
記錄自己是如何分析地震數據集,使用模塊,剋服一系列 bug 的過程。經緯度轉換省份城市、讀取 csv、多圖表合併 pyecharts、導入模塊、省份強震次數圖、地震震級分佈圖、國內前十大地震、震級震源深度散點圖、世界地震熱力圖、中國地震熱力圖、年月地震次數曲線圖、24小時段地震發生百分比圖、最大震級... ...
前情提要
編寫這篇文章是為了記錄自己是如何分析地震數據集,使用模塊,剋服一系列 \(bug\) 的過程。如果你是 \(python\) 初入數據分析的小白,那麼這篇文章很適合你。閱讀欄目時建議不要跳過任何步驟,從頭看到尾你會收穫很多。
本篇文章代碼註釋使用了 \(vscode\) 的 better-comments 拓展
數據獲取
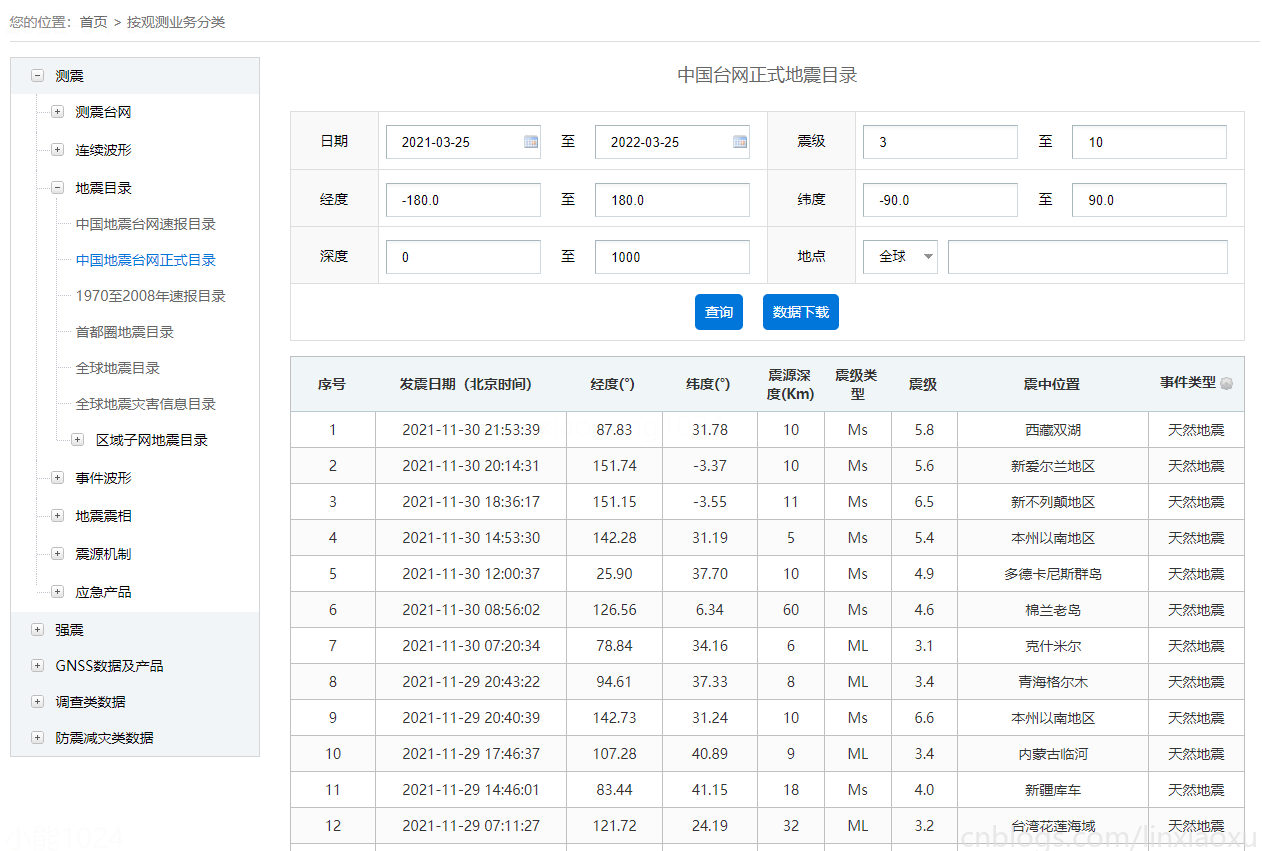
數據來源於中國地震台網中心 國家地震科學數據中心
我們挑選時間範圍 12 年內,震級 >= 3 級的數據集。低於3級的為無感地震,出現次數較為頻繁不作考慮。
![]()
運行環境
\(Python\) 版本 \(3.10.2\),使用模塊(包含兩個主流繪圖庫)
- \(pyecharts\)
- \(plotly\)
- \(requests\)
- \(pandas\)
- \(numpy\)
基本目標
讀取數據
從 excel 讀取
# ^ 讀取中國地震數據集
data = pd.read_excel("./china.xls")
data.columns = ["id", "date", "lon", "lat", "depth", "type", "level", "loc", "incident"]
print(data.shape, "\n", data.dtypes)
(6848, 9)
id int64
date datetime64[ns]
lon float64
lat float64
depth int64
type object
level float64
loc object
incident object
dtype: object
讀取數據集的方式很簡單,由於列名為中文且帶有特殊符號,我們這裡對其進行簡化全部修改為英文。可以直接修改 \(dataframe\) 的屬性。或者使用 \(rename\) 方法。
\(read\_excel\) 更多參數可參考 pandas.read_excel — pandas 1.4.2 documentation (pydata.org)
數據清洗
一般來說中國地震台網中心提供的數據比較權威,不會有問題。但是為了以防萬一,我們還是要進行數據清理,刪除空行、重覆行。
# ^ 數據清理
# @ 統計NaN個數
x = data.isnull().sum().sum()
# @ 第一次sum()算出各個列有幾個,第二次算出全部
print('共有NaN:', x)
# @ 統計重覆行個數
x = data.duplicated().sum()
print('共有重覆行:', x)
共有NaN: 0
共有重覆行: 0
可以看出數據還是比較可靠的。
經緯度轉換省份城市
申請 api
註冊高德地圖個人開發者,申請API,選擇 Web服務。申請完成後查看開發文檔,選擇坐標轉換。
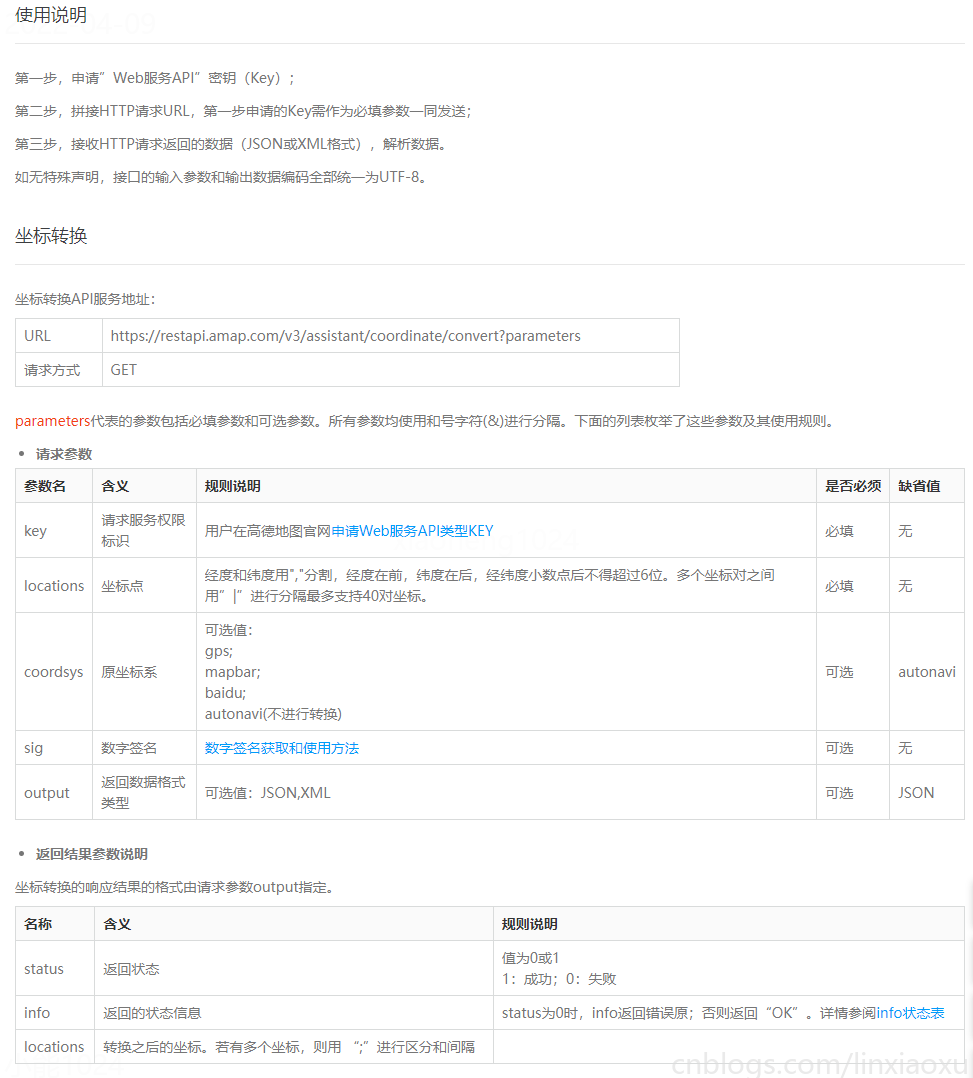
為了讓函數能夠重覆使用、整體代碼更加簡潔,將坐標轉換的方法分離出來單獨放入一個 \(utils.py\) 工具包類。
數據迭代方式
比較以下兩種方式獲取的數據
df = data.head(3)
# ^ 選取其中兩列,分別是經度緯度
print(df[['lon', 'lat']])
print(df[['lon', 'lat']].values)
lon lat
0 87.83 31.78
1 94.61 37.33
2 107.28 40.89
[[ 87.83 31.78]
[ 94.61 37.33]
[107.28 40.89]]
可以看到 \(.values\) 返回的是可迭代的 \(numpy\) 數組對象。我們就可以按照介面規定的方式發送請求了。
Return a Numpy representation of the DataFrame.
Only the values in the DataFrame will be returned, the axes labels will be removed.
測試 api 介面
import requests
# ^ 測試 API 介面 坐標轉換
location = "{0[0]},{0[1]}".format([87.83, 31.78])
url = 'https://restapi.amap.com/v3/geocode/regeo?'
params = {
'location': location,
'key': '不給你看',
'extensions': 'base',
'batch': 'false',
'roadlevel': 0,
}
r = requests.get(url, params=params)
data = r.json()
print(data)
{'status': '1', 'regeocode': {'addressComponent': {'city': '那曲市', 'province': '西藏自治區', 'adcode': '540630', 'district': '雙湖縣', 'towncode': '540630100000', 'streetNumber': {'number': [], 'direction': [], 'distance': [], 'street': []}, 'country': '中國', 'township': '措折
羅瑪鎮', 'businessAreas': [[]], 'building': {'name': [], 'type': []}, 'neighborhood': {'name': [], 'type': []}, 'citycode': '0896'}, 'formatted_address': '西藏自治區那曲市雙湖縣措折羅瑪鎮'}, 'info': 'OK', 'infocode': '10000'}
通過測試介面拿到的 \(json\) 中,我們關心的數據是 \(regeocode\) -> \(addressComponent\) -> \(city、province\)
上面代碼中關於字元串格式化 \(format\) 更多的信息參考 Python format 格式化函數 | 菜鳥教程 (runoob.com)
編寫函數(have bug)
def latitude_longitude_conversion(df):
# step 將經緯度坐標轉換為省份城市,作為兩列添加到df
citys = []
provinces = []
# ^ 選取其中兩列, 分別是經度緯度
for location in df[['lon', 'lat']].values:
# ^ 將每行的經緯度轉換成特定字元串
location = "{0[0]},{0[1]}".format(location)
url = 'https://restapi.amap.com/v3/geocode/regeo?'
params = {
'location': location,
'key': API_KEY,
'extensions': 'base',
'batch': 'false',
'roadlevel': 0,
}
# ^ 發送 get 請求
r = requests.get(url, params=params)
# ^ 接收數據轉換為 json 格式
data = r.json()['regeocode']
city = data['addressComponent']['city']
province = data['addressComponent']['province']
# ^ 上海市,上海市
if len(city) == 0:
city = province
citys.append(city)
provinces.append(province)
df['city'] = citys
df['province'] = provinces
迴圈遍歷然後把省份城市加到兩個數組內,最後再綁定到 \(dataframe\) 的兩個新列上。
if len(city) == 0:
city = province
這部分代碼的意思是假如拿到的 \(city\) 為空,應當把省份給 \(city\),否則會出現數據預設。
測試函數(find bug)
from utils import latitude_longitude_conversion
# ^ 測試經緯度坐標轉換
df_test = data.head(3)
latitude_longitude_conversion(df_test)
print(df_test)
引入編寫的工具庫函數,進行測試。警告如下
SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead
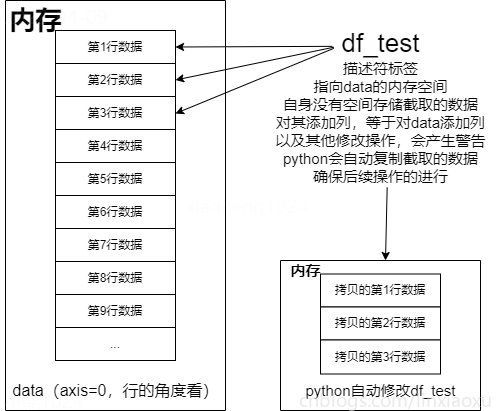
變數 \(df\)(df_test) 其實是一個“標簽”(描述符)而不是一個“容器”。截取數據的前三行,\(df\) 實際是一個指向 \(data\) 前三行的描述符,在記憶體中並沒有為 \(df\) 分配新的地址存儲希望截取的數據。
因此針對 \(df\) 的修改,會產生警告。因為 \(df\) 既沒有數據也沒有列名,其指向的是 \(data\) 的前三行。
這就是 \(python\) 所謂的“鏈式索引”(chained indexing)而引起的錯誤或警告。
但 \(python\) 比較聰明,為了防止報錯退出程式,會自己拷貝一份我們希望截取的內容,使 \(df\) 指向拷貝的數據塊,才能完成變更列名以及完成後面的計算。
解決方法是在截取數據的語句後加一個 \(.copy()\) 複製一份數據給 \(df\) 。
最終函數(fix bug)
def latitude_longitude_conversion(df):
# step 將經緯度坐標轉換為省份城市,作為兩列添加到df
df = df.copy()
citys = []
provinces = []
# ^ 選取其中兩列, 分別是經度緯度
for location in df[['lon', 'lat']].values:
# ^ 將每行的經緯度轉換成特定字元串
location = "{0[0]},{0[1]}".format(location)
url = 'https://restapi.amap.com/v3/geocode/regeo?'
params = {
'location': location,
'key': API_KEY,
'extensions': 'base',
'batch': 'false',
'roadlevel': 0,
}
# ^ 發送 get 請求
r = requests.get(url, params=params)
# ^ 接收數據轉換為 json 格式
data = r.json()['regeocode']
city = data['addressComponent']['city']
province = data['addressComponent']['province']
# ^ 上海市,上海市
if len(city) == 0:
city = province
citys.append(city)
provinces.append(province)
df['city'] = citys
df['province'] = provinces
return df
在第一行加 df = df.copy() ,併在末尾添加 return df
再次測試(final)
還是原來的代碼,這裡我們限定一些列防止行輸出過長。
# ^ 測試經緯度坐標轉換
df_test = data.head(3)
df_test = latitude_longitude_conversion(df_test)
print(df_test[['id', 'lon', 'lat', 'level', 'city', 'province']])
id lon lat level city province
0 1 87.83 31.78 5.8 那曲市 西藏自治區
1 2 94.61 37.33 3.4 海西蒙古族藏族自治州 青海省
2 3 107.28 40.89 3.4 巴彥淖爾市 內蒙古自治區
成功通過介面處理數據!
