一、ODS層ODS 全稱是 Operational Data Store,一般對應的是操作性數據存儲,直接面向主題的,也叫數據運營層,通常是最接近數據源中數據的一層,數據源中的數據,經過抽取、洗凈、傳輸,也就是通常說的 ETL 之後的數據存入本層。本層的數據,總體上大多是按照源頭業務系統的分類方式而 ...
一、ODS層
ODS 全稱是 Operational Data Store,一般對應的是操作性數據存儲,直接面向主題的,也叫數據運營層,通常是最接近數據源中數據的一層,數據源中的數據,經過抽取、洗凈、傳輸,也就是通常說的 ETL 之後的數據存入本層。本層的數據,總體上大多是按照源頭業務系統的分類方式而分類的。但是,這一層面的數據卻不等同於原始數據。在源數據裝入這一層時,要進行諸如去噪(例如有一條數據中人的年齡是 300 歲,這種屬於異常數據,就需要提前做一些處理)、去重(例如在個人資料表中,同一 ID 卻有兩條重覆數據,在接入的時候需要做一步去重)、欄位命名規範等一系列操作。
ODS包括的是當前或接近當前的數據,ODS反映的是當前業務條件的狀態,ODS的設計與用戶或業務的需要是有關聯的。
ODS中的數據具有以下4個基本特征:
① 面向主題的:進入ODS的數據是來源於各個操作型資料庫以及其他外部數據源,數據進入ODS前必須經過 ETL過程(抽取、清洗、轉換、載入等)。
② 集成的:ODS的數據來源於各個操作型資料庫,同時也會在數據清理加工後進行一定程度的綜合。
③ 可更新的:可以聯機修改。這一點區別於數據倉庫。
④ 當前或接近當前的:“當前”是指數據在存取時刻是最新的,“接近當前”是指存取的數據是最近一段時間得到的。
ODS的目的:
(1)實現企業級的OLTP操作:
傳統的操作型資料庫往往只存放企業某一類業務或者某一個部門的數據,因此無法面向企業全局數據的OLTP,而ODS可以實現。因為ODS的數據是面向整個企業進行集成彙總的,剋服了原來面嚮應用的操作型資料庫數據分散的缺陷。
(2)實現即時的OLAP操作:
在數據倉庫上進行OALP,往往由於數據量十分龐大而需要較長的時間。而在企業實際應用中,對於一些較低層次的決策,往往並不需要太多的歷史數據,可能只需要參考當前的或者接近當前的數據就可以完成,並且要求具有較快的響應時間,因此數據倉庫顯然無法滿足這樣的要求,但是ODS可以實現。ODS中不僅有面向企業全局的細節數據和彙總數據,而且規模比數據倉庫小,具有較強的實時響應能力。
數據分析的概念:
OLTP:On-Line Transaction Processing聯機事務處理過程(OLTP),也稱為面向交易的處理過程,其基本特征是前臺接收的用戶數據可以立即傳送到計算中心進行處理,併在很短的時間內給出處理結果,是對用戶操作快速響應的方式之一。
OLAP:OLAP展現在用戶面前的是一幅幅多維視圖。
聯機分析處理的概念:
維(Dimension):是人們觀察數據的特定角度,是考慮問題時的一類屬性,屬性集合構成一個維(時間維、地理維等)。
維的層次(Level):人們觀察數據的某個特定角度(即某個維)還可以存在細節程度不同的各個描述方面(時間維:日期、月份、季度、年)。
維的成員(Member):維的一個取值,是數據項在某維中位置的描述。(“某年某月某日”是在時間維上位置的描述)。
度量(Measure):多維數組的取值.
OLAP的基本多維分析操作有鑽取(Drill-up和Drill-down)、切片(Slice)和切塊(Dice)、以及旋轉(Pivot)等。
鑽取:是改變維的層次,變換分析的粒度。它包括向下鑽取(Drill-down)和向上鑽取(Drill-up)/上捲(Roll-up)。Drill-up是在某一維上將低層次的細節數據概括到高層次的彙總數據,或者減少維數;而Drill-down則相反,它從彙總數據深入到細節數據進行觀察或增加新維。
切片和切塊:是在一部分維上選定值後,關心度量數據在剩餘維上的分佈。如果剩餘的維只有兩個,則是切片;如果有三個或以上,則是切塊。
旋轉:是變換維的方向,即在表格中重新安排維的放置(例如行列互換)。
OLAP是以數據倉庫為基礎的,其最終數據來源與OLTP一樣均來自底層的資料庫系統,但由於二者面對的用戶不同,OLTP面對的是操作人員和低層管理人員,OLAP面員和高層管理人員.
二、DW數據倉庫層
數據倉庫層(DW,Data Warehouse),是數據倉庫的主體.在這裡,從 ODS 層中獲得的數據按照主題建立各種數據模型。是一個面向主題的(Subject Oriented)、集成的(Integrated)、相對穩定的(Non-Volatile)、反映歷史變化(Time Variant)的數據集合,用於支持管理決策(Decision Making Support)。
數據倉庫是一個很大的數據存儲集合,出於企業的分析性報告和決策支持目的而創建,對多樣的業務數據進行篩選與整合。它為企業提供一定的BI(商業智能)能力,指導業務流程改進、監視時間、成本、質量以及控制。
數據倉庫存儲是一個面向主題(移動的用戶分析也可做為一個主題)的,反映歷史變化數據,用於支撐管理決策。
特征:
1)、效率足夠高,要對進入的數據快速處理。
2)、數據質量高,數據倉庫是提供很多決策需要的數據支撐,DW的數據應該是唯一的具有權威性的數據,企業的所有系統只能從DW取數據,所以需要定期對DW裡面的數據進行質量審,保證DW裡邊數據的唯一、權威、準確性。
3)、擴展性,企業業務擴展和降低企業建設數據倉庫的成本考慮
4)、面向主題,數據倉庫中的數據是按照一定的主題域進行組織的,每一個主題對應一個巨集觀的分析領域,數據倉庫排除對決策無用的數據,提供特定主題的簡明視圖。
5)、數據倉庫主要提供查詢服務,並且需要查詢能夠及時響應
6)、DW的數據也是只允許增加不允許刪除和修改,數據倉庫主要是提供查詢服務,刪除和修改在分散式系統.
三、DW和ODS的區別
(1)存放的數據內容不同:
- ODS中主要存放當前或接近當前的數據、細節數據,可以進行聯機更新。
- DW中主要存放細節數據和歷史數據,以及各種程度的綜合數據,不能進行聯機更新。
- ODS中也可以存放綜合數據,但只在需要的時候生成。
(2)數據規模不同:
由於存放的數據內容不同,因此DW的數據規模遠遠超過ODS。
(3)技術支持不同:
ODS需要支持面向記錄的聯機更新,並隨時保證其數據與數據源中的數據一致。
DW則需要支持ETL技術和數據快速存取技術等。
(4)面向的需求不同:
ODS主要面向兩個需求:一是用於滿足企業進行全局應用的需要,即企業級的OLTP和即時的OLAP;二是向數據倉庫提供一致的數據環境用於數據抽取。
DW主要用於高層戰略決策,供挖掘分析使用。
(5)使用者不同:
ODS主要使用者是企業中層管理人員,他們使用ODS進行企業日常管理和控制。
DW主要使用者是企業高層和數據分析人員。
本文作者:張永清,轉載請註明:https://www.cnblogs.com/laoqing/p/13042271.html
四、DM數據集市
數據集市,以某個業務應用為出發點而建立的局部DW,DW只關心自己需要的數據,不會全盤考慮企業整體的數據架構和應用,每個應用有自己的DM。還有一種DM的叫法,就是DM(Data Mining):數據挖掘,又稱為資料庫中的知識發現(Knowledge Discovery in Database, KDD),就是從大量數據中獲取有效的、新穎的、潛在有用的、最終可理解的模式的非平凡過程,簡單的說,數據挖掘就是從大量數據中提取或“挖掘”知識。
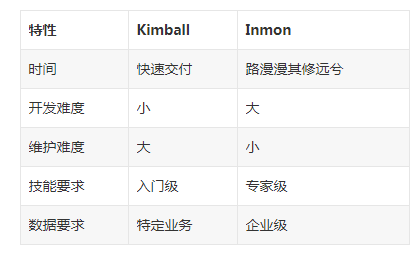
數據流向的過程一般如下:
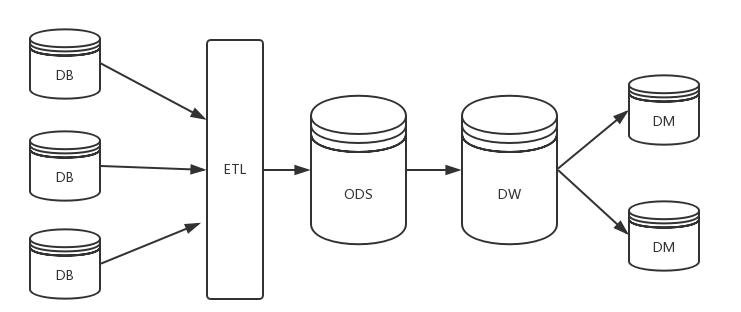
五、 Inmon
Inmon 模式從流程上看是自頂向下的,即從數據源到數據倉庫再到數據集市的(先有數據倉庫再有數據市場)一種瀑布流開發方法。對於Inmon模式,數據源往往是異構的,比如從自行定義的爬蟲數據就是較為典型的一種,數據源是根據最終目標自行定製的。這裡主要的數據處理工作集中在對異構數據的清洗,包括數據類型檢驗,數據值範圍檢驗以及其他一些複雜規則。在這種場景下,數據無法從stage層直接輸出到dm層,必須先通過ETL將數據的格式清洗後放入dw層,再從dw層選擇需要的數據組合輸出到dm層。在Inmon模式中,並不強調事實表和維度表的概念,因為數據源變化的可能性較大,需要更加強調數據的清洗工作,從中抽取實體-關係。
這個體系架構,左邊是操作型系統或者事務系統,裡面包括很多種系統,有資料庫線上系統,有文本文件系統…等等。而這些系統的數據經過ETL的過程,載入數據到企業數據倉庫中,ETL的過程是整合不同系統的數據,經過整合,清洗和統一,因此我們可以稱之為數據集成
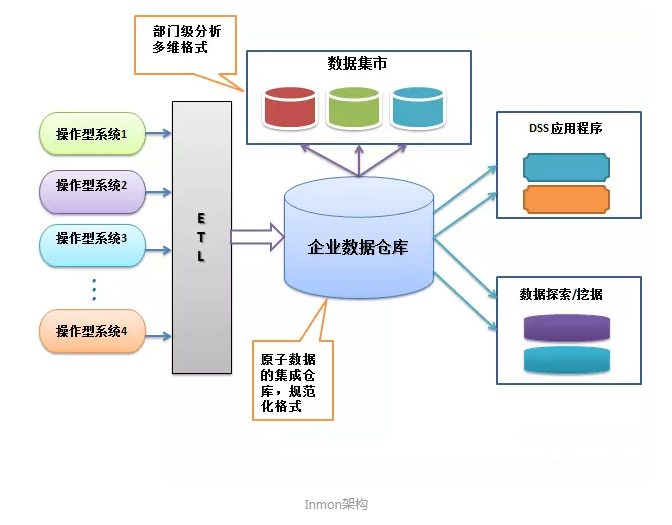
六、 Kimball
Kimball的維度數據倉庫是基於維度模型建立的企業級數據倉庫,它的架構有的時候可以稱之為“匯流排體繫結構”,Kimball 模式從流程上看是是自底向上的,即從數據集市到數據倉庫再到數據源(先有數據集市再有數據倉庫)的一種敏捷開發方法。對於Kimball模式,數據源往往是給定的若幹個資料庫表,數據較為穩定但是數據之間的關聯關係比較複雜,需要從這些OLTP中產生的事務型數據結構抽取出分析型數據結構,再放入數據集市中方便下一步的BI與決策支持。

Kimball和Inmon是兩種主流的數據倉庫方法論,分別由 Ralph Kimbal大神 和 Bill Inmon大神提出,在實際數據倉庫建設中,業界往往會相互借鑒使用兩種開發模式,這兩種的相同點如下:
1、都是假設操作型系統和分析型系統是分離的;
2,數據源(操作型系統)都是眾多;
3、ETL整合了多種操作型系統的信息,集中到一個企業數據倉庫。
不同點:
最大的不同就是企業數據倉庫的模式不同,inmon是採用第三範式的格式,而kimball則採用了多維模型–星型模型,並且還是最低粒度的數據存儲。其次是,維度數據倉庫可以被分析系統直接訪問,當然這種訪問方式畢竟在分析過程中很少使用。最後就是數據集市的概念有邏輯上的區別,在kimball的架構中,數據集市有維度數據倉庫的高亮顯示的表的子集來表示。 有的時候,在kimball的架構中,有一個可變通的設計,就是在ETL的過程中加入ODS層,使得ODS層中能保留第三範式的一組表來作為ETL過程的過度。但是這個思想,Kimball看來只是ETL的過程輔助而已。 特性對比: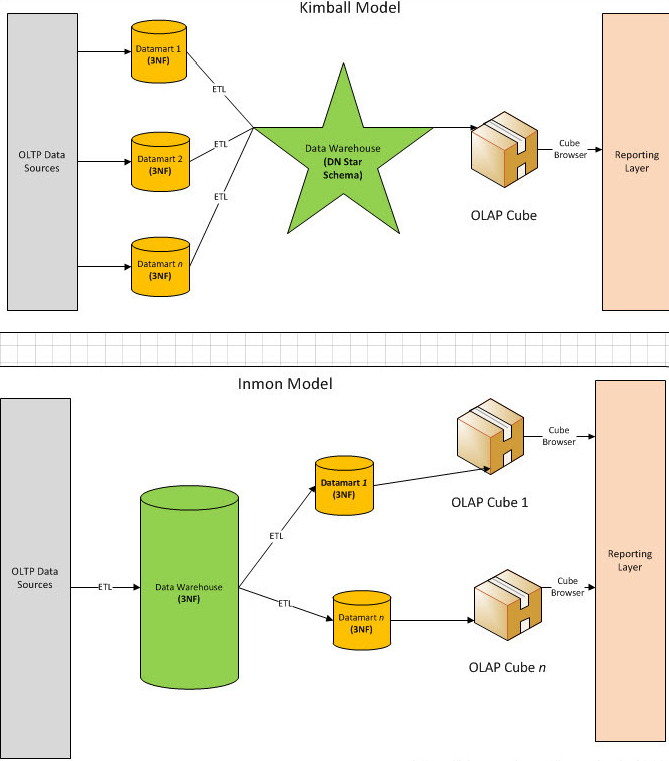
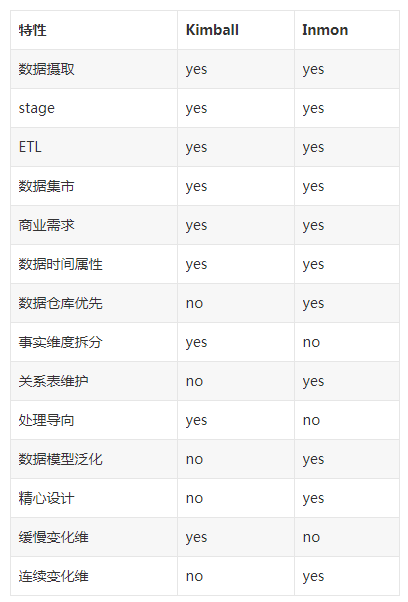
優缺點對比: