
一、概述 複合事件處理(簡稱Complex Event Processing:CEP)是一種基於動態環境中事件流的分析技術,事件在這裡通常是有意義的狀態變化,通過分析事件間的關係,利用過濾、關聯、聚合等技術,根據事件間的時序關係和聚合關係制定檢測規則,持續地從事件流中查詢出符合要求的事件序列,最終分 ...
目錄
一、概述
複合事件處理(簡稱
Complex Event Processing:CEP)是一種基於動態環境中事件流的分析技術,事件在這裡通常是有意義的狀態變化,通過分析事件間的關係,利用過濾、關聯、聚合等技術,根據事件間的時序關係和聚合關係制定檢測規則,持續地從事件流中查詢出符合要求的事件序列,最終分析得到更複雜的複合事件。官方文檔
特征
- 目標:從有序的簡單事件流中發現一些高階特征;
- 輸入:一個或多個簡單事件構成的事件流;
- 處理:識別簡單事件之間的內在聯繫,多個符合一定規則的簡單事件構成複雜事件;
- 輸出:滿足規則的複雜事件。

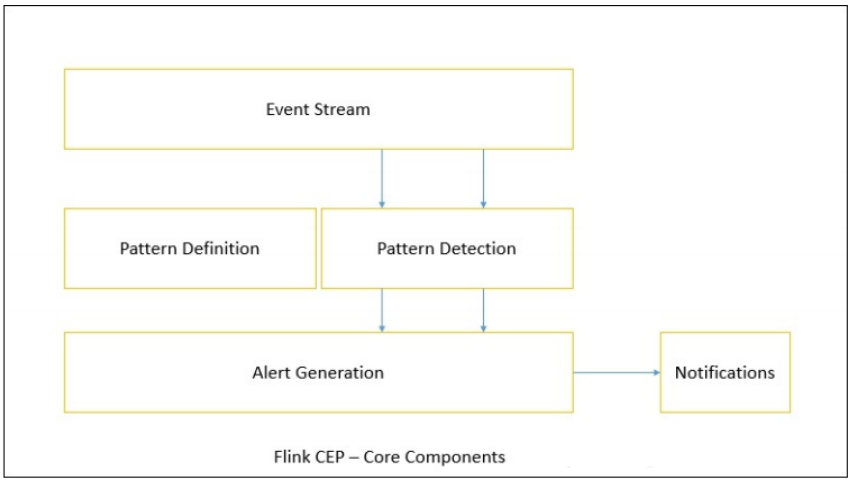
二、核心組件
Flink為CEP提供了專門的Flink CEP library,它包含如下組件:
Event Stream、Pattern定義、Pattern檢測和生成Alert。
首先,開發人員要在DataStream流上定義出模式條件,之後Flink CEP引擎進行模式檢測,必要時生成警告。
三、Pattern API
處理事件的規則,被叫作模式(Pattern)。Flink CEP提供了Pattern API用於對輸入流數據進行複雜事件規則定義,用來提取符合規則的事件序列。模式大致分為三類:
1)個體模式(Individual Patterns)
組成複雜規則的每一個單獨的模式定義,就是個體模式。個體模式可以是一個單例或者迴圈模式。單例模式只接受一個事件,迴圈模式可以接受多個事件。
1、量詞
在FlinkCEP中,你可以通過這些方法指定迴圈模式:
pattern.oneOrMore(),指定期望一個給定事件出現一次或者多次的模式;pattern.times(#ofTimes),指定期望一個給定事件出現特定次數的模式,可以在一個個體模式後追加量詞,也就是指定迴圈次數,更多量詞介紹請看下麵示例:
對一個命名為start的模式,以下量詞是有效的:
// 期望出現4次
start.times(4)
// 期望出現0或者4次
start.times(4).optional()
// 期望出現2、3或者4次
start.times(2, 4)
// 期望出現2、3或者4次,並且儘可能的重覆次數多
start.times(2, 4).greedy()
// 期望出現0、2、3或者4次
start.times(2, 4).optional()
// 期望出現0、2、3或者4次,並且儘可能的重覆次數多
start.times(2, 4).optional().greedy()
// 期望出現1到多次
start.oneOrMore()
// 期望出現1到多次,並且儘可能的重覆次數多
start.oneOrMore().greedy()
// 期望出現0到多次
start.oneOrMore().optional()
// 期望出現0到多次,並且儘可能的重覆次數多
start.oneOrMore().optional().greedy()
// 期望出現2到多次
start.timesOrMore(2)
// 期望出現2到多次,並且儘可能的重覆次數多
start.timesOrMore(2).greedy()
// 期望出現0、2或多次
start.timesOrMore(2).optional()
// 期望出現0、2或多次,並且儘可能的重覆次數多
start.timesOrMore(2).optional().greedy()
2、條件
對每個模式你可以指定一個條件來決定一個進來的事件是否被接受進入這個模式,指定判斷事件屬性的條件可以通過
pattern.where()、pattern.or()或者pattern.until()方法。這些可以是IterativeCondition或者SimpleCondition。按不同的調用方式,可以分成以下幾類:
- 簡單條件:這種類型的條件擴展了前面提到的IterativeCondition類,它決定是否接受一個事件只取決於事件自身的屬性。
start.where(event => event.getName.startsWith("foo"))
// 最後,你可以通過pattern.subtype(subClass)方法限制接受的事件類型是初始事件的子類型。
start.subtype(classOf[SubEvent]).where(subEvent => ... /* 一些判斷條件 */)
- 組合條件:這適用於任何條件,你可以通過依次調用where()來組合條件。 最終的結果是每個單一條件的結果的邏輯AND。如果想使用OR來組合條件,你可以像下麵這樣使用or()方法。
pattern.where(event => ... /* 一些判斷條件 */).or(event => ... /* 一些判斷條件 */)
- 停止條件:如果使用迴圈模式(oneOrMore()和oneOrMore().optional()),建議使用.until()作為停止條件,以便清理狀態。
pattern.oneOrMore().until(event => ... /* 替代條件 */)
- 迭代條件:這是最普遍的條件類型。使用它可以指定一個基於前面已經被接受的事件的屬性或者它們的一個子集的統計數據來決定是否接受時間序列的條件。
// 下麵是一個迭代條件的代碼,它接受"middle"模式下一個事件的名稱開頭是"foo", 並且前面已經匹配到的事件加上這個事件的價格小於5.0。 迭代條件非常強大,尤其是跟迴圈模式結合使用時。
middle.oneOrMore()
.subtype(classOf[SubEvent])
.where(
(value, ctx) => {
lazy val sum = ctx.getEventsForPattern("middle").map(_.getPrice).sum
value.getName.startsWith("foo") && sum + value.getPrice < 5.0
}
)
更多模式操作請看官網文檔
2)組合模式(Combining Patterns,也叫模式序列)
模式序列由一個初始模式作為開頭,如下所示:
val start : Pattern[Event, _] = Pattern.begin("start")
1、事件之間的連續策略
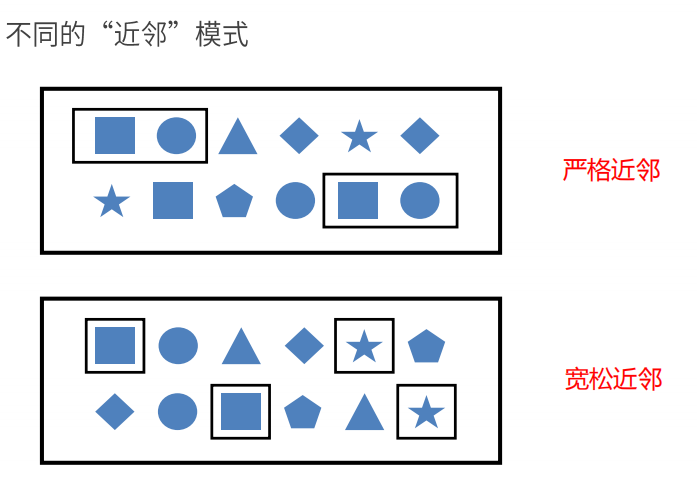
-
嚴格連續(嚴格近鄰): 期望所有匹配的事件嚴格的一個接一個出現,中間沒有任何不匹配的事件。
next() -
鬆散連續(寬鬆近鄰): 忽略匹配的事件之間的不匹配的事件。
followedBy() -
不確定的鬆散連續(非確定性寬鬆近鄰): 更進一步的鬆散連續,允許忽略掉一些匹配事件的附加匹配。
followedByAny()
除了以上模式序列外,還可以定義“不希望出現某種近鄰關係”:
notNext():如果不想後面直接連著一個特定事件notFollowedBy():如果不想一個特定事件發生在兩個事件之間的任何地方。
【溫馨提示】①所有模式序列必須以.begin()開始;②模式序列不能以.notFollowedBy()結束;③“not”類型的模式不能被optional所修飾;④可以為模式指定時間約束,用來要求在多長時間內匹配有效。
// 嚴格連續
val strict: Pattern[Event, _] = start.next("middle").where(...)
// 鬆散連續
val relaxed: Pattern[Event, _] = start.followedBy("middle").where(...)
// 不確定的鬆散連續
val nonDetermin: Pattern[Event, _] = start.followedByAny("middle").where(...)
// 嚴格連續的NOT模式
val strictNot: Pattern[Event, _] = start.notNext("not").where(...)
// 鬆散連續的NOT模式
val relaxedNot: Pattern[Event, _] = start.notFollowedBy("not").where(...)
也可以為模式定義一個有效時間約束。 例如,你可以通過
pattern.within()方法指定一個模式應該在10秒內發生。 這種時間模式支持處理時間和事件時間。
【溫馨提示】一個模式序列只能有一個時間限制。如果限制了多個時間在不同的單個模式上,會使用最小的那個時間限制。
next.within(Time.seconds(10))
2、迴圈模式中的連續性
對於迴圈模式(例如
oneOrMore()和times())),預設是鬆散連續。如果想使用嚴格連續,你需要使用consecutive()方法明確指定, 如果想使用不確定鬆散連續,你可以使用allowCombinations()方法。
-
嚴格連續:{a b3 c} – "b1"之後的"d1"導致"b1"被丟棄,同樣"b2"因為"d2"被丟棄。
-
鬆散連續:{a b1 c},{a b1 b2 c},{a b1 b2 b3 c},{a b2 c},{a b2 b3 c},{a b3 c} - "d"都被忽略了。
-
不確定鬆散連續:{a b1 c},{a b1 b2 c},{a b1 b3 c},{a b1 b2 b3 c},{a b2 c},{a b2 b3 c},{a b3 c} - 註意{a b1 b3 c},這是因為"b"之間是不確定鬆散連續產生的。
3)模式組(Group of Pattern)
也可以定義一個模式序列作為begin,followedBy,followedByAny和next的條件。這個模式序列在邏輯上會被當作匹配的條件, 並且返回一個
GroupPattern,可以在GroupPattern上使用oneOrMore(),times(#ofTimes), times(#fromTimes, #toTimes),optional(),consecutive(),allowCombinations()。
val start: Pattern[Event, _] = Pattern.begin(
Pattern.begin[Event]("start").where(...).followedBy("start_middle").where(...)
)
// 嚴格連續
val strict: Pattern[Event, _] = start.next(
Pattern.begin[Event]("next_start").where(...).followedBy("next_middle").where(...)
).times(3)
// 鬆散連續
val relaxed: Pattern[Event, _] = start.followedBy(
Pattern.begin[Event]("followedby_start").where(...).followedBy("followedby_middle").where(...)
).oneOrMore()
// 不確定鬆散連續
val nonDetermin: Pattern[Event, _] = start.followedByAny(
Pattern.begin[Event]("followedbyany_start").where(...).followedBy("followedbyany_middle").where(...)
).optional()
更多模式操作,請看官方文檔
匹配後跳過策略
對於一個給定的模式,同一個事件可能會分配到多個成功的匹配上。為了控制一個事件會分配到多少個匹配上,你需要指定跳過策略AfterMatchSkipStrategy。 有五種跳過策略,如下:
NO_SKIP: 每個成功的匹配都會被輸出。SKIP_TO_NEXT: 丟棄以相同事件開始的所有部分匹配。SKIP_PAST_LAST_EVENT: 丟棄起始在這個匹配的開始和結束之間的所有部分匹配。SKIP_TO_FIRST: 丟棄起始在這個匹配的開始和第一個出現的名稱為PatternName事件之間的所有部分匹配。SKIP_TO_LAST: 丟棄起始在這個匹配的開始和最後一個出現的名稱為PatternName事件之間的所有部分匹配。
【溫馨提示】當使用
SKIP_TO_FIRST和SKIP_TO_LAST策略時,需要指定一個合法的PatternName。
四、Pattern檢測
在指定了要尋找的模式後,該把它們應用到輸入流上來發現可能的匹配了。為了在事件流上運行你的模式,需要創建一個PatternStream。 給定一個輸入流input,一個模式pattern和一個可選的用來對使用事件時間時有同樣時間戳或者同時到達的事件進行排序的比較器comparator, 你可以通過調用如下方法來創建PatternStream:
val input : DataStream[Event] = ...
val pattern : Pattern[Event, _] = ...
var comparator : EventComparator[Event] = ... // 可選的
val patternStream: PatternStream[Event] = CEP.pattern(input, pattern, comparator)
五、Flink CEP應用場景
- 風險控制
對用戶異常行為模式進行實時檢測,當一個用戶發生了不該發生的行為,判定這個用戶是不是有違規操作的嫌疑。
- 策略營銷
用預先定義好的規則對用戶的行為軌跡進行實時跟蹤,對行為軌跡匹配預定義規則的用戶實時發送相應策略的推廣。
- 運維監控
靈活配置多指標、多依賴來實現更複雜的監控模式。
六、安裝Kafka(window)
1)下載kafka
下載地址:https://kafka.apache.org/downloads.html

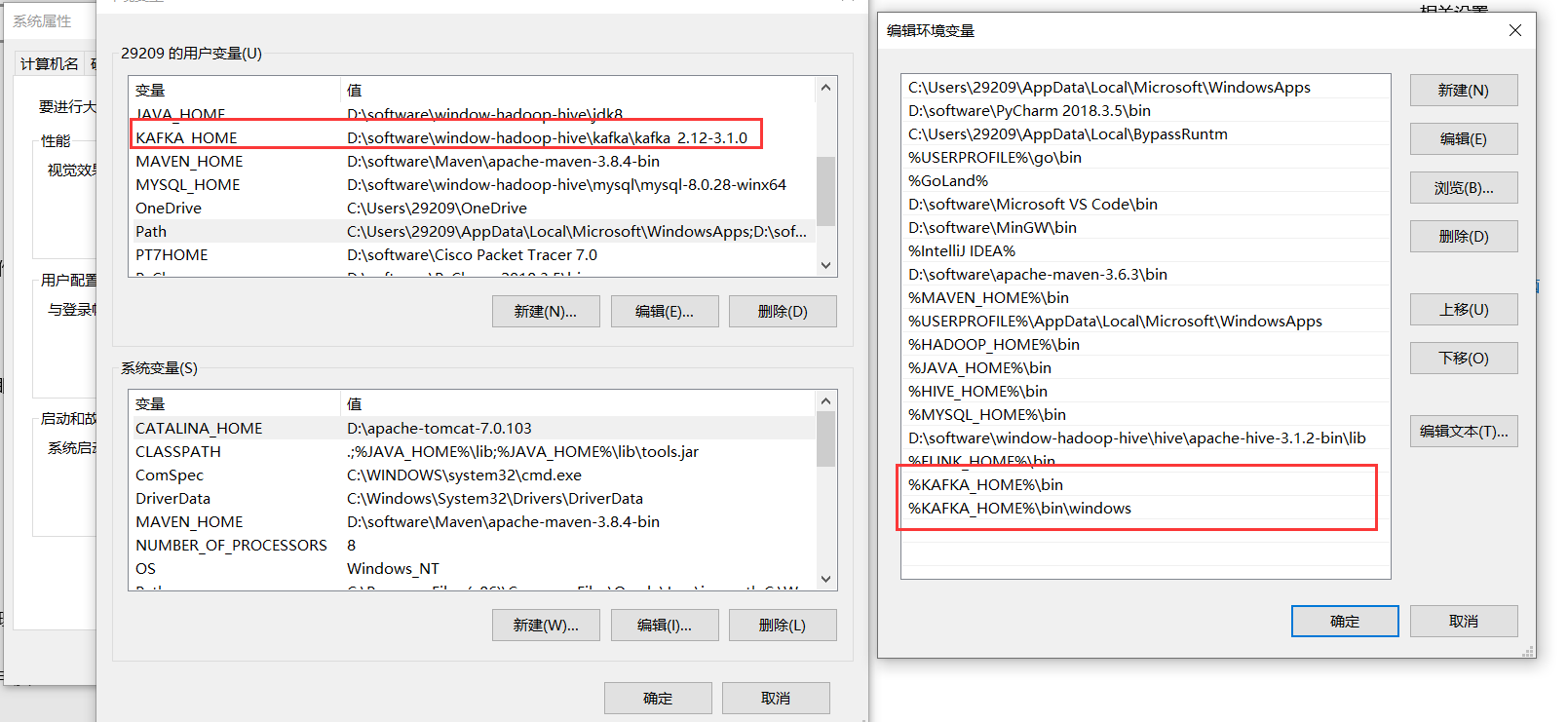
2)配置環境變數
3)創建相關文件
%KAFKA_HOME%\logs
%KAFKA_HOME%\data\zookeeper
4)修改配置
%KAFKA_HOME%\config\zookeeper.properties
###%KAFKA_HOME%換成具體目錄
dataDir=%KAFKA_HOME%\data\zookeeper
%KAFKA_HOME%\config\server.properties
###%KAFKA_HOME%換成具體目錄
log.dirs=%KAFKA_HOME%\logs
5)啟動zookeeper和kafka服務
$ d:
$ cd %KAFKA_HOME%
啟動zookeeper服務(必須先起zookeeper服務再起kafka服務)
.\bin\windows\kafka-server-start.bat .\config\server.properties

【問題】The input line is too long. The syntax of the command is incorrect.
