
一 創建模型 表和表之間的關係 一對一、多對一、多對多 ,用book表和publish表自己來想想關係,想想裡面的操作,加外鍵約束和不加外鍵約束的區別,一對一的外鍵約束是在一對多的約束上加上唯一約束。 實例:我們來假定下麵這些概念,欄位和關係 作者模型:一個作者有姓名和年齡。 作者詳細模型:把作者的 ...
一 創建模型
表和表之間的關係
一對一、多對一、多對多 ,用book表和publish表自己來想想關係,想想裡面的操作,加外鍵約束和不加外鍵約束的區別,一對一的外鍵約束是在一對多的約束上加上唯一約束。
實例:我們來假定下麵這些概念,欄位和關係
作者模型:一個作者有姓名和年齡。
作者詳細模型:把作者的詳情放到詳情表,包含生日,手機號,家庭住址等信息。作者詳情模型和作者模型之間是一對一的關係(one-to-one)
出版商模型:出版商有名稱,所在城市以及email。
書籍模型: 書籍有書名和出版日期,一本書可能會有多個作者,一個作者也可以寫多本書,所以作者和書籍的關係就是多對多的關聯關係(many-to-many);一本書只應該由一個出版商出版,所以出版商和書籍是一對多關聯關係(one-to-many)。
模型建立如下:
from django.db import models
# Create your models here.
class Author(models.Model): #比較常用的信息放到這個表裡面
nid = models.AutoField(primary_key=True)
name=models.CharField( max_length=32)
age=models.IntegerField()
# 與AuthorDetail建立一對一的關係,一對一的這個關係欄位寫在兩個表的任意一個表裡面都可以
authorDetail=models.OneToOneField(to="AuthorDetail",to_field="nid",on_delete=models.CASCADE) #就是foreignkey+unique,只不過不需要我們自己來寫參數了,並且orm會自動幫你給這個欄位名字拼上一個_id,資料庫中欄位名稱為authorDetail_id
class AuthorDetail(models.Model):#不常用的放到這個表裡面
nid = models.AutoField(primary_key=True)
birthday=models.DateField()
telephone=models.BigIntegerField()
addr=models.CharField( max_length=64)
class Publish(models.Model):
nid = models.AutoField(primary_key=True)
name=models.CharField( max_length=32)
city=models.CharField( max_length=32)
email=models.EmailField()
#多對多的表關係,我們學mysql的時候是怎麼建立的,是不是手動創建一個第三張表,然後寫上兩個欄位,每個欄位外鍵關聯到另外兩張多對多關係的表,orm的manytomany自動幫我們創建第三張表,兩種方式建立關係都可以,以後的學習我們暫時用orm自動創建的第三張表,因為手動創建的第三張表我們進行orm操作的時候,很多關於多對多關係的表之間的orm語句方法無法使用#如果你想刪除某張表,你只需要將這個表註銷掉,然後執行那兩個資料庫同步指令就可以了,自動就刪除了。
class Book(models.Model):
nid = models.AutoField(primary_key=True)
title = models.CharField( max_length=32)
publishDate=models.DateField()
price=models.DecimalField(max_digits=5,decimal_places=2)
# 與Publish建立一對多的關係,外鍵欄位建立在多的一方,欄位publish如果是外鍵欄位,那麼它自動是int類型
publish=models.ForeignKey(to="Publish",to_field="nid",on_delete=models.CASCADE) #foreignkey裡面可以加很多的參數,都是需要咱們學習的,慢慢來,to指向表,to_field指向你關聯的欄位,不寫這個,預設會自動關聯主鍵欄位,on_delete級聯刪除 欄位名稱不需要寫成publish_id,orm在翻譯foreignkey的時候會自動給你這個欄位拼上一個_id,這個欄位名稱在資料庫裡面就自動變成了publish_id
# 與Author表建立多對多的關係,ManyToManyField可以建在兩個模型中的任意一個,自動創建第三張表,並且註意一點,你查看book表的時候,你看不到這個欄位,因為這個欄位就是創建第三張表的意思,不是創建欄位的意思,所以只能說這個book類裡面有authors這個欄位屬性
authors=models.ManyToManyField(to='Author',) #註意不管是一對多還是多對多,寫to這個參數的時候,最後後面的值是個字元串,不然你就需要將你要關聯的那個表放到這個表的上面
關於多對多表的三種創建方式(目前你先作為瞭解)
方式一:自行創建第三張表
class Book(models.Model):
title = models.CharField(max_length=32, verbose_name="書名")
class Author(models.Model):
name = models.CharField(max_length=32, verbose_name="作者姓名")
# 自己創建第三張表,分別通過外鍵關聯書和作者
class Author2Book(models.Model):
author = models.ForeignKey(to="Author")
book = models.ForeignKey(to="Book")
class Meta:
unique_together = ("author", "book")方式二:通過ManyToManyField自動創建第三張表
class Book(models.Model):
title = models.CharField(max_length=32, verbose_name="書名")
# 通過ORM自帶的ManyToManyField自動創建第三張表
class Author(models.Model):
name = models.CharField(max_length=32, verbose_name="作者姓名")
books = models.ManyToManyField(to="Book", related_name="authors") #自動生成的第三張表我們是沒有辦法添加其他欄位的方式三:設置ManyTomanyField
並指定自行創建的第三張表(稱為中介模型)
class Book(models.Model):
title = models.CharField(max_length=32, verbose_name="書名")
# 自己創建第三張表,並通過ManyToManyField指定關聯
class Author(models.Model):
name = models.CharField(max_length=32, verbose_name="作者姓名")
books = models.ManyToManyField(to="Book", through="Author2Book", through_fields=("author", "book"))
# through_fields接受一個2元組('field1','field2'):
# 其中field1是定義ManyToManyField的模型外鍵的名(author),field2是關聯目標模型(book)的外鍵名。
class Author2Book(models.Model):
author = models.ForeignKey(to="Author")
book = models.ForeignKey(to="Book")
#可以擴展其他的欄位了
class Meta:
unique_together = ("author", "book")
註意:
當我們需要在第三張關係表中存儲額外的欄位時,就要使用第三種方式,第三種方式還是可以使用多對多關聯關係操作的介面(all、add、clear等等)
當我們使用第一種方式創建多對多關聯關係時,就無法使用orm提供的set、add、remove、clear方法來管理多對多的關係了。
to
設置要關聯的表。
to_field
設置要關聯的欄位。
on_delete
同ForeignKey欄位。to
設置要關聯的表
to_field
設置要關聯的表的欄位
related_name
反向操作時,使用的欄位名,用於代替原反向查詢時的'表名_set'。
related_query_name
反向查詢操作時,使用的連接首碼,用於替換表名。
on_delete
當刪除關聯表中的數據時,當前表與其關聯的行的行為。多對多的參數:
to
設置要關聯的表
related_name
同ForeignKey欄位。
related_query_name
同ForeignKey欄位。
through
在使用ManyToManyField欄位時,Django將自動生成一張表來管理多對多的關聯關係。
但我們也可以手動創建第三張表來管理多對多關係,此時就需要通過
through來指定第三張表的表名。
through_fields
設置關聯的欄位。
db_table
預設創建第三張表時,資料庫中表的名稱。 元信息
ORM對應的類裡面包含另一個Meta類,而Meta類封裝了一些資料庫的信息。主要欄位如下:
class Author2Book(models.Model):
author = models.ForeignKey(to="Author")
book = models.ForeignKey(to="Book")
class Meta:
unique_together = ("author", "book")
db_table
ORM在資料庫中的表名預設是 app_類名,可以通過db_table可以重寫表名。db_table = 'book_model'
index_together
聯合索引。
unique_together
聯合唯一索引。
ordering
指定預設按什麼欄位排序。
ordering = ['pub_date',]
只有設置了該屬性,我們查詢到的結果才可以被reverse(),否則是能對排序了的結果進行反轉(order_by()方法排序過的數據)獲取元信息,可以通過model對象._meta.verbose_name等獲取自己通過verbose_name指定的表名,model對象._meta.model_name獲取小寫的表名,還有model對象.app_label可以獲取這個對象的app應用名等等操作。例如:book_obj = models.Book.objects.get(id=1),book_obj._meta.model_name。
關於db_column和verbose_name
1.指定欄位名: 在定義欄位的時候,增加參數db_column=’real_field’;
2.指定表名: 在model的class中,添加Meta類,在Meta類中指定表名db_table
例如在某個models.py文件中,有一個類叫Info:
class Info(models.Model):
'''''
信息統計
'''
app_id = models.ForeignKey(App)
app_name = models.CharField(verbose_name='應用名', max_length=32, db_column='app_name2')
class Meta:
db_table = 'info'
verbose_name = '信息統計'
verbose_name_plural = '信息統計' 其中db_column指定了對應的欄位名,db_table指定了對應的表明;
如果不這樣指定,欄位名預設為app_name, 而表明預設為app名+類名: [app_name]_info.
