
Numpy是Python中用於處理數組的一個非常強大的庫,同時也是Pandas等數據處理的庫的核心,如果你有大量處理數組類型數據的操作,比如操作CSV文件數據或涉及數組的科學計算等,那麼Numpy是一個非常好的選擇。 註:此筆記中主要是以一維數組和二維數組作為示例,更高維的數組因為用的較少,同時原理 ...
Numpy是Python中用於處理數組的一個非常強大的庫,同時也是Pandas等數據處理的庫的核心,如果你有大量處理數組類型數據的操作,比如操作CSV文件數據或涉及數組的科學計算等,那麼Numpy是一個非常好的選擇。
註:此筆記中主要是以一維數組和二維數組作為示例,更高維的數組因為用的較少,同時原理和二維數組也相似,即數組中再套數組,所以就不再單獨解釋了。為了簡化表示,文中的np表示Numpy,即import numpy as np。
一、創建數組
Numpy中的數組對象類型為ndarray,數組的創建,最基礎的就是使用np.array()方法創建數組了,傳入對應的列表或元組即可,創建時也可使用dtype參數指定元素的數據類型。在使用array方法創建數組時,數組中的元素必須是同一類型,如果不是,則會發生自動類型轉換,如果不想進行自動轉換,可指定數據類型為object,具體見示例代碼。
其他還有一些用於創建特定類型數組的方法,常用的有:
- np.arange([start, ]stop, [step, ]dtype=None):相當於Python中range函數,創建一個指定範圍[0, start)或[start, stop)的連續的(具有相同間隔step)的數組。
- np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None, axis=0):創建一個指定範圍內具有相同間隔的指定元素個數的數組,註意,這個方法不用指定間隔,而是根據元素個數自動判斷間隔。
- np.zeros(shape, dtype=float, order='C'):創建一個元素值為0的數組。
- np.ones(shape, dtype=None, order='C'):創建一個元素值為1的數組。
- np.empty(shape, dtype=float, order='C'):創建一個元素值未初始化的數組。
- np.zeros_like(a, dtype=None, order='K', subok=True, shape=None):根據另一個數組創建一個相同維數和元素個數且元素值為0的數組。
- np.ones_like(a, dtype=None, order='K', subok=True, shape=None):根據另一個數組創建一個相同維數和元素個數且元素值為1的數組。
- np.random.rand(d0, d1, ..., dn):創建一個指定維數(d0, d1, ..., dn),元素為0到1之間的隨機數的數組,d0的值表示這一維的元素個數。
- np.random.randint(low, high=None, size=None, dtype=int):創建一個元素值為[0, low)或[low, high)之間的隨機整數的數組,可用size指定數組的shape。
- np.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None, axis=0):創建一個指定範圍內(base的start次冪到base的stop次冪)具有相同間隔的指定元素個數的數組。
示例:

二、數組索引和切片
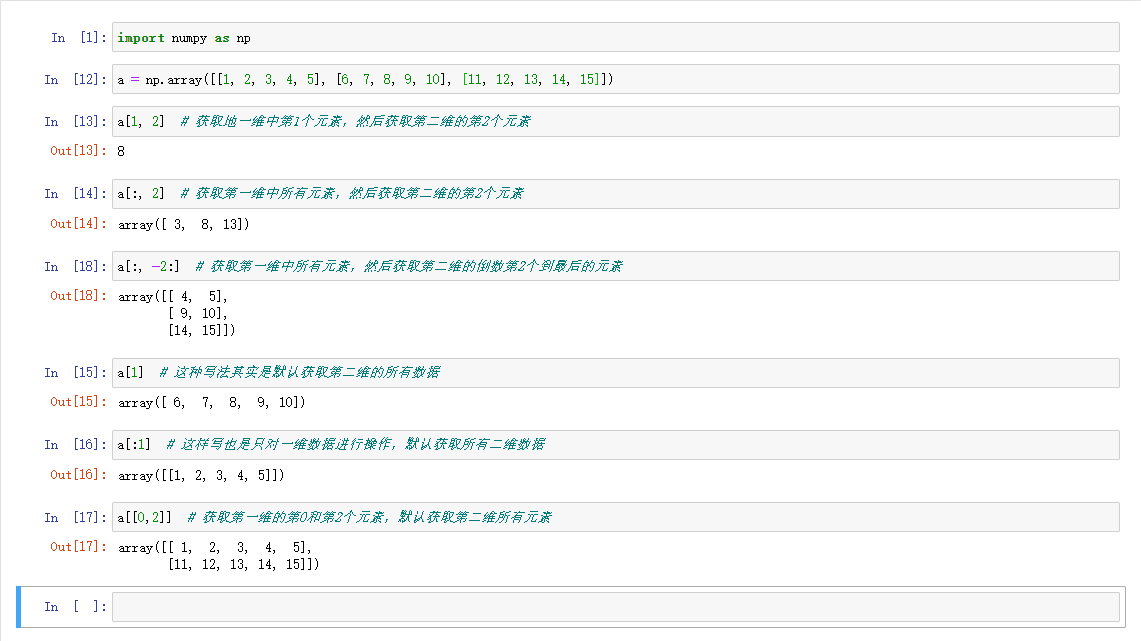
Numpy中數組的索引和切片的使用形如[d0, d1, ...]的方式,其中使用逗號分隔每一維的索引和切片表示,而每一維的索引和切片表示又是與Python中列表的使用是一致的,所以對於一位數組的索引和切片直接就和Python的列表使用是一樣的了,這裡也不再展示示例代碼了,重點在於二維及多位數組的索引和切片使用。
示例:
三、數組常用方法
常用屬性:
- ndarray.dtype:數組元素的數據類型。
- ndarray.shape:數組的維數和對應元素個數信息。
- ndarray.size:數組中的元素個數。
- ndarray.ndim:數組的維數。
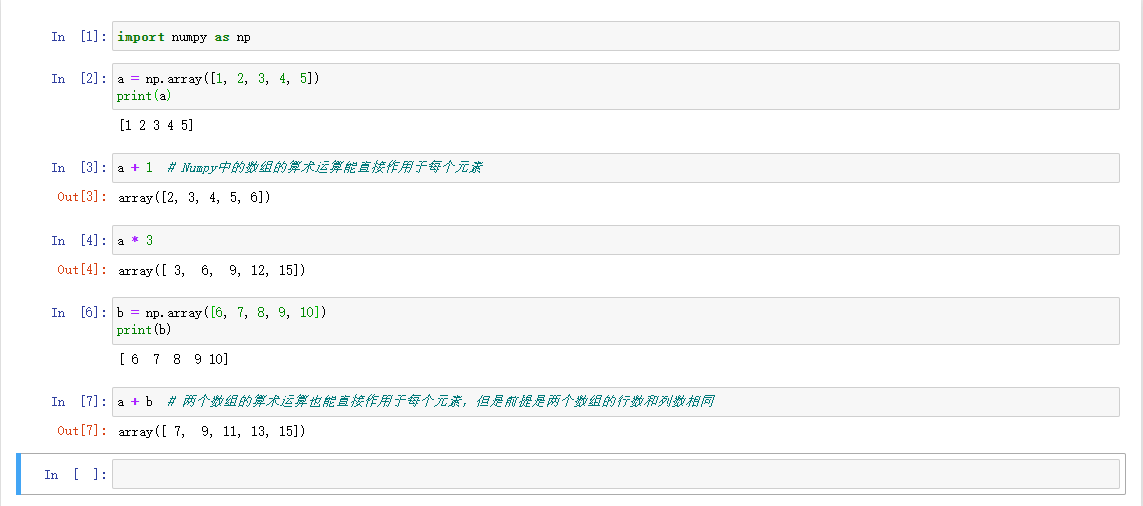
Numpy特色操作
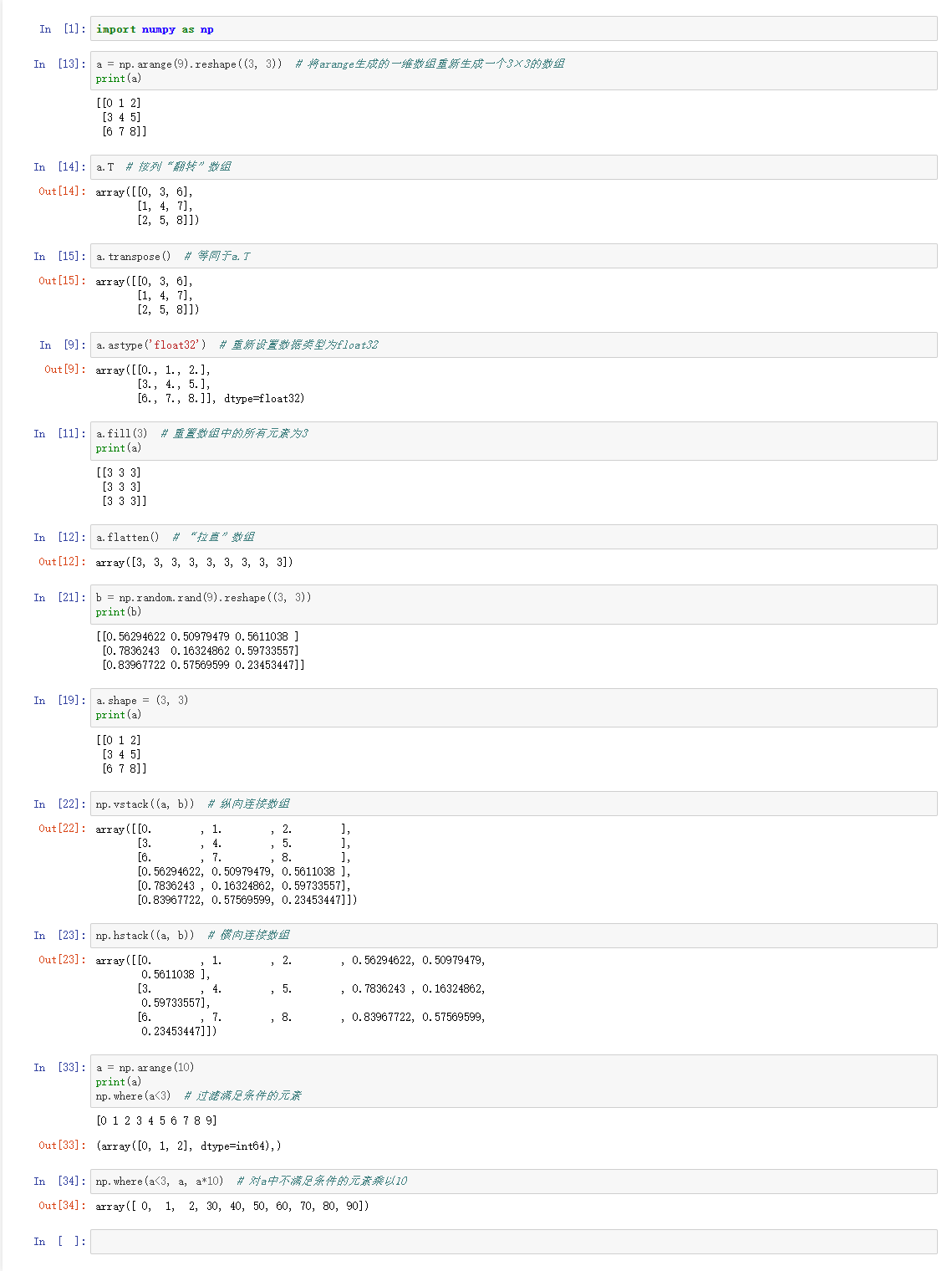
常用方法(大多adarray方法都能在numpy下直接找到並使用):
- ndarray.astype(dtype, order='K', casting='unsafe', subok=True, copy=True):將數組中元素的數據類型轉換為指定的類型。
- ndarray.fill(value):將數組中的元素填充為指定的值。
- ndarray.flatten(order='C'):將數組“拉直”,變為一維數組,返回的是一個新的數組。
- ndarray.ravel([order]):也是將數組“拉直”,變為一維數組,但返回的是原數組的一個視圖索引,即對這個一維數組的修改會同步到原數組。
- ndarray.reshape(shape, order='C'):重新定義數組的shape。
- ndarray.transpose(*axes):對數組進行“翻轉”。
- ndarray.T:相當於ndarray.transpose()。
- ndarray.round(decimals=0, out=None):以“四捨五入”的方式對數組元素進行取整,decimals參數可以指定小數位數。
- ndarray.max(axis=None, out=None, keepdims=False, initial=<no value>, where=True):獲取數組中的最大值,也可以獲取指定維度的最大值。
- ndarray.min(axis=None, out=None, keepdims=False, initial=<no value>, where=True):獲取數組中的最小值,也可以獲取指定維度的最小值。
- ndarray.mean(axis=None, dtype=None, out=None, keepdims=False):獲取數組的平均值,也可以獲取指定維度的平均值。
- ndarray.sum(axis=None, dtype=None, out=None, keepdims=False, initial=0, where=True):獲取數組的和,也可以獲取指定維度的和。
- ndarray.argmax(axis=None, out=None):最大值的索引。
- ndarray.argmin(axis=None, out=None):最小值的索引。
- ndarray.clip(min=None, max=None, out=None, **kwargs):截斷操作,將數組中小於min值的元素重置為min值,大於max值的元素重置為max值。
- ndarray.sort(axis=-1, kind=None, order=None):排序,也可以按照指定維度進行排序。
- ndarray.argsort(axis=-1, kind=None, order=None):返回排序之後的元素索引。
- numpy.vstack(tup):縱向連接數組。
- numpy.hstack(tup):橫向連接數組。
- numpy.where(condition[, x, y]):根據條件過濾數組。
示例:
四、文件讀寫
文本文件的讀寫可以使用以下兩個方法:
- numpy.savetxt(fname, X, fmt='%.18e', delimiter=' ', newline='n', header='', footer='', comments='# ', encoding=None):將一個數組保存到指定的文本文件中。fname為文件名稱,X表示數組,fmt表示數據格式(以%表示的字元串格式化),delimiter為分隔符,其他參數也都是見名知意,看著使用就可以了。
- numpy.loadtxt(fname, dtype=<class 'float'>, comments='#', delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0, encoding='bytes', max_rows=None):將文本文件中的數據載入到數組當中。
類似於數據的序列化和反序列化,可以將數組對象保存到文件中,然後載入出來後直接就是原先的數組對象:
- numpy.save(file, arr, allow_pickle=True, fix_imports=True):將數對象組保存到指定文件中。
- numpy.load(file, mmap_mode=None, allow_pickle=False, fix_imports=True, encoding='ASCII'):從文件中讀取數組對象。


