
本篇主要討論的是不同存儲結構(主要是LSM-tree和B-tree),它們應對的不同場景,所採用的底層存儲結構,以及對應用以提升效率的索引。 所謂資料庫,最基礎的功能,就是保存數據,並且在需要的時候可以方便地檢索到需要的數據。在這個基礎上,演化出了不同的資料庫系統,以及多種索引機制幫助檢索數據。這篇 ...
目錄
本篇主要討論的是不同存儲結構(主要是LSM-tree和B-tree),它們應對的不同場景,所採用的底層存儲結構,以及對應用以提升效率的索引。
所謂資料庫,最基礎的功能,就是保存數據,並且在需要的時候可以方便地檢索到需要的數據。在這個基礎上,演化出了不同的資料庫系統,以及多種索引機制幫助檢索數據。這篇我們就來討論幾種常見的數據存儲和索引機制,主要是B-tree,LSM-Tree,以及它們對應的優缺點。
順序存儲與哈希索引
試想一下,如果按照保存數據,並且在需要的時候可以方便地檢索到需要的數據這一標準,設計一個簡單的資料庫,那麼最簡單的做法應該怎麼做呢?
最簡單的做法,就是通過順序保存數據到一個日誌文件中。然後通過索引,這裡以哈希索引為例(比如java的hashMap),記錄每條數據的key以及對應的位移,將其保存到記憶體中,避免隨機檢索巨大的開銷。值得註意的是,引入索引,雖然會顯著提高查詢效率,但會略微降低寫入速度。因為每次寫入的時候都需要額外寫入到哈希索引中,這一點對大部分索引都是適用的。

上圖為哈希索引示例,下麵是順序存儲在磁碟上是日誌數據,上面的記憶體中的哈希索引。哈希索引是很多複雜索引的基礎,比如在mysql中就有提供哈希索引的選項,當然哈希索引並不常用,因為它最基礎,同時也意味著它最容易被優化。
上述形式的順序存儲+哈希索引中,增加數據和查找數據相對容易理解,而修改數據則可以通過將新數據追加到文件尾部,重新生成索引實現,刪除操作則可以給與哈希索引一個標識符實現(如對應key置為-1)。
但這樣有一個問題,可能會出現磁碟耗盡的情況。針對這一個問題,我們可以將日誌文件拆分成多個一定大小的文件段(這裡的文件段可以理解為接受統一管理的數據文件)。當一個文件段達到一定大小,比如4kb的時候,就關閉它,新建一個文件段。而舊的文件段可以進行壓縮,前面提到過,刪除和修改都是通過追加日誌相同的key-value實現的,那麼早先的數據其實就已經沒用的,所以壓縮的時候只保留最新的key數據。壓縮到過程如下麵這張圖所示:

圖中上面的部分就是順序存儲的數據,可以發現其中有很多的key都是相同的,這是因為順序存儲情況下,修改數據就是不斷新寫入相同的key。這種情況我們要的只有相同key的最新的value。所以壓縮過程也是一個清理磁碟的過程。
壓縮合併過程可以由後臺進行默默進行,所以不必擔心這個過程影響查詢性能。上圖中只有一個數據文件段,但實際上可以有多個文件段,多個文件段也可以合併(類似於Hbase中多個文件的merge操作)。
當然這樣的優化可以極大程度節省空間,但必不可少得會給檢索帶來時間上的損耗。在多個文件段的情況,每個文件段都有自己的哈希索引,故而要查找數據會首先根據key查找記憶體中最新文件段的哈希索引,如果找不到,那麼找次新文件段的哈希索引,接著找次新的哈希索引,直到遍歷所有文件段的哈希索引。
綜上,順序存儲+哈希索引優點明顯,簡單,高效。缺點是哈希索引需全部存到記憶體(如果將哈希索引放到磁碟那相當於放棄了檢索的高效),並且難以實現區域查詢。
為瞭解決它的這些問題,我們可以將哈希索引做一些小小的改變。具體來說,就是讓文件段的數據,按key進行排序存儲。這樣會帶來哪些改變呢?
SSTable和LSM tree
將數據文件段中的數據按key進行排序,並且保證相同的key只出現一次(在壓縮的時候保證),這種格式就稱之為排序字元串表,簡稱SStable(Sorted String Table)。
將數據按Key進行排序後有以下幾個好處:
- 合併更加簡單高效,即使數據文件段大於記憶體,也可以使用類似歸併排序演算法進行數據段的壓縮,即將一個大文件拆成多個小數據進行壓縮。如果多個文件段中有相同的key,那麼以最新的文件段的key為準。
- 緩解哈希索引需要整個hashMap存儲到記憶體的窘境。因為key是排序的,所以可以在記憶體中維持一個稀疏索引,存儲每個key的範圍,具體見下圖。並且這個稀疏索引所需的記憶體空間是很小的。
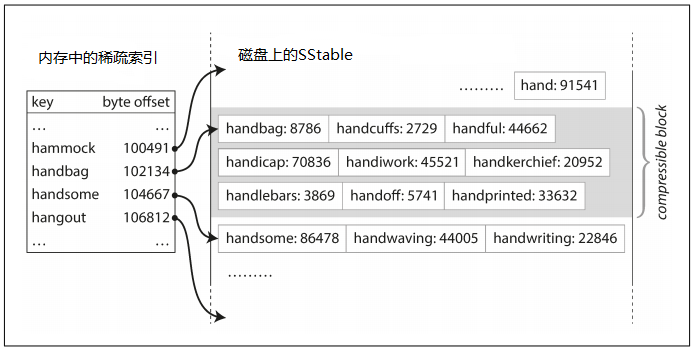
通過稍微改變一下文件段的結果,就獲得如此多的好處。但還有一個問題,前面的哈希索引是基於順序存儲的日誌文件的,要讓SStable按key排序,那就不能順序存儲磁碟了呀(即無法存儲的時候立即寫入磁碟)!!的確是這樣,雖然也可以使用類似B-tree來實現磁碟上的排序存儲,但轉換下思路,其實將數據先保存在記憶體中其實更加方便。
具體實現流程,是在記憶體中維護一個類似TreeMap的數據結構用於存儲數據(TreeMap底層是基於紅黑樹對存儲的key進行排序的。無論我們按照什麼樣的順序存儲數據,TreeMap總是會將數據按照key進行排序)。這個TreeMap稱為記憶體表,當記憶體表超過一定閾值的時候,就將其寫入到磁碟中,成為SStable,因為已經排好序,所以寫入的效率其實比想象的要高。後期再對磁碟中的SStable進行壓縮與合併操作。
當需要根據key檢索的時候,會先去記憶體表中檢索,找不到再去最新的SStable,再去次新的SStable,直到遍歷完全部。
上述這種索引結構被稱為之LSM-Tree,全稱是Log-Structured Merge-Tree,即日誌合併樹。而這種基於合併和壓縮文件原理的存儲引擎被稱為LSM存儲引擎,其中比較為人所知的是Hbase。
B-Tree
最後,我們再來討論流傳最久的資料庫村粗結構。與LSM-Tree這幾年才逐漸為人所知不同,B-tree存儲結構擔得起經久不衰這四個字。
B-tree本身是一種樹形的數據結構,更具體點說是一顆平衡查找樹,它也是通過存儲順序的key存儲數據(這一點和SStable有相似之處)。不同於前面的LSM-tree的文件段,B-tree將資料庫分解成固定大小的塊或頁,通常一個頁大小是4kb。這種分配方法更加貼合底層的磁碟。
當需要進行查找的時候,總是從根開始,根據範圍跳轉到對應的key,而其對應的value可以是值本身,也可以是指向存儲對應數據的磁碟地址。下圖是一個具體的例子:
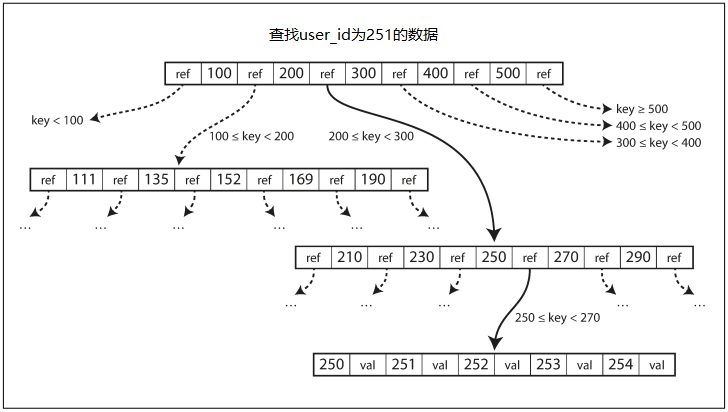
而在更新或插入的時候,有可能會出現沒有足夠空間來容納新key的問題,這時候就會發生分裂。分裂操作是比較危險的,在分裂的時候如果資料庫崩潰,可能會導致索引被破壞。為了防止這個問題,可以引入預寫日誌(write-ahead log,WAL)機制。mysql的binlog就是這樣的東西。具體說就是在執行操作的時候,將此次操作寫入一個只允許追加的文件中,這樣一來當崩潰的時候就可以檢查日誌併進行恢復。
存儲結構的比對
從使用的角度上來說,B-tree等索引存儲結構多用於OLTP型的資料庫,因為這類資料庫主要以事務,或是行級別的讀取和存儲為主的(比如Mysql)。換句話說,這種類型的資料庫更多的操作是小批量或單行級別的更新或讀取,並且可能還有事務方面的需求,這種類型正是B-tree結構所擅長的。
而 LSM-tree則多用於大規模數據情況下的檢索分析和快速寫入的情況。在寫入的性能上,因為上直接寫入記憶體再定期刷入到磁碟中,所以寫入操作對用戶的感知而言上非常迅速的。而檢索速度也因為key順序存儲,可以快速定位到key對應的位置,因而具有較好的檢索性能。
但是LSM-tree比較顯著的應用方向還是在大規模分析這方面,在大規模分析(OLAP)場景下,數據通常都是列式存儲,並且需要全表掃描。其中磁碟數據可以使用二進位進行壓縮,讀取的時候可以有效減少磁碟IO的處理時間(與之相比,B-tree等存儲結構就無法充分壓縮,因為每次都只處理小部分數據)。同時在存儲文件中還能再進一步切分,比如將列式數據按照水平切分成不同的Page,同時存儲一些簡單的索引,用來指定不同Page大概範圍,Hadoop的存儲數據格式Parquet就是類似的設計。
小結
本篇主要討論了幾種基礎的存儲結構和索引以及其對應使用場景,限於篇幅,更多索引的變種無法多加討論,比如B-tree的優化版B+tree,多列索引等。
其實大部分資料庫或者說存儲引擎,都是針對不同的場景下,在舊有的基礎上進行一定程度的微改造創新,但大體的結構依舊是以上述兩三種為準,瞭解了上述幾種結構,對數據存儲方面應該能夠有一個感性的認知了。
此外本章多參考自《DDIA》第三章節,對分散式系統感興趣的童鞋可以看看此書,肯定不會失望的。
以上~


