
1. 前言 上面我們已經做到了介面以及場景壓測,通過控制台輸出結果,我們只需要將結果收集整理下來,最後彙總到excel上,此次壓測報告就可以完成了,但收集報告也挺麻煩的,交給誰呢…… 找了一圈、沒找到願意接手的人,該怎麼辦呢……思考了會兒還是決定看看能否通過程式解決我們的難題吧,畢竟整理表格太累╯﹏ ...
1. 前言
上面我們已經做到了介面以及場景壓測,通過控制台輸出結果,我們只需要將結果收集整理下來,最後彙總到excel上,此次壓測報告就可以完成了,但收集報告也挺麻煩的,交給誰呢……
找了一圈、沒找到願意接手的人,該怎麼辦呢……思考了會兒還是決定看看能否通過程式解決我們的難題吧,畢竟整理表格太累╯﹏╰
2. 收集結果
通過查閱官方文檔,我們發現官方提供了把數據保存成Json、csv、以及資料庫三種方式,甚至還有小伙伴積極的對接要把數據保存到Es中,那選個最簡單的吧!
要不選擇Json吧,不需要依賴外部存儲,很簡單,我覺得應該可試,試一下看看:輸入命令:
crank --config load.benchmarks.yml --scenario api --load.framework net5.0 --application.framework net5.0 --json 1.json --profile local --profile crankAgent1 --description "wrk2-獲取用戶詳情" --profile defaultParamLocal
最後得到結果:
{
"returnCode": 0,
"jobResults": {
"jobs": {
"load": {
"results": {
"http/firstrequest": 85.0,
"wrk2/latency/mean": 1.81,
"wrk2/latency/max": 1.81,
"wrk2/requests": 2.0,
"wrk2/errors/badresponses": 0.0,
"wrk2/errors/socketerrors": 0.0,
"wrk2/latency/50": 1.81,
"wrk2/latency/distribution": [
[
{
"latency_us": 1.812,
"count": 1.0,
"percentile": 0.0
},
{
"latency_us": 1.812,
"count": 1.0,
"percentile": 1.0
}
]
]
}
}
}
}
}
好吧,數據有點少,好像數據不太夠吧,這些信息怎麼處理能做成報表呢,再說了數據不對吧,QPS、延遲呢?好吧,被看出來了,因為信息太多,我刪了一點點(也就1000多行指標信息吧),看來這個不行,用json的話還得配合個程式好難……
csv不用再試了,如果也是單個文本的話,也是這樣,還得配個程式,都不能單干,幹啥都得搭伴,那試試資料庫如何
crank --config load.benchmarks.yml --scenario api --load.framework net5.0 --application.framework net5.0 --sql "Server=localhost;DataBase=crank;uid=sa;pwd=P@ssw0rd;" --table "local" --profile local --profile crankAgent1 --description "wrk2-獲取用戶詳情" --profile defaultParamLocal
我們根據壓測環境,把不同的壓測指標存儲到不同的資料庫的表中,當前是本地環境,即 table = local
最後我們把數據保存到了資料庫中,那這樣做回頭需要報告的時候,我查詢下資料庫搞出來就好了,終於鬆了一口氣,但好景不長,發現資料庫存儲也有個坑,之前json中看到的結果竟然在一個欄位中存儲,不過幸好SqlServer 2016之後支持了json,可以通過json解析搞定,但其中參數名有/等特殊字元,sql server處理不了,難道又得寫個網站才能展示這些數據了嗎??真的繞不開搭伴幹活這個坑嗎?
微軟不會就做出個這麼雞肋的東西,還必須要配個前端才能清楚的搞出來指標吧……還得用vue、好吧,我知道雖然現在有blazer,可以用C#開發,但還是希望不那麼麻煩,又仔細查找了一番,發現Crank可以對結果做二次處理,可以通過script,不錯的東西,既然sql server資料庫無法支持特殊字元,那我加些新參數取消特殊字元不就好了,新建scripts.profiles.yml
scripts:
changeTarget: |
benchmarks.jobs.load.results["cpu"] = benchmarks.jobs.load.results["benchmarks/cpu"]
benchmarks.jobs.load.results["cpuRaw"] = benchmarks.jobs.load.results["benchmarks/cpu/raw"]
benchmarks.jobs.load.results["workingSet"] = benchmarks.jobs.load.results["benchmarks/working-set"]
benchmarks.jobs.load.results["privateMemory"] = benchmarks.jobs.load.results["benchmarks/private-memory"]
benchmarks.jobs.load.results["totalRequests"] = benchmarks.jobs.load.results["bombardier/requests;http/requests"]
benchmarks.jobs.load.results["badResponses"] = benchmarks.jobs.load.results["bombardier/badresponses;http/requests/badresponses"]
benchmarks.jobs.load.results["requestSec"] = benchmarks.jobs.load.results["bombardier/rps/mean;http/rps/mean"]
benchmarks.jobs.load.results["requestSecMax"] = benchmarks.jobs.load.results["bombardier/rps/max;http/rps/max"]
benchmarks.jobs.load.results["latencyMean"] = benchmarks.jobs.load.results["bombardier/latency/mean;http/latency/mean"]
benchmarks.jobs.load.results["latencyMax"] = benchmarks.jobs.load.results["bombardier/latency/max;http/latency/max"]
benchmarks.jobs.load.results["bombardierRaw"] = benchmarks.jobs.load.results["bombardier/raw"]
以上處理的數據是基於bombardier的,同理大家可以完成對wrk或者其他的數據處理
通過以上操作,我們成功的把特殊字元的參數改成了沒有特殊字元的參數,那接下來執行查詢sql就可以了。
SELECT Description as '場景',
JSON_VALUE (Document,'$.jobs.load.results.cpu') AS 'CPU使用率(%)',
JSON_VALUE (Document,'$.jobs.load.results.cpuRaw') AS '多核CPU使用率(%)',
