
使用Percona Toolkit的pt-duplicate-key-checker工具時,偶爾會遇到"Error checking xxx: Wide character in print at /usr/bin/pt-duplicate-key-checker line 5248."這類錯誤。如 ...
使用Percona Toolkit的pt-duplicate-key-checker工具時,偶爾會遇到"Error checking xxx: Wide character in print at /usr/bin/pt-duplicate-key-checker line 5248."這類錯誤。如下例子所示
$ pt-duplicate-key-checker -hlocalhost -P7306 -uroot -pxxxxxx --socket /tmp/mysql.sock
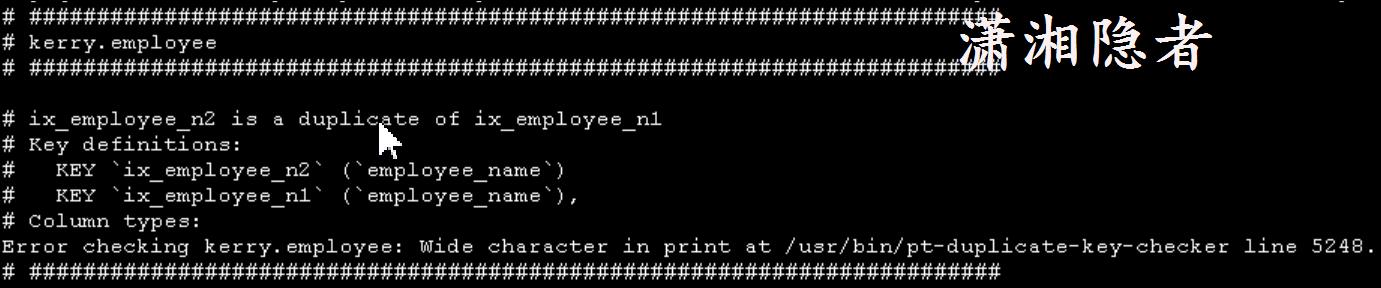
# ########################################################################
# kerry.employee
# ########################################################################
# ix_employee_n2 is a duplicate of ix_employee_n1
# Key definitions:
# KEY `ix_employee_n2` (`employee_name`)
# KEY `ix_employee_n1` (`employee_name`),
# Column types:
Error checking kerry.employee: Wide character in print at /usr/bin/pt-duplicate-key-checker line 5248.
.........................................................................
.........................................................................
遇到這個錯誤,是因為perl程式中處理中文等寬字元時,perl不能識別要處理的內容。所以你必須使用參數--charset指定字元集為utf8,才能避免這個錯誤。如下所示
$ pt-duplicate-key-checker -hlocalhost -P7306 -uroot --ask-pass --socket /tmp/mysql.sock --charset=utf8
Enter password:
# ########################################################################
# kerry.employee
# ########################################################################
# ix_employee_n2 is a duplicate of ix_employee_n1
# Key definitions:
# KEY `ix_employee_n2` (`employee_name`)
# KEY `ix_employee_n1` (`employee_name`),
# Column types:
# `employee_name` varchar(30) collate utf8mb4_general_ci default null comment '員工姓名'
# To remove this duplicate index, execute:
ALTER TABLE `kerry`.`employee` DROP INDEX `ix_employee_n2`;
小知識點:
在 Perl看來, 字元串只有兩種形式. 一種是octets, 即8位序列, 也就是我們通常說的位元組數組. 另一種utf8編碼的字元串, Perl管它叫string. 也就是說: Perl只熟悉兩種編碼: Ascii(octets)和utf8(string).Perl只能處理兩種編碼:ascii碼和utf-8。ascii碼是很少的,像中文、日文、韓文等字元要想能被perl處理,只能用utf-8編碼方式。
 掃描上面二維碼關註我
如果你真心覺得文章寫得不錯,而且對你有所幫助,那就不妨幫忙“推薦"一下,您的“推薦”和”打賞“將是我最大的寫作動力!
本文版權歸作者所有,歡迎轉載,但未經作者同意必須保留此段聲明,且在文章頁面明顯位置給出原文連接.
掃描上面二維碼關註我
如果你真心覺得文章寫得不錯,而且對你有所幫助,那就不妨幫忙“推薦"一下,您的“推薦”和”打賞“將是我最大的寫作動力!
本文版權歸作者所有,歡迎轉載,但未經作者同意必須保留此段聲明,且在文章頁面明顯位置給出原文連接.