【原因與解決方案】是由於kafka安裝目錄太深,所以這裡就直接把kafka放在D盤目錄下,記得把上面的環境變數和配置也得改一下,重新啟動服務
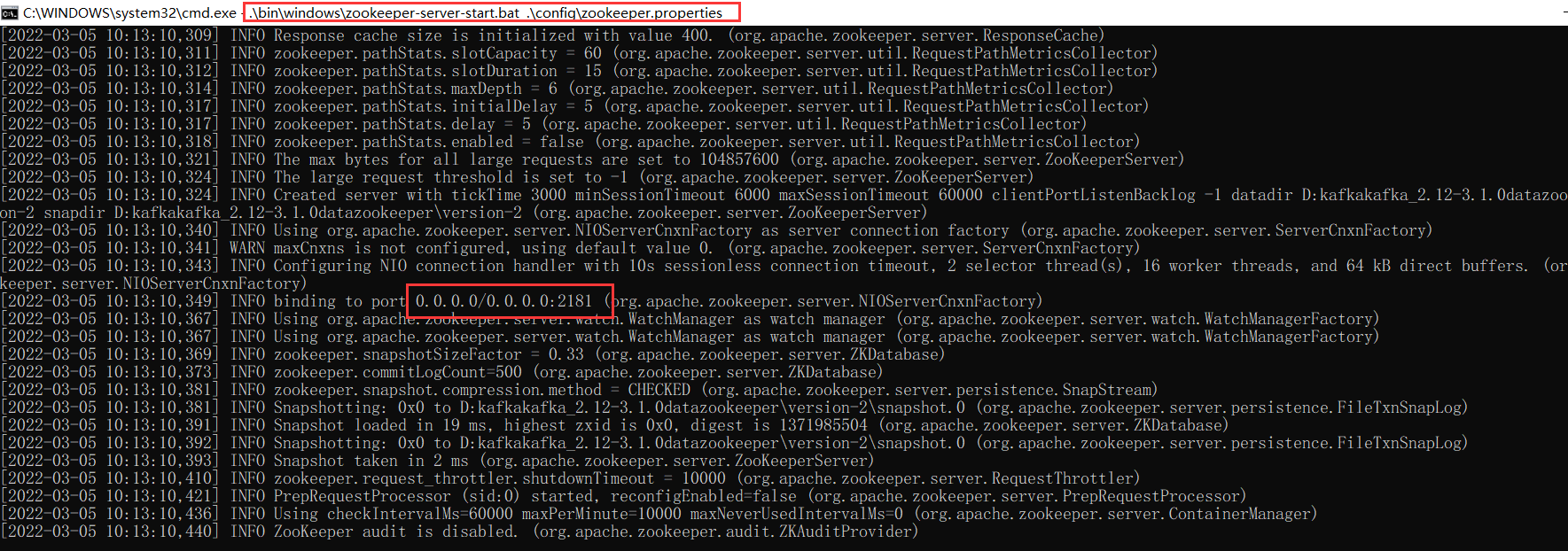
- 啟動zookeeper服務
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
###查看服務埠
netstat -ano|findstr 2181
### 參數詳解
# -a 顯示所有連接和偵聽埠。
# -n 以數字形式顯示地址和埠號。
# -o 顯示擁有的與每個連接關聯的進程 ID。

- 啟動Kafka服務
.\bin\windows\kafka-server-start.bat .\config\server.properties
###查看服務埠
netstat -ano|findstr 9092
### 參數詳解
# -a 顯示所有連接和偵聽埠。
# -n 以數字形式顯示地址和埠號。
# -o 顯示擁有的與每個連接關聯的進程 ID。
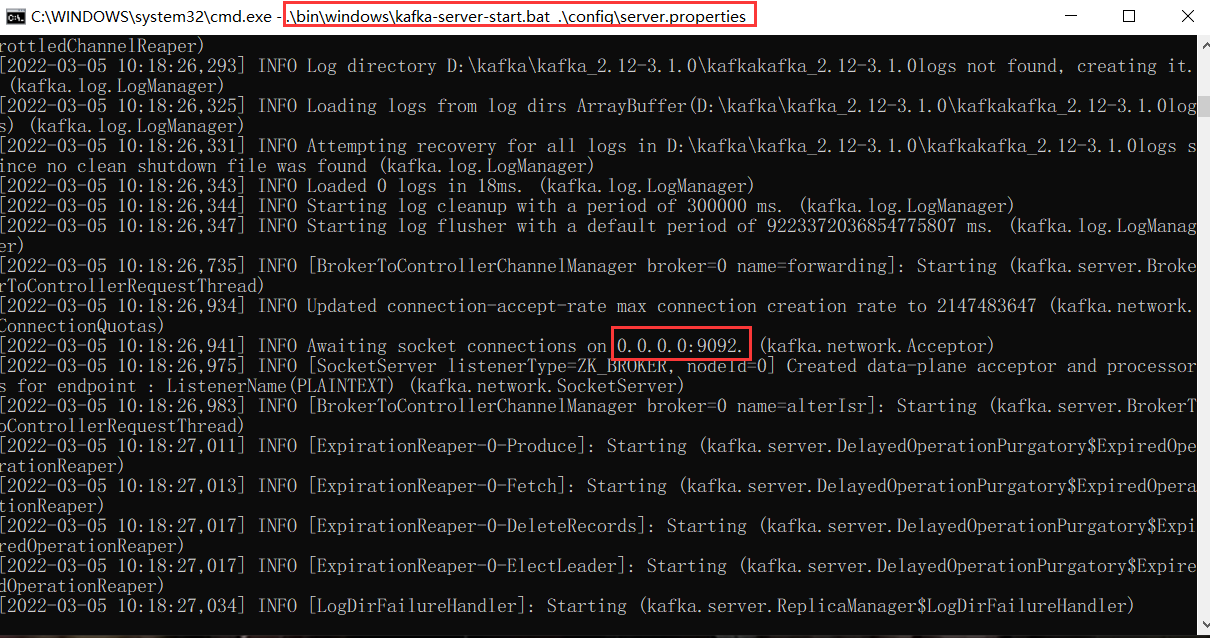

6)常用操作
- 創建Topic
kafka-topics.bat --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic cep
###查看topic
kafka-topics.bat --list --bootstrap-server localhost:9092

- 創建生產者
kafka-console-producer.bat --bootstrap-server localhost:9092 --topic cep
- 創建消費者
kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic cep --from-beginning --consumer-property group.id=cep

- 查看數據擠壓
kafka-consumer-groups.bat --bootstrap-server localhost:9092 --describe --group cep

LOG-END-OFFSET:下一條將要被加入到日誌的消息的位移
CURRENT-OFFSET:當前消費的位移
LAG:消息堆積量:消息中間件服務端中所留存的消息與消費掉的消息之間的差值即為消息堆積量也稱之為消費滯後量
七、Flink CEP實戰(java版)
參考:https://github.com/wooplevip/flink-tutorials

1)開發流程
- 讀取事件流並轉換為DataStream
- 運算元操作(可選)
- 必須指定水位線(watermark)
- 定義事件模式(event pattern)
- 在指定事件流上應用事件模式
- 匹配或選擇符合條件的事件,並產生告警
【溫馨提示】GitHub源碼中沒有指定水位線(watermark),無法觸發事件
2)Flink CEP快速上手
1、配置Maven
為了使用Flink CEP,需要導入pom依賴。(pom.xml完整配置)
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>bigdata-test2023</artifactId>
<groupId>com.bigdata.test2023</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>flink-java</artifactId>
<!-- DataStream API maven settings begin -->
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.14.3</version>
</dependency>
<!-- DataStream API maven settings end -->
<!-- Table and SQL maven settings begin-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<!-- 上面已經設置過了 -->
<!--<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>1.14.3</version>
</dependency>
<!-- Table and SQL maven settings end-->
<!-- Hive Catalog maven settings begin -->
<!-- Flink Dependency -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_2.12</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>1.14.3</version>
<scope>provided</scope>
</dependency>
<!-- Hive Dependency -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
<scope>provided</scope>
</dependency>
<!-- Hive Catalog maven settings end -->
<!--hadoop start-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.3.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>3.3.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>3.3.1</version>
<scope>provided</scope>
</dependency>
<!--hadoop end-->
<!-- cep -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep_2.12</artifactId>
<version>1.14.3</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>1.14.3</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-compress</artifactId>
<version>1.21</version>
</dependency>
</dependencies>
</project>
2、下載項目
【溫馨提示】直接下載項目可能運行不了,需要稍微改一下
$ git clone https://github.com/wooplevip/flink-tutorials.git
3、執行解析
源數據
1,VALID,2
2,VALID,200
3,VALID,3
4,INVALID,1
5,VALID,1
6,VALID,300
7,VALID,600
- CEPExample.java
package com.woople.streaming.cep;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.cep.CEP;
import org.apache.flink.cep.PatternStream;
import org.apache.flink.cep.functions.PatternProcessFunction;
import org.apache.flink.cep.pattern.Pattern;
import org.apache.flink.cep.pattern.conditions.SimpleCondition;
import org.apache.flink.core.fs.FileSystem;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import java.time.Duration;
import java.time.LocalDateTime;
import java.time.ZoneOffset;
import java.util.List;
import java.util.Map;
import java.util.Properties;
public class CEPExample{
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
/***
* kafka
*
* Properties properties = new Properties();
* properties.setProperty("bootstrap.servers", "localhost:9092");
* properties.setProperty("group.id", "flinkCEP");
*
* DataStream<String> dataStream = env
* .addSource(new FlinkKafkaConsumer<>("cep", new SimpleStringSchema(), properties));
*
*/
/**
* socket
* DataStreamSource<String> dataStream = env.socketTextStream("localhost", 9999, "\n");
*/
// 1.讀取事件流並轉換為DataStream(上面也列舉了socket和kafka,看自己需要怎麼選擇,因為我這裡是測試,所以簡單的用filesystem作為數據源)
DataStream<String> dataStream = env.readTextFile("flink-java/data/cep-data001.txt");
// 2.運算元操作
DataStream<Event> input = dataStream.map((MapFunction<String, Event>) value -> {
String[] v = value.split(",");
return new Event(LocalDateTime.now(), v[0], EventType.valueOf(v[1]), Double.parseDouble(v[2]));
});
// 3. 指定水位線(watermark)
SingleOutputStreamOperator<Event> watermarks = input.assignTimestampsAndWatermarks(
// 最大亂序程度
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner(
/*(SerializableTimestampAssigner<Event>) (event, recordTimestamp) -> event.toEpochMilli(event.getEventTime())*/
new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long recordTimestamp) {
return event.toEpochMilli(event.getEventTime());
}
}
)
);
// 4.定義事件模式(event pattern)
Pattern<Event, ?> pattern = Pattern.<Event>begin("start").where(
new SimpleCondition<Event>() {
@Override
public boolean filter(Event event) {
System.out.println(event + " from start");
return event.getType() == EventType.VALID && event.getVolume() < 10;
}
}
).next("end").where(
new SimpleCondition<Event>() {
@Override
public boolean filter(Event event) {
System.out.println(event + " from end");
return event.getType() == EventType.VALID && event.getVolume() > 100;
}
}
);
// 5.在指定事件流上應用事件模式
PatternStream<Event> patternStream = CEP.pattern(watermarks, pattern);
// 6.匹配或選擇符合條件的事件,並產生告警
DataStream<Alert> result = patternStream.process(
new PatternProcessFunction<Event, Alert>() {
@Override
public void processMatch(
Map<String, List<Event>> pattern,
Context ctx,
Collector<Alert> out) {
System.out.println(pattern);
out.collect(new Alert("111", "CRITICAL"));
}
});
result.print();
// result.writeAsText("flink-java/data/sink003");
env.execute("Flink cep example");
}
}
- Event.java
package com.woople.streaming.cep;
import java.time.LocalDateTime;
import java.time.ZoneOffset;
import java.util.Objects;
public class Event {
private EventType type;
private double volume;
private String id;
private LocalDateTime eventTime;
public Event(LocalDateTime eventTime, String id, EventType type, double volume) {
this.id = id;
this.type = type;
this.volume = volume;
this.eventTime = eventTime;
}
public double getVolume() {
return volume;
}
public String getId() {
return id;
}
public EventType getType() {
return type;
}
public LocalDateTime getEventTime() {
return eventTime;
}
public void setEventTime(LocalDateTime eventTime) {
this.eventTime = eventTime;
}
@Override
public String toString() {
return "Event(" + id + ", " + type.name() + ", " + volume + ")";
}
@Override
public boolean equals(Object obj) {
if (obj instanceof Event) {
Event other = (Event) obj;
return type.name().equals(other.type.name()) && volume == other.volume && id.equals(other.id);
} else {
return false;
}
}
@Override
public int hashCode() {
return Objects.hash(type.name(), volume, id);
}
public long toEpochMilli(LocalDateTime dt) {
ZoneOffset zoneOffset8 = ZoneOffset.of("+8");
return dt.toInstant(zoneOffset8).toEpochMilli();
}
}
- Alert.java
package com.woople.streaming.cep;
import java.util.Objects;
public class Alert {
private String id;
private String level;
public Alert(String id, String level) {
this.id = id;
this.level = level;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Alert alert = (Alert) o;
return Objects.equals(id, alert.id) &&
Objects.equals(level, alert.level);
}
@Override
public int hashCode() {
return Objects.hash(id, level);
}
@Override
public String toString() {
return "Alert{" +
"id='" + id + '\'' +
", level='" + level + '\'' +
'}';
}
}
- EventType
package com.woople.streaming.cep;
public enum EventType {
INVALID, VALID;
}
結果分析
- 如果使用的是
next("end"),只會觸發2次告警,分別為:
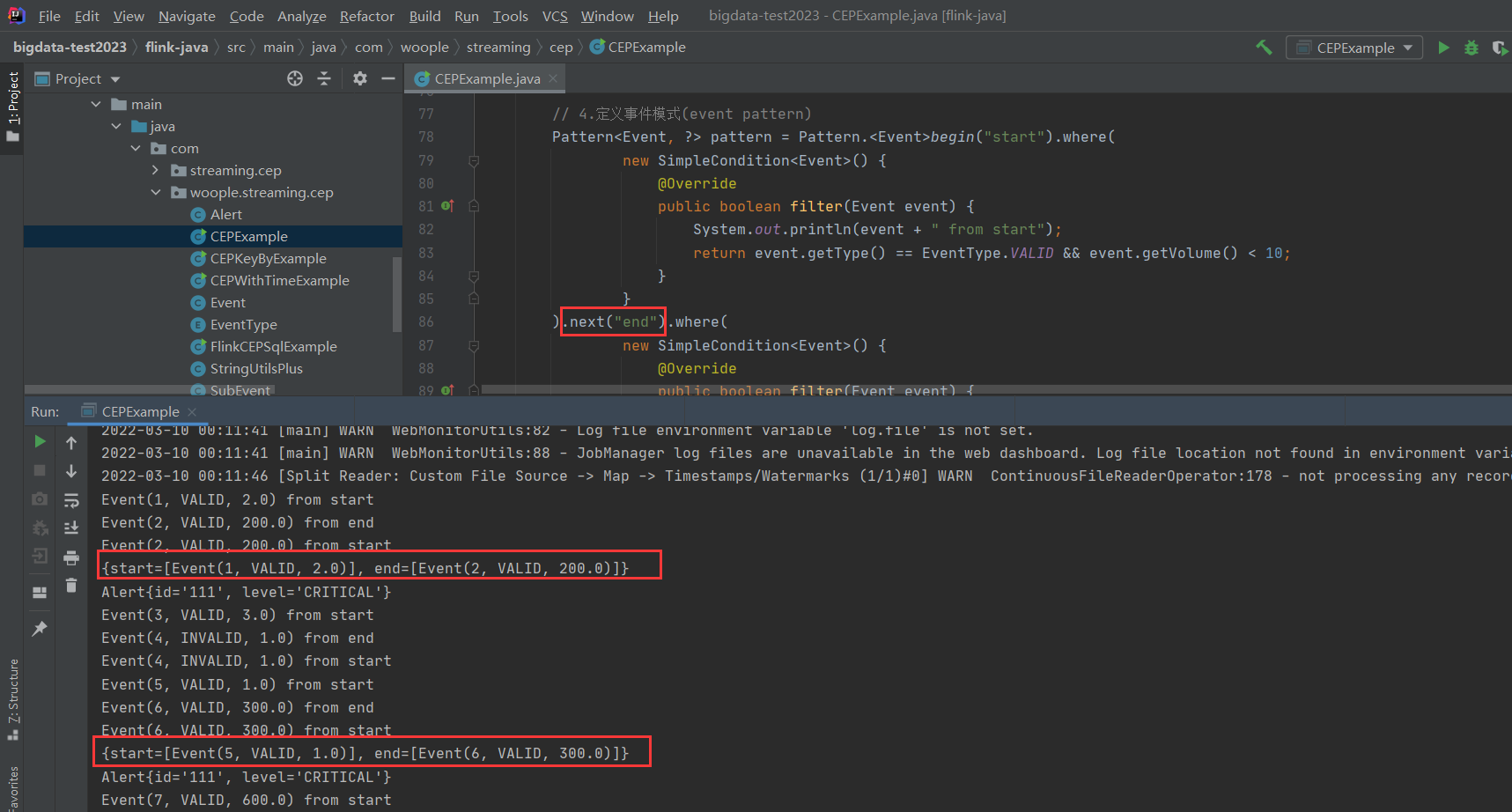
這就是因為next必須要滿足兩個連續的事件都符合條件。

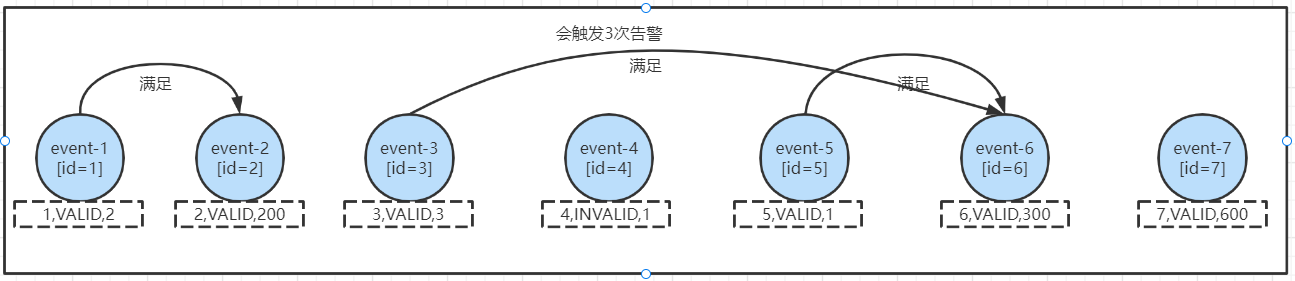
- 如果使用的是
followedBy("end"),會觸發3次告警,分別為:

可以看到滿足條件的event中間可以有不滿足的事件產生,第一個條件不重覆。
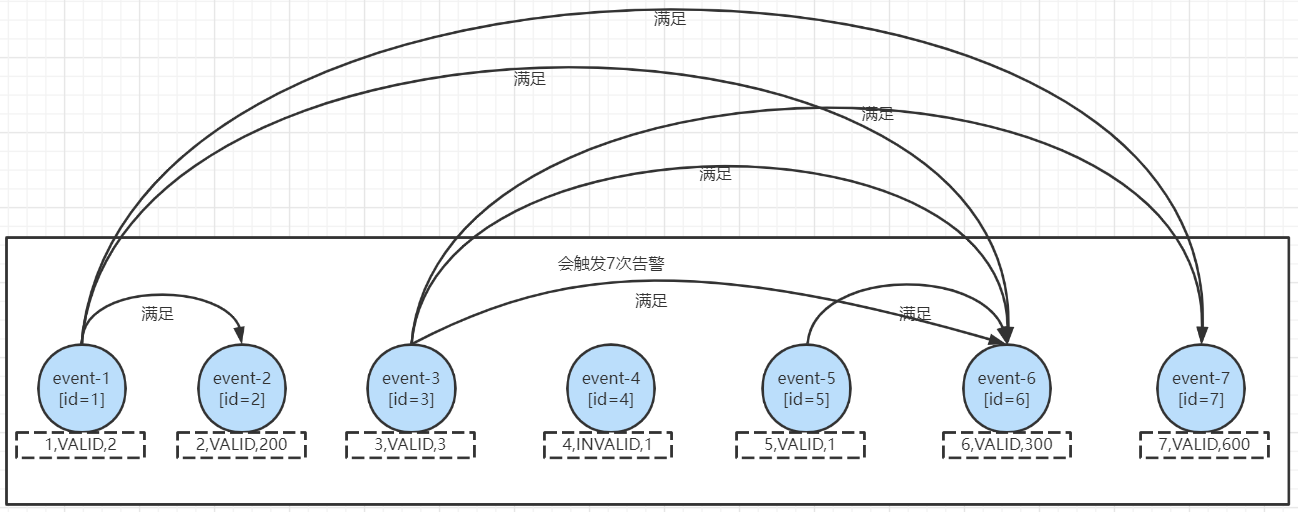
- 如果使用的是
followedByAny("end"),會觸發7次告警,分別為

followedByAny("end")和followedBy("end")主要的區別就是所有滿足條件的兩個事件都會觸發告警,即便前一個條件已經生效過,第一個條件可重覆。
其它幾個例子就演示了,都差不多,稍微改一下就ok了
3)Flink CEP進階
- CEPKeyByExample.java
package com.woople.streaming.cep;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.cep.CEP;
import org.apache.flink.cep.PatternStream;
import org.apache.flink.cep.pattern.Pattern;
import org.apache.flink.cep.pattern.conditions.SimpleCondition;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.time.Duration;
import java.time.LocalDateTime;
import java.util.List;
import java.util.Map;
import java.util.Properties;
public class CEPKeyByExample {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
/***
* kafka
*
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "flinkCEP");
DataStream<String> dataStream = env
.addSource(new FlinkKafkaConsumer<>("cep", new SimpleStringSchema(), properties));*/
/**
* socket
*
* DataStreamSource<String> dataStream = env.socketTextStream("localhost", 9999, "\n");
*/
// Filesystem
DataStream<String> dataStream = env.readTextFile("flink-java/data/cep-data001.txt");
DataStream<Event> input = dataStream.map((MapFunction<String, Event>) value -> {
String[] v = value.split(",");
return new Event(LocalDateTime.now(), v[0], EventType.valueOf(v[1]), Double.parseDouble(v[2]));
});
SingleOutputStreamOperator<Event> watermarks = input.assignTimestampsAndWatermarks(
// 最大亂序程度
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner(
/*(SerializableTimestampAssigner<Event>) (event, recordTimestamp) -> event.toEpochMilli(event.getEventTime())*/
new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long recordTimestamp) {
return event.toEpochMilli(event.getEventTime());
}
}
)
);
Pattern<Event, ?> pattern = Pattern.<Event>begin("start").where(
new SimpleCondition<Event>() {
@Override
public boolean filter(Event event) {
System.out.println(event + " from start");
return event.getType() == EventType.VALID && event.getVolume() < 10;
}
}
).followedBy("end").where(
new SimpleCondition<Event>() {
@Override
public boolean filter(Event event) {
System.out.println(event + " from end");
return event.getType() == EventType.VALID && event.getVolume() > 100;
}
}
);
PatternStream<Event> patternStream = CEP.pattern(watermarks.keyBy(Event::getId), pattern);
DataStream<Alert> result = patternStream.select((Map<String, List<Event>> p) -> {
List<Event> first = p.get("start");
List<Event> second = p.get("end");
return new Alert("111", "CRITICAL");
});
result.print();
env.execute("Flink cep example");
}
}
4)Flink CEP SQL用法
