
1. 3種系統架構與2種存儲器共用方式 1.1 架構概述 從系統架構來看,目前的商用伺服器大體可以分為三類 對稱多處理器結構(SMP:Symmetric Multi Processor) 非一致存儲訪問結構(NUMA:Non Uniform Memory Access) 海量並行處理結構(MPP:M ...
1. 3種系統架構與2種存儲器共用方式
1.1 架構概述
從系統架構來看,目前的商用伺服器大體可以分為三類
- 對稱多處理器結構(SMP:Symmetric Multi-Processor)
- 非一致存儲訪問結構(NUMA:Non-Uniform Memory Access)
- 海量並行處理結構(MPP:Massive Parallel Processing)。
共用存儲型多處理機有兩種模型
- 均勻存儲器存取(Uniform-Memory-Access,簡稱UMA)模型
- 非均勻存儲器存取(Nonuniform-Memory-Access,簡稱NUMA)模型
而我們後面所提到的COMA和ccNUMA都是NUMA結構的改進
1.2 SMP(Symmetric Multi-Processor)
所謂對稱多處理器結構,是指伺服器中多個CPU對稱工作,無主次或從屬關係。
各CPU共用相同的物理記憶體,每個 CPU訪問記憶體中的任何地址所需時間是相同的,因此SMP也被稱為一致存儲器訪問結構(UMA:Uniform Memory Access)
對SMP伺服器進行擴展的方式包括增加記憶體、使用更快的CPU、增加CPU、擴充I/O(槽口數與匯流排數)以及添加更多的外部設備(通常是磁碟存儲)。
SMP伺服器的主要特征是共用,系統中所有資源(CPU、記憶體、I/O等)都是共用的。也正是由於這種特征,導致了SMP伺服器的主要問題,那就是它的擴展能力非常有限。
對於SMP伺服器而言,每一個共用的環節都可能造成SMP伺服器擴展時的瓶頸,而最受限制的則是記憶體。由於每個CPU必須通過相同的記憶體匯流排訪問相同的記憶體資源,因此隨著CPU數量的增加,記憶體訪問衝突將迅速增加,最終會造成CPU資源的浪費,使CPU性能的有效性大大降低。實驗證明,SMP伺服器CPU利用率最好的情況是2至4個CPU
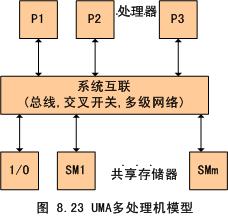
圖中,物理存儲器被所有處理機均勻共用。所有處理機對所有存儲字具有相同的存取時間,這就是為什麼稱它為均勻存儲器存取的原因。每台處理機可以有私用高速緩存,外圍設備也以一定形式共用
1.3 NUMA(Non-Uniform Memory Access)
由於SMP在擴展能力上的限制,人們開始探究如何進行有效地擴展從而構建大型系統的技術,NUMA就是這種努力下的結果之一
利用NUMA技術,可以把幾十個CPU(甚至上百個CPU)組合在一個伺服器內.
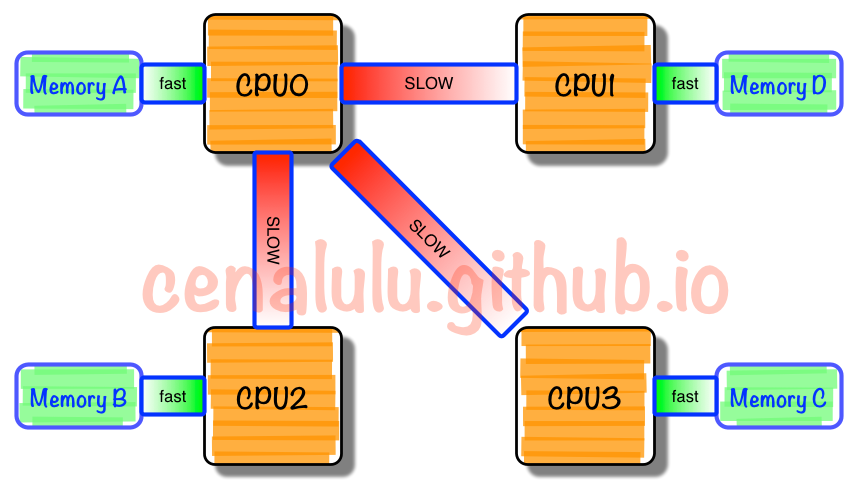
NUMA多處理機模型如圖所示,其訪問時間隨存儲字的位置不同而變化。其共用存儲器物理上是分佈在所有處理機的本地存儲器上。所有本地存儲器的集合組成了全局地址空間,可被所有的處理機訪問。處理機訪問本地存儲器是比較快的,但訪問屬於另一臺處理機的遠程存儲器則比較慢,因為通過互連網路會產生附加時延。
NUMA伺服器的基本特征是具有多個CPU模塊,每個CPU模塊由多個CPU(如4個)組成,並且具有獨立的本地記憶體、I/O槽口等。

由於其節點之間可以通過互聯模塊(如稱為Crossbar Switch)進行連接和信息交互,因此每個CPU可以訪問整個系統的記憶體(這是NUMA系統與MPP系統的重要差別)。顯然,訪問本地記憶體的速度將遠遠高於訪問遠地記憶體(系統內其它節點的記憶體)的速度,這也是非一致存儲訪問NUMA的由來。
由於這個特點,為了更好地發揮系統性能,開發應用程式時需要儘量減少不同CPU模塊之間的信息交互。利用NUMA技術,可以較好地解決原來SMP系統的擴展問題,在一個物理伺服器內可以支持上百個CPU。比較典型的NUMA伺服器的例子包括HP的Superdome、SUN15K、IBMp690等。
但NUMA技術同樣有一定缺陷,由於訪問遠地記憶體的延時遠遠超過本地記憶體,因此當CPU數量增加時,系統性能無法線性增加。如HP公司發佈Superdome伺服器時,曾公佈了它與HP其它UNIX伺服器的相對性能值,結果發現,64路CPU的Superdome (NUMA結構)的相對性能值是20,而8路N4000(共用的SMP結構)的相對性能值是6.3. 從這個結果可以看到,8倍數量的CPU換來的只是3倍性能的提升.
