
導讀: 近年來,知識圖譜在眾多行業場景被大量應用,例如推薦、醫療。為了構造儘可能完備的圖譜,知識圖譜的推理工作也成為學術屆和工業界的一個重要研究課題。來自Mila人工智慧實驗室的瞿錳博士,給大家分享了他們在圖譜推理任務方向的一個研究:基於邏輯規則的圖譜推理(RNNLogic: Learning Lo ...

導讀: 近年來,知識圖譜在眾多行業場景被大量應用,例如推薦、醫療。為了構造儘可能完備的圖譜,知識圖譜的推理工作也成為學術屆和工業界的一個重要研究課題。來自Mila人工智慧實驗室的瞿錳博士,給大家分享了他們在圖譜推理任務方向的一個研究:基於邏輯規則的圖譜推理(RNNLogic: Learning Logic Rules for Reasoning on Knowledge Graphs),研究結果顯示RNNLogic可以很好地兼顧圖譜推理任務的模型效果和可解釋性的問題。
本文將圍繞以下幾點展開:
- 圖譜和圖譜推理介紹
- 常見方法和優缺點
- 邏輯規則學習方法 RNNLogic
- 工作展望
--
01 圖譜和圖譜推理介紹

知識圖譜可以看作是我們真實世界中的一些事實的集合,每一條事實可以表示成(h,r,t)或者r(h,t)的形式。比如說我們知道比爾蓋茨是微軟公司的創始人,我們就可以得到一個(Bill Gates, co-founder of, Microsoft)的3元組組成的事實。在實際生活當中,有眾多知識圖譜,總結了各個領域的相關知識。
這些知識圖譜在很多應用中發揮著重要作用。比如推薦系統中,知識圖譜可以幫助我們更好地挖掘用戶的興趣;還有藥物再利用方面,對於藥物的屬性、疾病的屬性以及藥物和疾病之間關係的已有信息,可以幫助我們去發現新的藥物和疾病間的聯繫,從而更好地去對抗疾病。
不過在實際應用過程中存在的一個問題,圖譜信息是不完全的,而補全圖譜的人工成本又是非常巨大的,尤其是像是一些醫葯、金融等一些特定的領域。如果還要考慮知識的動態更新的話,就更加大了圖譜補全的難度。
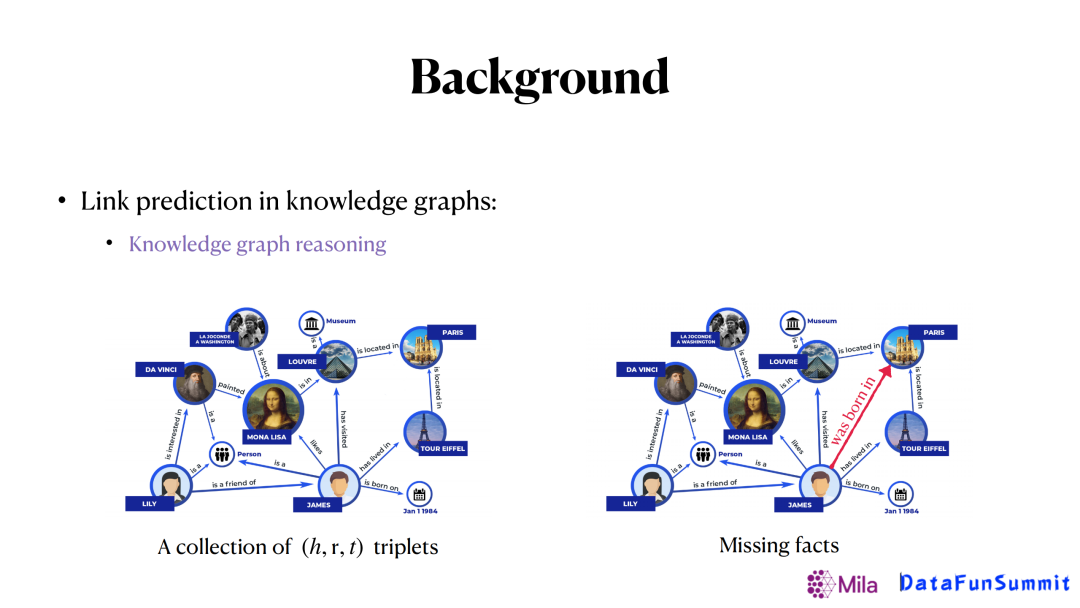
也正是這些問題促成了關係預測這個任務(用來補全圖譜),在知識圖譜里,關係預測也被稱作知識圖譜推理。圖譜推理的任務就是給定已有圖譜,去推理出圖譜中的一些缺失的邊。比如上圖,我們希望能推出紅色的邊(詹姆斯出生在巴黎)。
--
02 常見方法和優缺點
1. 圖譜表示法

圖譜推理最常見的方法是基於知識圖譜表示(KG Embedding)的方法,基本思想就是希望把每一個實體或者關係做向量嵌入,通過這些向量表示來進行推斷找到缺失的邊。
- 優點:通常能有較好的預測效果。
- 缺點:模型缺乏可解釋性。
2. 歸納邏輯編程法
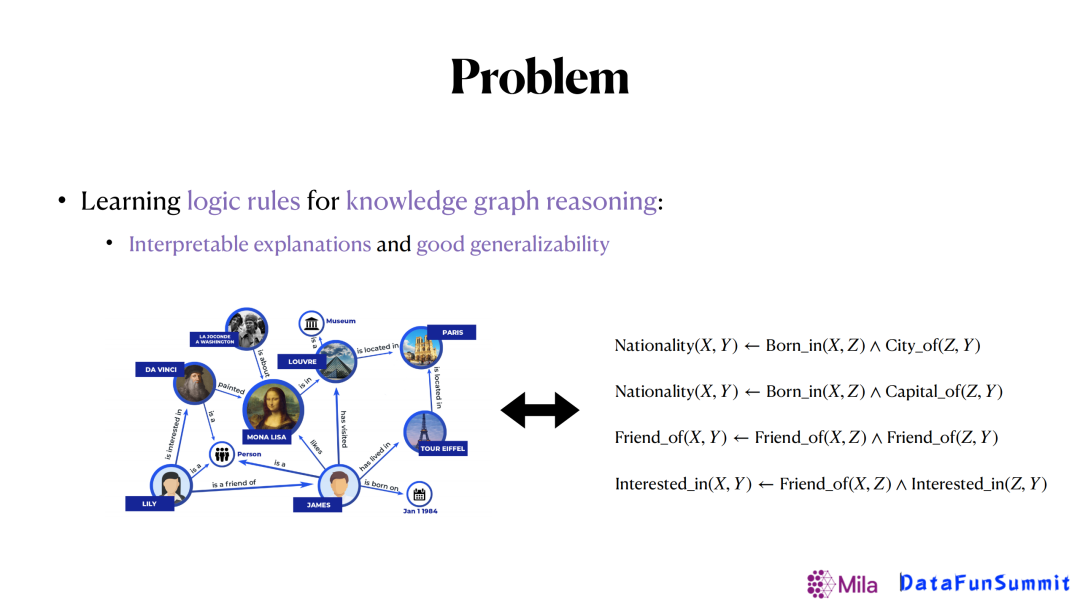
考慮到圖譜嵌入法的可解釋性差,我們希望通過學習一些邏輯規則來完成這個任務,提高可解釋性。大概的思路是給定已有的知識圖譜,我們希望可以從知識圖譜裡面提取出一些通用邏輯規則,如上圖出生地(born in)和城市(city of)兩個關係可以用來推斷國籍(nationality),再反過來去做關係預測。通過這樣的方式,可以使得模型的可解釋性更強,而且生成的規則也具有更好的可泛化性。
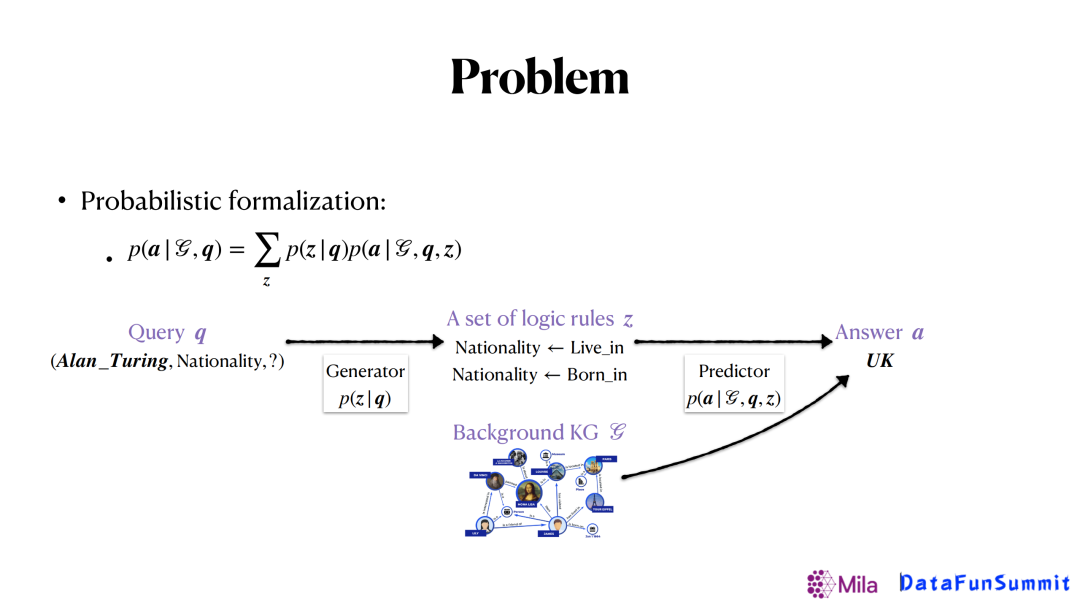
以上的問題可以通過概率形式建模。如上圖所示,我們將這個任務建模分成兩部分,生成器(generator)和 預測器(predictor)。其中生成器用來生成邏輯規則,預測器將利用生成的規則和已有的圖譜去預測最後的答案。對於這樣的形式,我們會有不同的方法來解決,其中之一是歸納邏輯編程(Inductive logic programming)。

這種方法的核心是學到一個好的預測器,然後在具體在操作的過程中,他們會利用一個固定的生成器(比如一套邏輯規則的模板)生成出大量的潛在邏輯規則,在預測階段會給每個潛在的邏輯規則一個權重(weight),最後從所有的邏輯規則裡面挑選權重大的規則,當作學習到的比較重要的規則。
- 優點:整個框架的優化比較簡單。
- 缺點:對規則的搜索空間大,因為固定的生成器。如果想要得到比較好的結果就要嘗試大量的邏輯規則,導致效率較低。
3. 基於強化學習的方法
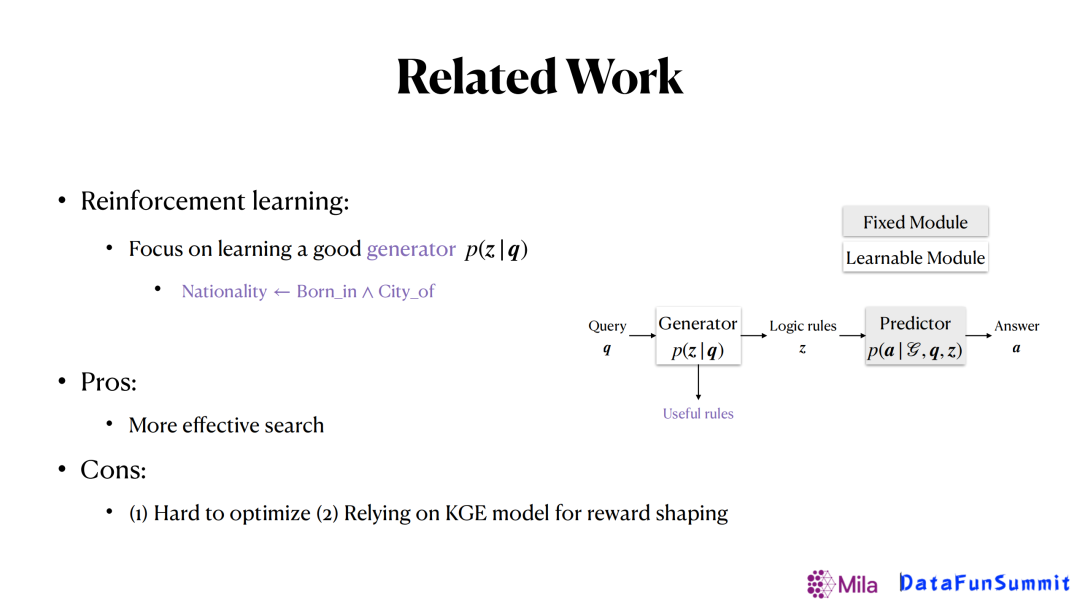
另外一類方法是基於強化學習的方法,其思想和之前的方法是完全相反的,是直接去學習一個生成器,給定一個查詢(Query)後可以直接生成一個規則,一旦有了這個規則之後,就可以根據規則定義的關係在知識圖譜上去做隨機游走,得到我們想要的答案。在這個框架里,只有生成器是可以學習的,預測器是相對簡單的,固定的。
- 優點:預測搜索效率高。
- 缺點:整個框架的優化很難;依賴KGE(圖譜嵌入)的方法來做激勵調整。
--
03 邏輯規則學習方法 RNNLogic
1. 研究背景

在對上面兩個方法對比時,我們發現一個方法側重在學習生成器,另一個側重學習預測器。我們希望有一種框架,可以同時訓練生成器和預測器,也就是RNNLogic的一個核心點。
2. RNNLogic方法

在我們的研究里主要考慮鏈式的邏輯規則,如上圖中所示,可以將鏈式的邏輯規則變成一個關係序列,其中用END來表示結尾。那很自然的,我們可以通過LSTM來生成這些不同的鏈式邏輯規則,並輸出每一條邏輯規則的概率,進而得到一個弱邏輯規則的集合。

接著我們使用了一個叫做隨機邏輯編程(stochastic logic programming)的框架來去定義預測器。會通過生成器的弱關係集合進行游走,如圖中所示的兩種關係鏈,第一種可以得到France這個答案,第二個邏輯規則可以得到France,Canada和US三個答案。對於每個潛在答案,我們可以給它定義一個分數,也就是到達這個實體的邏輯規則的weight的和。最後就可以根據分數得到每種答案的概率,挑選出那些概率最大的來當成我們最終的答案。

當前方法的主要難點是如何優化,因為無論是生成器還是預測期,都是動態學習的,所以優化起來可能會有一定難度。而我們發現生成器和預測器兩者的難度是不同的,前者由於對後者的依賴,使得生成器是需要依賴於預測器的結果來進行動態調整的,所以生成器會更難些。
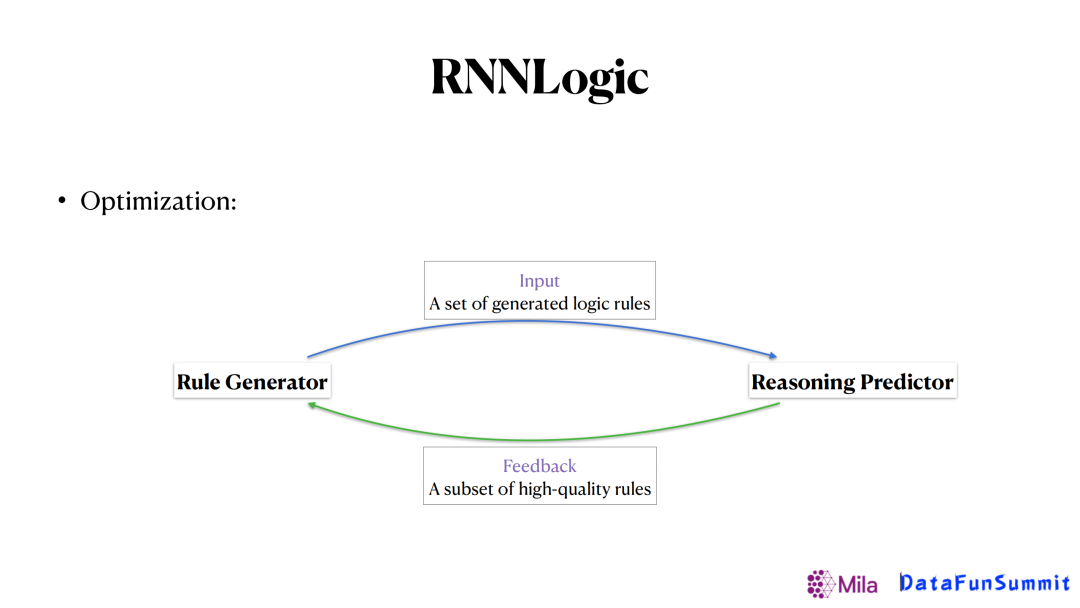
為瞭解決這個難點,我們提出了上圖所示的框架。像之前的一些方法,是給定了一個生成器生成了一些邏輯規則送給預測期,讓預測器給生成器反饋這個邏輯規則的集合是好還是壞。我們的思路是希望預測器給生成器的反饋更加具體,譬如哪幾條規則更重要,從而幫助生成器更好地去更新,得到更好的結果。最後,整個優化的過程可以如下表示:

首先第一步,給定一個查詢(Query),讓生成器生成很多邏輯規則,再把邏輯規則和知識圖譜同時送到預測器裡面,去更新預測器,最大化生成正確答案的概率。
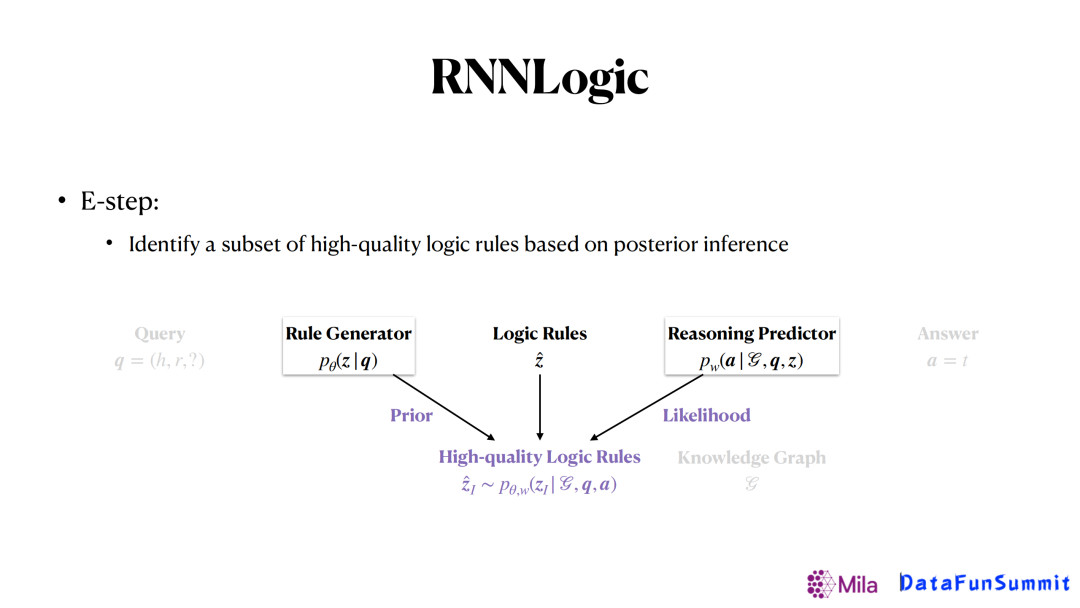
接著,從所有生成的這些邏輯規則裡面去挑選出那些最重要的邏輯規則。這裡我們通過使用後驗推斷的方法來計算每一條弱的邏輯規則的後驗概率進行挑選。因此,在整個過程中,每一條弱的規則概率是由生成器來提供的,似然函數由預測器來提供。這樣結合兩者共同的信息來得到一個比較重要的邏輯規則。

最後,我們就可以把找到的高質量的邏輯規則當成訓練數據,送回生成器去學習。
3. 實踐效果
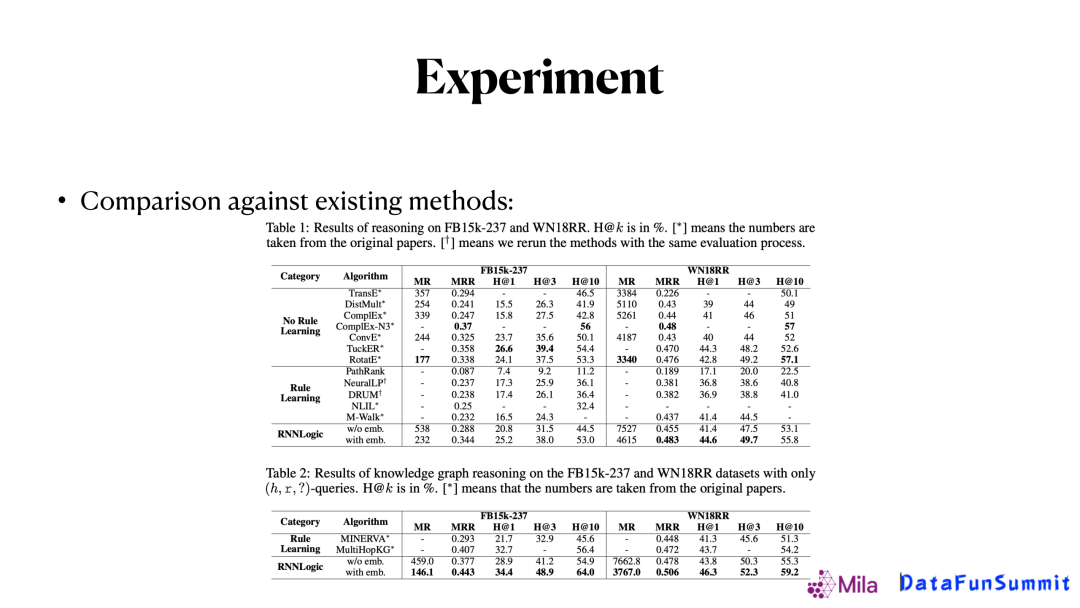
最後我們通過實驗來比較我們的演算法和現有演算法的效果。上圖是在常見的FB15K和WN18RR兩個數據上的實驗對比,可以看到,我們的方法能達到嵌入方法差不多的效果,而且有更好的可解釋性,因此,它的潛力還是比較大的。
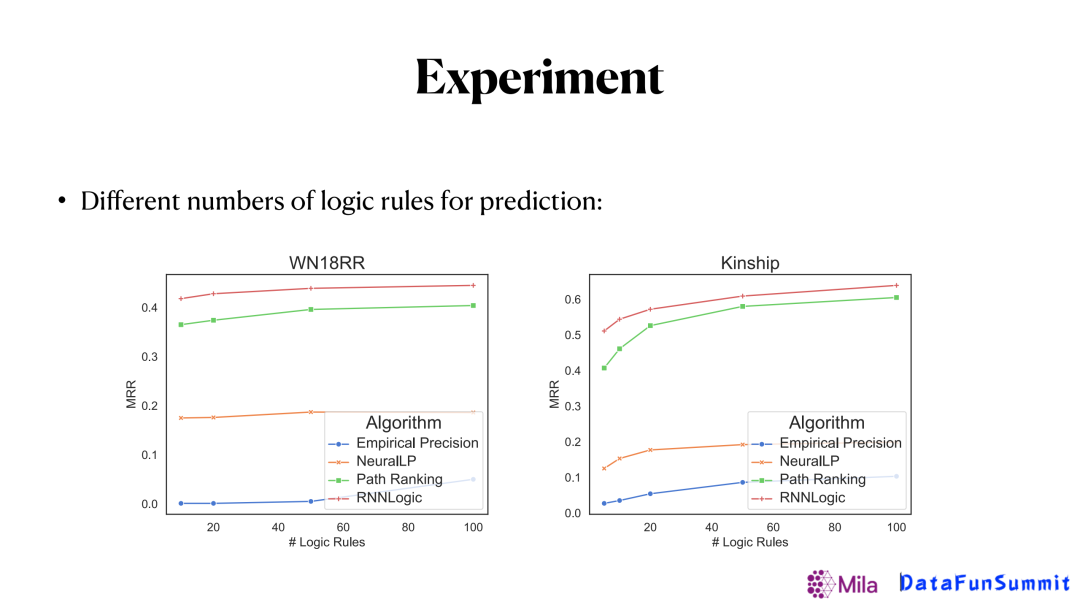
另一個有趣的實驗是和模型生成的邏輯規則數量有關,可以看到針對某個關係,只生成10個邏輯規則就可以有個不錯的效果,數量提升到100基本就收斂了。也就是只需要比較少的邏輯規則就可以對知識圖譜中缺失的邊進行有效的預測。

上圖是我們最後生成的樣例,整體規則是多樣的,既有長度為1的比較短的規則,也有些跳四五步才能推斷出來的很長的邏輯規則。
4. 更複雜的預測器(RNNLogic+)

接著我們實驗一些更複雜的預測器來進行預測,前面仍然是給定一些邏輯規則,通過這些規則在圖譜里我們會得到不同的路徑,然後對於這些路徑我們用不同的方法來打分。比如上圖我們既用了LSTM的Score,也用了圖嵌入(KGE)的Score來打分,來得出我們最終預測結果的得分和答案。
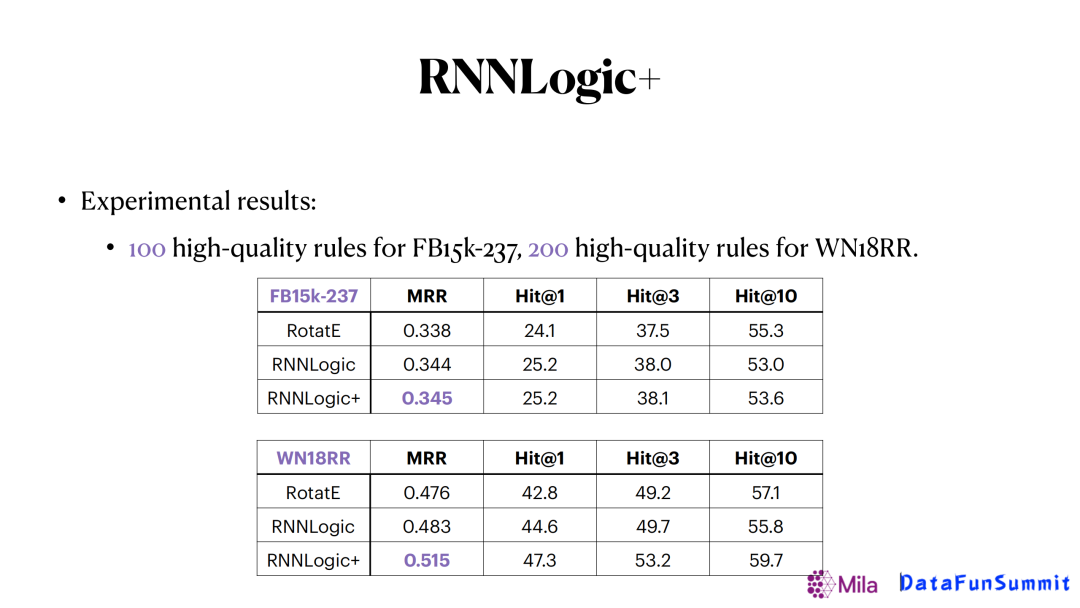
通過這個更複雜的預測器我們可以看到它的結果可以是被進一步提升的,如上圖在兩個數據集里我們分別用100個邏輯規則和200個邏輯規則,就可以得到非常好的結果。而且在像wordNet(WN18RR)這種相對稀疏的圖譜中,提升更明顯。
--
04 工作展望
基於邏輯規則的模型在知識圖推理中受到越來越多的關註,因為它可以比較好的融合神經網路和符號規則的方法,而且會同時擁有比較好的可解釋性和好的結果。今後一個值得探索的方向是,如何去設計更強大的neural-symbolic的模型。
第二個值得關註的方向是如何把文本信息結合進來。因為在實際應用的時候,我們會發現圖譜並不是單獨存在的,往往是和文本信息同時存在的,因此如何在這種混合的數據上面進行知識推理,也將會是一個值得探索的方向。
今天的分享就到這裡,謝謝大家。
本文首發於微信公眾號“DataFunTalk”。