package com.woople.streaming.cep;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.formats.csv.CsvRowDeserializationSchema;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks;
import org.apache.flink.streaming.api.watermark.Watermark;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableSchema;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import java.util.Properties;
public class FlinkCEPSqlExample {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
env.setParallelism(1);
final StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
final TableSchema tableSchema = new TableSchema(new String[]{"symbol","tax","price", "rowtime"}, new TypeInformation[]{Types.STRING, Types.STRING, Types.LONG, Types.SQL_TIMESTAMP});
final TypeInformation<Row> typeInfo = tableSchema.toRowType();
final CsvRowDeserializationSchema.Builder deserSchemaBuilder = new CsvRowDeserializationSchema.Builder(typeInfo).setFieldDelimiter(',');
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
FlinkKafkaConsumer<Row> myConsumer = new FlinkKafkaConsumer<>(
"cep",
deserSchemaBuilder.build(),
properties);
myConsumer.setStartFromLatest();
DataStream<Row> stream = env.addSource(myConsumer).assignTimestampsAndWatermarks(new BoundedOutOfOrdernessGenerator());
tableEnv.registerDataStream("Ticker", stream, "symbol,tax,price,rowtime.rowtime");
Table result = tableEnv.sqlQuery("SELECT * " +
"FROM Ticker " +
" MATCH_RECOGNIZE( " +
" PARTITION BY symbol " +
" ORDER BY rowtime " +
" MEASURES " +
" A.price AS firstPrice, " +
" B.price AS lastPrice " +
" ONE ROW PER MATCH " +
" AFTER MATCH SKIP PAST LAST ROW " +
" PATTERN (A+ B) " +
" DEFINE " +
" A AS A.price < 10, " +
" B AS B.price > 100 " +
" )");
final TableSchema tableSchemaResult = new TableSchema(new String[]{"symbol","firstPrice","lastPrice"}, new TypeInformation[]{Types.STRING, Types.LONG, Types.LONG});
final TypeInformation<Row> typeInfoResult = tableSchemaResult.toRowType();
DataStream ds = tableEnv.toAppendStream(result, typeInfoResult);
ds.print();
env.execute("Flink CEP via SQL example");
}
private static class BoundedOutOfOrdernessGenerator implements AssignerWithPeriodicWatermarks<Row> {
private final long maxOutOfOrderness = 5000;
private long currentMaxTimestamp;
@Override
public long extractTimestamp(Row row, long previousElementTimestamp) {
System.out.println("Row is " + row);
long timestamp = StringUtilsPlus.dateToStamp(String.valueOf(row.getField(3)));
currentMaxTimestamp = Math.max(timestamp, currentMaxTimestamp);
System.out.println("watermark:" + StringUtilsPlus.stampToDate(String.valueOf(currentMaxTimestamp - maxOutOfOrderness)));
return timestamp;
}
@Override
public Watermark getCurrentWatermark() {
return new Watermark(currentMaxTimestamp - maxOutOfOrderness);
}
}
}
未完待續~