保存為 csv
因為介面有使用次數限制,為了方便後續調試。我們將 \(6000\) 多行數據統一轉換,保存為 \(csv\) 文件。這也會加快 \(pandas\) 模塊讀取數據集的速度。
# ^ 將所有數據坐標進行轉換並保存為 csv 文件
data = latitude_longitude_conversion(data)
data.to_csv('china_new.csv', index=False)
由於是單線程,網路速率不是很快,等待時間會長一點,處理完成後是圖下結果。

讀取 csv
# STEP 讀取數據集
data = pd.read_csv('./china_new.csv')
print(data.shape)
# STEP 對 city、province 進行修改
data["province"].replace("[]", "其他", inplace=True)
data["city"].replace("[]", "其他", inplace=True)
data["province"].replace("中華人民共和國", "其他", inplace=True)
data["city"].replace("中華人民共和國", "其他", inplace=True)
有部分境內但沒有明確城市省份的地震統一歸為其他(一般為海域、邊境地區)。 對 \(city、province\) 進行替換
多圖表合併 pyecharts
像生成了許多 \(html\) 圖表文件,可以使用 \(echarts.Page\) 統一合併為一個 \(html\) 文件。
# STEP 多圖表合併
page = Page(layout=Page.SimplePageLayout)
page.add(
depth_info, level_info, c5, c1, c2, c3, c4, c6, c7, c8, c9_1, c9_2, c9_3, c10, c11
) # 可以多次添加 pycharts 圖表信息
page.render("完整版.html")
這段代碼放在末尾,用於一次性生成完整的 \(html\) 文件,具體可參考
Page - Page_simple_layout - Document (pyecharts.org)
導入模塊
\(pyecharts\) 和 \(plotly\) 分開寫在兩個文件中,引入需要的庫。
import pandas as pd
import numpy as np
from utils import province_to_short
from pyecharts import options as opts
from pyecharts.charts import WordCloud, Page, Bar, Scatter, Line
from pyecharts.globals import SymbolType, ThemeType
from pyecharts.charts import Map
from pyecharts.components import Table
from pyecharts.options import ComponentTitleOpts
from pyecharts.commons.utils import JsCode
import plotly.graph_objects as go
import plotly.express as px
import pandas as pd
省份強震次數圖
地震級別劃分標準
M>=4.5級的屬於可造成破壞的地震,但破壞輕重還與震源深度、震中距等多種因素有關。發震時刻、震級、震中統稱為"地震三要素"。
- M≥3級,小於4.5級的稱為有感地震,這種地震人們能夠感覺到,但一般不會造成破壞。
- M≥4.5級,小於6級的稱為中強震。
- M≥6級,小於7級的稱為強震。
- M≥7級,小於8級的稱為大地震。
- 8級以及8級以上的稱為巨大地震 (5·12汶川地震,3·11日本地震)。
統計各地區強震次數
統計 \(12\) 年內各地區發生 \(M>=4.5\) 強震的次數。
# STEP 各地區強震次數
df1 = data.query('level>=4.5 and province!="其他"').groupby("province")
print("level>=4.5 共有地區 ", df1.ngroups)
只考慮省份,不考慮境內其他地方,通過 \(query\) 進行過濾,再用 \(groupby\) 進行分組。
詞雲繪圖 pyecharts
Wordcloud - Wordcloud_diamond - Document (pyecharts.org)
# 接上面部分
maxCount = df1.size().max() # @ 選擇可視化地圖標尺的最大值
df1 = list(df1.size().items()) # @ 是右邊的簡寫形式 [(val, idx) for idx, val in s.iteritems()]
print(df1)
# ^ pycharts 繪製詞雲
c1 = (
WordCloud()
.add("", df1, word_size_range=[20, 55], shape=SymbolType.DIAMOND) # @ 字體太大會導致過長欄位無法顯示
