
作者:吉玉 智能化測試 在互動中經常需要維護大量的狀態,對這些狀態進行測試驗證成本較高,尤其是當有功能變動需要回歸測試的時候。為了降低開發測試的成本,在這方面使用強化學習模擬用戶行為,在兩個方面提效: mock介面:將學習過程中的狀態作為服務介面的測試數據; 回歸測試:根據mock介面數據回溯到特定 ...

作者:吉玉
智能化測試
在互動中經常需要維護大量的狀態,對這些狀態進行測試驗證成本較高,尤其是當有功能變動需要回歸測試的時候。為了降低開發測試的成本,在這方面使用強化學習模擬用戶行為,在兩個方面提效:
- mock介面:將學習過程中的狀態作為服務介面的測試數據;
- 回歸測試:根據mock介面數據回溯到特定狀態,Puppeteer根據強化學習觸發前端操作,模擬真實用戶行為;
什麼是強化學習呢?
強化學習是機器學習的一個領域,它強調如何基於環境行動,獲取最大化的預期利益。強化學習非常適用於近幾年比較流行的電商互動機制:做任務/做游戲 -> 得到不同的獎勵值 -> 最終目標大獎,在這類型的互動游戲中,獎勵是可預期的,用戶的目標是使得自己的獎勵最大化。這個過程可以抽象為馬爾科夫決策模型:玩家(agent)通過不同的交互行為(action),改變游戲(environment)的狀態(state),反饋給玩家不同的獎勵 (reward);這個過程不斷迴圈迭代, 玩家的最終目標是獎勵最大化。
接下來,我們使用比較簡單的Q-learning,來實現類似的智能化測試目的。
Q-learning
對於不同狀態下,Q-learning的Q(s,a)表示在某一個時刻的s狀態下,採取動作a可以得到的收益期望,演算法的主要思想是將state和ation構建一張Q-table來存儲Q值,根據Q值來選取能夠獲得最大收益的動作。Q值的公式計算如下:
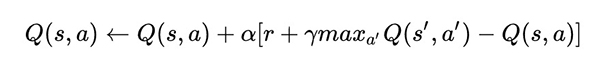
其中,s表示state,a表示action,α為學習率,γ為衰減率,r表示action能帶來的收益。
這個公式表示當前狀態的Q值由“記憶中”的利益(max Q[s',a])和當前利益(r)結合形成。衰減率γ越高,“記憶中”的利益影響越大;學習率α越大,當前利益影響越大。Q-learning的目標是通過不斷訓練,最後得到一個能拿到最多獎勵的最優動作序列。
在賽車游戲中,玩家的交互行為包含購買車廂、合成車廂、做任務獲得金幣(為了方便理解,此處簡化為一個任務);玩家從初始化狀態開始,通過重覆“action -> 更新state”的過程,以下的偽代碼簡單的說明我們怎麼得到一個儘量完美的Q表格:
// action: [ 購買車廂,合成車廂,做任務獲得金幣 ]
// state: 包含等級、擁有車廂等級、剩餘金幣表示
初始化 Q = {}
while Q未收斂:
初始化游戲狀態state
while 賽車沒有達到50級:
使用策略π,獲得動作a = π(S)
使用動作a,獲得新的游戲狀態state
更新Q,Q[s,a] ← (1-α)*Q[s,a] + α*(R(s,a) + γ* max Q[s',a])
更新狀態state
簡單的demo地址:
https://github.com/winniecjy/618taobao
Puppeteer
由上面Q-learning的訓練過程,我們可以得到一系列的中間態介面作為mock數據,可以很快的回溯到特定狀態進行測試,這一點在回歸測試的時候十分有用。但是僅僅只是自動mock數據對效率提升還是有限,在618互動中,友商的互動團隊結合Puppeteer對整個流程進行自動化測試。Puppeteer是chrome團隊推出的一個工具引擎,提供了一系列的API控制Chrome,可以自動提交表單、鍵盤輸入、攔截修改請求、保存UI快照等。
結合Puppeteer的一系列操作邏輯,部分是可以沉澱成為一個通用的測試環境的,比如:
- 不同用戶類型,如登錄、非登錄、風險、會員等;
- 介面攔截mock邏輯;
- 頁面快照留存;
- 頁面性能數據留存;
- 其他常見的業務邏輯,如互動任務體系,跳轉後等幾秒後返回,加積分;
- ...
彈窗規模化
在互動中,彈窗一直是視覺表現的一個重要組成部分,對UI有比較強的定製需求。
友商的思路是將所有的邏輯儘可能的沉澱。對於電商場景來說,彈窗的業務邏輯是可窮舉、可固化的,而互動場景之下,UI定製化需求很高,所以將UI層抽離, 僅對可復用的邏輯進行固化,以DSL + Runtime的機制動態下發。
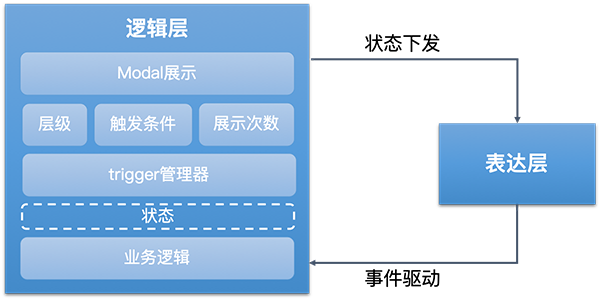
結合這一套邏輯層模型,表達層/UI層也可以相應的結構化。根據項目 > 場景 > 圖層的維度,靜態配置和動態綁定相結合,搭配對應的配置平臺就可以實現動態下發。
總結
對於智能化測試,80%的流程其實成本是相對較低的,從測試用例的生成到puppeteer自動化測試,都是可以參考學習的,圖像對比的部分需要較多訓練,對於固化的功能可以進行探索,如果是新的模式性價比較低。
對於彈窗規模化,部門內部的做法是將彈窗沉澱成一個通用的組件,只包含通用的相容邏輯,包括顯示/隱藏、彈窗出現底層禁止滾動、多彈窗層級問題等。對於UI和其他業務邏輯,復用性較低,所以每次都是重寫。這種做法儘可能地保持了組件的通用性,在會場線比較適用,因為會場線的彈窗一般不包含業務邏輯(如抽獎、PK等),但是對於互動線來說,復用的內容相較於彈窗的“重量”來說顯得有些微不足道。 友商的沉澱思路前提在於上游介面的邏輯需要可復用,上游邏輯如果無法固定下來,前端的互動邏輯也較難固化。總體來說,友商在互動方面的沉澱思路大部分是從開發提效出發,主要供給內部使用;京東內部已有類似的互動提效方案終極目標是盈利,如京喜的社交魔方平臺和最近正在成型的滿天星平臺,所以沉澱方式都是以成套的H5。
參考
[1] 生產力再提速,618互動項目進化之路
[2] 機器學習相關教程 - 莫煩
[3] Puppeteer docs
歡迎關註凹凸實驗室博客:aotu.io
或者關註凹凸實驗室公眾號(AOTULabs),不定時推送文章。