1.4 MPP(Massive Parallel Processing)
和NUMA不同,MPP提供了另外一種進行系統擴展的方式,它由多個SMP伺服器通過一定的節點互聯網路進行連接,協同工作,完成相同的任務,從用戶的角度來看是一個伺服器系統。其基本特征是由多個SMP伺服器(每個SMP伺服器稱節點)通過節點互聯網路連接而成,每個節點只訪問自己的本地資源(記憶體、存儲等),是一種完全無共用(Share Nothing)結構,因而擴展能力最好,理論上其擴展無限制,目前的技術可實現512個節點互聯,數千個CPU。目前業界對節點互聯網路暫無標準,如 NCR的Bynet,IBM的SPSwitch,它們都採用了不同的內部實現機制。但節點互聯網僅供MPP伺服器內部使用,對用戶而言是透明的。
在MPP系統中,每個SMP節點也可以運行自己的操作系統、資料庫等。但和NUMA不同的是,它不存在異地記憶體訪問的問題。換言之,每個節點內的CPU不能訪問另一個節點的記憶體。節點之間的信息交互是通過節點互聯網路實現的,這個過程一般稱為數據重分配(Data Redistribution)。
但是MPP伺服器需要一種複雜的機制來調度和平衡各個節點的負載和並行處理過程。目前一些基於MPP技術的伺服器往往通過系統級軟體(如資料庫)來屏蔽這種複雜性。舉例來說,NCR的Teradata就是基於MPP技術的一個關係資料庫軟體,基於此資料庫來開發應用時,不管後臺伺服器由多少個節點組成,開發人員所面對的都是同一個資料庫系統,而不需要考慮如何調度其中某幾個節點的負載。
2 三種體系架構之間的差異
2.1 NUMA、MPP、SMP之間性能的區別
NUMA的節點互聯機制是在同一個物理伺服器內部實現的,當某個CPU需要進行遠地記憶體訪問時,它必須等待,這也是NUMA伺服器無法實現CPU增加時性能線性擴展。
MPP的節點互聯機制是在不同的SMP伺服器外部通過I/O實現的,每個節點只訪問本地記憶體和存儲,節點之間的信息交互與節點本身的處理是並行進行的。因此MPP在增加節點時性能基本上可以實現線性擴展。
SMP所有的CPU資源是共用的,因此完全實現線性擴展。
2.2 NUMA、MPP、SMP之間擴展的區別
NUMA理論上可以無限擴展,目前技術比較成熟的能夠支持上百個CPU進行擴展。如HP的SUPERDOME。
MPP理論上也可以實現無限擴展,目前技術比較成熟的能夠支持512個節點,數千個CPU進行擴展。
SMP擴展能力很差,目前2個到4個CPU的利用率最好,但是IBM的BOOK技術,能夠將CPU擴展到8個。
MPP是由多個SMP構成,多個SMP伺服器通過一定的節點互聯網路進行連接,協同工作,完成相同的任務。
2.3 MPP和SMP、NUMA應用之間的區別
MPP的優勢
MPP系統不共用資源,因此對它而言,資源比SMP要多,當需要處理的事務達到一定規模時,MPP的效率要比SMP好。由於MPP系統因為要在不同處理單元之間傳送信息,在通訊時間少的時候,那MPP系統可以充分發揮資源的優勢,達到高效率。也就是說:操作相互之間沒有什麼關係,處理單元之間需要進行的通信比較少,那採用MPP系統就要好。因此,MPP系統在決策支持和數據挖掘方面顯示了優勢。
SMP的優勢
MPP系統因為要在不同處理單元之間傳送信息,所以它的效率要比SMP要差一點。在通訊時間多的時候,那MPP系統可以充分發揮資源的優勢。因此當前使用的OTLP程式中,用戶訪問一個中心資料庫,如果採用SMP系統結構,它的效率要比採用MPP結構要快得多。
NUMA架構的優勢
NUMA架構來看,它可以在一個物理伺服器內集成許多CPU,使系統具有較高的事務處理能力,由於遠地記憶體訪問時延遠長於本地記憶體訪問,因此需要儘量減少不同CPU模塊之間的數據交互。顯然,NUMA架構更適用於OLTP事務處理環境,當用於數據倉庫環境時,由於大量複雜的數據處理必然導致大量的數據交互,將使CPU的利用率大大降低。
3 總結
傳統的多核運算是使用SMP(Symmetric Multi-Processor )模式:將多個處理器與一個集中的存儲器和I/O匯流排相連。所有處理器只能訪問同一個物理存儲器,因此SMP系統有時也被稱為一致存儲器訪問(UMA)結構體系,一致性意指無論在什麼時候,處理器只能為記憶體的每個數據保持或共用唯一一個數值。很顯然,SMP的缺點是可伸縮性有限,因為在存儲器和I/O介面達到飽和的時候,增加處理器並不能獲得更高的性能,與之相對應的有AMP架構,不同核之間有主從關係,如一個核控制另外一個核的業務,可以理解為多核系統中控制平面和數據平面。
NUMA模式是一種分散式存儲器訪問方式,處理器可以同時訪問不同的存儲器地址,大幅度提高並行性。 NUMA模式下,處理器被劃分成多個”節點”(node), 每個節點被分配有的本地存儲器空間。 所有節點中的處理器都可以訪問全部的系統物理存儲器,但是訪問本節點內的存儲器所需要的時間,比訪問某些遠程節點內的存儲器所花的時間要少得多。
NUMA 的主要優點是伸縮性。NUMA 體繫結構在設計上已超越了 SMP 體繫結構在伸縮性上的限制。通過 SMP,所有的記憶體訪問都傳遞到相同的共用記憶體匯流排。這種方式非常適用於 CPU 數量相對較少的情況,但不適用於具有幾十個甚至幾百個 CPU 的情況,因為這些 CPU 會相互競爭對共用記憶體匯流排的訪問。NUMA 通過限制任何一條記憶體匯流排上的 CPU 數量並依靠高速互連來連接各個節點,從而緩解了這些瓶頸狀況。
名詞解釋
| 概念 | 描述 |
|---|---|
| SMP | 稱為共用存儲型多處理機(Shared Memory mulptiProcessors), 也稱為對稱型多處理機(Symmetry MultiProcessors) |
| UMA | 稱為均勻存儲器存取(Uniform-Memory-Access) |
| NUMA | 非均勻存儲器存取(Nonuniform-Memory-Access) |
| COMA | 只用高速緩存的存儲器結構(Cache-Only Memory Architecture) |
| ccNUMA | 高速緩存相關的非一致性記憶體訪問(CacheCoherentNon-UniformMemoryAccess) |
UMA
物理存儲器被所有處理機均勻共用。所有處理機對所有存儲字具有相同的存取時間,這就是為什麼稱它為均勻存儲器存取的原因。每台處理機可以有私用高速緩存,外圍設備也以一定形式共用。
NUMA
其訪問時間隨存儲字的位置不同而變化。其共用存儲器物理上是分佈在所有處理機的本地存儲器上。所有本地存儲器的集合組成了全局地址空間,可被所有的處理機訪問。處理機訪問本地存儲器是比較快的,但訪問屬於另一臺處理機的遠程存儲器則比較慢,因為通過互連網路會產生附加時延。
COMA
一種只用高速緩存的多處理機。COMA模型是NUMA機的一種特例,只是將後者中分佈主存儲器換成了高速緩存, 在每個處理機結點上沒有存儲器層次結構,全部高速緩衝存儲器組成了全局地址空間。遠程高速緩存訪問則藉助於分佈高速緩存目錄進行。
是CC-NUMA體繫結構的競爭者,兩者擁有相同的目標,但實現方式不同。COMA節點不對記憶體部件進行分佈,也不通過互連設備使整個系統保持一致性。COMA節點沒有記憶體,只在每個Quad中配置大容量的高速緩存
CCNUMA
在CC-NUMA系統中,分散式記憶體相連接形成單一記憶體,記憶體之間沒有頁面複製或數據複製,也沒有軟體消息傳送。CC-NUMA只有一個記憶體映象,存儲部件利用銅纜和某些智能硬體進行物理連接。CacheCoherent是指不需要軟體來保持多個數據拷貝的一致性,也不需要軟體來實現操作系統與應用系統的數據傳輸。如同在SMP模式中一樣,單一操作系統和多個處理器完全在硬體級實現管理。

