
隨著短視頻的大火,不僅可以給人們帶來娛樂,還有熱點新聞時事以及各種知識,刷短視頻也逐漸成為了日常生活的一部分。本文以一個簡單的小例子,簡述如何通過Pyhton依托Selenium來爬取短視頻,僅供學習分享使用,如有不足之處,還請指正。 ...
隨著短視頻的大火,不僅可以給人們帶來娛樂,還有熱點新聞時事以及各種知識,刷短視頻也逐漸成為了日常生活的一部分。本文以一個簡單的小例子,簡述如何通過Pyhton依托Selenium來爬取短視頻,僅供學習分享使用,如有不足之處,還請指正。
涉及知識點
- selenium,作為瀏覽器端一個自動化測試工具,可以模擬用戶操作瀏覽器的動作,就像是人自己操作瀏覽器一樣。關於selenium的具體信息如下
- Selenium進行元素定位,主要有ID,Name,ClassName,Css Selector,Partial LinkText,LinkText,XPath,TagName等8種方式。
- Selenium獲取單一元素(如:find_element)和獲取元素數組(如:find_elements)兩種方式。
- Selenium元素定位後,可以給元素進行賦值和取值,或者進行相應的事件操作(如:click)。
- requests,web請求對象,通過selenium獲取到視頻的url後,再通過requests庫進行視頻流的獲取,然後保存成本地視頻文件。
- 瀏覽器開發者工具,通過開發者工具可以查看頁面上某一個按鈕或鏈接等頁面元素對應的html標識。
目標分析
在爬取視頻之前,需要分析目標結構,本視頻爬取分析可分為三步,具體如下所示:
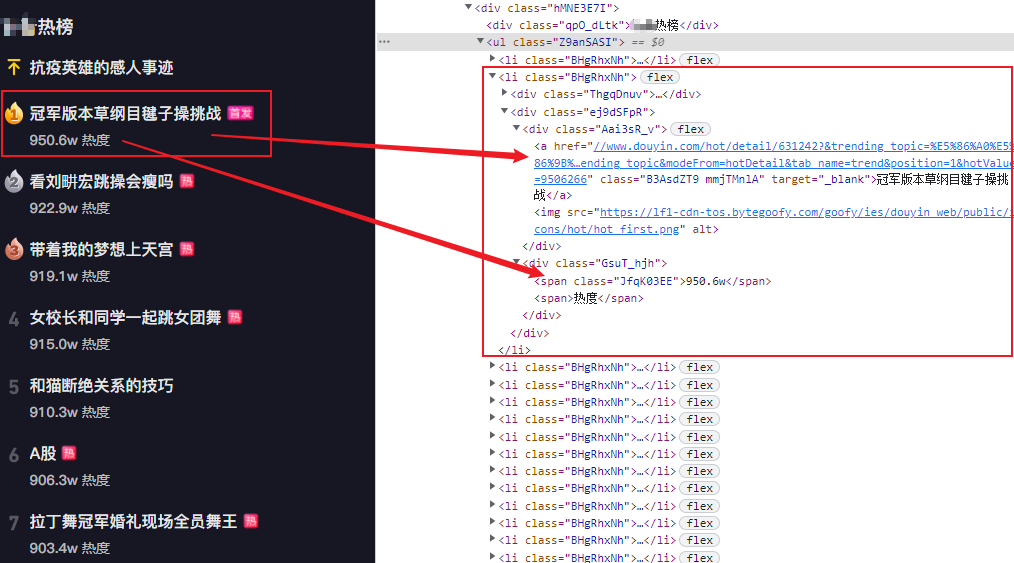
1. 分析熱榜目錄
熱榜目錄是一個ul標簽,每一個熱榜對象一個li子標簽,分別包含熱度,標題等內容。點擊標題鏈接可以進入具體視頻播放頁面,目標分析如下所示:
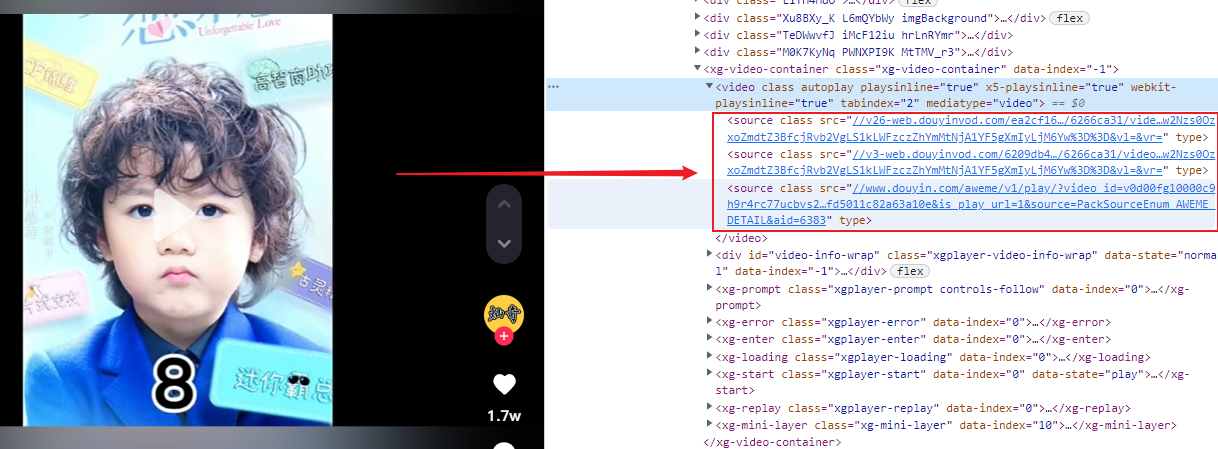
2.分析視頻播放頁面
視頻在video標簽中播放,短視頻播放的真實地址,在video的source子標簽中,且為了保證播放質量,video下有三個source,任取其一即可,如下所示:
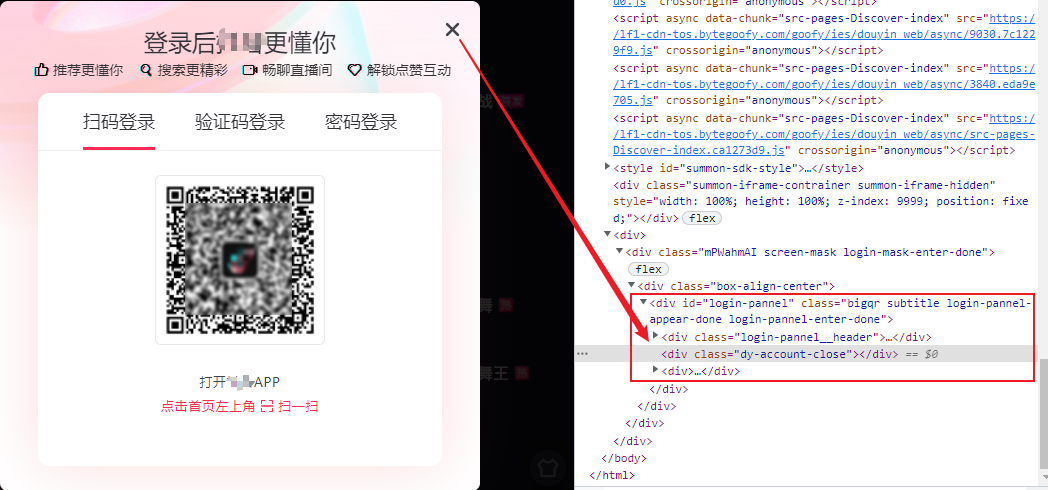
3. 分析彈出框
在爬取過程中,經過彈出需要登錄的視窗,需要及時關閉掉,否則可能會導致找不到頁面元素,從而爬取不成功。如下所示:
核心代碼
經過以上分析,就可以編寫爬蟲代碼了,如下所示:
1. 遍歷熱點目錄
通過獲取頁面上對應的信息,解析出熱點視頻的目錄,如下所示:
1 self.__driver.get(self.__url) 2 self.close_popup_window() 3 # 4. 最大化視窗 4 self.__driver.maximize_window() 5 time.sleep(self.__wait_sec) 6 # 打開以後,根據class=BHgRhxNh獲取ul下的li 7 if self.checkIsExistsByClass(cls='BHgRhxNh'): 8 # 獲取 9 hots = self.__driver.find_elements(by=By.CLASS_NAME, value='BHgRhxNh') 10 hot_infos = [] 11 index = 0 12 for hot in hots: 13 hot_info = {} 14 a = hot.find_element(by=By.TAG_NAME, value='a') 15 href = a.get_attribute("href") 16 text = a.text 17 hot_info['url'] = href 18 hot_info['text'] = text 19 if index > 0: 20 div = hot.find_element(by=By.CLASS_NAME, value='GsuT_hjh') 21 if div is not None: 22 hot_value = div.find_element(by=By.TAG_NAME, value='span').text 23 hot_info['value'] = hot_value 24 hot_infos.append(hot_info) 25 index = index + 1 26 print(hot_infos)
2. 獲取真實短視頻url
打開單個熱點視頻的url,並解析真實短視頻播放url,如下所示:
1 def open_video_html(self, url): 2 """打開具體視頻的頁面""" 3 self.__driver.get(url=url) 4 time.sleep(1) 5 self.close_popup_window() # 關閉彈窗 6 video = self.__driver.find_element(by=By.TAG_NAME, value='video') 7 source = video.find_element(by=By.TAG_NAME, value='source') 8 src = source.get_attribute('src') 9 return src
3. 下載視頻
獲取真實的url後,即可進行下載,如下所示:
1 def download_video(self, url, video_name): 2 """根據視頻源地址進行下載""" 3 if os.path.exists(video_name): 4 # 如果已重新下載過,則不需要再次下載 5 return 6 else: 7 with open(video_name, 'wb') as fp: 8 fp.write(requests.get(url).content)
4. 關閉彈出的登錄視窗
在爬取過程中,經常彈出需要登錄的遮罩視窗,需要進行關閉,如下所示:
1 def close_popup_window(self): 2 try: 3 login = self.__driver.find_element(by=By.ID, value='login-pannel') 4 if login is not None: 5 login.find_element(by=By.CLASS_NAME, value='dy-account-close').click() 6 except BaseException as e: 7 pass 8 try: 9 login = self.__driver.find_element(by=By.CLASS_NAME, value='GaDkStRD') 10 if login is not None: 11 btns = login.find_elements(by=By.TAG_NAME, value='button') 12 for btn in btns: 13 if btn.text == '取消': 14 btn.click() 15 break 16 except BaseException as e: 17 pass
5. 保存日誌
在爬取成功後,對爬取的短視頻的相關內容進行保存,如下所示:
1 def save_data(self, hot_infos): 2 """ 3 保存數據 4 :param res_list: 保存的內容文件 5 :return: 6 """ 7 t = time.strftime("%Y-%m-%d", time.localtime()) 8 with open(f'logs[{t}].json', 'a', encoding='utf-8') as f: 9 res_list_json = json.dumps(hot_infos, ensure_ascii=False) 10 f.write(res_list_json)
示例截圖
程式開發完成後,運行示例如下所示:
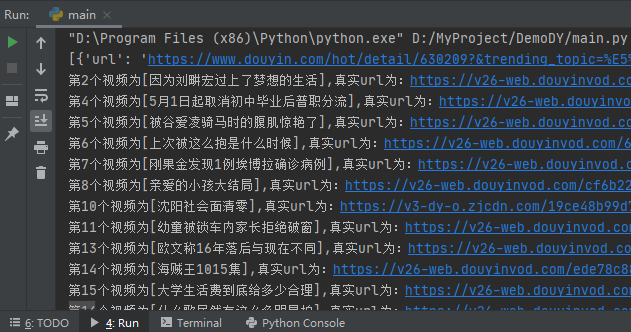
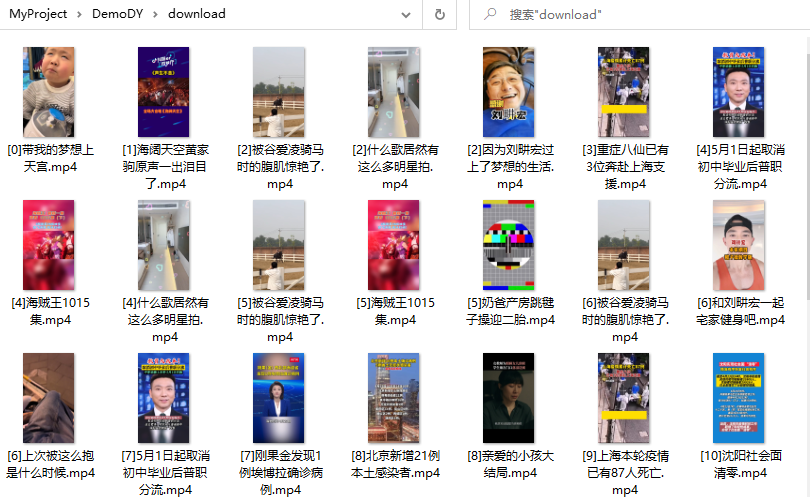
爬取的視頻保存在download目錄下,如下所示:
總結
為什麼會採用selenium進行本次短視頻的爬取,而不直接採用requests庫,原因如下:
- 在對目標網站進行分析的過程中,發現目標網站採用非同步調用的方式數據獲取,即網址請求獲取的只是空殼,並沒有真實的數據。
- 在對非同步介面調用的url進行分析時發現,很多介面的url都具有時效性及有效性驗證,如token,時間戳等,構造起來相當麻煩。
由於以上兩點原因,結合selenium的特點及優勢,所以最終採用selenium進行此次爬蟲的最佳選擇。
備註
以上就是本次爬取短視頻的全部內容,僅供學習分享使用,不足之處,還請指正。
菩薩蠻·書江西造口壁【作者】辛棄疾
鬱孤臺下清江水,中間多少行人淚?西北望長安,可憐無數山。
青山遮不住,畢竟東流去。江晚正愁餘,山深聞鷓鴣。
 作者:小六公子
作者:小六公子
出處:http://www.cnblogs.com/hsiang/
本文版權歸作者和博客園共有,寫文不易,支持原創,歡迎轉載【點贊】,轉載請保留此段聲明,且在文章頁面明顯位置給出原文連接,謝謝。
關註個人公眾號,定時同步更新技術及職場文章


