的各種模型實戰和探索,全文圍繞以下幾大方面展開: 快手推薦系統 CTR模型——PPNet 多domain多任務學習框架 短期行為序列建模 長期行為序列建模 千億特征,萬億參數模型 總結和展望 -- 01 快手推薦系統 ...

導讀: 本文主要介紹了快手的精排模型實踐,包括快手的推薦系統,以及結合快手業務展開的各種模型實戰和探索,全文圍繞以下幾大方面展開:
- 快手推薦系統
- CTR模型——PPNet
- 多domain多任務學習框架
- 短期行為序列建模
- 長期行為序列建模
- 千億特征,萬億參數模型
- 總結和展望
--
01 快手推薦系統
快手的推薦系統類似於一個信息檢索範式,只不過沒有用戶顯示query。結構為數據漏斗,候選集有百億量級的短視頻,在召回層,會召回萬級的視頻給粗排打分,再選取數百個短視頻,給精排模型打分,最後會有數十個短視頻進行重排。推薦主要是雙類或單類,快手推薦的特點是用戶比較多,會超過3.0億。我們的短視頻,每天有百億的分發量,候選的短視頻有百億之多,用戶的行為差距會非常之大,比如,有些用戶每天會刷成百上千條短視頻,有些用戶又刷得非常少。相對於電商或者新聞來說,短視頻的玩法會更豐富,用戶的興趣非常廣泛,並且是不變的。
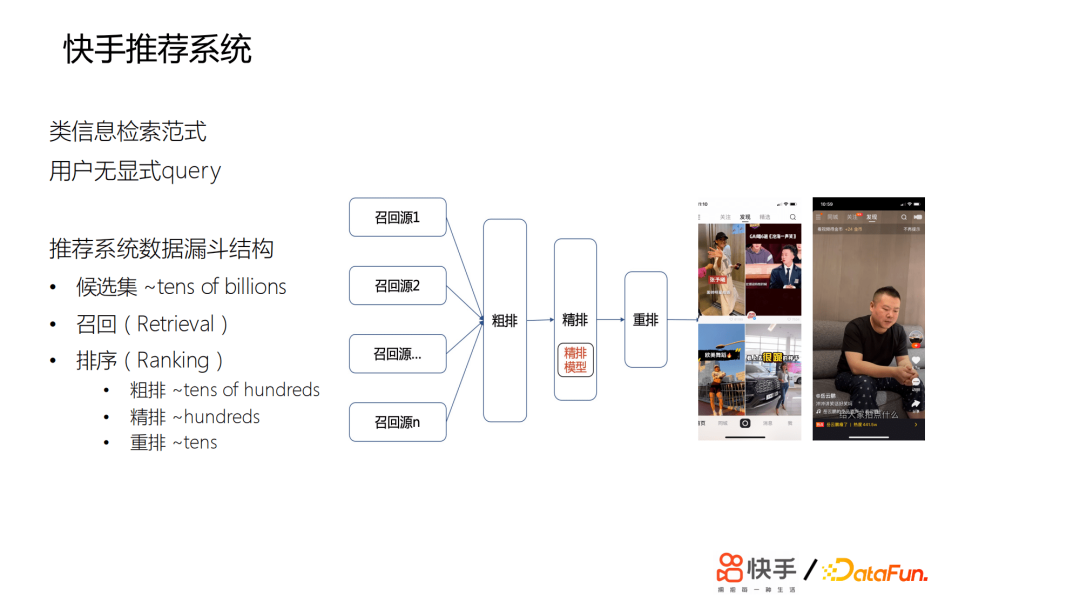
用戶的交互類型非常多,場景複雜。這裡簡單展示一下,主要有主站的雙列發現頁、主站精選、極速版發現頁,這些主要是用來幫助用戶發現可能感興趣的視頻,還有關註頁、同城頁。除了短視頻之外,還有直播、電商直播的推薦。對於整個推薦系統來說,我們最大的挑戰是如何為用戶的興趣精準建模。

--
02 CTR模型——PPNet

這是我們2019年的模型,ctr的個性化預估是推薦系統的核心,主要用來預估用戶對視頻會不會點擊,預估效果直接影響用戶體驗。
從業界的演化來看,一方面是從特征的交叉角度,另一方面是從用戶的行為序列建模來提升模型個性化。這裡DNN核心為全連接網路。
特征全局共用,主要用來捕捉全局用戶和短視頻的特征。要做到真正的千人千面,需要用戶個性化的特征更強一些。所以當時我們探索瞭如何為DNN網路增加個性化。我們嘗試了一些方法,最開始嘗試用stacking的方法,在最頂層或中間加一些user獨有的一些網路,對網路的參數,每個用戶是不同的,但是收益甚微。然後我們嘗試了另外一種方式,受LHUC的啟發,思想來源於語音識別,給每個用戶學習個性化的偏置項。
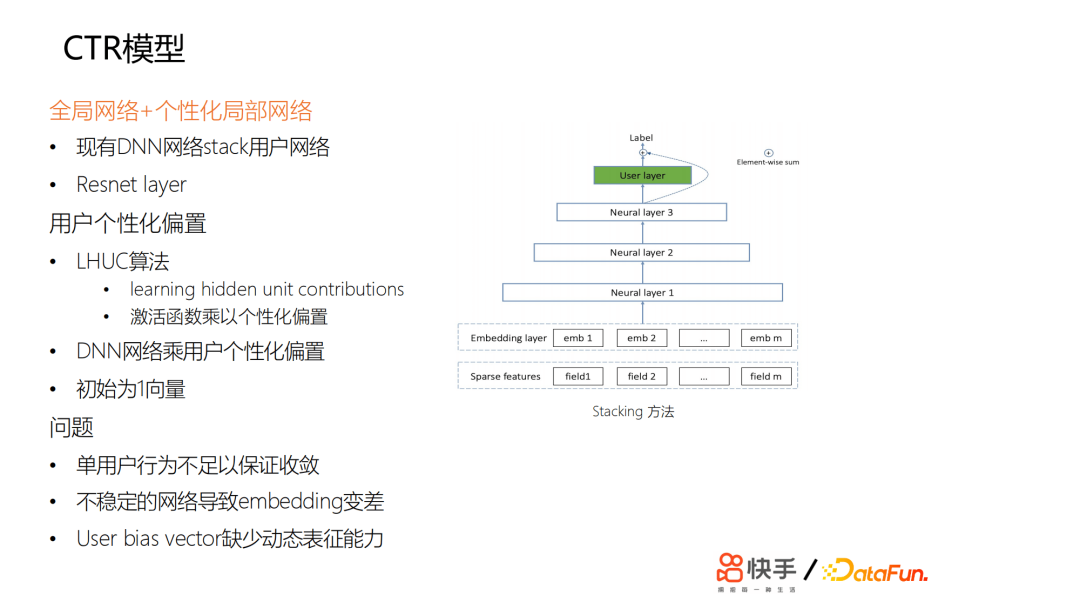
在網路輸出的激活函數那裡,設置了個性化的偏置項,可以認為是給每個用戶學了一個bias和一個vector。我們做了一些嘗試,但是基本上沒有太大的收益。
我們發現一些問題,總結來說,首先是用戶每天刷的樣本不足以讓網路的參數收斂,因為參數量相對來說比較少,這相當於是給一個用戶學一個最寬的一個id的embedding向量。
另外用戶每天都在上傳新的視頻,我們推薦的視頻,主要約束在兩天以內,所以會有一個視頻冷啟動的問題,而且基於流式訓練,會導致訓練樣本中各方面的雜訊非常大,如果是一個不穩定的網路,也會導致embedding的效果變差。如果只是簡單學一個優質的id的embedding,則缺少足夠的動態表達能力。另外,如果只是通過bp的方法傳導梯度來更新id的embedding,其修正能力非常慢。最終我們在lte的基礎上設計了一個pnet,以全局共用為基礎,進行個性化的微調;我們又設計了gate網路來擬合個性化的參數:
- 白色的部分可以認為是原來的基線。這個基線主要是訓練原來的ctr模型。
- 灰色和綠色部分是新加的,灰色部分是基於所有用戶共用的,綠色部分是門控網路,通過門控網路與灰色部分的網路來學慣用戶的個性化。
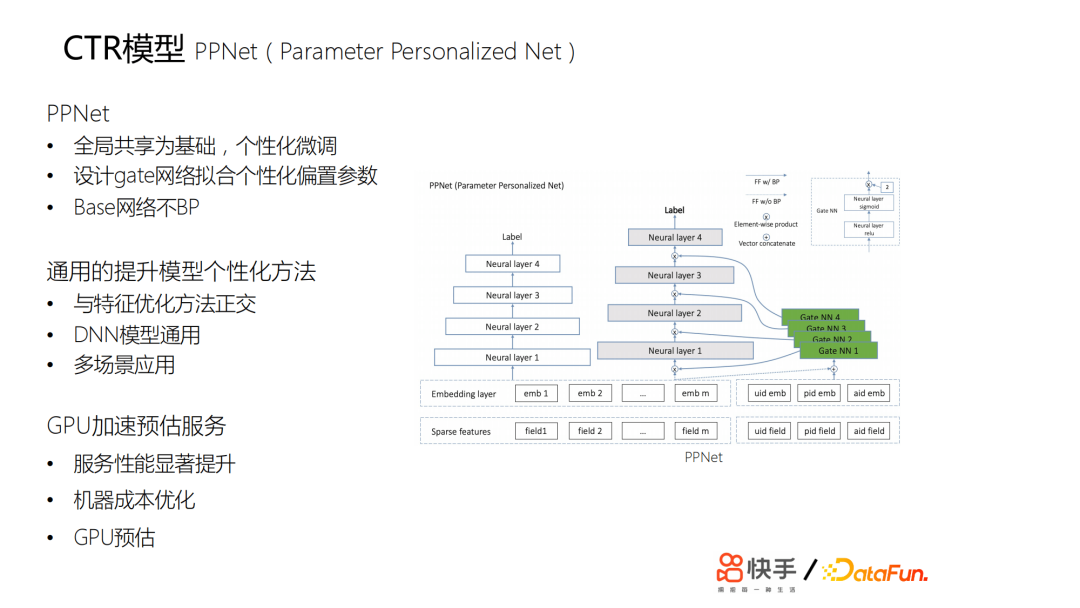
這兩部分的網路也就是ppnet的網路結構。上線後,收益非常明顯。包括所有用戶細分上提升都是非常明顯的,特別是一些行為比較稀疏的用戶,他們的提升非常大,因為他們的行為相對來說比較少,之前的兩個方案模型很難學到他們的一些特征。這套方案給我們提供了一個比較通用的提升模型個性化的方法。
我們推廣到了一些其他場景,實現多場景應用。但是這個演算法的計算量比較大,因此我們對線上的預估服務做了一次升級——原來是cpu預估,我們在2019年10月份做了gpu加速預估。
--
03 多domain多任務學習框架

快手的產品場景非常多樣,包括主站發現頁、主站精選、發現頁內流、極速版發現頁等。另一方面,人群多樣化,包括新用戶、老用戶、激活用戶等。另外,這兩個場景正交,就有幾十個目標。因此,我們要預估的目標也會非常多。這樣會存在一系列的問題,比如業務獨占模型會導致訓練資源低效、迭代低效、業務間不共用網路等。為瞭解決這些問題,我們在模型融合場景下做了多任務學習。

對於模型融合,我們做了很多工作,比如特征語義對齊,主要包括刪減無用特征,改正語義不一致特征,添加單列播放列表類特征、交叉特征;embedding空間的對齊,通過Embedding transform gate,直接學習映射關係;特征重要性對齊,這裡用到了slot gate,主要參考了前面提到的ppnet裡面的gate設計方案。在不同的場景下,不同的用戶或視頻,對於特征的重要性選擇,gate會把它約束在0~2,均值是1,動態選擇這個特征是重要還是不重要,這樣我們可以將樣本的特征做一個比較好的對齊。最後,我們做了一個多目標的mmoe,動態建模目標之間的關係,每個task tower輸入添加個性化偏置項。通過上面的工作,我們成功將線上與離線的模型融合成一套模型,全業務推全,用戶交互漲幅提升近10%,效果顯著。
--
04 短期行為序列建模
接下來介紹短期行為序列建模的工作,在2019年初,快手交互場景越來越多,同時出現了單雙列的交互體驗,單雙列業務下用戶行為序列存在差異。單列剝奪了用戶主動點的權利,用戶更多是被動來看推薦系統推薦的短視頻,因此,單列更適合作E&E。雙列的交互體驗下用戶獲得的主動性、可選擇性強,用戶的點擊歷史沒有太多的特征可以學習,用戶會不斷地釋放自己想看的內容,釋放自己的欲望,可能會一直不斷地在看相關的一些內容。我們當時做了一些嘗試,發現RNN表現不如sum pooling,其相關性大於時序性。因此我們對演算法做了四個方面的改進:
① 使用encoder部分:對歷史序列進行表徵
② 使用用戶視頻播放歷史序列
- 包含用戶更多信息(觀看時長,交互label)
- 不同業務語義一致
③ Transformer layer self attention替為target attention
- Self attention無明顯收益
- 使用當前embedding層對sequence做attention
- 簡化計算複雜度 O(n2d) -> O(nd)
④ log(now - 視頻觀看時間戳) 代替position embedding
- 最近觀看視頻更相關,log處理更合適
- 更久之前觀看視頻體現用戶長期興趣分佈
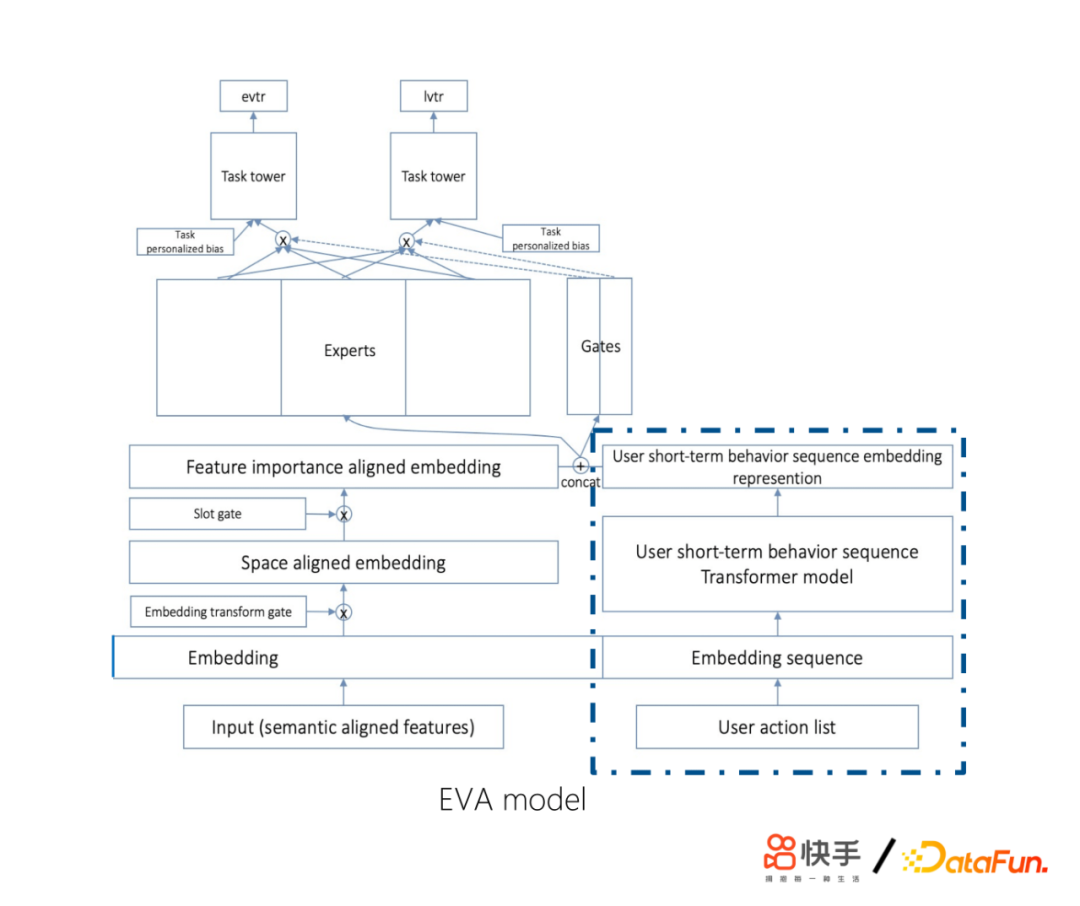
首先,使用encoder部分對歷史序列進行表徵。其次,使用用戶視頻播放歷史序列,因為裡面包含用戶更多信息(觀看時長、交互label)。另外,將Transformer layer self attention替換為target attention,主要是self attention無明顯收益,然後使用當前embeding層對sequence做attention,因為我們認為對用戶的行為歷史作為監測的時候,不應該只看要推薦的這個視頻,我們還會關註這是一個什麼用戶,這個用戶的上下文信息是非常有用的。最後,使用log(現在時間-視頻觀看時間)代替position embedding,因為最近觀看視頻更相關,log處理更合適。上線之後,取得了非常大的收益。
--
05 長期行為序列建模
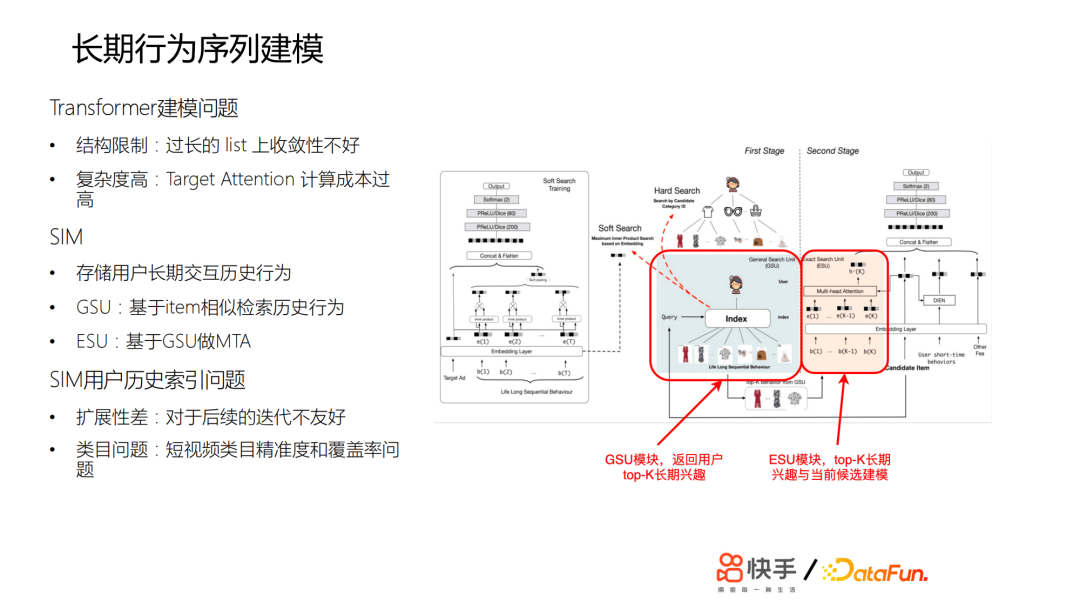
推薦系統擁有短期記憶,容易導致信息繭房或者出現多樣性不足的一些問題。但是在長期行為建模的時候又遇到了各種問題,比如:Transformer建模問題,SIM用戶歷史索引問題等。Transformer建模容易出現結構限制,模型在過長的list上收斂性不好。另外,模型複雜度高,Target Attention計算成本也會很高。SIM用戶歷史索引的擴展性差,對於後續的迭代不友好,而且對於短視頻類目精準度和覆蓋率也有問題。為了能夠捕捉到用戶不同程度的興趣偏好,我們迭代了兩個版本模型,作了很多探索和改進。
下麵介紹快手在長期行為序列建模的工作。
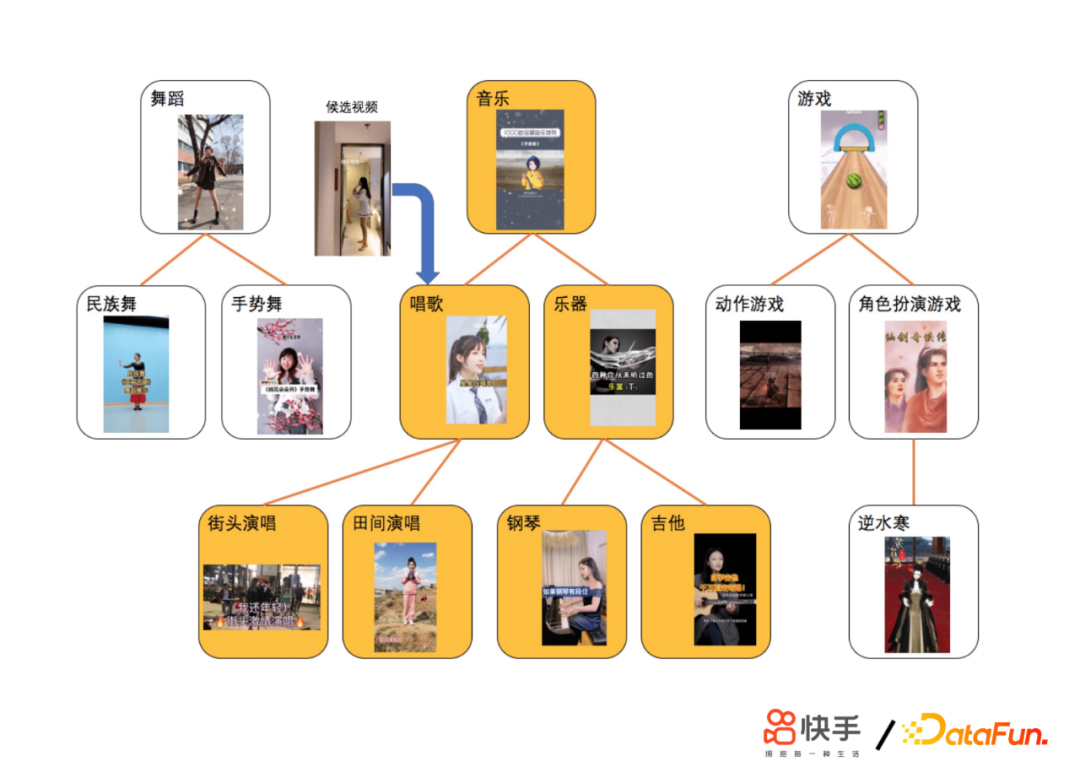
- 第一個版本方案V1.0(基於Tag檢索)
為了應對上面提到的一些問題,我們採用了獨立存儲方案,依托AEP高密度存儲設備直接存儲用戶超長行為歷史;進一步完善類目體系;GSU檢索採用回溯補全演算法,最大路徑匹配的演算法衡量相似度;ESU採用短時。關於Transformer方案,難點在於計算量增加,因此我們進行了演算法優化;合併相同Tag候選視頻的搜索過程;提前建立類目倒排鏈,簡化搜索流程;成本優化,利用線上 GPU 推理伺服器的閑置 CPU 資源。通過這些嘗試,我們做到了讓SIM演算法首次在短視頻推薦落地;在業界首次覆蓋用戶歷史至年,這是數萬級別的;收益巨大,建立了護城河;擴展到了其他場景。
- V2.0(基於Embedding距離檢索)
後面又做了第二個版本,基於視頻內容embedding的聚類。採用GSU檢索演算法:優先聚類內視頻;最近聚類補全;近似做了餘弦相似度檢索。
其次,又節省了餘弦相似度計算量。通過這些工作,我們取得了一些成果:建立了快手特色的長期行為建模機制;收益巨大,建立了護城河;擴展到了其他場景。
經過這兩版的迭代,整體效果提升明顯,人均app使用時長提升顯著,其中我們的工作做了非常多的貢獻。
--
06 千億特征,萬億參數模型
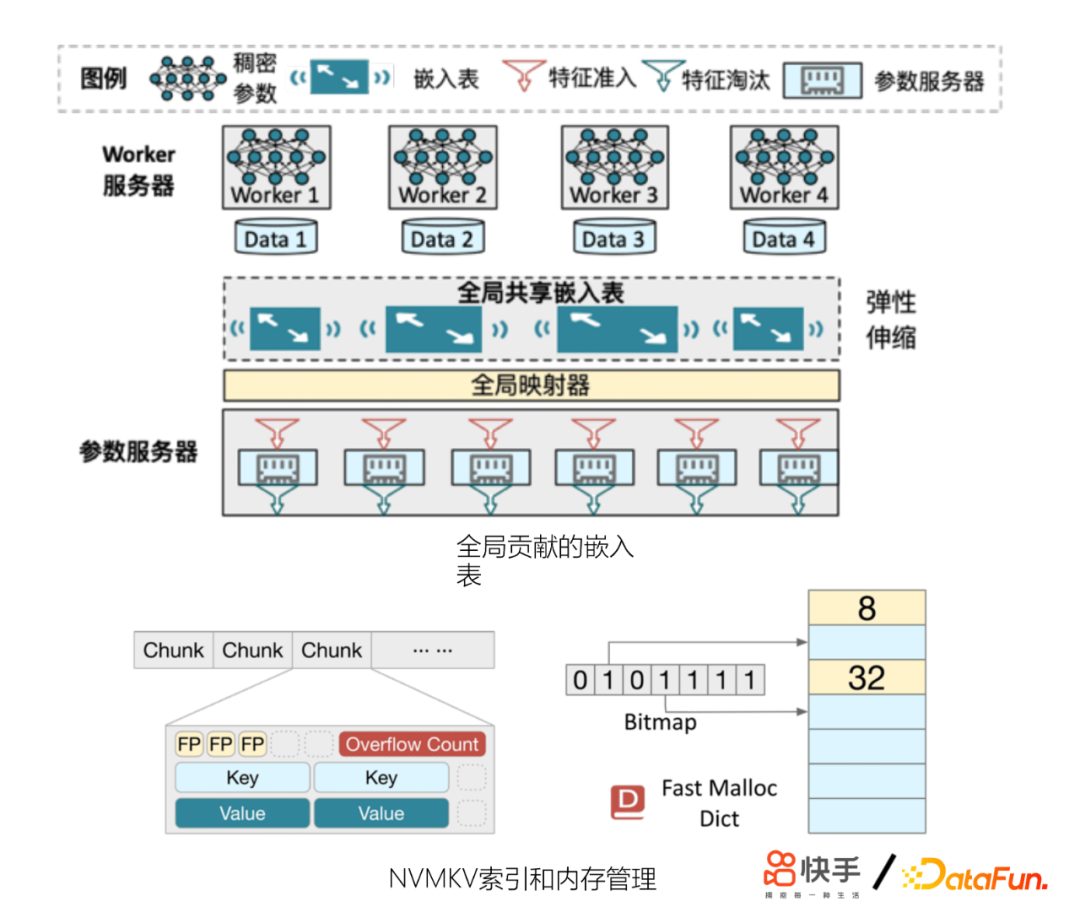
另外,我們發現模型的特征量還會制約模型精排的效果。模型收斂不穩定,模型更容易逐出低頻特征、冷啟動效果變差等。為此,我們在工程上做了一些優化,也起到了非常好的收益。主要包括:
- 改進參數伺服器(GSET)
- 更好地控制記憶體使用
- 定製feature score淘汰策略
- 效果優於LFU,LRU等淘汰策略
- 結合新的硬體:非易失記憶體(Intel AEP)
- 底層KV引擎NVMKV來支撐GSET
--
07 總結和展望
對於未來優化的重點,我們會放在模型融合,多任務學習方向。另外用戶長短期興趣怎樣更好得建模和融合,以及用戶的留存建模也是我們未來優化的重點。
今天的分享就到這裡,謝謝大家。
本文首發於微信公眾號“DataFunTalk”。

