
一、概述 Scala是一門多範式的編程語言,一種類似java的編程語言 ,設計初衷是實現可伸縮的語言 、並集成面向對象編程和函數式編程的各種特性。Spark就是使用Scala編寫的。因此為了更好的學習大數據開發, 需要掌握Scala這門語言,當然Spark的興起,也帶動Scala語言的發展!官方文檔 ...
fork在英文中是“分叉”的意思。為什麼取這個名字呢?因為一個進程在運行中,如果使用了fork函數,就產生了另一個進程,於是進程就“分叉”了,所以這個名字取得很形象。下麵就看看如何具體使用fork函數,這段程式演示了使用fork的基本框架。 函數聲明: pid_t fork(); fork函數用於產生一個新的進程,函數返回值pid_t是一個整數,在父進程中,返回值是子進程編號,在子進程中,返回值是0。
#include <stdio.h> #include <sys/types.h> #include <unistd.h> int main() { printf("本程式的進程編號是:%d\n",getpid()); int ipid=fork(); sleep(1); // sleep等待進程的生成。 printf("pid=%d\n",ipid); if (ipid!=0) printf("父進程編號是:%d\n",getpid()); else printf("子進程編號是:%d\n",getpid()); sleep(30); // 是為了方便查看進程在shell下用ps -ef|grep book252查看本進程的編號。 }從 fork() 這個函數開始出現後, 便創建了子進程,並且子進程和父進程一樣從fork(這個函數一起執行下去,也就是說從fork()開始的下麵所有代碼分別被父 進程和子進程都執行了一次,如果沒有條件判斷語句判別fork()的返回值,將無法分別子父進程,根據fork()的返回值可以令子父進程跳過或執行某條語句
運行結果
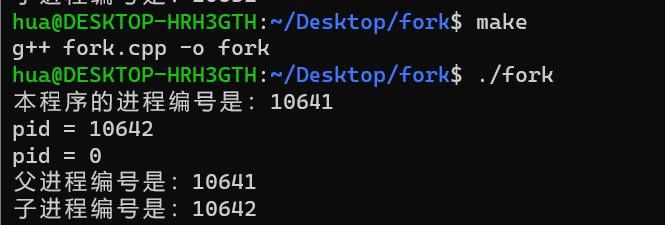
初學者可能用點接受不了現實。
1)一個函數(fork)返回了兩個值?
2)if和else中的代碼能同時被執行?
那麼調用這個fork函數時發生了什麼呢?fork函數創建了一個新的進程,新進程(子進程)與原有的進程(父進程)一模一樣。子進程和父進程使用相同的代碼段;子進程拷貝了父進程的堆棧段和數據段。子進程一旦開始運行,它複製了父進程的一切數據,然後各自運行,相互之間沒有影響。
fork函數對返回值做了特別的處理,調用fork函數之後,在子程式中fork的返回值是0,在父進程中fork的返回是子進程的編號,程式員可以通過fork的返回值來區分父進程和子進程,然後再執行不同的代碼。
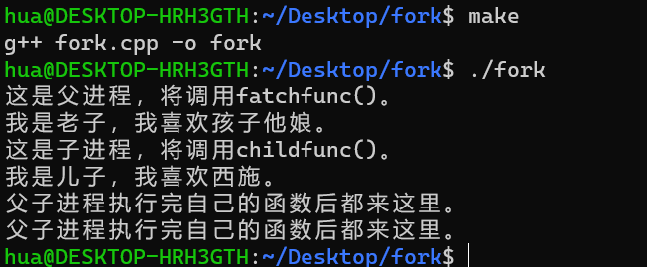
#include <stdio.h> #include <sys/types.h> #include <unistd.h> #include <stdio.h> #include <sys/types.h> #include <unistd.h> void fatchfunc() // 父進程流程的主函數 { printf("我是老子,我喜歡孩子他娘。\n"); } void childfunc() // 子進程流程的主函數 { printf("我是兒子,我喜歡西施。\n"); } int main() { if (fork() > 0) { printf("這是父進程,將調用fatchfunc()。\n"); fatchfunc(); } else { printf("這是子進程,將調用childfunc()。\n"); childfunc(); } sleep(1); printf("父子進程執行完自己的函數後都來這裡。\n"); sleep(1); }
運行結果:
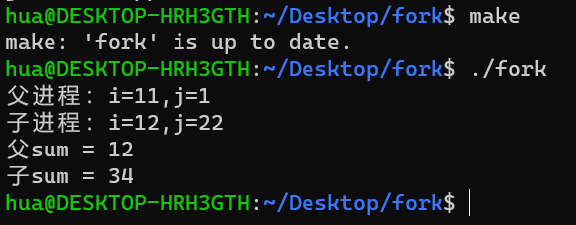
在上文上已提到過,子進程拷貝了父進程的堆棧段和數據段,也就是說,在父進程中定義的變數子進程中會複製一個副本,fork之後,子進程對變數的操作不會影響父進程,父進程對變數的操作也不會影響子進程。
#include <stdio.h> #include <sys/types.h> #include <unistd.h> int i=10; int main() { int j=20; if (fork()>0) //從 fork() 這個函數開始出現後, //便創建了子進程並且和父進程一樣從fork() //這個函數一起執行下去,也就是說從fork()開始的下麵所有代碼分別被父///進程和子進程都執行了一次,如果沒有條件判斷語句判別fork()的返回/////值,將無法分別子父進程,根據fork()的返回值可以令子父進程跳過或執///行某條語句 { //如果fork大於零,證明是父進程,即執行下麵的語句 i=11;j=1; sleep(1); printf("父進程:i=%d,j=%d\n",i,j); int sum = i + j; printf("父sum = %d\n",sum); } else { //如果fork小於零,證明是子進程,執行下麵的語句 i=12;j=22; sleep(1); printf("子進程:i=%d,j=%d\n",i,j); printf("子sum = %d\n",i+j); } }從 fork() 這個函數開始出現後,便創建了子進程,並且子進程和父進程一樣從fork(這個函數一起執行下去,也就是說從fork()開始的下麵所有代碼分別被父 進程和子進程都執行了一次,如果沒有條件判斷語句判別fork()的返回值,將無法分別子父進程,根據fork()的返回值可以令子父進程跳過或執行某條語句
運行結果
作者:碼農有道
作業:
(1)編寫一個多進程程式,驗證子進程是複製父進程的記憶體變數,還是父子進程共用記憶體變數?
複製記憶體變數
2)編寫一個示常式序,由父進程生成10個子進程,在子進程中顯示它是第幾個子進程和子進程本身的進程編號。
#include <stdio.h> #include <sys/types.h> #include <unistd.h> int main() { int i = 0; while (i < 10) { if (fork() > 0) { i++; continue; //父進程回到while(迴圈), } else { printf("子進程第%d個,pid = %d\n", i, getpid()); break; } } sleep(10); return 0; }
運行結果


