
前言 在【JAVA進階架構師指南】系列二和三中,我們瞭解了JVM的記憶體模型以及類載入機制,其中在記憶體模型中,我們說到,從線程角度來說,JVM分為線程私有的區域(虛擬機棧/本地方法棧/程式計數器)和線程公有區域(方法區和java堆),其中線程私有區域記憶體隨著線程的結束而跟著被回收,GC主要關註的是堆和 ...
前言
在【JAVA進階架構師指南】系列二和三中,我們瞭解了JVM的記憶體模型以及類載入機制,其中在記憶體模型中,我們說到,從線程角度來說,JVM分為線程私有的區域(虛擬機棧/本地方法棧/程式計數器)和線程公有區域(方法區和java堆),其中線程私有區域記憶體隨著線程的結束而跟著被回收,GC主要關註的是堆和方法區這部分的記憶體.
GC回收演算法
GC如何確定哪些對象需要回收呢?一般而言,有兩種演算法:引用計數演算法和可達性分析演算法.
引用計數演算法
為每個對象都持有一個引用計數器,初試狀態為0,該對象每次被引用就加一,否則就減一,因此當GC進行垃圾回收的時候,判斷如果該引用計數器=0則進行回收,否則不進行回收,顯而易見,引用計數演算法的缺點就是不能解決迴圈依賴的問題,假如對象A引用對象B,對象B引用對象C,對象C引用對象A,迴圈依賴導致ABC三個對象都不能被回收.因此引出了可達性分析演算法.
可達性分析演算法
所謂可達性分析演算法,就是通過一系列名為"GC Roots"的對象作為起始點,從這些節點開始向下搜索,搜索所走過的路徑稱為引用鏈(Reference Chain),當一個對象到GC Roots沒有任何引用鏈相連時,則證明此對象是可以被回收的,反之則不可被回收,在JAVA中,可被作為"GC Roots"的對象包括如下幾種:
a.虛擬機棧(棧楨中的本地變數表)中的引用的對象
b.方法區中的類靜態屬性引用的對象
c.方法區中的常量引用的對象
d.本地方法棧中JNI的引用的對象
java語言對象引用類型
無論是引用計數演算法還是可達性分析演算法,都涉及到對象的引用,在Java中,引用分為強引用、軟引用、弱引用、虛引用(幽靈引用)4種,這四種引用強度依次逐漸減弱.所謂強引用,就是我們平時最常用的new一個新對象,比如:
Object object = new Object();
強引用的對象永遠不會被GC回收,即使在記憶體不足的情況下,JVM寧願拋出OutOfMemory錯誤也不會回收這種對象,因此,我們看許多優秀框架的源碼的時候,經常會看到如下代碼:
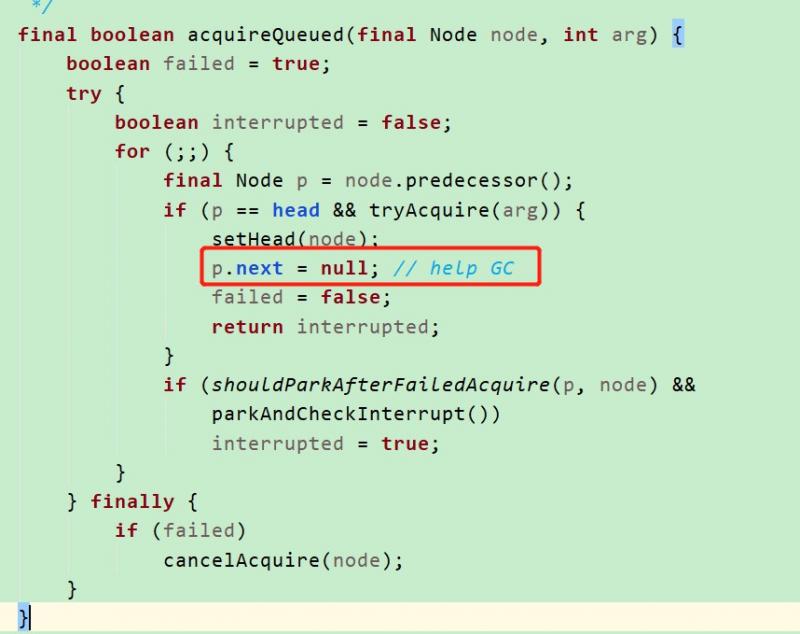
後面有註釋//help gc, 將對象置為null,幫助GC進行垃圾回收,這裡就是消除強引用,讓無用對象的記憶體能被順利回收.有興趣的童鞋可以多多翻看優秀框架的源碼,比如JDK/Spring中肯定會有大量這樣的寫法,足見這些源碼作者的態度之嚴謹,編程功力之深厚,值得我們學習!