verbose_name指定在admin管理界面中顯示中文;verbose_name表示單數形式的顯示,verbose_name_plural表示覆數形式的顯示;中文的單數和複數一般不作區別。
創建完這個表,我們自己可以通過navicat工具來看看資料庫裡面的那些表,出版社這個表裡面沒有任何的關係欄位,這種單表的數據,我們可以先添加幾條數據,在進行下麵的增刪改查的操作。
生成表如下:
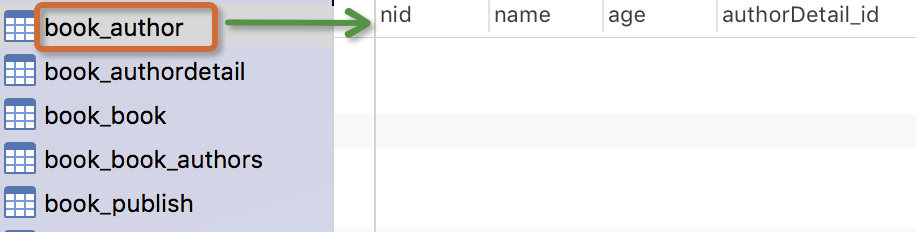

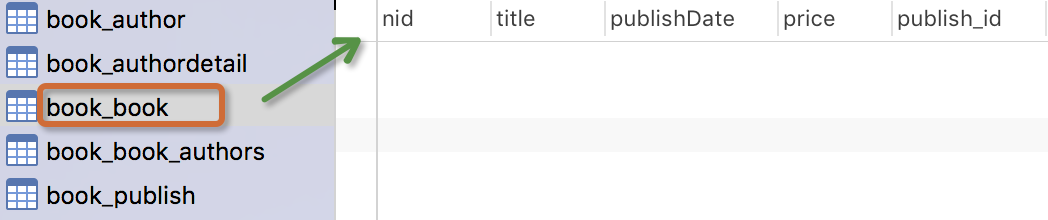
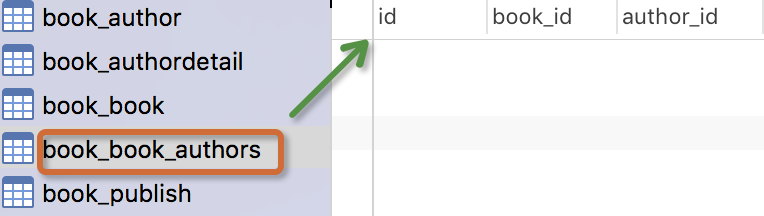
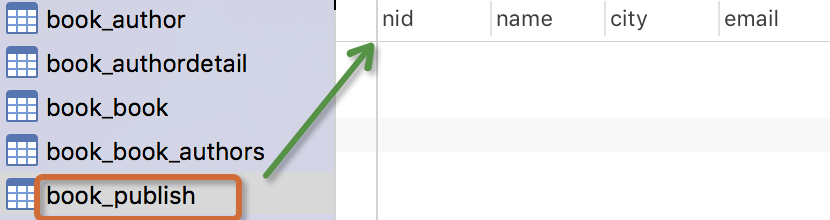
註意事項:
- 表的名稱
myapp_modelName,是根據 模型中的元數據自動生成的,也可以覆寫為別的名稱 id欄位是自動添加的- 對於外鍵欄位,Django 會在欄位名上添加
"_id"來創建資料庫中的列名 - 這個例子中的
CREATE TABLESQL 語句使用PostgreSQL 語法格式,要註意的是Django 會根據settings 中指定的資料庫類型來使用相應的SQL 語句。 - 定義好模型之後,你需要告訴Django _使用_這些模型。你要做的就是修改配置文件中的INSTALL_APPSZ中設置,在其中添加
models.py所在應用的名稱。 - 外鍵欄位 ForeignKey 有一個 null=True 的設置(它允許外鍵接受空值 NULL),你可以賦給它空值 None 。
咱們的表裡麵包含了一對一、一對多、多對多的關係,我們基於這幾個表來練習,將來無論有多少張表,都逃脫不了這三個關係,操作起來都是一樣的。
關於on_delete(瞭解)
on_delete
當刪除關聯表中的數據時,當前表與其關聯的行的行為。
models.CASCADE
刪除關聯數據,與之關聯也刪除
models.DO_NOTHING
刪除關聯數據,引發錯誤IntegrityError
models.PROTECT
刪除關聯數據,引發錯誤ProtectedError
models.SET_NULL
刪除關聯數據,與之關聯的值設置為null(前提FK欄位需要設置為可空)
models.SET_DEFAULT
刪除關聯數據,與之關聯的值設置為預設值(前提FK欄位需要設置預設值)
models.SET
刪除關聯數據,
a. 與之關聯的值設置為指定值,設置:models.SET(值)
b. 與之關聯的值設置為可執行對象的返回值,設置:models.SET(可執行對象)ForeignKey的db_contraint參數
關係和約束大家要搞清楚,我不加外鍵能不能表示兩個表之間的關係啊,當然可以
但是我們就不能使用ORM外鍵相關的方法了,所以我們單純的將外鍵換成一個其他欄位類型,只是單純的存著另外一個關聯表的主鍵值是不能使用ORM外鍵方法的。
#db_constraint=False只加兩者的關係,沒有強制約束的效果,並且ORM外鍵相關的介面(方法)還能使用,所以如果將來公司讓你建立外鍵,並且不能有強制的約束關係,那麼就可以將這個參數改為False
customer = models.ForeignKey(verbose_name='關聯客戶', to='Customer',db_constraint=False)
二 添加表記錄
操作前先簡單的錄入一些數據:還是create和save兩個方法,和單表的區別就是看看怎麼添加關聯欄位的數據
publish表:

author表:
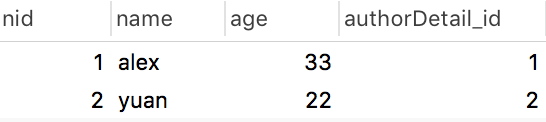
authordetail表:
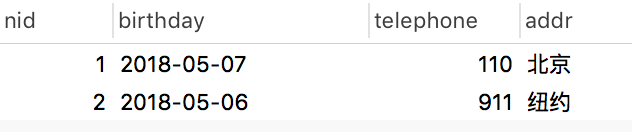
一對多
方式1:
publish_obj=Publish.objects.get(nid=1) #拿到nid為1的出版社對象
book_obj=Book.objects.create(title="金瓶眉",publishDate="2012-12-12",price=100,publish=publish_obj) #出版社對象作為值給publish,其實就是自動將publish欄位變成publish_id,然後將publish_obj的id給取出來賦值給publish_id欄位,註意你如果不是publish類的對象肯定會報錯的,別亂昂
方式2:
book_obj=Book.objects.create(title="金瓶眉",publishDate="2012-12-12",price=100,publish_id=1) #直接可以寫id值,註意欄位屬性的寫法和上面不同,這個是publish_id=xxx,上面是publish=xxx。 
核心:book_obj.publish與book_obj.publish_id是什麼?
多對多
方式一: 多對多一般在前端頁面上使用的時候是多選下拉框的樣子來給用戶選擇多個數據,這裡可以讓用戶選擇多個書籍,多個作者 # 當前生成的書籍對象
book_obj=Book.objects.create(title="追風箏的人",price=200,publishDate="2012-11-12",publish_id=1)
# 為書籍綁定的做作者對象
yuan=Author.objects.filter(name="yuan").first() # 在Author表中主鍵為2的紀錄,註意取的是author的model對象
egon=Author.objects.filter(name="alex").first() # 在Author表中主鍵為1的紀錄
#有人可能會說,我們可以直接給第三張表添加數據啊,這個自動生成的第三張表你能通過models獲取到嗎,是獲取不到的,用不了的,當然如果你知道了這個表的名字,那麼你通過原生sql語句可以進行書的添加,所以要通過orm間接的給第三張表添加數據,如果是你手動添加的第三張表你是可以直接給第三張表添加數據
# 綁定多對多關係,即向關係表book_authors中添加紀錄,給書添加兩個作者,下麵的語法就是告訴orm給第三張表添加兩條數據
book_obj.authors.add(yuan,egon) # 將某些特定的 model 對象添加到被關聯對象集合中。 ======= book_obj.authors.add(*[]) #book_obj是書籍對象,authors是book表裡面那個多對多的關係欄位名稱。 #其實orm就是先通過book_obj的authors屬性找到第三張表,然後將book_obj的id值和兩個作者對象的id值組合成兩條記錄添加到第三張表裡面去 方式二
book_obj.authors.add(1,2)
book_obj.authors.add(*[1,2]) #這種方式用的最多,因為一般是給用戶來選擇,用戶選擇是多選的,選完給你發送過來的就是一堆的id值
資料庫表紀錄生成如下:
book表

book_authors表

核心:book_obj.authors.all()是什麼?
多對多關係其它常用API:
book_obj.authors.remove() # 將某個特定的對象從被關聯對象集合中去除。 ====== book_obj.authors.remove(*[1,2]),將多對多的關係數據刪除
book_obj.authors.clear() #清空被關聯對象集合
book_obj.authors.set() #先清空再設置 ===== 刪除示例:
book_obj = models.Book.objects.filter(nid=4)[0]
# book_obj.authors.remove(2) #將第三張表中的這個book_obj對象對應的那個作者id為2的那條記錄刪除
# book_obj.authors.clear()
# book_obj.authors.set('2') #先清除掉所有的關係數據,然後只給這個書對象綁定這個id為2的作者,所以只剩下一條記錄 3---2,比如用戶編輯數據的時候,選擇作者發生了變化,那麼需要重新選擇,所以我們就可以先清空,然後再重新綁定關係數據,註意這裡寫的是字元串,數字類型不可以
book_obj.authors.set(['1',]) #這麼寫也可以,但是註意列表中的元素是字元串,列表前面沒有*,之前我測試有*,感覺是版本的問題,沒事,能夠用哪個用哪個more(瞭解)
一對一和一對多的刪改和單表的刪改是一樣的,別忘了刪除表的時候,咱們是做了級聯刪除的。
更新:
book_obj = models.Book.objects.get(id=1) #獲取一個書籍對象
data = {'title':'xxx','price':100} #這個書籍對象更新後的數據
models.Book.objects.filter(id=n).update(**data) #將新數據更新到原來的記錄中
book_obj.authors.set(author_list) #將數據和作者的多對多關係加上
刪除:
models.Book.objects.filter(id=1).delete()接下來要學的查詢就是咱的重頭戲了,比較複雜。
三 基於對象的跨表查詢
跨表查詢是分組查詢的基礎,F和Q查詢是最簡單的,所以認真學習跨表查詢
一對多查詢(Publish 與 Book)

正向查詢(按欄位:publish):關聯屬性欄位所在的表查詢被關聯表的記錄就是正向查詢,反之就是反向查詢
# 查詢主鍵為1的書籍的出版社所在的城市
book_obj=Book.objects.filter(pk=1).first()
# book_obj.publish 是主鍵為1的書籍對象關聯的出版社對象,book對象.外鍵欄位名稱
print(book_obj.publish.city) 反向查詢(按表名:book_set,因為加上_set是因為反向查詢的時候,你查詢出來的可能是多條記錄的集合):
publish=Publish.objects.get(name="蘋果出版社")
#publish.book_set.all() : 與蘋果出版社關聯的所有書籍對象集合,寫法:小寫的表名_set.all(),得到queryset類型數據
book_list=publish.book_set.all()
for book_obj in book_list:
print(book_obj.title)
一對一查詢(Author與AuthorDetail)

正向查詢(按欄位:authorDetail):
egon=Author.objects.filter(name="egon").first()
print(egon.authorDetail.telephone) egon.authorDeail就拿到了這個對象,因為一對一找到的就是一條記錄,註意寫法:作者對象.欄位名,就拿到了那個關聯對象反向查詢(按表名:author):不需要_set,因為一對一正向反向都是找到一條記錄
# 查詢所有住址在北京的作者的姓名
authorDet=AuthorDetail.objects.filter(addr="beijing")[0]
authorDet.author.name多對多查詢(Author與Book)

正向查詢(按欄位:authors):
反向查詢(按表名:book_set):
註意:
你可以通過在 ForeignKey() 和ManyToManyField的定義中設置 related_name 的值來覆寫 FOO_set 的名稱。例如,如果 Article model 中做一下更改:
那麼接下來就會如我們看到這般:
在這裡我們補充一點,因為你很快就要接觸到了,那就是form表單裡面的button按鈕和form表單外面的button按鈕的區別,form表單裡面的button按鈕其實和input type='submit'的標簽是有同樣的效果的,都能夠提交form表單的數據,但是如果放在form表單外面的button按鈕,那就只是個普通的按鈕了。,還有一點,input type='submit'按鈕放到form表單外面那就成了一個普通的按鈕。