.set_global_opts(title_opts=opts.TitleOpts(title="2010-2022年各省份M>=4.5地震次數"))
)
# c1.render("1_省份強震次數圖_詞雲.html")
\(maxCount\) 獲取分組中最大值,也就是可視化地圖最大深度值。使用了巧妙的方式將 \(Series\) 對象轉換成元組數組,可以參考 python - how to convert pandas series to tuple of index and value - Stack Overflow
地圖繪圖 pyecharts
轉化短省份名
由於 \(pyecharts\) 地圖模塊的省份名必須是短省份名,否則將無法正確顯示。為 \(utils\) 工具包編寫如下函數,原理是根據字典查詢並返回短省份名。
def province_to_short(province):
P2S = {
"北京市": "北京",
"天津市": "天津",
"重慶市": "重慶",
"上海市": "上海",
"河北省": "河北",
"山西省": "山西",
"遼寧省": "遼寧",
"吉林省": "吉林",
"黑龍江省": "黑龍江",
"江蘇省": "江蘇",
"浙江省": "浙江",
"安徽省": "安徽",
"福建省": "福建",
"江西省": "江西",
"山東省": "山東",
"河南省": "河南",
"湖北省": "湖北",
"湖南省": "湖南",
"廣東省": "廣東",
"海南省": "海南",
"四川省": "四川",
"貴州省": "貴州",
"雲南省": "雲南",
"陝西省": "陝西",
"甘肅省": "甘肅",
"青海省": "青海",
"臺灣省": "臺灣",
"內蒙古自治區": "內蒙古",
"廣西壯族自治區": "廣西",
"寧夏回族自治區": "寧夏",
"新疆維吾爾自治區": "新疆",
"西藏自治區": "西藏",
"香港特別行政區": "香港",
"澳門特別行政區": "澳門"
}
return P2S.get(province)
繪製地圖(gotcha)
Map - Map_visualmap - Document (pyecharts.org)
# ^ pycharts 繪製地圖
# print(maxCount, type(maxCount))
df1 = [(province_to_short(x[0]), x[1]) for x in df1] # @ 需要將完整省份名轉換成短省份名,否則無法顯示
c2 = (
Map()
.add("強震次數", df1, "china")
.set_global_opts(
title_opts=opts.TitleOpts(title="2010-2022年各省份M>=4.5地震次數"),
visualmap_opts=opts.VisualMapOpts(max_=int(maxCount)),
)
)
# c2.render("1_省份強震次數圖_地圖.html")
這裡有個明顯的 \(gotcha\),前面使用 maxCount = df1.size().max() 獲取到標尺的最大值。輸出也是浮點數,但是你需要註意這是 numpy.int64 類型,是不能被直接用的,需要進行顯式轉換。所以你可以看到在繪圖的過程中使用了 max_=int(maxCount) 。
圖表效果

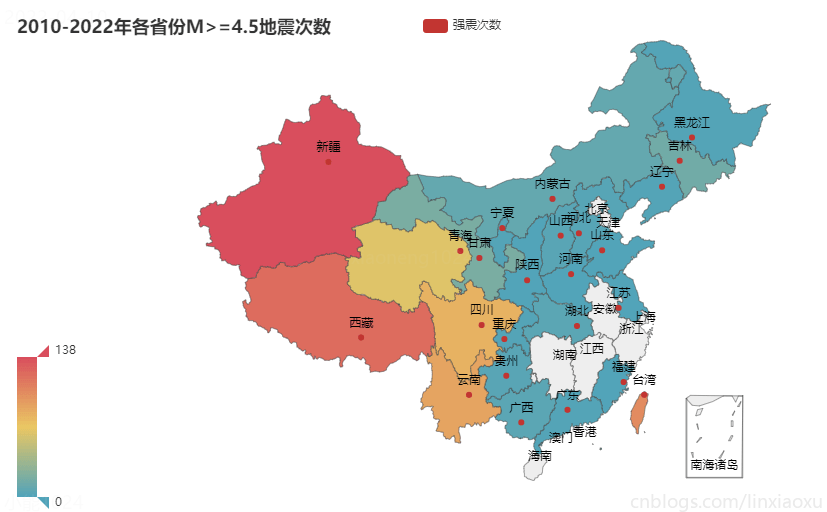
結論
通過統計2010-2022年各省份 M>= 4.5 地震次數
- 12年內新疆強震次數最多為138次。其次為西藏121次,臺灣省103次,雲南89次,四川81次。
- 強震多發生於第一級階梯、第二級階梯地勢高的地方。地勢低且平緩的第三級階梯發生強震少,部分地區沒有發生過強震。
地震震級分佈圖
柱狀圖繪圖 pyecharts
Bar - Bar_base - Document (pyecharts.org)
# STEP 地震震級分佈
mags = data.groupby("level")
print("震級分組 ", mags.ngroups)
mags = mags.size().items()
# ^ mags 只可以迭代一次
xaxis, yaxis = [], []
for x in mags:
xaxis.append(x[0])
yaxis.append(x[1])
c3 = (
Bar()
.add_xaxis(xaxis)
.add_yaxis("震次", yaxis, category_gap=8)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(title_opts=opts.TitleOpts(title="2010-2022年國內地震震級分佈", subtitle="地震次數"))
)
# c3.render("2_地震震級分佈.html")
需要註意的是使用 \(items()\) 獲取的迭代器只能完整迭代一次。再次迭代會得到空數組。
category_gap=8 為各個柱體的間隔距離。
opts.LabelOpts(is_show=False) 不在柱體上顯示數字標簽。
# FIXME 這部分應該還可以優化,太慢了
mags = data.groupby(lambda x: int(data.iloc[x]['level']))
mags = mags.size().items()
xaxis, yaxis = [], []
for x in mags:
xaxis.append(x[0])
yaxis.append(x[1])
c4 = (
Bar()
.add_xaxis(xaxis)
.add_yaxis("震次", yaxis, category_gap=50)
.set_series_opts(label_opts=opts.LabelOpts(is_show=True))
.set_global_opts(title_opts=opts.TitleOpts(title="2010-2022年國內地震震級分佈", subtitle="地震次數"))
)
使用 \(lambda\) 匿名函數處理每行欄位震級化為整數再進行 \(groupby\) ,速度較慢,後續有新方法會更新。
圖表效果
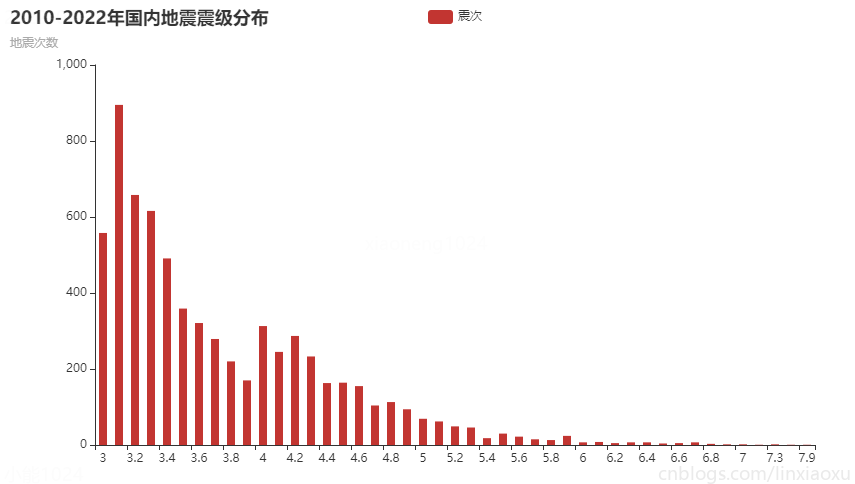
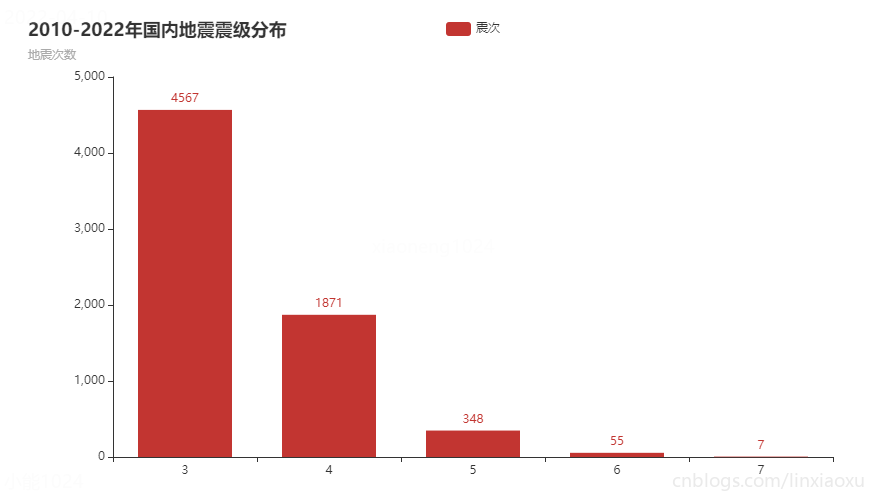
結論
通過統計2010-2022年國內地震震級分佈
- 震級分佈明顯成斜向下的曲線函數。
- 中強震較多,破壞性地震較少。
國內前十大地震
表格繪圖 pyecharts
Table - Table_base - Document (pyecharts.org)
# STEP 挑選前十大地震
c5_df = data.sort_values('level', ascending=False).head(10)
print(c5_df.values, c5_df.columns.values)
c5 = Table()
headers = c5_df.columns.values.tolist()
rows = c5_df.values.tolist()
# print(type(headers)) # BUG <class 'numpy.ndarray'>
c5.add(headers, rows)
c5.set_global_opts(
title_opts=ComponentTitleOpts(title="2010-2022國內前十大地震", subtitle="地震信息")
)
使用 \(sort\_values\) 對特定列排序,並給定 \(ascending\) 參數要求降序排序,最後挑選前十個。
這裡需要註意如果不使用 \(tolist()\) 會出現如下錯誤
The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()
具體原因還是類型問題,預設 \(values\) 拿到的是 <class 'numpy.ndarray'>。轉換成普通類型就好了。
圖表效果
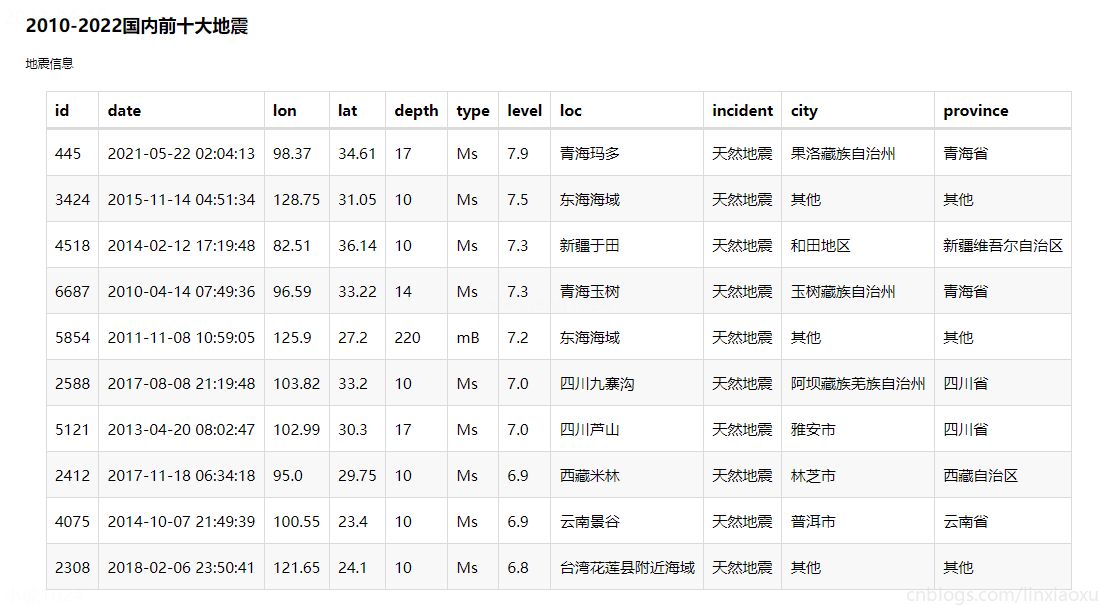
結論
通過統計2010-2022年中國前十大地震
- 青海、東海、四川都發生過兩次特大地震。
- 特大地震震源深度眾數為 10 km,但是東海海域震源深度為 220 km 比較特殊。
- 特大地震震級都在 7 級左右。
震級震源深度散點圖
散點圖繪圖
Scatter - Basic_scatter_chart - Document (pyecharts.org)
全局配置項 - pyecharts - A Python Echarts Plotting Library built with love.
# STEP 震級震源深度散點圖
c6_df = data[["level", "depth"]].copy()
c6_df.drop_duplicates(inplace=True)
c6_df = c6_df.values.tolist()
c6_df.sort(key=lambda x: x[0])
x_data = [d[0] for d in c6_df]
y_data = [d[1] for d in c6_df]
c6 = (
Scatter(init_opts=opts.InitOpts(width="1600px", height="1000px"))
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name="震源深度",
y_axis=y_data,
symbol_size=8,
label_opts=opts.LabelOpts(is_show=False),
)
.set_series_opts()
.set_global_opts(
xaxis_opts=opts.AxisOpts(
type_="value", splitline_opts=opts.SplitLineOpts(is_show=True), min_=3, name="震級(M)"
),
yaxis_opts=opts.AxisOpts(
type_="value",
name="深度(KM)",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
tooltip_opts=opts.TooltipOpts(is_show=True),
title_opts=opts.TitleOpts(title="2010-2022年震級震源深度散點圖"),
)
)
複製了兩個列表,然後刪除相同行。用 \(c6\_df.sort(key=lambda x: x[0])\) 對數組進行一次排序,然後遍曆數組。
\(symbol\_size\) 為點的大小。\(min\_=3\) 將圖表前部分剔除。因為數據集的數據 \(M>=3\)。
圖表效果
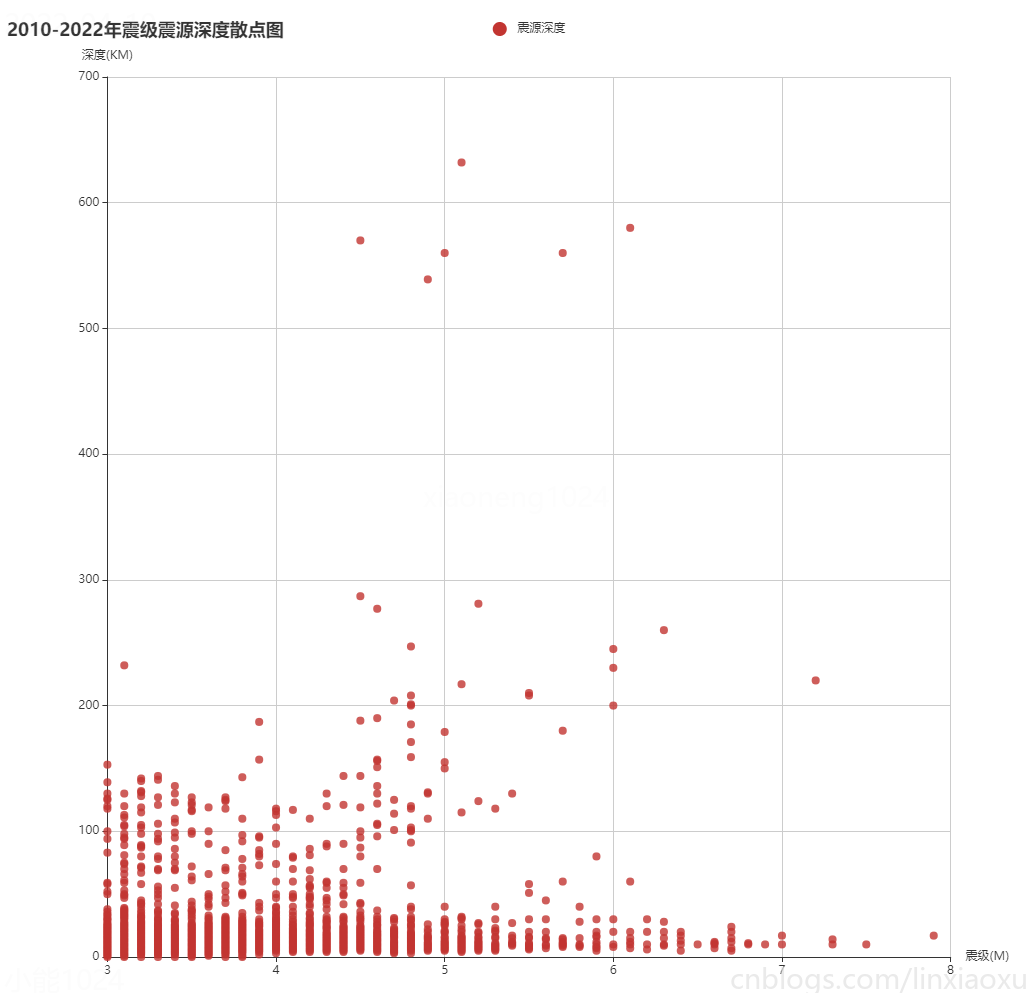
總結
通過震級震源深度散點圖
- 震級和震源深度呈現不均勻分佈。總體來看兩者沒有多大關係。
- 由於內陸經常發生中小型地震,震源深度一般不會過高。致使左下角震級與震源深度的堆積
世界地震熱力圖
繪製熱力圖 plotly
# STEP 世界地震熱力圖 plotly
p1_data = pd.read_csv("./world_new.csv")
# step 篩選 >= 4.5 地震
p1_data = p1_data.query('level>=4.5')
my_map = go.Densitymapbox(lat=p1_data['lat'], lon=p1_data['lon'], z=p1_data['level'], radius=10)
fig = go.Figure(my_map)
p1 = fig.update_layout(mapbox_style="stamen-terrain")
p1.write_html("p1.html", include_plotlyjs='cdn')
# pip install -U kaleido
# p1.write_image("p1.png", format="png")
需要註意的是給定一個 \(mapbox\_style\) 否則圖表將無法正常顯示。
write_html("p1.html", include_plotlyjs='cdn') 將圖表導出為 \(html\) 文件。\(js\) 需要配置為 \(cdn\) 加速載入速度。
圖表效果
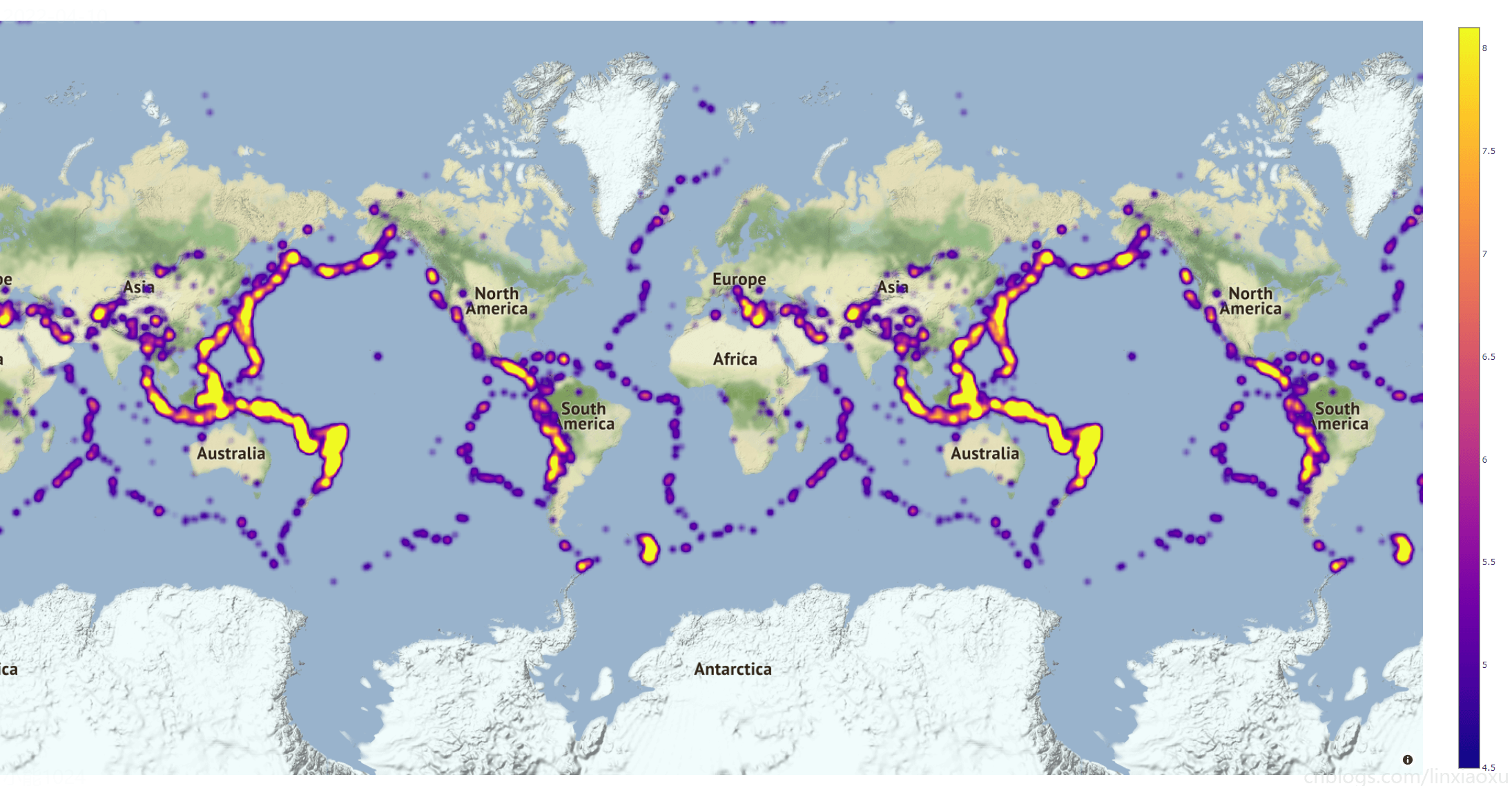
總結
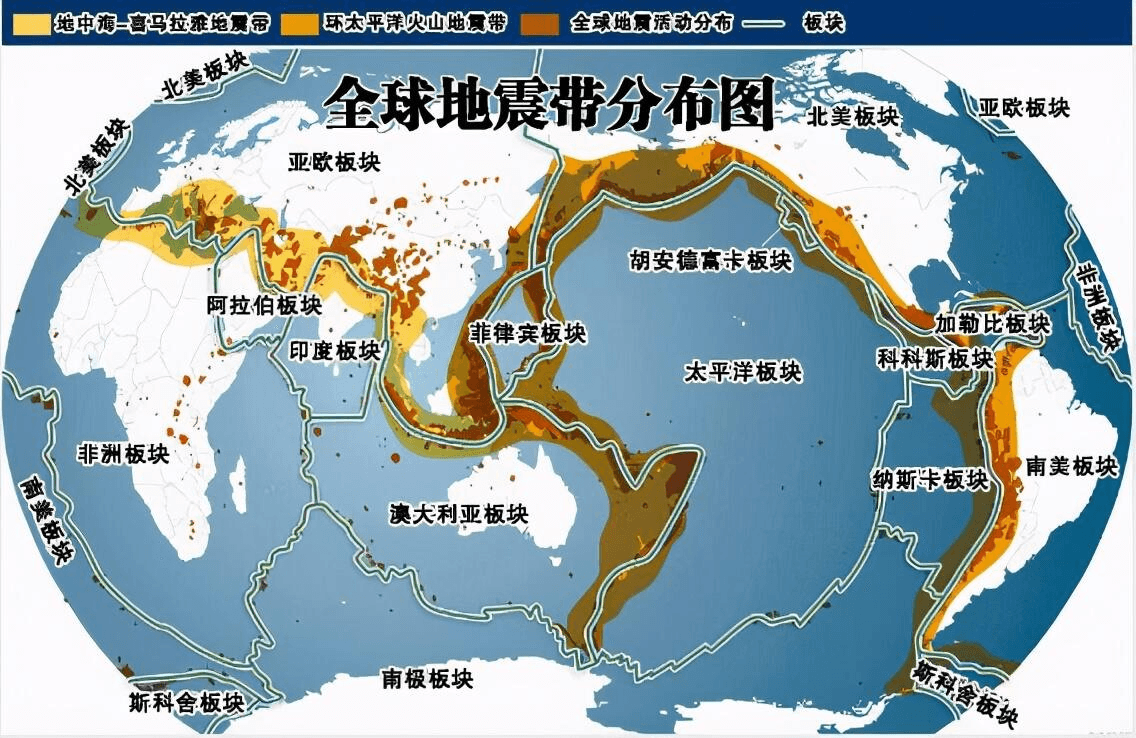
結合全球地震帶分佈圖分析,可以看出熱力圖輪廓與全球地震帶分佈圖輪廓非常相似。基本上吻合。強地震大部分都發生在板塊交界處。
中國地震熱力圖
繪製熱力圖 plotly
# STEP 中國地震熱力圖 plotly
p2_data = pd.read_csv("./china_new.csv")
p2 = px.density_mapbox(p2_data, lat='lat', lon='lon', z='level', radius=10,
center=dict(lat=34, lon=108), zoom=4,
mapbox_style="stamen-terrain")
p2.write_html("p2.html", include_plotlyjs='cdn')
這裡用了另外一種方法,比上面的方法更加簡潔,並明確指定了初始化圖表的中心方位。
圖表效果

結論
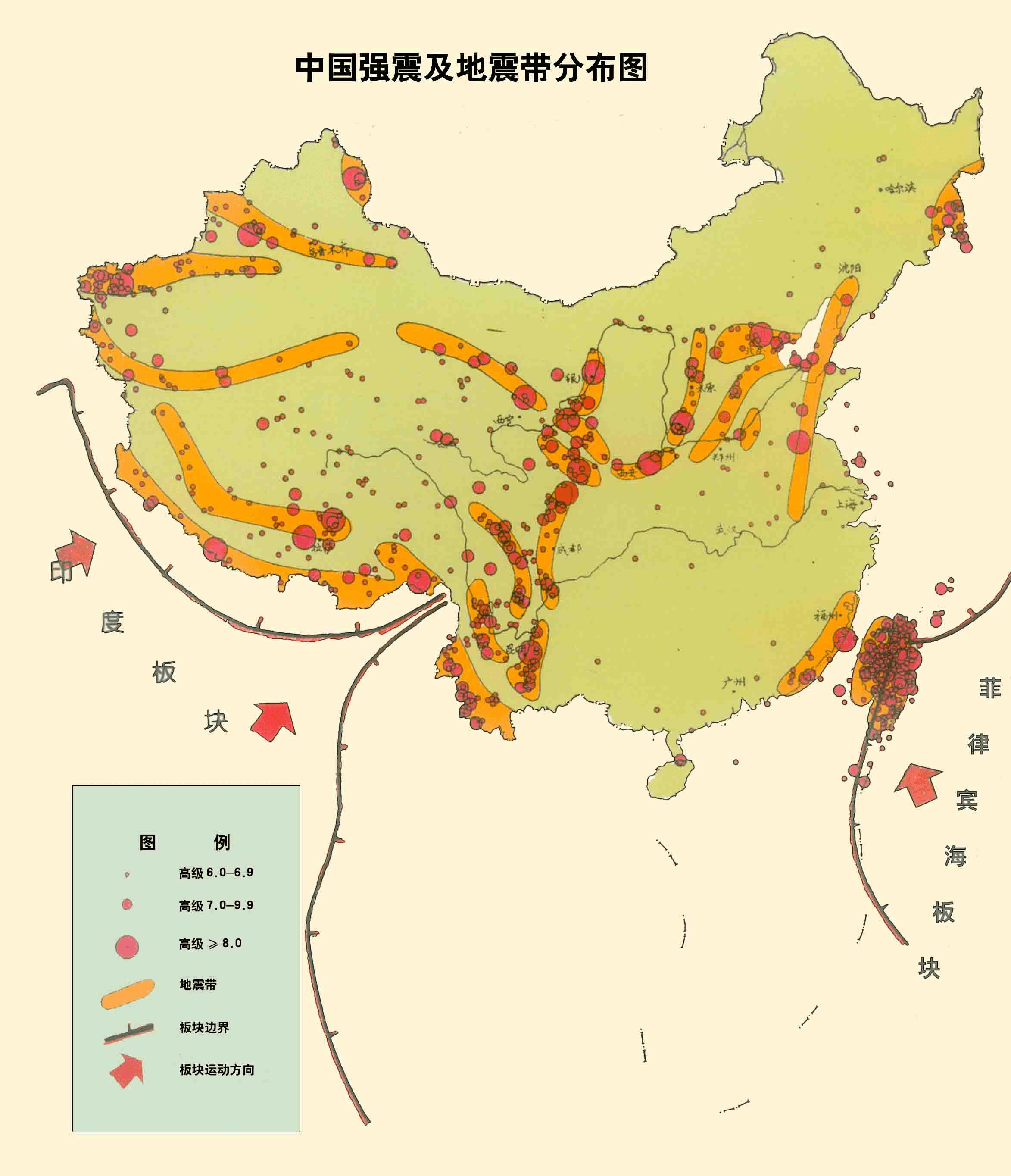
- 結合中國地震帶分佈圖,可以看出熱力圖輪廓與其輪廓非常相似,大體吻合。
- 臺灣省發生的地震強震次數明顯,在地圖中高亮顯示。原因是臺灣剛好地處環太平洋地震帶,所以是我國地震頻率最高的省份。
我國位於亞歐大陸東部,太平洋的西岸地區,兩大地震帶對於我國都有影響。我國的西南地區的喜馬拉雅山脈和橫斷山脈地區就是地中海-喜馬拉雅地震帶經過的區域,亞歐板塊和印度洋板塊在南北方向上碰撞擠壓,形成一系列呈東西走向的地震斷裂帶,以及橫斷山脈地區南北走向的地震斷裂帶。與此有關的地震帶包括喜馬拉雅地震帶、青藏高原地震帶、西北地震帶、南北地震帶、騰衝-瀾滄地震帶、滇西地震帶和滇東地震帶。
我國西部地區總體而言是地震相對高發的地區,包括西藏自治區、青海省、新疆維吾爾自治區、甘肅省、寧夏回族自治區、四川省和雲南省等地都有較高的地震風險,其中越靠近地中海-喜馬拉雅地震帶,地震風險越高,比如說雲南、四川、西藏等地區都是地震高風險省區。此外,我國東部海域地區又處在環太平洋地震帶通過的地區,亞歐板塊和太平洋板塊在東西方向上相互擠壓,形成一系列東北西南走向的地震斷裂帶。與此有關的地震帶包括環太平洋地震帶、東南沿海地震帶和華北地震帶。
相對而言環太平洋地震帶離我國的距離比地中海-喜馬拉雅地震帶要遠一些,因此,總體影響要小一些,但是某些地區地震活躍程度卻非常高,比如我國的臺灣省剛好地處環太平洋地震帶,是我國地震頻率最高的省份。除此之外廣東省、福建省、安徽省、江蘇省、山東省、河北省、河南省、山西省、陝西省、北京市、天津市、遼寧省、吉林省和黑龍江省都有地震帶的分佈。除去以上省份,我們發現內蒙古自治區、上海市、浙江省、江西省、湖北省、湖南省、貴州省和廣西壯族自治區基本上沒有地震帶涉及,也就是地震風險相對較低的省份。
年月地震次數曲線圖
繪製曲線圖 pyecharts
Line - Smoothed_line_chart - Document (pyecharts.org)
# STEP 按年地震次數曲線圖
# ^ 日期轉換
data['date'] = pd.to_datetime(data['date'])
c7_data = data.groupby(data['date'].dt.year)
c7_data = c7_data.size().items()
x_data, y_data = [], []
for x in c7_data:
x_data.append(str(x[0])) # IMPORTANT 必須是字元串
y_data.append(x[1])
c7 = (
Line()
.set_global_opts(
tooltip_opts=opts.TooltipOpts(is_show=True),
xaxis_opts=opts.AxisOpts(type_="category"),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
title_opts=opts.TitleOpts(title="2010-2022年按年地震次數曲線圖"),
)
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name="震次",
y_axis=y_data,
symbol="emptyCircle",
is_symbol_show=True,
is_smooth=True,
label_opts=opts.LabelOpts(is_show=True),
)
)
c8_data = data.groupby([data['date'].dt.year, data['date'].dt.month])
c8_data = c8_data.size().items()
x_data, y_data = [], []
for x in c8_data:
x_data.append(str(x[0]))
y_data.append(x[1])
c8 = (
Line()
.set_global_opts(
tooltip_opts=opts.TooltipOpts(is_show=True),
xaxis_opts=opts.AxisOpts(type_="category"),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
title_opts=opts.TitleOpts(title="2010-2022年按月地震次數曲線圖"),
)
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name="震次",
y_axis=y_data,
symbol="emptyCircle",
is_symbol_show=True,
is_smooth=True,
label_opts=opts.LabelOpts(is_show=False),
)
)
為了能夠使用特殊日期函數,必須進行整列的日期轉換。
data['date'] = pd.to_datetime(data['date'])
需要註意圖表屬性 \(x\_axis\) 必須是字元串數組,否則將不能正常顯示。
日期函數
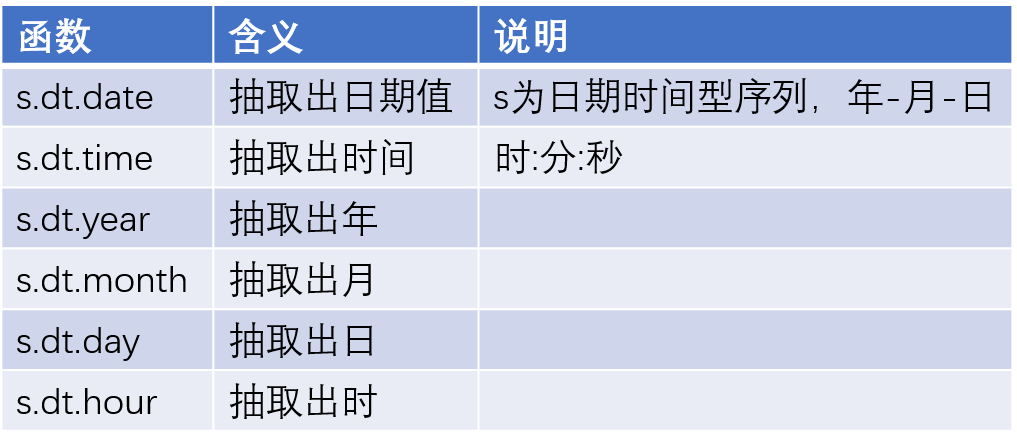
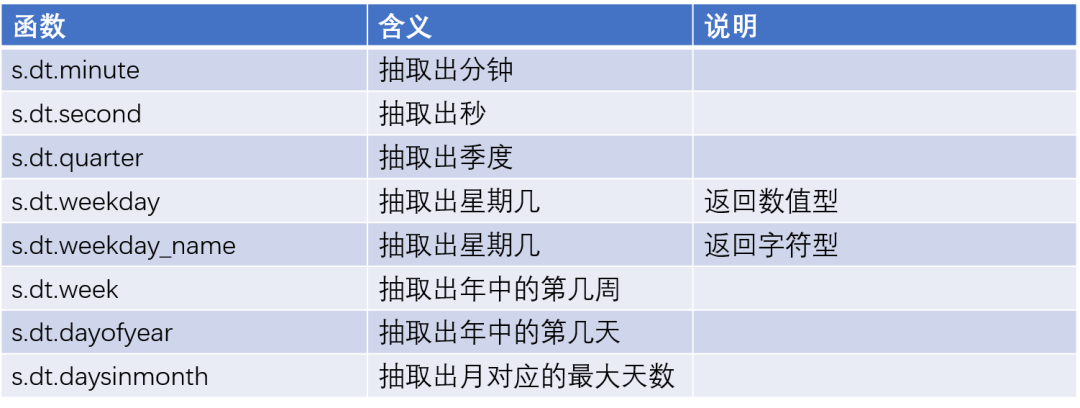
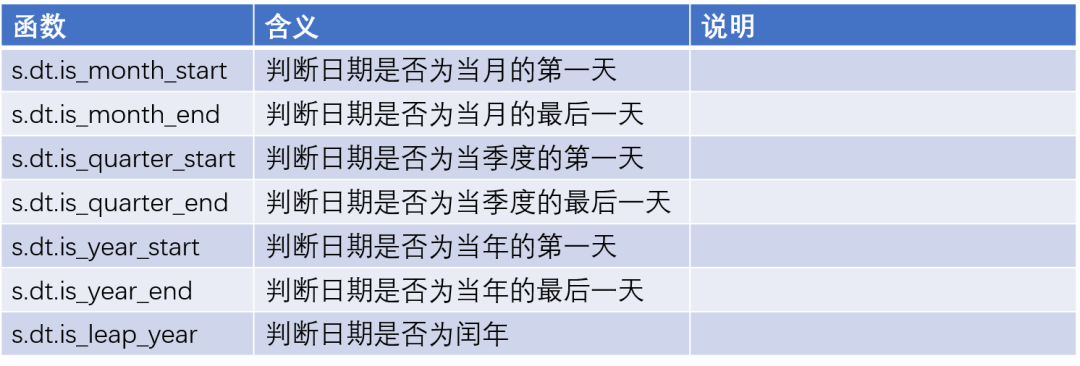
月份繪圖函數
def month_count(year):
c9_data = data[data['date'].dt.year == year].groupby(data['date'].dt.month)
c9_data = c9_data.size().items()
x_data, y_data = [], []
for x in c9_data:
x_data.append(str(x[0]))
y_data.append(x[1])
c9 = (
Line()
.set_global_opts(
tooltip_opts=opts.TooltipOpts(is_show=True),
xaxis_opts=opts.AxisOpts(type_="category"),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
title_opts=opts.TitleOpts(title="{}年按月地震次數曲線圖".format(year)),
)
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name="震次",
y_axis=y_data,
symbol="emptyCircle",
is_symbol_show=True,
is_smooth=True,
label_opts=opts.LabelOpts(is_show=True),
)
)
return c9
c9_1 = month_count(2013)
c9_2 = month_count(2014)
c9_3 = month_count(2015)
圖表效果
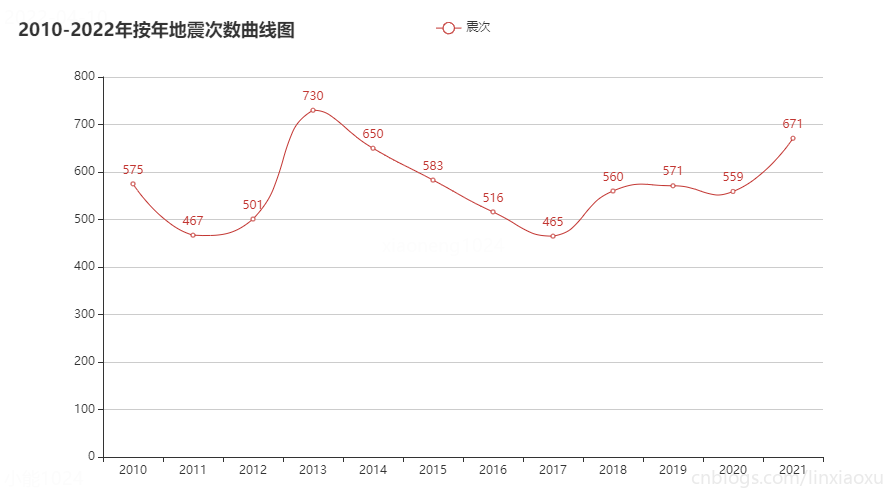
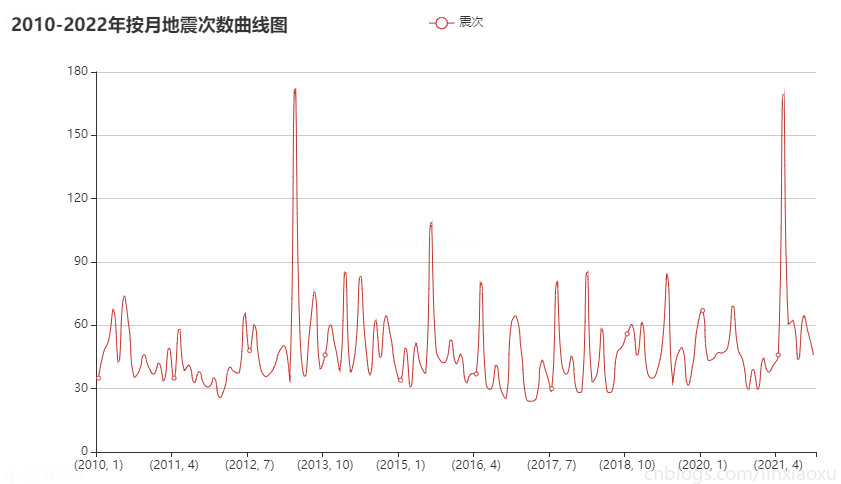
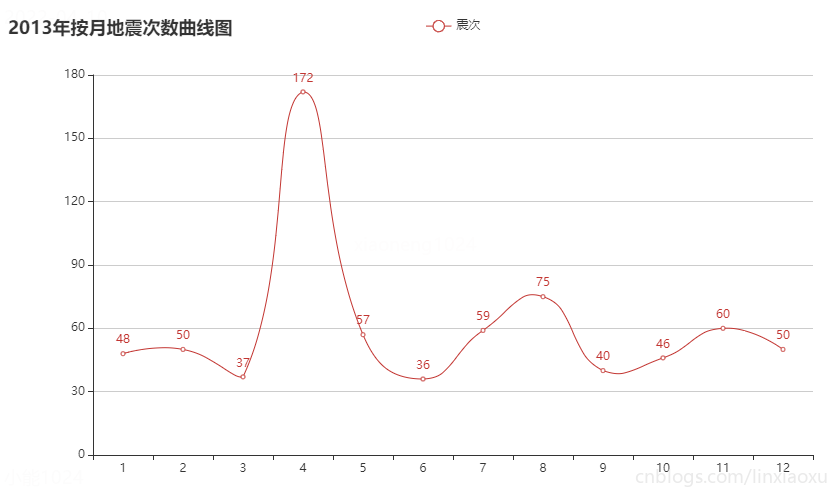
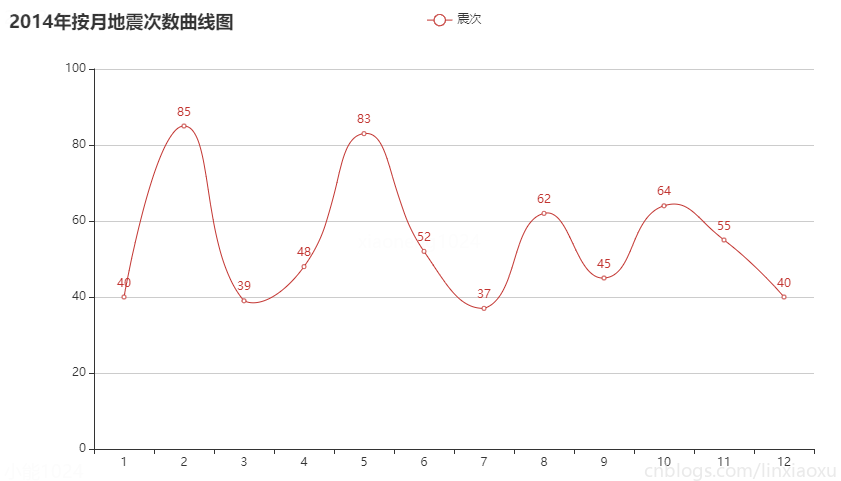
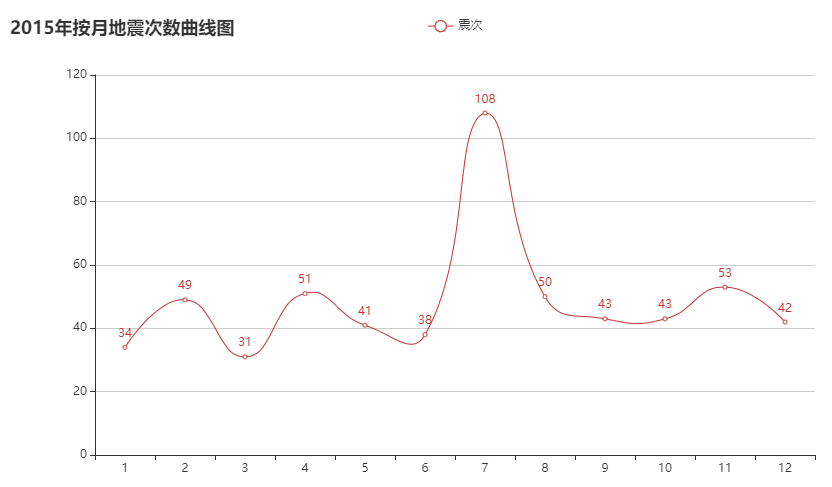
結論
-
按月份來看每月地震次數在 30~90 次的範圍波動。可通過方差判斷各年月地震次數波動。
-
偶爾會有地震次數高峰期,可能是因為地殼活動過於強烈。
24小時段地震發生百分比圖
繪圖 pyecharts
Bar - Stack_bar_percent - Document (pyecharts.org)
# STEP 24小時段地震發生百分比圖
c10_data = data.groupby(data['date'].dt.hour)
total = c10_data.size().sum()
c10_data = c10_data.size().items()
x_data, y_data = [], []
for x in c10_data:
x_data.append(str(x[0]))
y_data.append({"value": x[1], "percent": x[1]/total})
c10 = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
.add_xaxis(x_data)
.add_yaxis("震次", y_data, category_gap="50%")
.set_series_opts(
label_opts=opts.LabelOpts(
position="top",
formatter=JsCode(
"function(x){return Number(x.data.percent * 100).toFixed() + '%';}"
),
)
)
.set_global_opts(
title_opts=opts.TitleOpts(title="24小時段地震發生百分比圖"),
)
)
這裡引入了 \(Jscode\) 特殊化要顯示的標簽。前面數據我們需要獲取到字典數組。\(total\) 實際上是在計算行數。
圖表效果
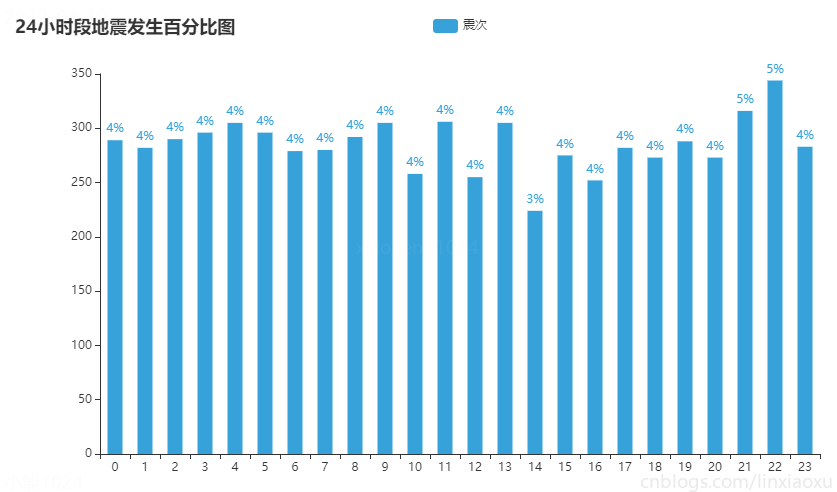
結論
- 每個時間段發生的地震次數較為均勻,沒有出現比較大的差別。
最大震級與平均震級折線圖
繪圖 pyecharts
Line - Line_base - Document (pyecharts.org)
# STEP 2010-2022年最大震級與平均震級折線圖
c11_data = data.groupby(data['date'].dt.year)
x_data, y1_data, y2_data = [], [], []
for name, group in c11_data:
x_data.append(str(name)) # IMPORTANT
y1_data.append(group['level'].max())
y2_data.append(round(group['level'].mean(), 2))
print(x_data, y1_data, y2_data)
c11 = (
Line()
.add_xaxis(x_data)
.add_yaxis("最大震級", y1_data, linestyle_opts=opts.LineStyleOpts(width=2),)
.add_yaxis("平均震級", y2_data, linestyle_opts=opts.LineStyleOpts(width=2),)
.set_global_opts(title_opts=opts.TitleOpts(title="2010-2022年最大震級與平均震級折線圖"))
)
opts.LineStyleOpts(width=2) 設置線條寬度。
圖表效果
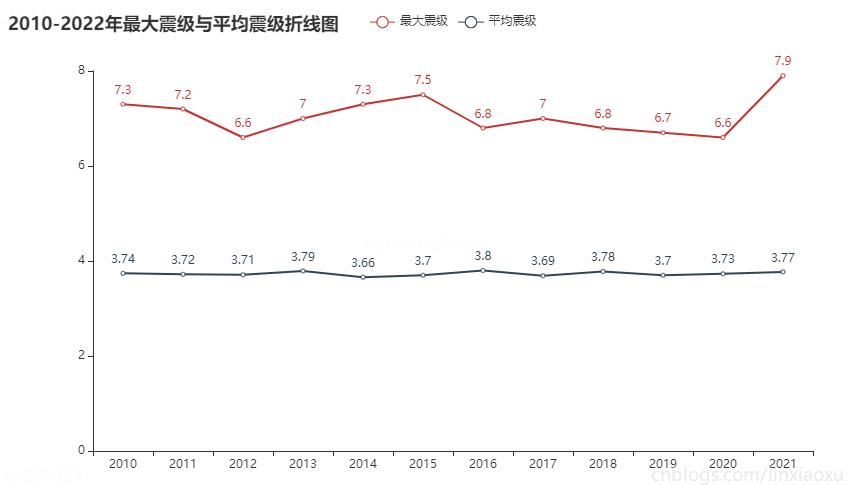
結論
- 每年平均震級均在 3.7 級左右,數值比較穩定,基本成一條直線。
- 每年最大震級均在 6 級以上,在 7 級左右。
震源、震級基本信息
# STEP info 基本信息
info_data = data.describe()
depth_data = info_data['depth']
headers = depth_data.index.to_list()
rows = [[str(round(x, 2)) for x in depth_data.values]]
depth_info = Table().add(headers, rows).set_global_opts(
title_opts=ComponentTitleOpts(title="震源深度信息")
)
level_data = info_data['level']
headers = level_data.index.to_list()
rows = [[str(round(x, 2)) for x in level_data.values]]
level_info = Table().add(headers, rows).set_global_opts(
title_opts=ComponentTitleOpts(title="震級信息")
\(rows\) 必須是二維數組,且元素應該是字元串。



