
一、概述 Spark Streaming是對核心Spark API的一個擴展,它能夠實現對實時數據流的流式處理,並具有很好的可擴展性、高吞吐量和容錯性。Spark Streaming支持從多種數據源提取數據,如:Kafka、Flume、Twitter、ZeroMQ、Kinesis以及TCP套接字,並 ...
目錄
一、概述
Spark Streaming是對核心Spark API的一個擴展,它能夠實現對實時數據流的流式處理,並具有很好的可擴展性、高吞吐量和容錯性。Spark Streaming支持從多種數據源提取數據,如:Kafka、Flume、Twitter、ZeroMQ、Kinesis以及TCP套接字,並且可以提供一些高級API來表達複雜的處理演算法,如:map、reduce、join和window等。最後,Spark Streaming支持將處理完的數據推送到文件系統、資料庫或者實時儀錶盤中展示。實際上,你完全可以將Spark的機器學習(machine learning) 和 圖計算(graph processing)的演算法應用於Spark Streaming的數據流當中。

二、Spark Streaming基本原理
1)官方文檔對Spark Streaming的原理解讀
Spark Streaming從實時數據流接入數據,再將其劃分為一個個小批量供後續Spark engine處理,所以實際上,Spark Streaming是按一個個小批量來處理數據流的。下圖展示了Spark Streaming的內部工作原理:
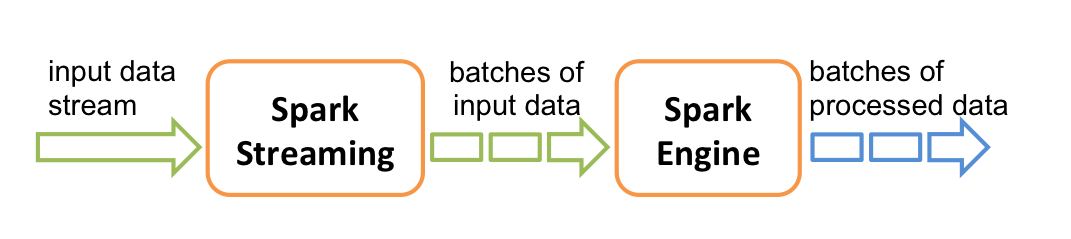
Spark Streaming為這種持續的數據流提供了的一個高級抽象,即:discretized stream(離散數據流)或者叫DStream。DStream既可以從輸入數據源創建得來,如:Kafka、Flume或者Kinesis,也可以從其他DStream經一些運算元操作得到。其實在內部,一個DStream就是包含了一系列RDDs。
2)框架執行流程
下麵將從更細粒度架構角度看Spark Streaming的執行原理,這裡先回顧一下Spark框架執行流程。
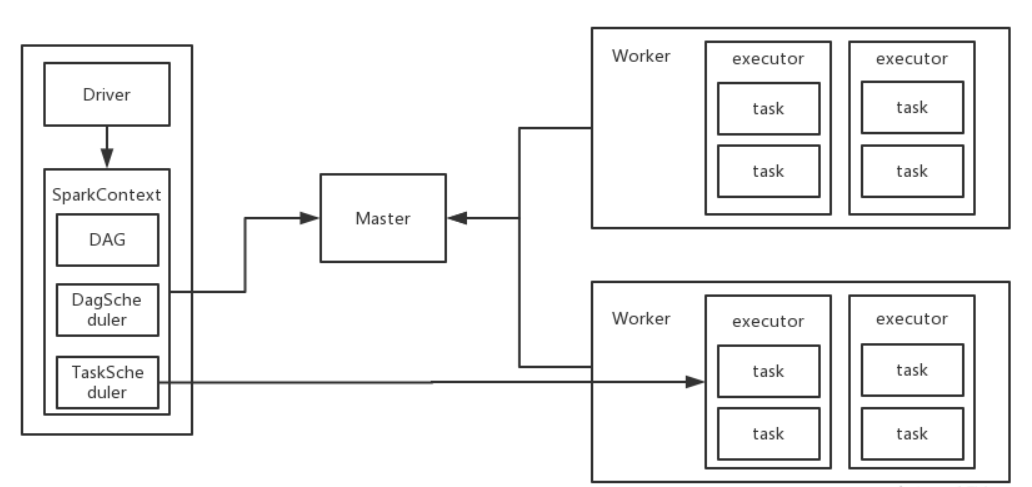
Spark計算平臺有兩個重要角色,Driver和executor,不論是Standlone模式還是Yarn模式,都是Driver充當Application的master角色,負責任務執行計劃生成和任務分發及調度;executor充當worker角色,負責實際執行任務的task,計算的結果返回Driver。
下圖是Driver和Ececutor的執行流程。

Driver負責生成邏輯查詢計劃、物理查詢計劃和把任務派發給executor,executor接受任務後進行處理,離線計算也是按這個流程進行。
- DAGScheduler:負責將Task拆分成不同Stage的具有依賴關係(包含RDD的依賴關係)的多批任務,然後提交給TaskScheduler進行具體處理。
- TaskScheduler:負責實際每個具體Task的物理調度執行。
下麵看Spark Streaming實時計算的執行流程:
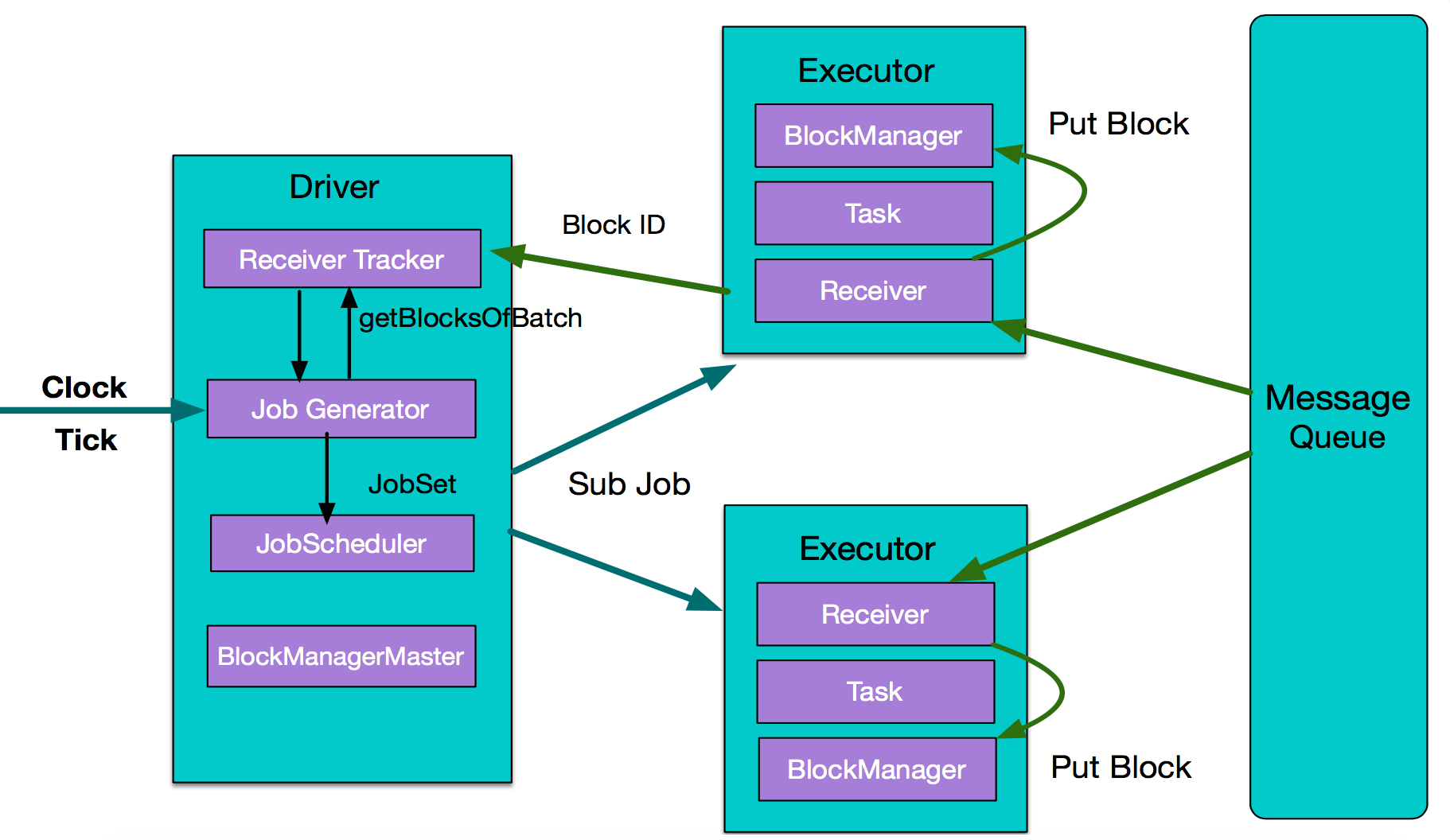
- 從整體上看,實時計算與離線計算一樣,主要組件是Driver和Executor的。不同的是多了數據採集和數據按時間分片過程,數據採集依賴外部數據源,這裡用MessageQueue表示,數據分片則依靠內部一個時鐘Clock,按batch interval來定時對數據分片,然後把每一個batch interval內的數據提交處理。
- Executor從MessageQueue獲取數據並交給BlockManager管理,然後把元數據信息BlockID返給driver的Receiver Tracker,driver端的Job Jenerator對一個batch的數據生成JobSet,最後把作業執行計劃傳遞給executor處理。
三、Spark Streaming核心API
SparkStreaming完整的API包括StreamingContext、DStream輸入、DStream上的各種操作和動作、DStream輸出、視窗操作等。
1)StreamingContext
為了初始化Spark Streaming程式,必須創建一個StreamingContext對象,該對象是Spark Streaming所有流操作的主要入口。一個StreamingContext對象可以用SparkConf對象創建:
import org.apache.spark.*;
import org.apache.spark.api.java.function.*;
import org.apache.spark.streaming.*;
import org.apache.spark.streaming.api.java.*;
import scala.Tuple2;
// Create a local StreamingContext with two working thread and batch interval of 1 second
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount");
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(1));
2)DStream輸入
DStream輸入表示從數據源獲取的原始數據流。每個輸入流DStream和一個接收器(receiver)對象相關聯,這個Receiver從源中獲取數據,並將數據存入記憶體中用於處理。
Spark Streaming有兩類數據源:
- 基本源(basic source):在StreamingContext API中直接可用的源頭,例如文件系統、套接字連接、Akka的actor等。
- 高級源(advanced source):包括 Kafka、Flume、Kinesis、Tiwtter等,他們需要通過額外的類來使用。
3)DStream的轉換
和RDD類似,transformation用來對輸入DStreams的數據進行轉換、修改等各種操作,當然,DStream也支持很多在Spark RDD的transformation運算元。
| 轉換操作(transformation) | 含義(Meaning) |
|---|---|
| map(func) | 利用函數func處理原DStream的每個元素,返回一個新的DStream. |
| flatMap(func) | 與map相似,但是每個輸入項可用被映射0個或多個輸出項 |
| filter(func) | 返回一個新的DStream,它僅包含源DStream中滿足函數func的項 |
| repartition(numPartitions) | 通過創建更多或更少的的partition改變這個DStream的並行級別(level ofparallelism) |
| union(otherStream) | 返回一個新的DStream,它包含源DStream和otherStream的聯合元素 |
| count() | 通過計算源DStream中每個RDD的元素數量,返回一個包含單元素RDD的新DStream |
| reduce(func) | 利用函數func聚集源DStream中每個RDD的元素,返回一個包含單元素RDD的新的DStream。函數應該是相關聯的,以使計算可以並行化 |
| countByValue() | 這個運算元應用於元素類型為K的DStream上,返回一個(Kjong)前的新DStreamo每個鍵的值是在原DStream的每個RDD的頻率 |
| reduceByKey(func, [numTasks]) | 當在一個由(K,V)對組成的DStream上調用這個運算元,返回一個新的由(K,V)對組成的DStream,每一個key的值均有給定的reduce函數聚集起來。註意:在預設情況下,這個運算元利用了 Spark預設的併發任務數去分組。可以用numTasks參數設置不同的任務數 |
| join(otherStream, [numTasks]) | 當應用於兩個DStream(一個包含(K,V)對,一個包含(K,W)對,返回一個包含(K,(V,W))對的新的 DStream |
| cogroup(otherStream, [numTasks]) | 當應用於兩個DStream(一個包含(K,V)對,一個包含(K,W)對,返回一個包含(K,Seq[VJSeq[WN 的元組 |
| transform(func) | 通過對源DStream的每個RDD應用RDD-to-RDD函數,創建一個新的DStreamo這個可以在DStream中的任何RDD操作中使用 |
| updateStateByKey(func) | 利用給定的函數更新DStream狀態,返回一個新“state”的DStream |
4)DStream的輸出
和RDD類似,Spark Streaming允許將DStream轉換後的結果發送到資料庫、文件系統等外部系統中。目前,定義了Spark Streaming的輸出操作:
| 轉換操作(transformation) | 含義(Meaning) |
|---|---|
| print() | 在運行流應用程式的驅動程式節點上列印數據流中每批數據的前十個元素。這對於開發和調試非常有用。Python API在Python API中稱為pprint()。 |
| saveAsTextFiles(prefix, [suffix]) | 將此數據流的內容另存為文本文件。每個批處理間隔的文件名基於首碼和尾碼生成:“prefix-TIME_IN_MS[.suffix]”。 |
| saveAsObjectFiles(prefix, [suffix]) | 將此數據流的內容另存為序列化Java對象的SequenceFile。每個批處理間隔的文件名基於首碼和尾碼生成:“prefix-TIME_IN_MS[.suffix]”。Python API這在Python API中不可用。 |
| saveAsHadoopFiles(prefix, [suffix]) | 將此數據流的內容另存為Hadoop文件。每個批處理間隔的文件名基於首碼和尾碼生成:“prefix-TIME_IN_MS[.suffix]”。Python API這在Python API中不可用。 |
| foreachRDD(func) | 對從流生成的每個RDD應用函數func的最通用的輸出運算符。此函數應將每個RDD中的數據推送到外部系統,例如將RDD保存到文件中,或通過網路將其寫入資料庫。請註意,函數func是在運行流應用程式的驅動程式進程中執行的,其中通常包含RDD操作,這些操作將強制計算流RDD。 |
5)視窗操作
Spark Streaming 還提供視窗計算,允許您在數據的滑動視窗上應用轉換。下圖說明瞭這個滑動視窗:

如圖所示,每次視窗滑過一個源 DStream 時,落入視窗內的源 RDD 被組合併操作以產生視窗化 DStream 的 RDD。在這種特定情況下,該操作應用於最後 3 個時間單位的數據,並滑動 2 個時間單位。這說明任何視窗操作都需要指定兩個參數。
- windowLength:視窗的持續時間(圖中 3)。
- slideInterval :執行視窗操作的間隔(圖中為 2)。
一些常見的視窗操作如下。所有這些操作都採用上述兩個參數 - windowLength和slideInterval。
| 轉換操作(transformation) | 含義(Meaning) |
|---|---|
| window(windowLength, slideInterval) | 返回一個新的 DStream,它是根據源 DStream 的視窗批次計算的。 |
| countByWindow(windowLength, slideInterval) | 返迴流中元素的滑動視窗計數。 |
| reduceByWindow(func, windowLength, slideInterval) | 返回一個新的單元素流,它是通過使用func在滑動間隔內聚合流中的元素而創建的。該函數應該是關聯的和可交換的,以便它可以被正確地並行計算。 |
| reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) | 當在 (K, V) 對的 DStream 上調用時,返回一個新的 (K, V) 對 DStream,其中每個鍵的值使用給定的 reduce 函數func 在滑動視窗中的批次上聚合。註意:預設情況下,這使用 Spark 的預設並行任務數(本地模式為 2,在集群模式下,數量由 config 屬性決定spark.default.parallelism)進行分組。您可以傳遞一個可選 numTasks參數來設置不同數量的任務。 |
| reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) | reduceByKeyAndWindow()其中每個視窗的減少值是使用前一個視窗的減少值遞增計算的。這是通過減少進入滑動視窗的新數據,並“逆減少”離開視窗的舊數據來完成的。一個例子是在視窗滑動時“添加”和“減去”鍵的計數。但是,它只適用於“可逆歸約函數”,即那些具有相應“逆歸約”函數(作為參數invFunc)的歸約函數。跟reduceByKeyAndWindow一樣,reduce 任務的數量可通過可選參數進行配置。請註意,必須啟用檢查點才能使用此操作。 |
| countByValueAndWindow(windowLength, slideInterval, [numTasks]) | 當在 (K, V) 對的 DStream 上調用時,返回一個新的 (K, Long) 對 DStream,其中每個鍵的值是其在滑動視窗內的頻率。與 in 一樣 reduceByKeyAndWindow,reduce 任務的數量可通過可選參數進行配置。 |
更多操作詳情,請參考官方文檔:https://spark.apache.org/docs/latest/streaming-programming-guide.html
四、Spark下一代實時計算框架Structured Streaming
1)簡介
從Spark 2.0開始,Spark Streaming引入了一套新的流計算編程模型:Structured Streaming,開發這套API的主要動因是自Spark 2.0之後,以RDD為核心的API逐步升級到Dataset/DataFrame上,而另一方面,以RDD為基礎的編程模型對開發人員的要求較高,需要有足夠的編程背景才能勝任Spark Streaming的編程工作,而新引入的Structured Streaming模型是把數據流當作一個沒有邊界的數據表來對待,這樣開發人員可以在流上使用Spark SQL進行流處理,這大大降低了流計算的編程門檻。
下圖為Structure Streaming邏輯數據結構圖:
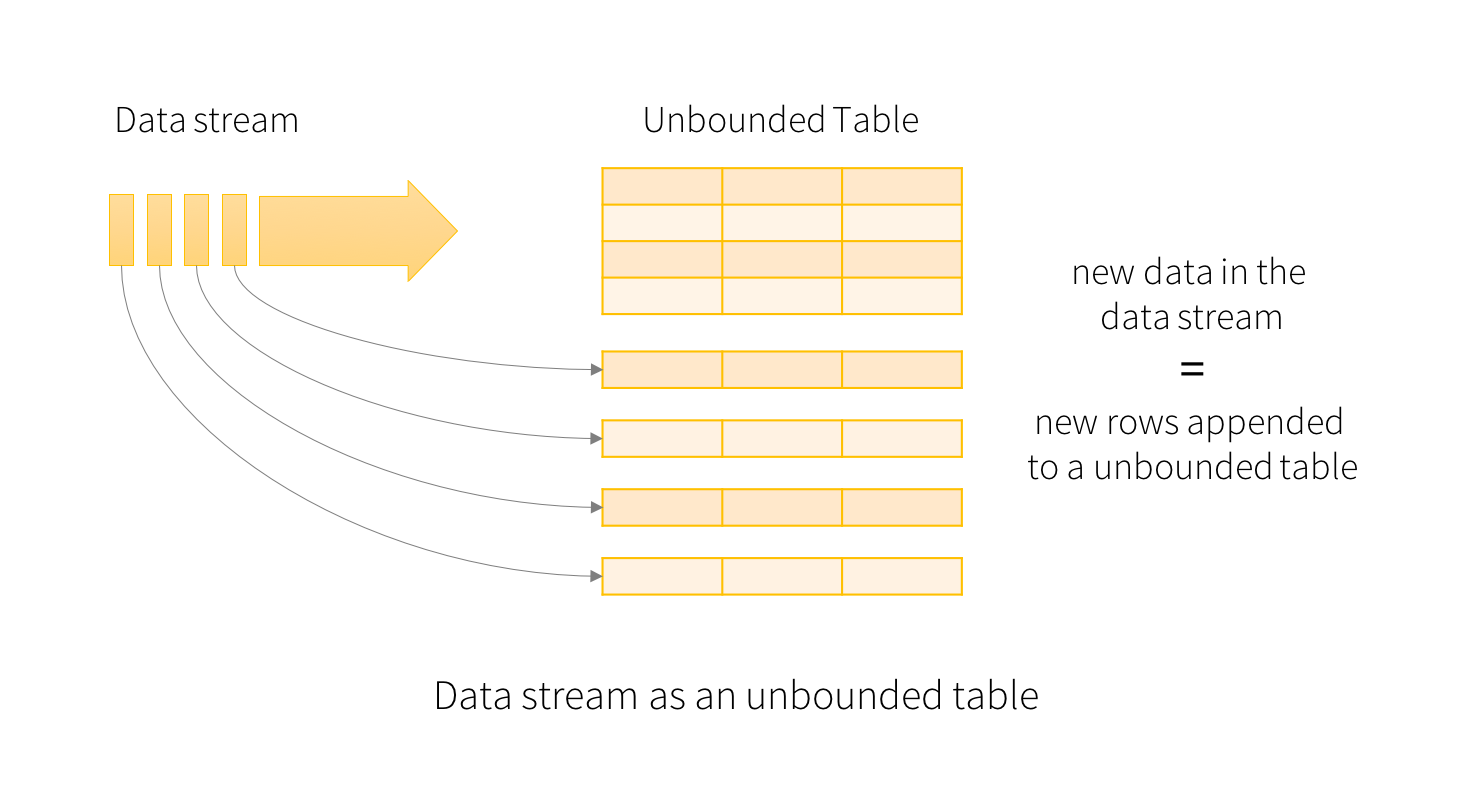
這裡以wordcount為例的計算過程如下圖:
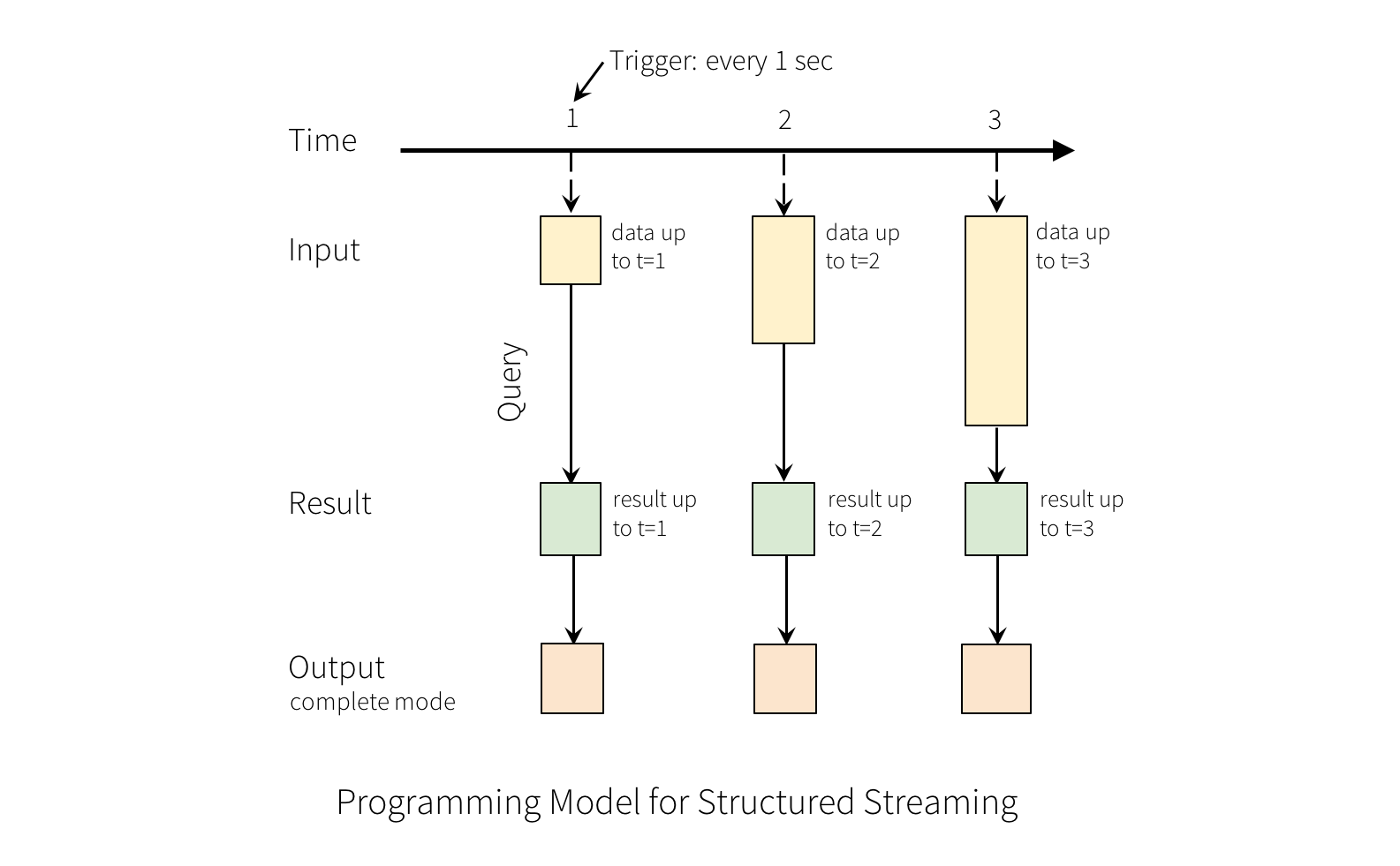
圖中Time橫軸是時間軸,隨著時間,在1、2、3秒分別輸入數據,進入wordcount演算法計算聚合,輸出結果。更對關於Structure Streaming可以參考官網:https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
2) Spark streaming 和 Spark Structured Streaming的對比
| 對比項 | Spark Streaming | Structured Streaming |
|---|---|---|
| 流模型 | Spark Streaming是spark最初的流處理框架,使用了微批的形式來進行流處理,微批終究是批。每一個批處理間隔的為一個批,也就是一個RDD,我們對RDD進行操作就可以源源不斷的接收、處理數據。 | Spark 2.X出來的流框架,採用了無界表的概念,流數據相當於往一個表上連續追加行,流上的每一條數據都類似於將一行新數據添加到表中。 |
| 操作對象 | Dtream編程介面是RDD | 使用 DataFrame、DataSet 的編程介面,處理數據時可以使用Spark SQL中提供的方法 |
| 時延 | 接收到數據時間視窗,秒級 | 實時處理數據,毫秒級 |
| 可靠性 | Checkpoint 機制 | Checkpoint 機制 |
| Sink | 提供了 foreachRDD()方法,通過自己編程實現將每個批的數據寫出 | 提供了一些 sink(Console Sink、File Sink、Kafka Sink等),只要通過option配置就可以使用;對於需要自定義的Sink,提供了ForeachWriter的編程介面,實現相關方法就可以完成 |
| Spark Streaming |
-
Spark Streaming是spark最初的流處理框架,使用了微批的形式來進行流處理。
-
提供了基於RDDs的Dstream API,每個時間間隔內的數據為一個RDD,源源不斷對RDD進行處理來實現流計算。
-
Spark Streaming採用微批的處理方法,微批終究是批。每一個批處理間隔的為一個批,也就是一個RDD,我們對RDD進行操作就可以源源不斷的接收、處理數據。
Spark Structured Streaming
-
Spark 2.X出來的流框架,採用了無界表的概念,流數據相當於往一個表上不斷追加行。
-
基於Spark SQL引擎實現,可以使用大多數Spark SQL的function。
-
Structured Streaming將實時數據當做被連續追加的表。流上的每一條數據都類似於將一行新數據添加到表中。
3)對比其它實時計算框架
為了展示結構化流的獨特之處,下表將其與其他幾個系統進行了比較。正如我們所討論的,Structured Streaming 對首碼完整性的強大保證使其等同於批處理作業,並且易於集成到更大的應用程式中。此外,在 Spark 上構建可以與批處理和互動式查詢集成。

-
從延遲看:Storm和Flink原生支持流計算,對每條記錄處理,毫秒級延遲,是真正的實時計算,對延遲要求較高的應用建議選擇這兩種。Spark Streaming的延遲是秒級。Flink是目前最火的實時計算引擎,也是公司用的最多的實時計算引擎,出來的晚,但是發展迅猛。
-
從容錯看 :Spark Streaming和Flink都支持最高的exactly-once容錯級別,Storm會有記錄重覆計算的可能
-
從吞吐量看 :Spark Streaming是小批處理,故吞吐量會相對更大。
-
從成熟度看: Storm最成熟,Spark其次,Flink處於仍處於發展中,這三個項目都有公司生產使用,但畢竟開源項目,項目越不成熟,往往越要求公司大數據平臺研發水平。
-
從整合性看:Storm與SQL、機器學習和圖計算的結合複雜性最高;而Spark和Flink都有生態圈內對應的SQL、機器學習和圖計算,與這些項目結合更容易。
【參考資料】
-
http://spark.apache.org/docs/latest/streaming-programming-guide.html
-
http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
-
https://databricks.com/blog/2016/07/28/structured-streaming-in-apache-spark.html


