一、Kafka持久化概述 Kakfa 依賴文件系統來存儲和緩存消息。對於硬碟的傳統觀念是硬碟總是很慢,基於文件系統的架構能否提供優異的性能?實際上硬碟的快慢完全取決於使用方式。同時 Kafka 基於 JVM 記憶體有以下缺點: 對象的記憶體開銷非常高,通常是要存儲的數據的兩倍甚至更高 隨著堆內數據的增加 ...

一、Kafka持久化概述
Kakfa 依賴文件系統來存儲和緩存消息。對於硬碟的傳統觀念是硬碟總是很慢,基於文件系統的架構能否提供優異的性能?實際上硬碟的快慢完全取決於使用方式。同時 Kafka 基於 JVM 記憶體有以下缺點:
- 對象的記憶體開銷非常高,通常是要存儲的數據的兩倍甚至更高
- 隨著堆內數據的增加,GC的速度越來越慢
實際上磁碟線性寫入的性能遠遠大於任意位置寫的性能,線性讀寫由操作系統進行了大量優化(read-ahead、write-behind 等技術),甚至比隨機的記憶體讀寫更快。所以與常見的數據緩存在記憶體中然後刷到硬碟的設計不同,Kafka 直接將數據寫到了文件系統的日誌中:
- 寫操作:將數據順序追加到文件中
- 讀操作:從文件中讀取
這樣實現的好處:
- 讀操作不會阻塞寫操作和其他操作,數據大小不對性能產生影響
- 硬碟空間相對於記憶體空間容量限制更小
- 線性訪問磁碟,速度快,可以保存更長的時間,更穩定。
二、Kafka的持久化原理解析
一個 Topic 被分成多 Partition,每個 Partition 在存儲層面是一個 append-only 日誌文件,屬於一個 Partition 的消息都會被直接追加到日誌文件的尾部,每條消息在文件中的位置稱為 offset(偏移量)。
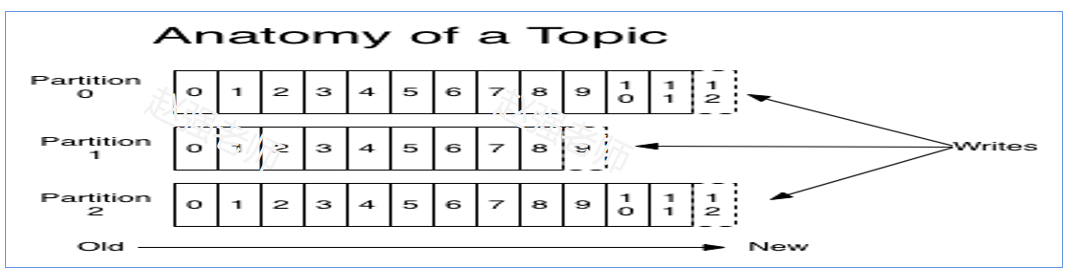
如下圖所示,我們之前創建了mytopic1,具有三個分區。我們可以到對應的日誌目錄下進行查看。

Kafka日誌分為index與log(如上圖所示),兩個成對出現:index文件存儲元數據,log存儲消息。索引文件元數據指向對應log文件中message的遷移地址;例如2,128指log文件的第2條數據,偏移地址為128;而物理地址(在index文件中指定)+ 偏移地址可以定位到消息。
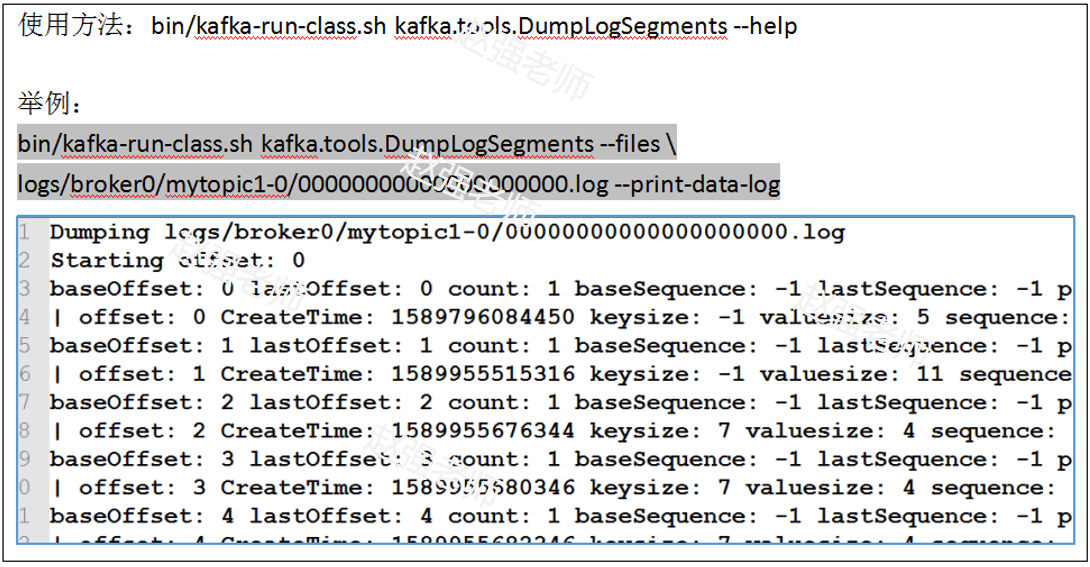
我們可以使用Kafka自帶的工具來查看log日誌文件中的數據信息: