
#一、實驗目標 理解數據挖掘的基本概念,掌握基於Weka工具的基本數據挖掘(分類、回歸、聚類、關聯規則分析)過程。 #二、實驗內容 下載並安裝Java環境(JDK 7.0 64位)。 下載並安裝Weka 3.7版。 基於Weka的數據分類。 基於Weka的數據回歸。 基於Weka的數據聚類。 基於W ...
一、實驗目標
理解數據挖掘的基本概念,掌握基於Weka工具的基本數據挖掘(分類、回歸、聚類、關聯規則分析)過程。
二、實驗內容
- 下載並安裝Java環境(JDK 7.0 64位)。
- 下載並安裝Weka 3.7版。
- 基於Weka的數據分類。
- 基於Weka的數據回歸。
- 基於Weka的數據聚類。
- 基於Weka的關聯規則分析。
三、實驗步驟
1.下載並安裝Java環境(JDK 7.0 64位)
(1)搜索JDK 7.0 64位版的下載,下載到本地磁碟並安裝。
(2)配置系統環境變數PATH,在末尾補充JDK安裝目錄的bin子目錄,以便於在任意位置都能執行Java程式。
2.下載並安裝Weka 3.7版
3.基於Weka的數據分類
(1)讀取“電費回收數據.csv”(逗號分隔列),作為原始數據。
讀取文件後,將一些對數據分析無用的屬性刪除。
首先,刪除CONS_NO(用戶編號),用戶編號是用來標識用戶的,對數據分析沒用。
然後,發現TQSC(欠費時長)為YMD(年月日)與RCVED_DATE(實收日期)之差,故刪去YMD與RCVED_DATE。
其次,CUISHOU_COUNT(催收次數)全為0,刪去;YM(年月)對數據分析無用,刪去。
(2) 數據預處理:
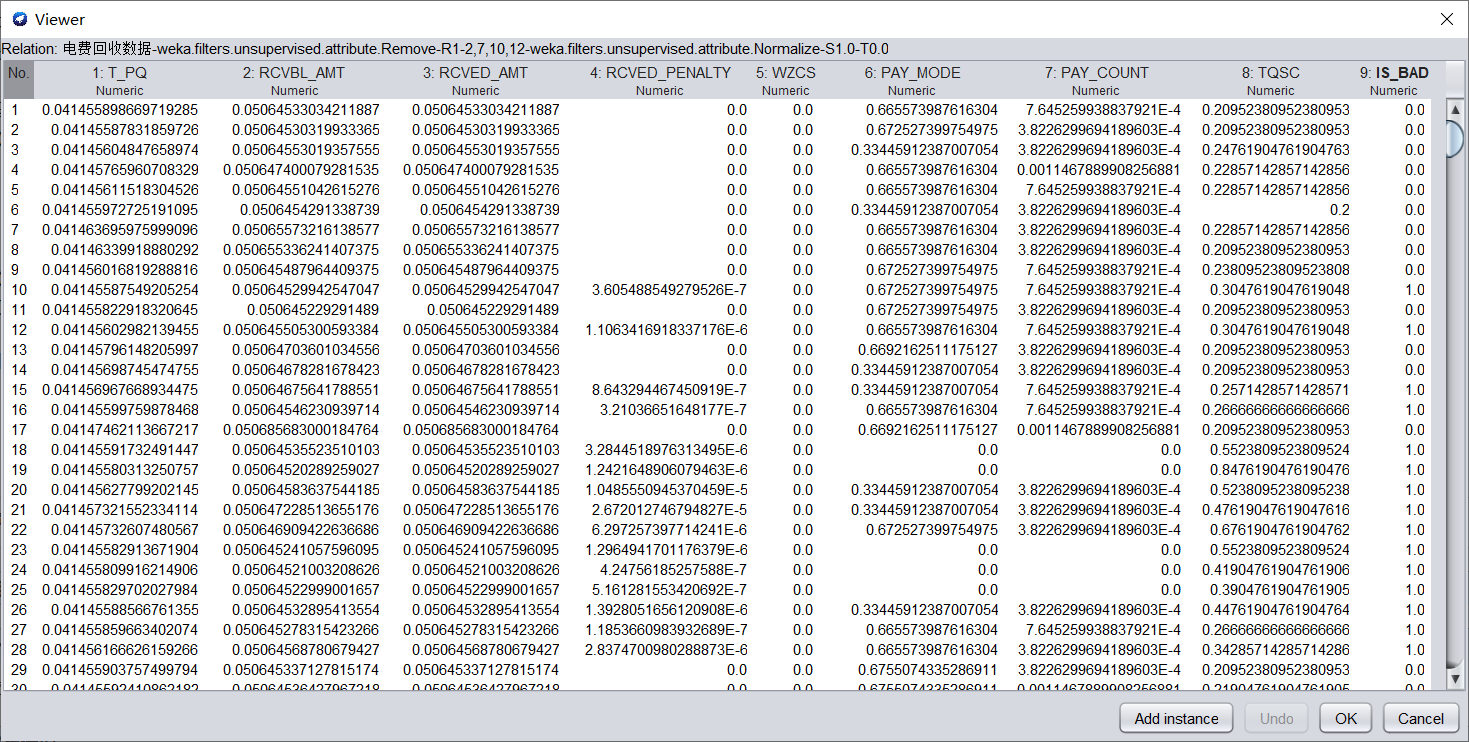
a)將數值型欄位規範化至[0,1]區間。
在Filter中選擇weka.filters.unsupervised.attribute.Normalize,進行歸一化。歸一化的數據如下圖所示。
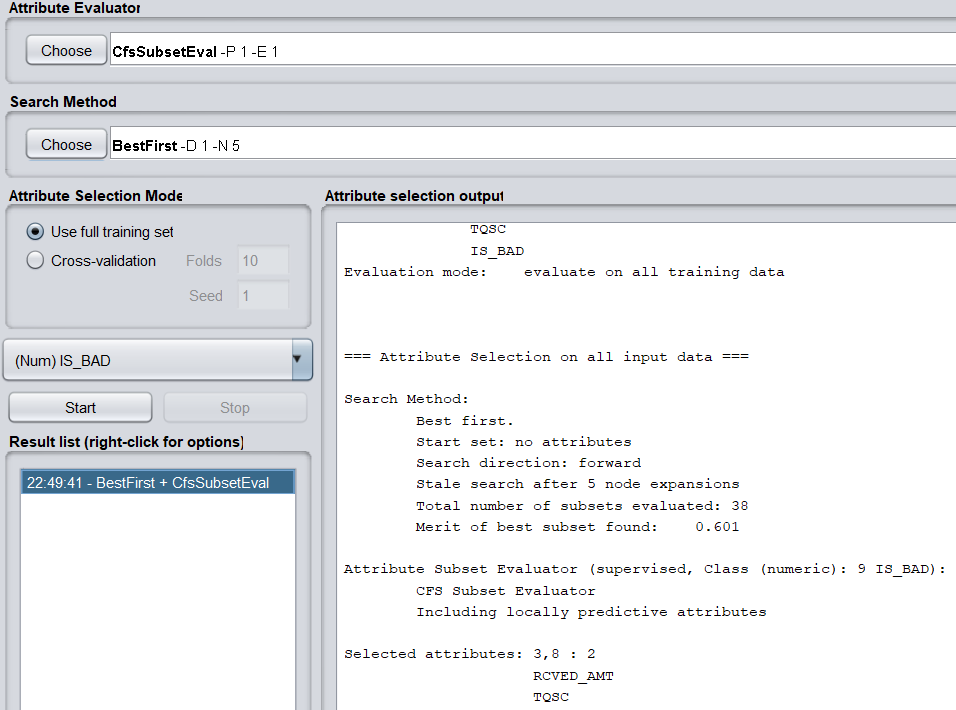
b)調用特征選擇演算法(Select attributes),選擇關鍵特征。
評價策略使用CfsSubsetEval,它根據屬性子集中每一個特征的預測能力以及它們之間的關聯性進行評估。
搜索方法使用BestFirst。
得到兩個關鍵特征,分別為RCVED_AMT(實收金額)與TQSC(欠費時長)。
(3)分別使用決策樹(J48)、隨機森林(RandomForest)、神經網路(MultilayerPerceptron)、朴素貝葉斯(NaiveBayes)等演算法對數據進行分類,取60%作為訓練集,記錄各演算法的查準率(precision)、查全率(recall)、混淆矩陣與運行時間。
對數據進行分類,首先要對其進行離散化。
在Filter中選擇weka.filters.unsupervised.attribute.Discretize,進行離散化。
對數據分類,需要數據為Nominal類型,但此時IS_BAD還是Number類型,在Filter中選擇weka.filters.unsupervised.attribute.NumericToNominal進行類型轉換。
(a)決策樹(J48)
查準率:0.838
查全率:0.807
混淆矩陣:
運行時間:2.27s
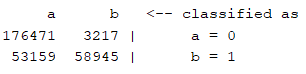
(b)隨機森林(RandomForest)
查準率:0.837
查全率:0.807
混淆矩陣:
運行時間:67.04s
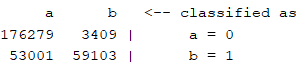
(c)神經網路(MultilayerPerceptron)
查準率:0.837
查全率:0.807
混淆矩陣:
運行時間:14713.98s

(d)朴素貝葉斯(NaiveBayes)
查準率:0.837
查全率:0.807
混淆矩陣:
運行時間:0.57s

4.基於Weka的回歸分析
(1)讀取“配網搶修數據.csv”,作為原始數據。
讀取文件後,將一些對數據分析無用的屬性刪除,如:YMD(年月日)、REGION_ID(地區編號)
(2)數據預處理:
a)將數值型欄位規範化至[0,1]區間。
在Filter中選擇weka.filters.unsupervised.attribute.Normalize,進行歸一化。歸一化的數據如下圖所示。
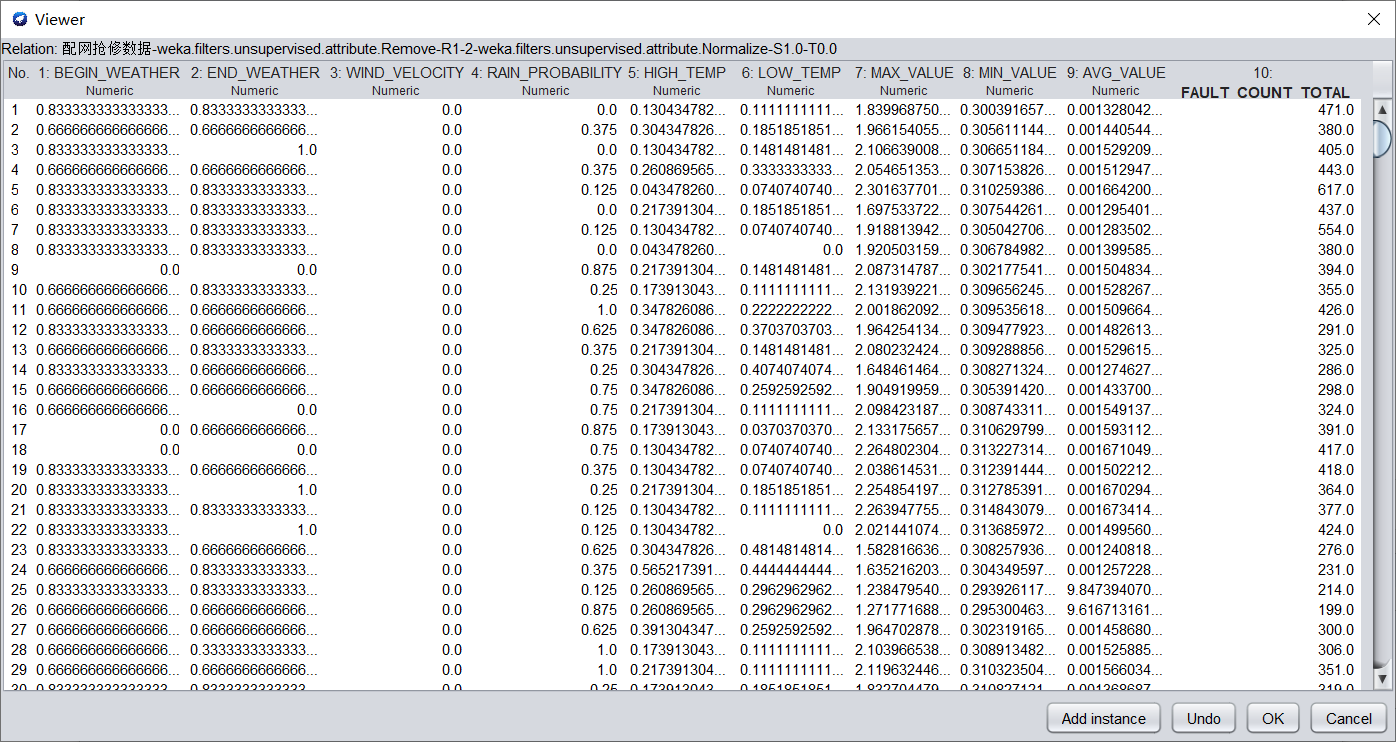
b)調用特征選擇演算法(Select attributes),選擇關鍵特征。
評價策略使用CfsSubsetEval,搜索方法使用BestFirst。
得到三個關鍵特征,分別為HIGH_TEMP(開始氣溫)、MAX_VALUE(負荷最大值)和MIN_VALUE(負荷最小值)。
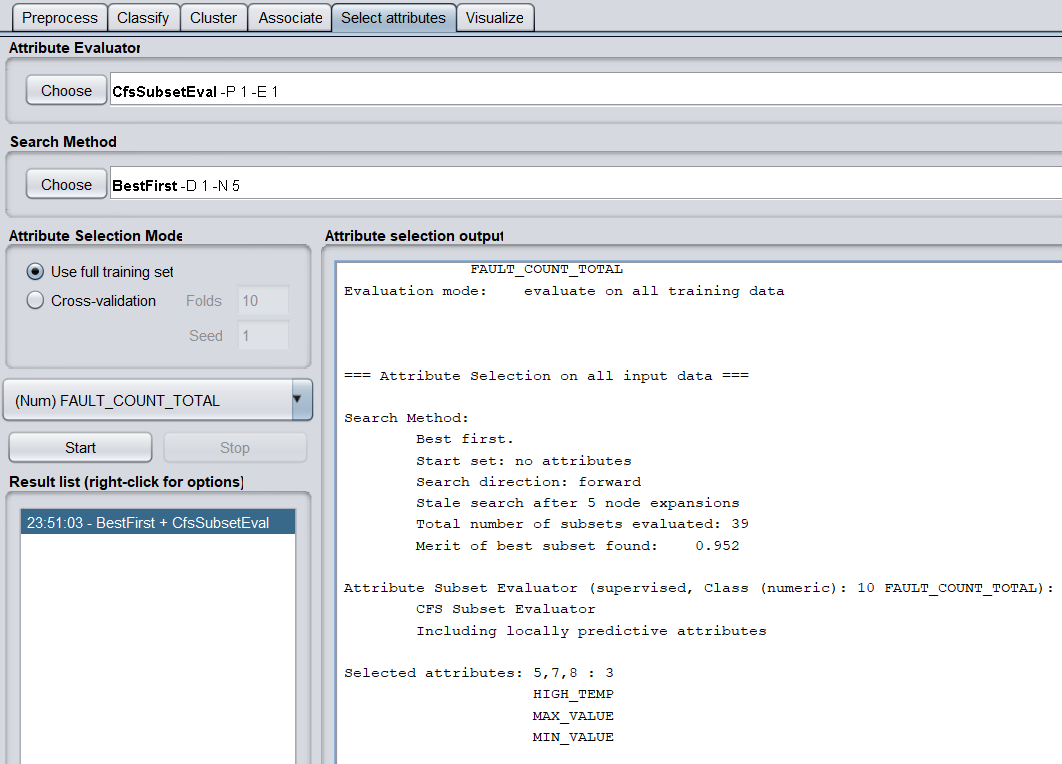
(3)分別使用隨機森林(RandomForest)、神經網路(MultilayerPerceptron)、線性回歸(LinearRegression)等演算法對數據進行回歸分析,取60%作為訓練集,記錄各演算法的均方根誤差(RMSE,Root Mean Squared Error)、相對誤差(relative absolute error)與運行時間。
對數據進行回歸分析前,先進行離散化。
在Filter中選擇weka.filters.unsupervised.attribute.Discretize,進行離散化。
(a)隨機森林(RandomForest)
均方根誤差:152.2666
相對誤差:27.9604%
運行時間:0.26s
(b)神經網路(MultilayerPerceptron)
均方根誤差:185.7892
相對誤差:41.9412%
運行時間:33.85s
(c)線性回歸(LinearRegression)
均方根誤差:141.7254
相對誤差:26.9541 %
運行時間:0.19s
5.基於Weka的數據聚類
(1)讀取“移動客戶數據.tsv”(TAB符分隔列),作為原始數據。
刪除無關屬性,SUM_MONTH、USER_ID、MSISDN、CUS_ID。
(2)數據預處理:
(a)將數值型欄位規範化至[0,1]區間。
在Filter中選擇weka.filters.unsupervised.attribute.Normalize,進行歸一化。歸一化的數據如下圖所示。
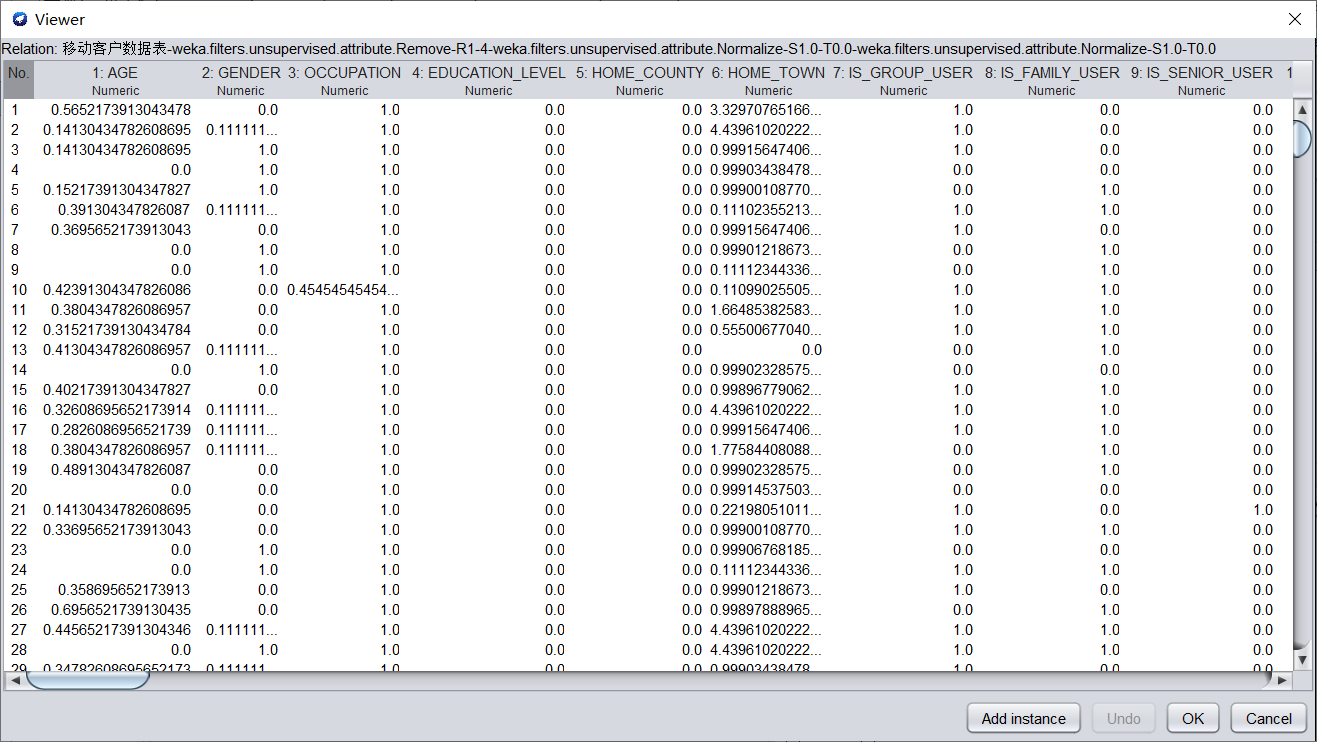
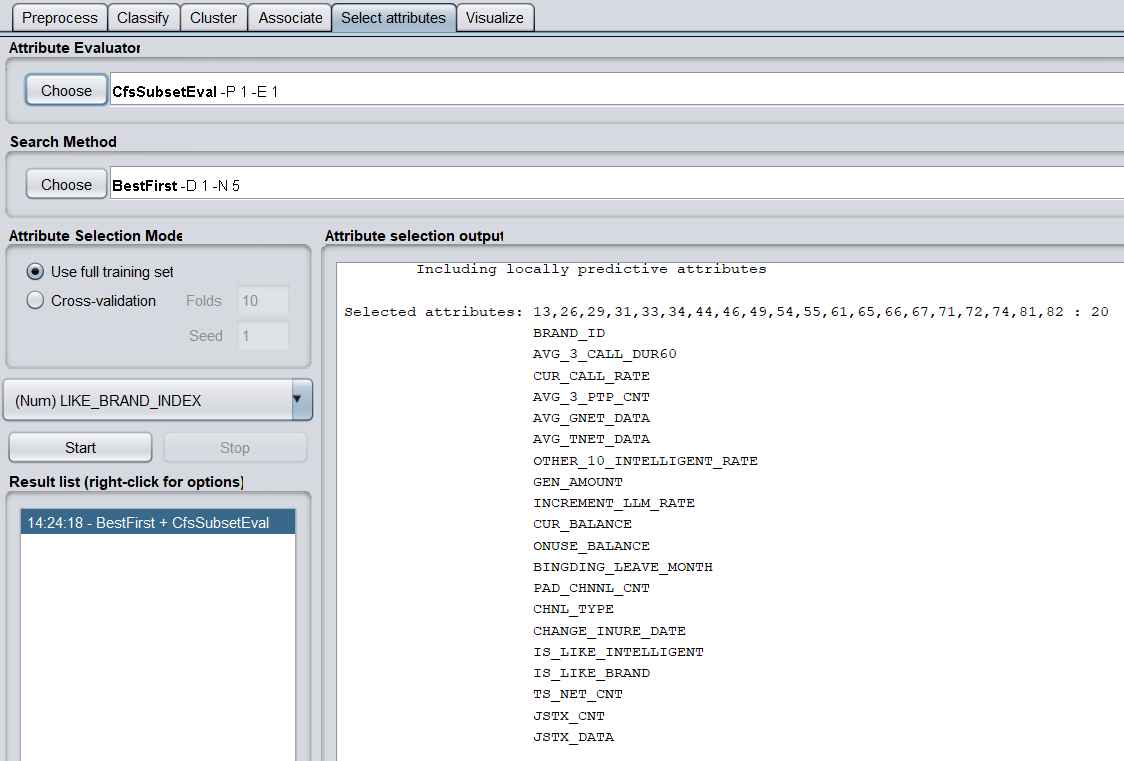
(b)調用特征選擇演算法(Select attributes),選擇關鍵特征。
選擇特征前,還要把數據中的2個string屬性的刪掉,才能使用CfsSubsetEval成功選擇特征
評價策略使用CfsSubsetEval,搜索方法使用BestFirst。
共有20個關鍵特征,分別為
BRAND_ID
AVG_3_CALL_DUR60
CUR_CALL_RATE
AVG_3_PTP_CNT
AVG_GNET_DATA
AVG_TNET_DATA
OTHER_10_INTELLIGENT_RATE
GEN_AMOUNT
INCREMENT_LLM_RATE
CUR_BALANCE
ONUSE_BALANCE
BINGDING_LEAVE_MONTH
PAD_CHNNL_CNT
CHNL_TYPE
CHANGE_INURE_DATE
IS_LIKE_INTELLIGENT
IS_LIKE_BRAND
TS_NET_CNT
JSTX_CNT
JSTX_DATA
(3)分別使用K均值(SimpleKMeans)、期望值最大化(EM)、層次聚類(HierarchicalClusterer)等演算法對數據進行聚類,記錄各演算法的聚類質量(sum of squared errors)與運行時間。
(a)K均值(SimpleKMeans)
聚類質量: 138999.20953835524
運行時間:1.18s
(b)期望值最大化(EM)
聚類質量:
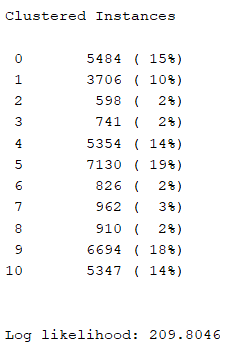
運行時間:6892.63s
(c)層次聚類(HierarchicalClusterer)
爆了記憶體,暫時找不到解決方法。
聚類質量:
運行時間:
6.基於Weka的關聯規則分析
(1)讀取“配網搶修數據.csv”,作為原始數據。
讀取文件後,將一些對數據分析無用的屬性刪除,如:YMD(年月日)、REGION_ID(地區編號)
(2)數據預處理:
a)將數值型欄位規範化至[0,1]區間。
在Filter中選擇weka.filters.unsupervised.attribute.Normalize,進行歸一化。歸一化的數據如下圖所示。
b)調用特征選擇演算法(Select attributes),選擇關鍵特征。
評價策略使用CfsSubsetEval,搜索方法使用BestFirst。
得到三個關鍵特征,分別為HIGH_TEMP(開始氣溫)、MAX_VALUE(負荷最大值)和MIN_VALUE(負荷最小值)。
(3)使用Apriori演算法對數值型欄位進行關聯規則分析,記錄不同置信度(confidence)下演算法生成的規則集。
(a)置信度為0.9
- MAX_VALUE='(-inf-0.1]' 1718 ==> AVG_VALUE='(-inf-0.1]' 1718 conf:(1) lift:(1) lev:(0) [0] conv:(1)
- WIND_VELOCITY='(0.9-inf)' 1190 ==> MAX_VALUE='(-inf-0.1]' 1190 conf:(1) lift:(1) lev:(0) [1] conv:(1.38)
- WIND_VELOCITY='(0.9-inf)' 1190 ==> AVG_VALUE='(-inf-0.1]' 1190 conf:(1) lift:(1) lev:(0) [0] conv:(0.69)
- WIND_VELOCITY='(0.9-inf)' AVG_VALUE='(-inf-0.1]' 1190 ==> MAX_VALUE='(-inf-0.1]' 1190 conf:(1) lift:(1) lev:(0) [1] conv:(1.38)
- WIND_VELOCITY='(0.9-inf)' MAX_VALUE='(-inf-0.1]' 1190 ==> AVG_VALUE='(-inf-0.1]' 1190 conf:(1) lift:(1) lev:(0) [0] conv:(0.69)
- WIND_VELOCITY='(0.9-inf)' 1190 ==> MAX_VALUE='(-inf-0.1]' AVG_VALUE='(-inf-0.1]' 1190 conf:(1) lift:(1) lev:(0) [1] conv:(1.38)
- MIN_VALUE='(0.2-0.3]' 913 ==> MAX_VALUE='(-inf-0.1]' 913 conf:(1) lift:(1) lev:(0) [1] conv:(1.06)
- MIN_VALUE='(0.2-0.3]' 913 ==> AVG_VALUE='(-inf-0.1]' 913 conf:(1) lift:(1) lev:(0) [0] conv:(0.53)
- MIN_VALUE='(0.2-0.3]' AVG_VALUE='(-inf-0.1]' 913 ==> MAX_VALUE='(-inf-0.1]' 913 conf:(1) lift:(1) lev:(0) [1] conv:(1.06)
- MAX_VALUE='(-inf-0.1]' MIN_VALUE='(0.2-0.3]' 913 ==> AVG_VALUE='(-inf-0.1]' 913 conf:(1) lift:(1) lev:(0) [0] conv:(0.53)
(b)置信度為0.6
- MAX_VALUE='(-inf-0.1]' 1718 ==> AVG_VALUE='(-inf-0.1]' 1718 conf:(1) lift:(1) lev:(0) [0] conv:(1)
- WIND_VELOCITY='(0.9-inf)' 1190 ==> MAX_VALUE='(-inf-0.1]' 1190 conf:(1) lift:(1) lev:(0) [1] conv:(1.38)
- WIND_VELOCITY='(0.9-inf)' 1190 ==> AVG_VALUE='(-inf-0.1]' 1190 conf:(1) lift:(1) lev:(0) [0] conv:(0.69)
- WIND_VELOCITY='(0.9-inf)' AVG_VALUE='(-inf-0.1]' 1190 ==> MAX_VALUE='(-inf-0.1]' 1190 conf:(1) lift:(1) lev:(0) [1] conv:(1.38)