JSON_VALUE (Document,'$.jobs.load.results.workingSet') AS '記憶體使用(MB)',
JSON_VALUE (Document,'$.jobs.load.results.privateMemory') AS '進程使用的私有記憶體量(MB)',
ROUND(JSON_VALUE (Document,'$.jobs.load.results.totalRequests'),0) AS '總發送請求數',
ROUND(JSON_VALUE (Document,'$.jobs.load.results.badResponses'),0) AS '異常請求數',
ROUND(JSON_VALUE (Document,'$.jobs.load.results.requestSec'),0) AS '每秒支持請求數',
ROUND(JSON_VALUE (Document,'$.jobs.load.results.requestSecMax'),0) AS '每秒最大支持請求數',
ROUND(JSON_VALUE (Document,'$.jobs.load.results.latencyMean'),0) AS '平均延遲時間(us)',
ROUND(JSON_VALUE (Document,'$.jobs.load.results.latencyMax'),0) AS '最大延遲時間(us)',
CONVERT(varchar(100),DATEADD(HOUR, 8, DateTimeUtc),20) as '時間'
FROM dev;
3. 如何分析瓶頸
通過上面的操作,我們已經可以輕鬆的完成對場景的壓測,並能快速生成相對應的報表信息,那正題來了,可以模擬高併發場景,那如何分析瓶頸呢?畢竟報告只是為了知曉當前的系統指標,而我們更希望的是知道當前系統的瓶頸是多少,怎麼打破瓶頸,完成突破呢……
首先我們要先瞭解我們當前的應用的架構,比如我們現在使用的是微服務架構,那麼
- 應用拆分為幾個服務?瞭解清楚每個服務的作用
- 服務之間的調用關係
- 各服務依賴的基礎服務有哪些、基礎服務基本的信息情況
舉例我們當前的微服務架構如下:
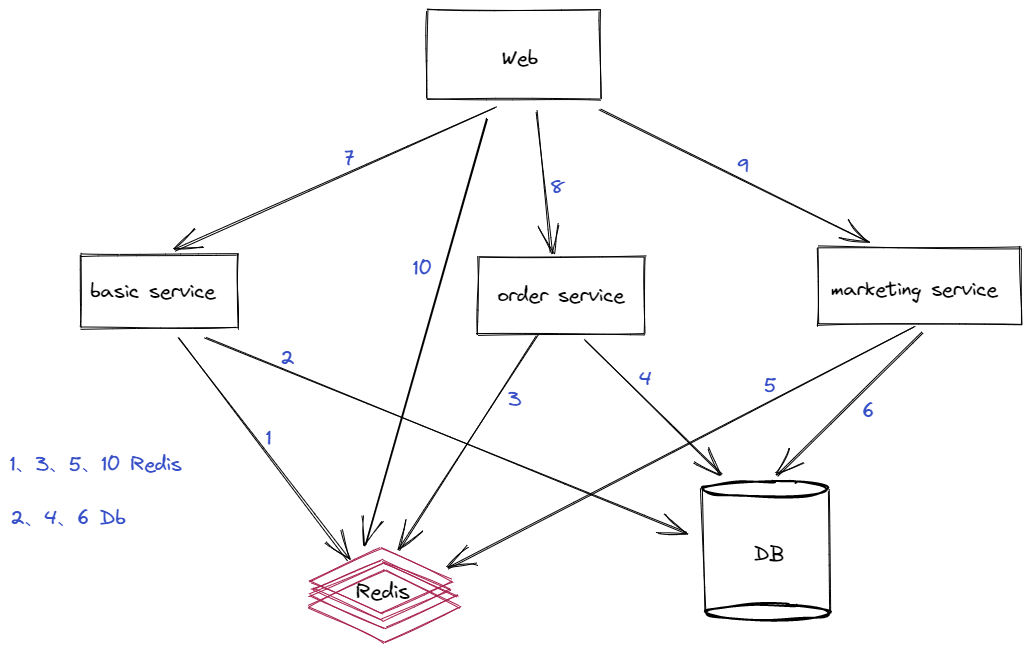
通過架構圖可以快速瞭解到項目結構,我們可以看到用戶訪問web端,web端根據請求對應去查詢redis或者通過http、grpc調用服務獲取數據、各服務又通過redis、db獲取數據。
首先我們先通過crank把當前的數據指標保存入庫。調出其中不太理想的介面開始分析。
在這裡我們拿兩個壓測介面舉例:
- 獲取首頁Banner、QPS:3800 /s (Get)
- 下單、QPS:8 /s (Post)
3.1. 獲取首頁Banner
通過單測首頁banner的介面,QPS是3800多不到4000這樣,雖然這個指標還不錯,但我們仍然覺得很慢,畢竟首頁banner就是很簡單幾個圖片+標題組合的數據,數據量不大,並且是直連Redis,僅在Redis不存在時才查詢對應服務獲取banner數據,這樣的QPS實在不應該,並且這個還是僅壓測單獨的banner,如果首頁同時壓測十幾個介面,那其性能會暴降十倍不止,這樣肯定是不行的
我們又壓測了一次首頁banner介面,發現有幾個疑點:
- redis請求數徘徊在3800左右的樣子,網路帶寬占用1M的樣子,無法繼續上漲
- 查看web服務,發現時不時的會有調用服務超時出錯的問題,Db的訪問量有上漲,但不明顯,很快就下去了
思考: Redis的請求數與最後的壓測結果差不多,最後倒也對上了,但為什麼redis的請求數這麼低呢?難道是帶寬限制!!
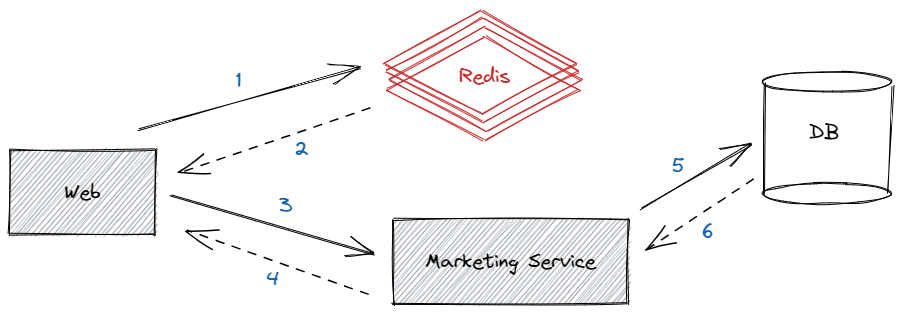
雖然是單機redis,但4000也絕對不可能是它的瓶頸,懷疑是帶寬被限制了,應該就是帶寬被限制了,後來跟運維一番切磋後,得到結論是redis沒限制帶寬……
那為什麼不行呢,這麼奇怪,redis不可能就這麼點併發就不行了,算了還是寫個程式試一下吧,看看是不是真的測試環境不給力,redis配置太差了,一番操作後發現,同一個redis數據,redis讀可以到6萬8,不到7萬、帶寬占用10M,redis終於洗清了它的嫌疑,此介面的QPS不行與Redis無關,但這麼簡單的一個結構為什麼QPS就上不去呢……,如果不是redis的問題,那會不會是因為請求就沒到redis上,是因為壓測機的強度不夠,導致請求沒到redis……當時冒出來這個有點愚蠢的想法,那就增加壓測機的數量,通過更改負載壓測機配置,1台壓測機升到了3台,但可惜的是單台壓測機的指標不升反降,最後所有壓測機的指標加到一起正好與之前一臺壓測機的壓測結果差不多一樣,那說明QPS低與壓測機無關,後來想到試試通過增加多副本來提升QPS,後來web副本由1台提升到了3台,之前提到的服務調用報錯的情況更加嚴重,之前只是偶爾有一個錯誤,但提升web副本後,看到一大片的錯誤
- 提示Thread is busy,很多線程開始等待
- 大量的服務調用超時,DB查詢緩慢
最後QPS 1000多一點,有幾千個失敗的錯誤,這盲目的提升副本貌似不大有效,之前儘管Qps不高,但起碼也在4000,DB也沒事,這波神操作後QPS直降4分之3,DB還差點崩了,思想滑坡了,做了負優化……
繼續思考,為何提升副本,QPS不升反降,為何出現大量的調用超時、為何DB會差點被乾崩,我只是查詢個redis,跟DB有毛關係啊!奇了怪了,看看代碼怎麼寫的吧……燒腦
public async Task<List<BannerResponse>> GetListAsync()
{
List<BannerResponse> result = new List<BannerResponse>();
try
{
var cacheKey = "banner_all";
var cacheResult = await _redisClient.GetAsync<List<BannerResponse>>(cacheKey);
if (cacheResult == null)
{
result = this.GetListServiceAsync().Result;
_redisClient.SetAsync(cacheKey, result, new()
{
DistributedCacheEntryOptions = new()
{
AbsoluteExpirationRelativeToNow = TimeSpan.FromDays(5)
}
}).Wait();
}
else
{
result = cacheResult;
}
}
catch (Exception e)
{
result = await this.GetListServiceAsync();
}
return result;
}
看了代碼後發現,僅當Reids查詢不到的時候,會調用對應服務查詢數據,對應服務再查詢DB獲取數據,另外查詢異常時,會再次調用服務查詢結果,確保返回結果一定是正確的,看似沒問題,但為何壓測會出現上面那些奇怪現象呢……
請求超時、大量等待,那就是正好redis不存在,穿透到對應的服務查詢DB了,然後壓測同一時刻數據量過大,同一時刻查詢到的Reids都是沒有數據,最後導致調用服務的數量急劇上升,導致響應緩慢,超時加劇,線程因超時釋放不及時,又導致可用線程較少。
這塊我們查找到對應的日誌顯示以下信息
System.TimeoutException: Timeout performing GET MyKey, inst: 2, mgr: Inactive, queue: 6, qu: 0, qs: 6, qc: 0, wr: 0, wq: 0, in: 0, ar: 0,
IOCP: (Busy=6,Free=994,Min=8,Max=1000),
WORKER: (Busy=152,Free=816,Min=8,Max=32767)
- 那麼我們可以調整Startup.cs:
public void ConfigureServices(IServiceCollection services)
{
ThreadPool.GetMinThreads(out int workerThreads, out int completionPortThreads);
ThreadPool.SetMinThreads(1000, completionPortThreads);//根據情況調整最小工作線程,避免因創建線程導致的耗時操作
……………………………………………………………此處省略…………………………………………………………………………………………………………
}
web服務調用底層服務太慢,那麼提升底層服務的響應速度(優化代碼)或者提高處理能力(提升副本)
- 防止高併發情況下全部穿透到下層,增加底層服務的壓力
前兩點也是一個好的辦法,但不是最好的解決辦法,最好還是不要穿透到底層服務,如果reids不存在,就放一個請求過去是最好的,拿到數據就持久化到redis,不要總穿透到下層服務,那麼怎麼做呢,最簡單的辦法就是使用加鎖,但加鎖會影響性能,但這個我們能接受,後來調整加鎖測試,穿透到底層服務的情況沒有了,但很可惜,請求數確實會隨著副本的增加而增加,但是實在是有點不好看,後來又測試了下另外一個獲取緩存數據的結果,結果QPS:1000多一點,比banner還要低的多,兩邊明明都使用的是Reids,性能為何還有這麼大的差別,為何我們寫的redis的demo就能到6萬多的QPS,兩邊都是拿的一個緩存,差距有這麼大?難道是封裝redis的sdk有問題?後來仔細對比了後來寫的redis的demo與banner調用redis的介面發現,一個是直接查詢的redis的字元串,一個是封裝redis的sdk,多了一個反序列化的過程,最後經過測試,反序列化之後性能降低了十幾倍,好吧看來只能提升副本了……但為何另外的介面也是從redis獲取,性能跟banner的介面不一樣呢!!