而軟引用、弱引用、虛引用這幾類在JDK中都有對應的實現,分別對應SoftReference/WeakReference/PhantomReference,由於博客篇幅有限,不能所有知識點都講得很詳細,只能告訴童鞋們有這些知識點,有興趣的童鞋可以自己下去學習瞭解.
GC回收策略
講完了GC如何確定哪些對象需要回收之後,我們再來看看GC進行垃圾回收有哪些策略,一般而言,有三種:標記清除演算法/複製演算法/標記整理演算法.
1.標記清除演算法
標記清除演算法是最基礎的回收演算法,分為標記和清除兩個部分:首先標記出所有需要回收的對象,這一過程在可達性分析過程中進行.在標記完之後統一回收所有被標記的對象: 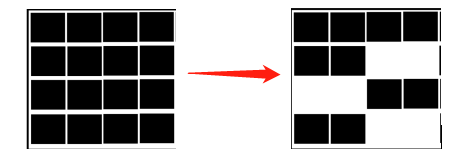
這種演算法的缺點很明顯,就是會產生大量不連續的記憶體碎片,導致經常無法分配出較大的記憶體,從而不得不經常觸發垃圾回收.
2.複製演算法
既然不能回收出連續的記憶體空間,那就從一開始就把記憶體劃分為兩個區,平時只用一個區域,當其中一個區域記憶體滿了,觸發GC時,找出無需回收的對象,將它們全部轉移到另一塊未使用的區域,並且整理到一起使之連續,如此迴圈,這就是複製演算法:
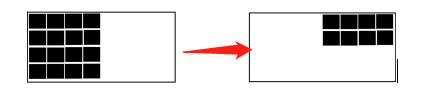
複製演算法改善了標記清楚演算法中記憶體碎片不連續的缺點,但是它的缺點也很明顯,記憶體利用率不高,每次只能使用50%的記憶體.
3.標記整理演算法
既然複製演算法每次只能使用一半的記憶體,記憶體使用率不高,那就再繼續優化,還是和標記清楚演算法一樣使用全部區域的記憶體,不同於標記清除演算法的是進行垃圾回收時,確認無需回收的對象,然後將這些對象進行整理後向一端移動:
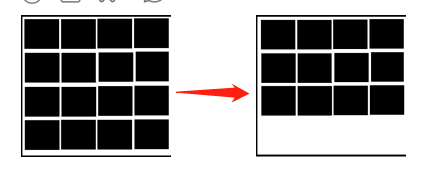
標記整理演算法的優點在於記憶體使用率更充分,並且不會產生大量記憶體碎片.
堆(Heap)中的回收演算法
java堆採用分代搜集來進行垃圾回收.首先明確一點,堆中為什麼要進行分代?或者說,java堆為什麼要使用分代收集演算法來進行垃圾回收?因為據權威統計,80%以上的對象都是朝生夕死,即這些對象隨著方法的執行完畢而不再使用,可以被回收,而剩餘的20%左右的對象是還需要繼續被使用,無法回收的,因此,JDK根據對象的這種特點進行分代收集,一句話概括就是對象的生命周期不同.
所謂分代收集,就是把java堆分為新生代和老年代,老年代採用標記整理演算法,而新生代採用複製演算法,其中將新生代劃分為伊甸園區(Eden)和幸存區(Survivor)S0以及S1(有的也稱之為Survivor from和Survivor to),預設情況下其比例為8:1:1,而整個新生代和老年代的比例為1:2(即新生代占整個堆區1/3,而老年代占2/3):

至於新生代和老年代的詳細工作流程,就不再贅述,網上這種博客太多了.需要註意的是,發生在新生代的GC稱之為Minor GC或者 Young GC,而發生在老年代的GC稱之為Full GC或者Major GC,一般而言,Full GC的效率會比Minor GC低十倍以上!
讀完本篇文章,我相信童鞋們應該對JVM垃圾回收有了一定的瞭解,下一篇文章,讓我們來學習一下JVM篇最後一個知識點,也是最重要的知識點---JVM性能調優,敬請期待!
如果覺得博主寫的不錯,歡迎關註博主微信公眾號,博主會不定期分享技術乾貨!

本文由博客一文多發平臺 OpenWrite 發佈!