- WIND_VELOCITY='(0.9-inf)' MAX_VALUE='(-inf-0.1]' 1190 ==> AVG_VALUE='(-inf-0.1]' 1190 conf:(1) lift:(1) lev:(0) [0] conv:(0.69)
- WIND_VELOCITY='(0.9-inf)' 1190 ==> MAX_VALUE='(-inf-0.1]' AVG_VALUE='(-inf-0.1]' 1190 conf:(1) lift:(1) lev:(0) [1] conv:(1.38)
- AVG_VALUE='(-inf-0.1]' 1719 ==> MAX_VALUE='(-inf-0.1]' 1718 conf:(1) lift:(1) lev:(0) [0] conv:(1)
- MAX_VALUE='(-inf-0.1]' 1718 ==> WIND_VELOCITY='(0.9-inf)' 1190 conf:(0.69) lift:(1) lev:(0) [1] conv:(1)
- MAX_VALUE='(-inf-0.1]' AVG_VALUE='(-inf-0.1]' 1718 ==> WIND_VELOCITY='(0.9-inf)' 1190 conf:(0.69) lift:(1) lev:(0) [1] conv:(1)
- MAX_VALUE='(-inf-0.1]' 1718 ==> WIND_VELOCITY='(0.9-inf)' AVG_VALUE='(-inf-0.1]' 1190 conf:(0.69) lift:(1) lev:(0) [1] conv:(1)
(c)置信度為0.3
- MAX_VALUE='(-inf-0.1]' 1718 ==> AVG_VALUE='(-inf-0.1]' 1718 conf:(1) lift:(1) lev:(0) [0] conv:(1)
- WIND_VELOCITY='(0.9-inf)' 1190 ==> MAX_VALUE='(-inf-0.1]' 1190 conf:(1) lift:(1) lev:(0) [1] conv:(1.38)
- WIND_VELOCITY='(0.9-inf)' 1190 ==> AVG_VALUE='(-inf-0.1]' 1190 conf:(1) lift:(1) lev:(0) [0] conv:(0.69)
- WIND_VELOCITY='(0.9-inf)' AVG_VALUE='(-inf-0.1]' 1190 ==> MAX_VALUE='(-inf-0.1]' 1190 conf:(1) lift:(1) lev:(0) [1] conv:(1.38)
- WIND_VELOCITY='(0.9-inf)' MAX_VALUE='(-inf-0.1]' 1190 ==> AVG_VALUE='(-inf-0.1]' 1190 conf:(1) lift:(1) lev:(0) [0] conv:(0.69)
- WIND_VELOCITY='(0.9-inf)' 1190 ==> MAX_VALUE='(-inf-0.1]' AVG_VALUE='(-inf-0.1]' 1190 conf:(1) lift:(1) lev:(0) [1] conv:(1.38)
- AVG_VALUE='(-inf-0.1]' 1719 ==> MAX_VALUE='(-inf-0.1]' 1718 conf:(1) lift:(1) lev:(0) [0] conv:(1)
- MAX_VALUE='(-inf-0.1]' 1718 ==> WIND_VELOCITY='(0.9-inf)' 1190 conf:(0.69) lift:(1) lev:(0) [1] conv:(1)
- MAX_VALUE='(-inf-0.1]' AVG_VALUE='(-inf-0.1]' 1718 ==> WIND_VELOCITY='(0.9-inf)' 1190 conf:(0.69) lift:(1) lev:(0) [1] conv:(1)
- MAX_VALUE='(-inf-0.1]' 1718 ==> WIND_VELOCITY='(0.9-inf)' AVG_VALUE='(-inf-0.1]' 1190 conf:(0.69) lift:(1) lev:(0) [1] conv:(1)