3)編寫示常式序,由父進程生成子進程,子進程再生成孫進程,共生成第10代進程,在各級子進程中顯示它是第幾代子進程和子進程本身的進程編號。
如圖
#include <stdio.h> #include <sys/types.h> #include <unistd.h> int main() { int i = 0; //全局變數,計數器,計算第幾代子進程 while (i < 10) { if (fork()== 0) { i++; continue; } else { printf("第%d代子進程,pid = %d\n", i, getpid()); 第 0 代子進程是第一個父進程 break; } } sleep(10); return 0; }
運行結果:

子進程是下一個子進程的父進程

4)利用儘可能少的代碼快速fork出更多的進程,試試看能不能把linux系統搞死。
#include <stdio.h> #include <sys/types.h> #include <unistd.h> int main() { int i = 0; //全局變數,計數器,計算第幾代子進程 while (i < 10) { if (fork()>0) { fork(); } } printf("pid=%d",getpid()); return 0; }

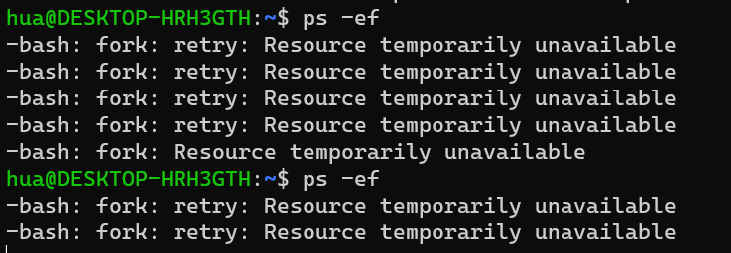
5)ps -ef |grep book251命令是ps和grep兩個系統命令的組合,各位查一下資料,瞭解一下grep命令的功能,對程式員來,grep是經常用到的命令。
https://blog.csdn.net/weixin_52273136/article/details/110451596
來源:C語言技術網(www.freecplus.net)
作者:碼農有道


