
前言 其中的過程適用於靜態網頁(豆瓣電影信息、嗶哩嗶哩評論區等)、動態頁面(百度圖片滾輪觸發頁面更新、下拉框觸發頁面更 新等url不變但通過滑鼠互動,致使信息更新等場景)的信息爬取。 基本適用於所有網頁信息的爬取,但代碼不夠簡潔,下述流程不夠詳細。 1 Selenium安裝 Python學習交流Q群 ...
前言
其中的過程適用於靜態網頁(豆瓣電影信息、嗶哩嗶哩評論區等)、動態頁面(百度圖片滾輪觸發頁面更新、下拉框觸發頁面更
新等url不變但通過滑鼠互動,致使信息更新等場景)的信息爬取。
基本適用於所有網頁信息的爬取,但代碼不夠簡潔,下述流程不夠詳細。

1 Selenium安裝
Python學習交流Q群:906715085#### (1)pip install selenium (2)以edge為例,安裝驅動。url:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/ (3)Selenium的網頁信息定位主要使用xpath表達式,需要對其有所瞭解,利用edge中的擴展,可以極大的簡化定位過程,但是不能取代個人工作,還是要對xpath有所瞭解,擴展如圖1。

2 案例:以經合組織(OECD)為例,如圖1
url: https://stats.oecd.org/Index.aspx?DataSetCode=CS_BAROMETER#
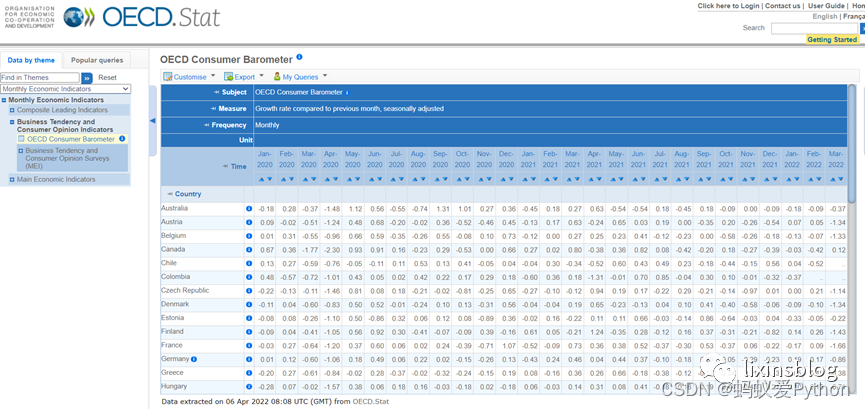
最終結果:
原頁面數據:
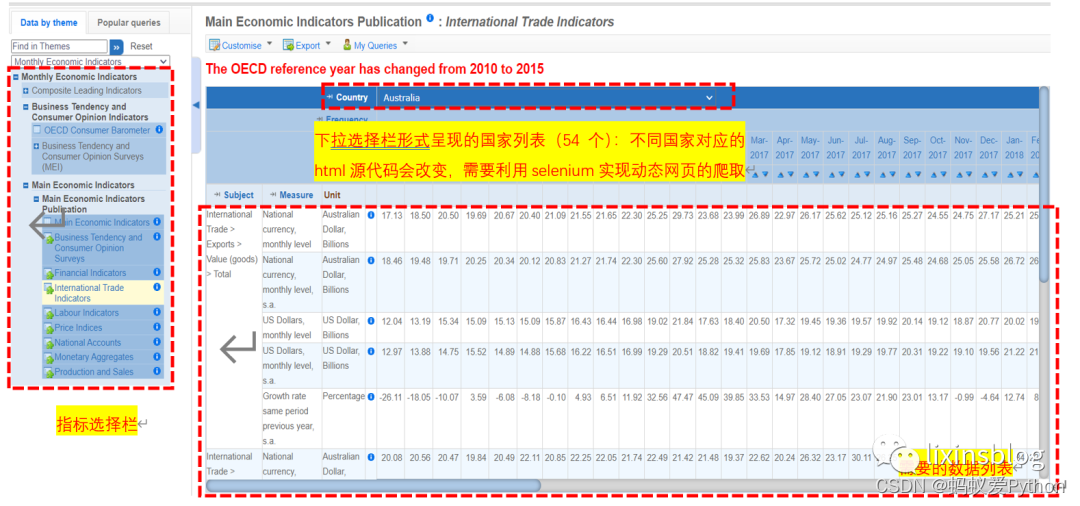
爬取到的數據(簡潔起見,以international trade index為例,但是爬取的各個過程均有涉及,其他指標、數據以及網頁只要做簡單
推廣即可,這個流程基本可以實現所有網頁信息的爬取):

3 流程
(1)需要的python庫;
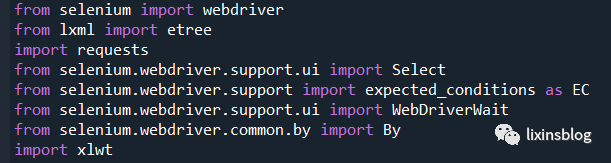
(2)獲取初始網頁;

(3)展開指標欄,並選取international trade index;
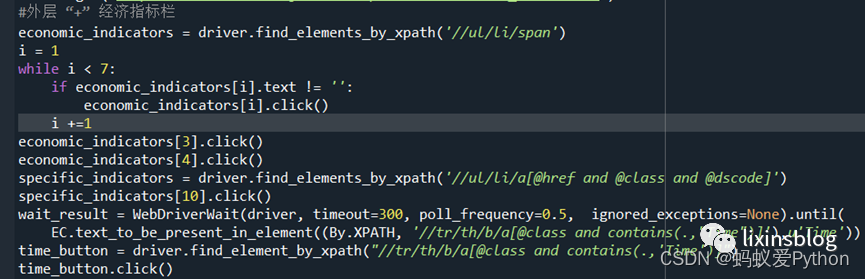

(4)將時間定位到2021年,其餘時間不要;
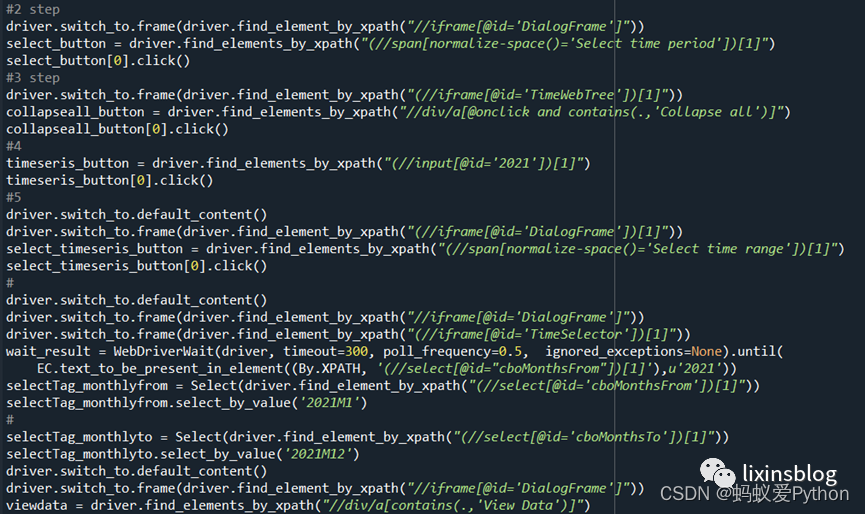
(5)獲取表頭:年月/國家信息;
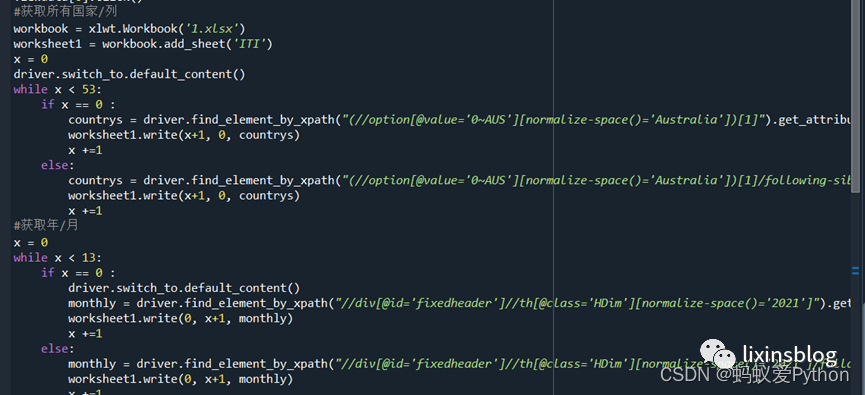
(6)獲取指標信息;
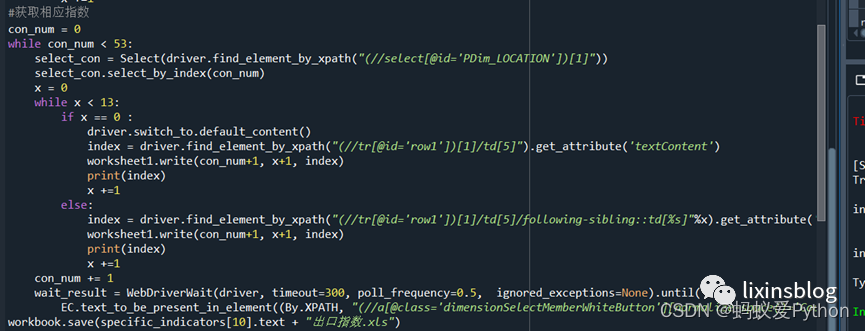
Notice:
1.註意隱藏數據。利用xpth定位源代碼時,明明沒有任何問題,但python報錯,顯示無此元素,此時應註意是否是隱藏元素,查看是否在iframe內,上述代碼中對這一問題做了處理;
2.註意每個網頁的刷新時間,需根據時間設置time.sleep或者WebDriverWait;