四 基於雙下劃線的跨表查詢(基於join實現的)
Django 還提供了一種直觀而高效的方式在查詢(lookups)中表示關聯關係,它能自動確認 SQL JOIN 聯繫。要做跨關係查詢,就使用兩個下劃線來鏈接模型(model)間關聯欄位的名稱,直到最終鏈接到你想要的model 為止。
'''
基於雙下劃線的查詢就一句話:正向查詢按欄位,反向查詢按表名小寫用來告訴ORM引擎join哪張表,一對一、一對多、多對多都是一個寫法,註意,我們寫orm查詢的時候,哪個表在前哪個表在後都沒問題,因為走的是join連表操作。
'''一對多查詢
# 練習: 查詢蘋果出版社出版過的所有書籍的名字與價格(一對多)
# 正向查詢 按欄位:publish
queryResult=Book.objects
.filter(publish__name="蘋果出版社") #通過__告訴orm將book表和publish表進行join,然後找到所有記錄中publish.name='蘋果出版社'的記錄(註意publish是屬性名稱),然後select book.title,book.price的欄位值
.values_list("title","price") #values或者values_list
# 反向查詢 按表名:book
queryResult=Publish.objects
.filter(name="蘋果出版社")
.values_list("book__title","book__price")多對多查詢
# 練習: 查詢yuan出過的所有書籍的名字(多對多)
# 正向查詢 按欄位:authors:
queryResult=Book.objects
.filter(authors__name="yuan")
.values_list("title")
# 反向查詢 按表名:book
queryResult=Author.objects
.filter(name="yuan")
.values_list("book__title","book__price")一對一查詢
# 查詢yuan的手機號
# 正向查詢
ret=Author.objects.filter(name="yuan").values("authordetail__telephone")
# 反向查詢
ret=AuthorDetail.objects.filter(author__name="yuan").values("telephone")進階練習(連續跨表)
# 練習: 查詢人民出版社出版過的所有書籍的名字以及作者的姓名
# 正向查詢
queryResult=Book.objects
.filter(publish__name="人民出版社")
.values_list("title","authors__name")
# 反向查詢
queryResult=Publish.objects
.filter(name="人民出版社")
.values_list("book__title","book__authors__age","book__authors__name")
# 練習: 手機號以151開頭的作者出版過的所有書籍名稱以及出版社名稱
# 方式1:
queryResult=Book.objects
.filter(authors__authorDetail__telephone__regex="151")
.values_list("title","publish__name")
# 方式2:
ret=Author.objects
.filter(authordetail__telephone__startswith="151")
.values("book__title","book__publish__name")related_name
反向查詢時,如果定義了related_name ,則用related_name替換 表名,例如:
# 練習: 查詢人民出版社出版過的所有書籍的名字與價格(一對多)# 反向查詢 不再按表名:book,而是related_name:bookList
queryResult=Publish.objects
.filter(name="人民出版社")
.values_list("bookList__title","bookList__price") 五 聚合查詢、分組查詢、F查詢和Q查詢
聚合
aggregate(*args, **kwargs)
# 計算所有圖書的平均價格
>>> from django.db.models import Avg
>>> Book.objects.all().aggregate(Avg('price')) #或者給它起名字:aggretate(a=Avg('price'))
{'price__avg': 34.35}
aggregate()是QuerySet 的一個終止子句,意思是說,它返回一個包含一些鍵值對的字典。鍵的名稱是聚合值的標識符,值是計算出來的聚合值。鍵的名稱是按照欄位和聚合函數的名稱自動生成出來的。如果你想要為聚合值指定一個名稱,可以向聚合子句提供它。
>>> Book.objects.aggregate(average_price=Avg('price'))
{'average_price': 34.35}
如果你希望生成不止一個聚合,你可以向aggregate()子句中添加另一個參數。所以,如果你也想知道所有圖書價格的最大值和最小值,可以這樣查詢:
>>> from django.db.models import Avg, Max, Min
>>> Book.objects.aggregate(Avg('price'), Max('price'), Min('price')) #count('id'),count(1)也可以統計個數,Book.objects.all().aggregete和Book.objects.aggregate(),都可以
{'price__avg': 34.35, 'price__max': Decimal('81.20'), 'price__min': Decimal('12.99')}分組
###################################--單表分組查詢--#######################################################
查詢每一個部門名稱以及對應的員工數
emp:
id name age salary dep
1 alex 12 2000 銷售部
2 egon 22 3000 人事部
3 wen 22 5000 人事部
sql語句:
select dep,Count(*) from emp group by dep;
ORM:
emp.objects.values("dep").annotate(c=Count("id") #註意:annotate裡面必須寫個聚合函數,不然沒有意義,並且必須有個別名=,別名隨便寫,但是必須有,用哪個欄位分組,values裡面就寫哪個欄位,annotate其實就是對分組結果的統計,統計你需要什麼。''' select dep,count('id') as c from emp grouby dep; #原生sql語句中的as c,不是必須有的'''
###################################--多表分組查詢--###########################
多表分組查詢:
查詢每一個部門名稱以及對應的員工數
emp:
id name age salary dep_id
1 alex 12 2000 1
2 egon 22 3000 2
3 wen 22 5000 2
dep
id name
1 銷售部
2 人事部
emp-dep:
id name age salary dep_id id name
1 alex 12 2000 1 1 銷售部
2 egon 22 3000 2 2 人事部
3 wen 22 5000 2 2 人事部
sql語句:
select dep.name,Count(*) from emp left join dep on emp.dep_id=dep.id group by dep.id
ORM:
dep.objetcs.values("id").annotate(c=Count("emp")).values("name","c")
ret = models.Emp.objects.values('dep_id','name').annotate(a=Count(1)) ''' SELECT `app01_emp`.`dep_id`, `app01_emp`.`name`, COUNT(1) AS `a` FROM `app01_emp` GROUP BY `app01_emp`.`dep_id`, `app01_emp`.`name`'''#<QuerySet [{'dep_id': 1, 'name': 'alex', 'a': 1}, {'dep_id': 2, 'name': 'egon', 'a': 1}, {'dep_id': 2, 'name': 'wen', 'a': 1}]>,註意,這裡如果你寫了其他欄位,那麼只有這兩個欄位重覆,才算一組,合併到一起來統計個數
class Emp(models.Model):
name=models.CharField(max_length=32)
age=models.IntegerField()
salary=models.DecimalField(max_digits=8,decimal_places=2)
dep=models.CharField(max_length=32)
province=models.CharField(max_length=32) annotate()為調用的QuerySet中每一個對象都生成一個獨立的統計值(統計方法用聚合函數)。
總結 :跨表分組查詢本質就是將關聯表join成一張表,再按單表的思路進行分組查詢,,既然是join連表,就可以使用咱們的雙下劃線進行連表了。
#單表:
#查詢每一個部門的id以及對應員工的平均薪水
ret = models.Emp.objects.values('dep_id').annotate(s=Avg('salary'))
#查詢每個部門的id以及對對應的員工的最大年齡
ret = models.Emp.objects.values('dep_id').annotate(a=Max('age'))
#Emp表示表,values中的欄位表示按照哪個欄位group by,annotate裡面是顯示分組統計的是什麼
#連表:
# 查詢每個部門的名稱以及對應的員工個數和員工最大年齡
ret = models.Emp.objects.values('dep__name').annotate(a=Count('id'),b=Max('age')) #註意,正向與反向的結果可能不同,如果反向查的時候,有的部門還沒有員工,那麼他的數據也會被統計出來,只不過值為0,但是正向查的話只能統計出來有員工的部門的相關數據,因為通過你是員工找部門,而不是通過部門找員工,結果集裡面的數據個數不同,但是你想要的統計結果是一樣的
#<QuerySet [{'a': 1, 'dep__name': '銷售部', 'b': 12}, {'a': 3, 'dep__name': '人事部', 'b': 22}]>
#使用雙下劃線進行連表,然後按照部門名稱進行分組,然後統計員工個數和最大年齡,最後結果裡面顯示的是部門名稱、個數、最大年齡。
#註意:如果values裡面有多個欄位的情況:ret = models.Emp.objects.values('dep__name','age').annotate(a=Count('id'),b=Max('age')) #是按照values裡面的兩個欄位進行分組,兩個欄位同時相同才算是一組,看下麵的sql語句''' SELECT `app01_dep`.`name`, `app01_emp`.`age`, COUNT(`app01_emp`.`id`) AS `a`, MAX(`app01_emp`.`age`) AS `b` FROM `app01_emp` INNER JOIN `app01_dep` ON (`app01_emp`.`dep_id` = `app01_dep`.`id`) GROUP BY `app01_dep`.`name`, `app01_emp`.`age`;'''
下麵是書籍表和出版社表的一個連表分組的sql語句寫法:

查詢練習
(1) 練習:統計每一個出版社的最便宜的書
publishList=Publish.objects.annotate(MinPrice=Min("book__price")) #如果沒有使用objects後面values或者values_list,得到的結果是queryset類型,裡面是Publish的model對象,並且是對所有記
錄進行的統計,統計的Minprice也成了這些model對象裡面的一個屬性,這種連表分組統計的寫法最常用,思路也比較清晰
for publish_obj in publishList:
print(publish_obj.name,publish_obj.MinPrice)
annotate的返回值是querySet,如果不想遍歷對象,可以用上valuelist:
queryResult= Publish.objects
.annotate(MinPrice=Min("book__price"))
.values_list("name","MinPrice")
print(queryResult)'''
SELECT "app01_publish"."name", MIN("app01_book"."price") AS "MinPrice" FROM "app01_publish"
LEFT JOIN "app01_book" ON ("app01_publish"."nid" = "app01_book"."publish_id")
GROUP BY "app01_publish"."nid", "app01_publish"."name", "app01_publish"."city", "app01_publish"."email"
'''(2) 練習:統計每一本書的作者個數
ret=Book.objects.annotate(authorsNum=Count('authors__name'))
ret=models.Book.objects.annotate(authorsNum=Count('authors__name')).values('title','authorsNum') #註意寫法,values裡面寫的個數的別名ret=models.Book.objects.annotate(a=Count('author__name')).filter(a__gt=2).values('title','a') #還有這種寫法,看看你能不能明白這是在做什麼(3) 統計每一本以py開頭的書籍的作者個數:
queryResult=Book.objects
.filter(title__startswith="Py")
.annotate(num_authors=Count('authors')) #連接第三張表再連接author表,where title regexp '^Py' 然後按照連表後的大表中的book表的title欄位進行分組,並且統計對應作者的個數(4) 統計不止一個作者的圖書:
queryResult=Book.objects
.annotate(num_authors=Count('authors'))
.filter(num_authors__gt=1) #filter也是也可以是querset來調用 (5) 根據一本圖書作者數量的多少對查詢集 QuerySet進行排序:
Book.objects.annotate(num_authors=Count('authors')).order_by('num_authors')
(6) 查詢各個作者出的書的總價格:
# 按author表的所有欄位 group by
queryResult=Author.objects .annotate(SumPrice=Sum("book__price")) .values_list("name","SumPrice")
print(queryResult)F查詢與Q查詢
F查詢
在上面所有的例子中,我們構造的過濾器都只是將欄位值與某個常量做比較。如果我們要對兩個欄位的值做比較,那該怎麼做呢?我們在book表裡面加上兩個欄位:評論數:commentNum,收藏數:KeepNum
Django 提供 F() 來做這樣的比較。F() 的實例可以在查詢中引用欄位,來比較同一個 model 實例中兩個不同欄位的值。
# 查詢評論數大於收藏數的書籍
from django.db.models import F
Book.objects.filter(commentNum__lt=F('keepNum'))
Django 支持 F() 對象之間以及 F() 對象和常數之間的加減乘除和取模的操作。
# 查詢評論數大於收藏數2倍的書籍
Book.objects.filter(commentNum__lt=F('keepNum')*2)
修改操作也可以使用F函數,比如將每一本書的價格提高30元:
Book.objects.all().update(price=F("price")+30)
Q查詢
filter() 等方法中的關鍵字參數查詢都是一起進行“AND” 的。 如果你需要執行更複雜的查詢(例如OR 語句),你可以使用Q 對象。
from django.db.models import Q
Q(title__startswith='Py')
Q 對象可以使用&(與) 、|(或)、~(非) 操作符組合起來。當一個操作符在兩個Q 對象上使用時,它產生一個新的Q 對象。
bookList=Book.objects.filter(Q(authors__name="yuan")|Q(authors__name="egon"))
等同於下麵的SQL WHERE 子句:
WHERE name ="yuan" OR name ="egon"
你可以組合& 和| 操作符以及使用括弧進行分組來編寫任意複雜的Q 對象。同時,Q 對象可以使用~ 操作符取反,這允許組合正常的查詢和取反(NOT) 查詢:
bookList=Book.objects.filter(Q(authors__name="yuan") & ~Q(publishDate__year=2017)).values_list("title")
bookList=Book.objects.filter(Q(Q(authors__name="yuan") & ~Q(publishDate__year=2017))&Q(id__gt=6)).values_list("title") #可以進行Q嵌套,多層Q嵌套等,其實工作中比較常用
查詢函數可以混合使用Q 對象和關鍵字參數。所有提供給查詢函數的參數(關鍵字參數或Q 對象)都將"AND”在一起。但是,如果出現Q 對象,它必須位於所有關鍵字參數的前面。例如:
bookList``=``Book.objects.``filter``(Q(publishDate__year``=``2016``) | Q(publishDate__year``=``2017``),
``title__icontains``=``"python" #也是and的關係,但是Q必須寫在前面
``)綜合查詢練習題
#1 查詢每個作者的姓名以及出版的書的最高價格
ret = models.Author.objects.values('name').annotate(max_price=Max('book__price'))
print(ret) #註意:values寫在annotate前面是作為分組依據用的,並且返回給你的值就是這個values裡面的欄位(name)和分組統計的結果欄位數據(max_price)
# ret = models.Author.objects.annotate(max_price=Max('book__price')).values('name','max_price')#這種寫法是按照Author表的id欄位進行分組,返回給你的是這個表的所有model對象,這個對象裡面包含著max_price這個屬性,後面寫values方法是獲取的這些對象的屬性的值,當然,可以加雙下劃線來連表獲取其他關聯表的數據,但是獲取的其他關聯表數據是你的這些model對象對應的數據,而關聯獲取的數據可能不是你想要的最大值對應的那些數據
# 2 查詢作者id大於2作者的姓名以及出版的書的最高價格
ret = models.Author.objects.filter(id__gt=2).annotate(max_price=Max('book__price')).values('name','max_price')#記著,這個values取得是前面調用這個方法的表的所有欄位值以及max_pirce的值,這也是為什麼我們取關聯數據的時候要加雙劃線的原因
print(ret)
#3 查詢作者id大於2或者作者年齡大於等於20歲的女作者的姓名以及出版的書的最高價格