經過仔細對比發現,差別是信息量,QPS更低的介面的數據量更大,那結果就有了,隨著數據量的增加,QPS會進一步降低,那這樣一來的話,增加副本的作用不大啊,誰知道會不會有一個介面的數據量很大,那性能豈不是差的要死,那還怎麼玩,能不能提升反序列化的性能或者不反序列化呢,經過認真思考,想到了二級緩存,如果用到了二級緩存,記憶體中有就不需要查詢redis,也不需要再反序列化,那麼性能應該有所提升,最後的結構如下圖:
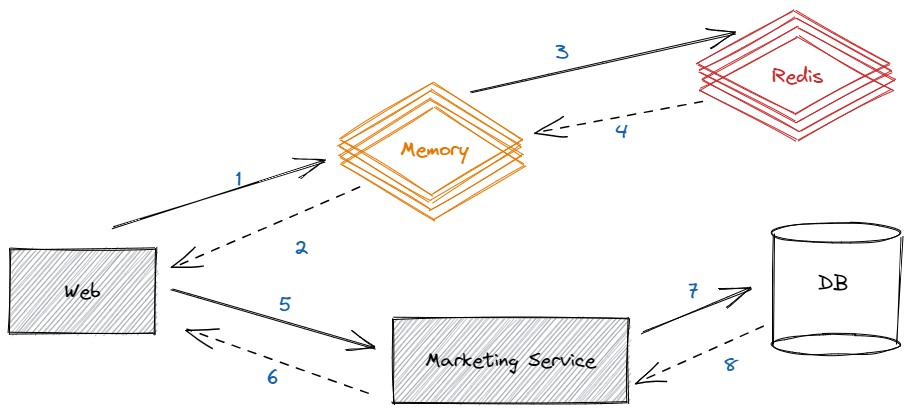
最後經過壓測發現,單副本QPS接近50000,比最開始提升12倍,並且也不會出現服務調用超時,DB崩潰等問題、且記憶體使用平穩
此次壓測發現其banner這類場景的性能瓶頸在反序列化,而非Redis、DB,如果按照一開始不清楚其工作原理、盲目的調整副本數,可能最後會加劇系統的雪崩,而如果我們把DB資源、Redis資源盲目上調、並不會對最後的結果有太大幫助,最多也只是延緩崩潰的時間而已
3.2. 下單
下單的QPS是8,這樣的QPS已經無法忍受了,每秒只有十個請求可以下單成功,如果中間再出現一個庫存不足、賬戶餘額不足、活動資格不夠等等,實際能下單的人用一個手可以數過來,真的就這麼慘……雖然下單確實很費性能,不過確實不至於這麼低吧,先看下下單流程吧
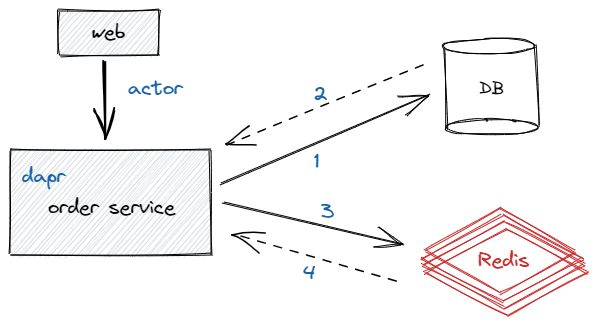
簡化後的下單流程就這麼簡單,web通過dapr的actor服務調用order service,然後就是漫長的查詢db、操作redis操作,因涉及業務代碼、具體代碼就不再放出,但可以簡單說一下其中做的事情,檢查賬戶餘額、反覆的增加redis庫存確保庫存安全、檢查是否滿足活動、為推薦人計算待結算佣金等等一系列操作,整個看下來把人看懵了,常常是剛看了上面的,看下麵代碼的時候忘記上面具體幹了什麼事,代碼太多了,一個方法數千行,其中再調用一些數百行的代碼,真的吐血了,不免感嘆我司的開發小哥哥是真的強大,這麼複雜的業務居然能這麼"順暢"的跑起來,後面還有N個需求等待加到下單上,果然不是一般人
不過話說回來,雖然是業務是真的多,也真的亂,不過這樣搞也不至於QPS才只有8這麼可憐吧,伺服器的處理能力可不是二十幾年前的電腦可以比擬的,單副本8核16G的配置不支持這麼拉胯吧,再看一下究竟誰才是真正的幕後黑手……
但究竟哪裡性能瓶頸在哪裡,這塊就要出殺手鐧了
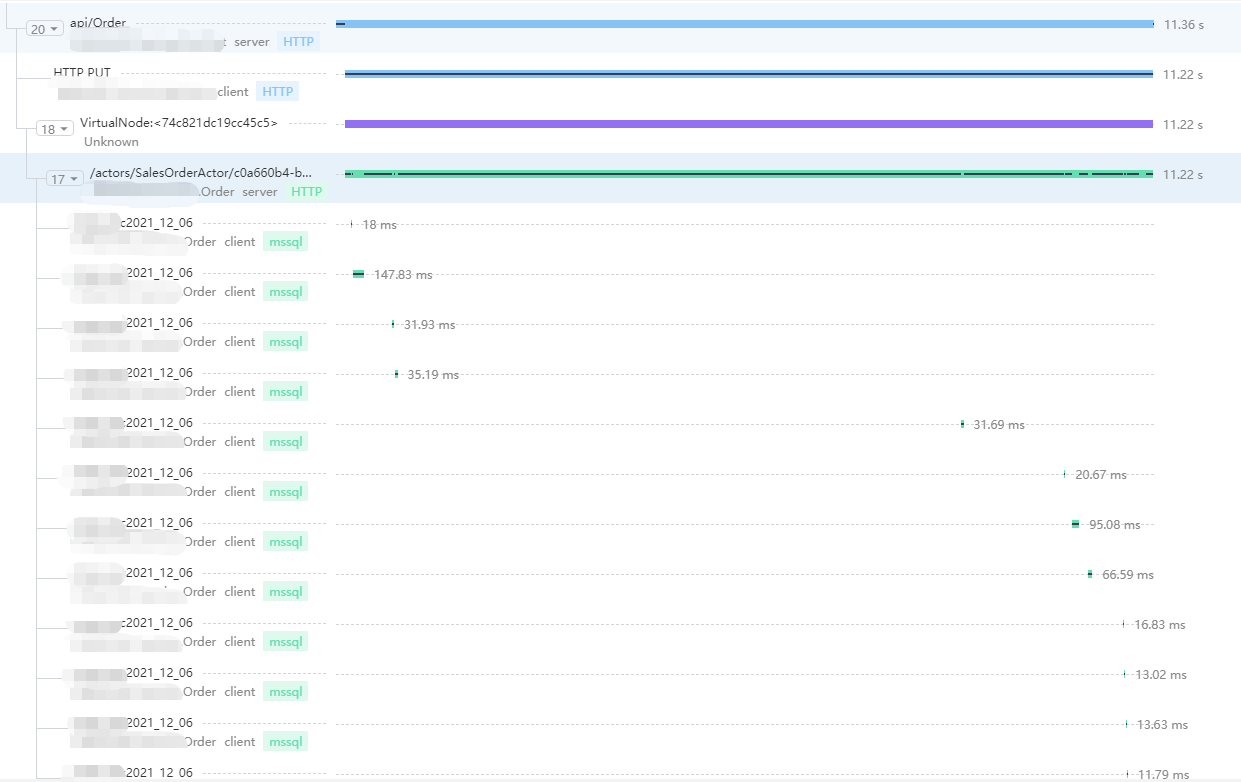
通過Tracing可以很清楚的看到各節點的耗時情況,這將對我們分析瓶頸提供了非常大的幫助、我們看到了雖然有幾十次的查詢DB操作,但DB還挺給力,基本也再很短時間內就給出了響應,那剩餘時間耗費到了哪裡呢?我們看到整體耗時11s、但查詢Db加起來也僅僅不到1s,那麼剩餘操作都在哪裡?要知道哪怕我們優化DB查詢性能,減少DB查詢,那提升的性能對現在的結果也是微乎其微
結合Tracing以及下單流程圖,我們發現從Web到Order Service是通過actor來實現的,那會不是這裡耗時影響的呢?
但dapr是個新知識、開發的小哥哥速度真快,這麼快就用上dapr了(ˇˍˇ)不知道小哥哥的頭髮還有多少……
快速去找到下單使用actor的地方,如下:
[HttpPost]
[Authorize]
public async Task<CreateOrderResponse> CreeateOrder([FromBody] CreateOrderModel request)
{
string actionType = "SalesOrderActor";
var salesOrderActor = ActorProxy.Create<ISalesOrderActor>(new ActorId(request.SkuList.OrderBy(sku => sku.Sku).FirstOrDefault().Sku), actionType);
request.AccountId = Account.Id;
var result = await salesOrderActor.CreateOrderAsync(request);
return new Mapping<ParentSalesOrderListViewModel, CreateOrderResponse>().Map(result);
}
我們看到了這邊代碼十分簡單,獲取商品信息的第一個sku編號作為actor的actorid使用,然後得到下單的actor,之後調用actor中的創建訂單方法最後得到下單結果,這邊的代碼太簡單了,讓人心情愉快,那這塊會不會有可能影響下單速度呢?它是不是那個性能瓶頸最大的幕後黑手?
首先這塊我們就需要瞭解下什麼是Dapr、Actor又是什麼,不瞭解這些知識我們只能靠抓鬮來猜這塊是不是瓶頸了……
Dapr 全稱是Distributed Application Runtime,分散式應用運行時,並於今年加入了 CNCF 的孵化項目,目前Github的star高達16k,相關的學習文檔在文檔底部可以找到,我也是看著下麵的文檔瞭解dapr
通過瞭解actor,我們發現用sku作為actorid是極不明智的選擇,像秒殺這類商品不就是搶的指定規格的商品嗎?如果這樣一來,這不是在壓測actor嗎?這塊我們跟對應的開發小哥哥溝通了下,通過調整actorid順利將Qps提升到了60作用,後面又通過優化減少db查詢、調整業務規則的順序等操作順利將QPS提升到了不到一倍,雖然還是很低,不過接下來的優化工作就需要再深層次的調整業務代碼了……
4. 總結
通過實戰我們總結出分析瓶頸從以下幾步走:
- 通過第一輪的壓測獲取性能差的介面以及指標
- 通過與開發溝通或者自己查看源碼的方式梳理介面流程
- 通過分析其項目所占用資源情況、依賴第三方基礎占用資源情況以及Tracing更進一步的確定瓶頸大概的點在哪幾塊
- 通過反覆測試調整確定性能瓶頸的最大黑手
- 將最後的結論與相關開發、運維人員溝通,確保都知曉瓶頸在哪裡,最後優化瓶頸
知識點:
- Dapr
- Tracing
- OpenTracing 簡介、關於OpenTracing後續我們也會開源,可以提前關註我們的開源項目
開源地址
MASA.BuildingBlocks:https://github.com/masastack/MASA.BuildingBlocks
MASA.Contrib:https://github.com/masastack/MASA.Contrib
MASA.Utils:https://github.com/masastack/MASA.Utils
MASA.EShop:https://github.com/masalabs/MASA.EShop
MASA.Blazor:https://github.com/BlazorComponent/MASA.Blazor
如果你對我們的 MASA Framework 感興趣,無論是代碼貢獻、使用、提 Issue,歡迎聯繫我們