# ret = models.Author.objects.filter(Q(id__gt=2)|Q(age__gte=20),sex='female').annotate(max_price=Max('book__price')).values('name','max_price')
#4 查詢每個作者出版的書的最高價格 的平均值
# ret = models.Author.objects.values('id').annotate(max_price=Max('book__price')).aggregate(Avg('max_price')) #{'max_price__avg': 555.0} 註意,aggregate是queryset的終止句,得到的是字典
# ret = models.Author.objects.annotate(max_price=Max('book__price')).aggregate(Avg('max_price')) #{'max_price__avg': 555.0} 註意,aggregate是queryset的終止句,得到的是字典
#5 每個作者出版的所有書的最高價格以及最高價格的那本書的名稱(通過orm玩起來就是個死題,需要用原生sql)
'''
select title,price from (select app01_author.id,app01_book.title,app01_book.price from app01_author INNER JOIN app01_book_authors on app01_author.id=
app01_book_authors.author_id INNER JOIN app01_book on app01_book.id=
app01_book_authors.book_id ORDER BY app01_book.price desc) as b GROUP BY id
'''
print(ret)六 ORM執行原生sql語句(瞭解)
在模型查詢API不夠用的情況下,我們還可以使用原始的SQL語句進行查詢。
Django 提供兩種方法使用原始SQL進行查詢:一種是使用raw()方法,進行原始SQL查詢並返回模型實例;另一種是完全避開模型層,直接執行自定義的SQL語句。
執行原生查詢
raw()管理器方法用於原始的SQL查詢,並返回模型的實例:
註意:raw()語法查詢必須包含主鍵。
這個方法執行原始的SQL查詢,並返回一個django.db.models.query.RawQuerySet 實例。 這個RawQuerySet 實例可以像一般的QuerySet那樣,通過迭代來提供對象實例。
舉個例子:
class Person(models.Model):
first_name = models.CharField(...)
last_name = models.CharField(...)
birth_date = models.DateField(...)可以像下麵這樣執行原生SQL語句
>>> for p in Person.objects.raw('SELECT * FROM myapp_person'):
... print(p)raw()查詢可以查詢其他表的數據。
舉個例子:
ret = models.Student.objects.raw('select id, tname as hehe from app02_teacher')
for i in ret:
print(i.id, i.hehe)raw()方法自動將查詢欄位映射到模型欄位。還可以通過translations參數指定一個把查詢的欄位名和ORM對象實例的欄位名互相對應的字典
d = {'tname': 'haha'}
ret = models.Student.objects.raw('select * from app02_teacher', translations=d)
for i in ret:
print(i.id, i.sname, i.haha)原生SQL還可以使用參數,註意不要自己使用字元串格式化拼接SQL語句,防止SQL註入!
d = {'tname': 'haha'}
ret = models.Student.objects.raw('select * from app02_teacher where id > %s', translations=d, params=[1,])
for i in ret:
print(i.id, i.sname, i.haha)直接執行自定義SQL
有時候raw()方法並不十分好用,很多情況下我們不需要將查詢結果映射成模型,或者我們需要執行DELETE、 INSERT以及UPDATE操作。在這些情況下,我們可以直接訪問資料庫,完全避開模型層。
我們可以直接從django提供的介面中獲取資料庫連接,然後像使用pymysql模塊一樣操作資料庫。
from django.db import connection, connections
cursor = connection.cursor() # cursor = connections['default'].cursor()
cursor.execute("""SELECT * from auth_user where id = %s""", [1])
ret = cursor.fetchone() 七 Python腳本中調用Django環境
(django外部腳本使用models)
如果你想通過自己創建的python文件在django項目中使用django的models,那麼就需要調用django的環境:
import os
if __name__ == '__main__':
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "BMS.settings")
import django
django.setup()
from app01 import models #引入也要寫在上面三句之後
books = models.Book.objects.all()
print(books)八 補充多個app配置models
app01的models文件內容
from django.db import models
# Create your models here.
class UserInfo(models.Model):
name = models.CharField(max_length=12)app02的models文件內容
from django.db import models
# Create your models here.
class Class(models.Model):
title = models.CharField(max_length=32)
user = models.ForeignKey('app01.Userinfo') #如果需要兩個app之間的models進行關聯,直接這樣寫就可以,或者直接將那個被關聯的表,通過import的方法引入進行進行關聯。不需要進行其他的配置了,直接執行資料庫同步指令就可以了。
關於多個app多個資料庫,並且數據有關聯時的一些玩法,等後面我再補充吧

