
在當今數據驅動的時代,企業對數據的實施性能力提出了前所未有的高要求。為了應對這一挑戰,構建高效、靈活且可擴展的實時湖倉成為數字化轉型的關鍵。本文將深入探討袋鼠雲數棧如何通過三大核心實踐——ChunJun 融合 Flink CDC、MySQL 一鍵入湖至 Paimon 的實踐,以及湖倉一體治理 Pai ...
在當今數據驅動的時代,企業對數據的實施性能力提出了前所未有的高要求。為了應對這一挑戰,構建高效、靈活且可擴展的實時湖倉成為數字化轉型的關鍵。本文將深入探討袋鼠雲數棧如何通過三大核心實踐——ChunJun 融合 Flink CDC、MySQL 一鍵入湖至 Paimon 的實踐,以及湖倉一體治理 Paimon 的實踐,重塑實時湖倉的架構與管理,為企業打造實時數據分析的新引擎。
ChunJun 融合 Flink CDC
Flink CDC(Change Data Capture)是由 Apache Flink 提供的一個流數據集成工具,它允許用戶通過 YAML 文件優雅地定義 ETL(Extract, Transform, Load)流程,並自動生成定製化的 Flink 運算元和提交 Flink 作業。
Flink CDC 的核心特性包括:端到端數據集成框架、易於構建作業的 API、多表支持、整庫同步精確一次語義、增量快照演算法等諸多特性。ChunJun 融合 Flink CDC 能夠更好支持數據的入湖入倉,帶來了多方面的變化:
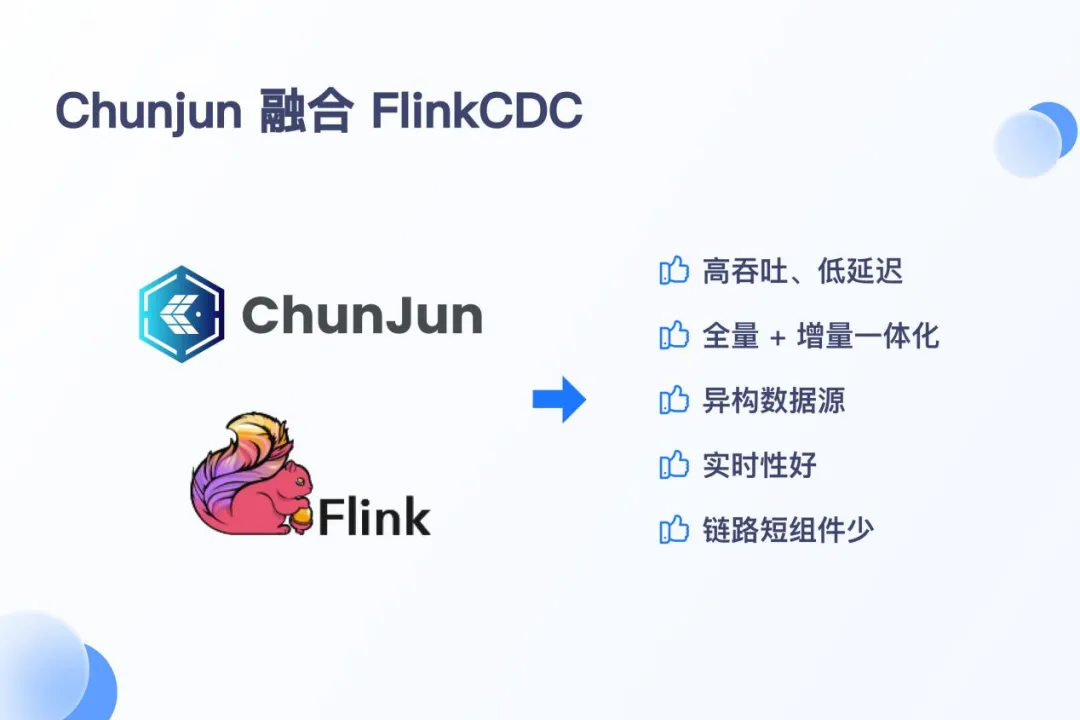
· 高吞吐、低延遲:Flink CDC 能夠以高吞吐量和低延遲的方式捕獲和傳輸資料庫的變更
· 全增量一體化:Flink CDC 支持全量數據和增量數據的同步,無需手動操作即可實現全量快照與增量日誌的自動銜接
· 支持異構數據源:Flink CDC 支持多種數據源,可以輕鬆實現異構數據源的集成,通過 Flink SQL 定義不同類型的 CDC 表,實現數據融合
· 實時性:支持近實時的數據同步,滿足對數據時效性要求高的場景
· 鏈路短組件少:Flink CDC 的架構設計讓整個數據捕獲和處理的鏈路變得更為簡潔,所涉及的組件數量相對有限,這不但降低了系統的繁雜程度,還削減了學習與運維的成本
MySQL 一鍵入湖 Paimon 實踐
ChunJun 融合 Flink CDC 增加了實時湖倉數據接入的方式,結合 FLink CDC 提供的 MySQL 數據到 Paimon 的數據同步能力,能夠高效地將 MySQL 表數據實時寫入 Paimon 中。在融合的同時,還支持歷史 Json 格式構建任務、臟數據、Mertic、表血緣、可視化配置等功能。
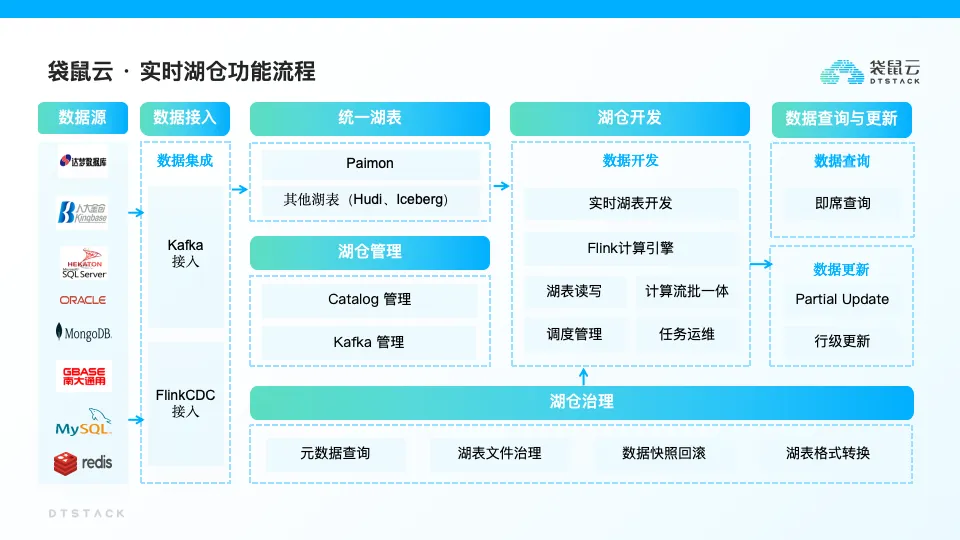
接下來通過內部實踐案例進行深入分析。
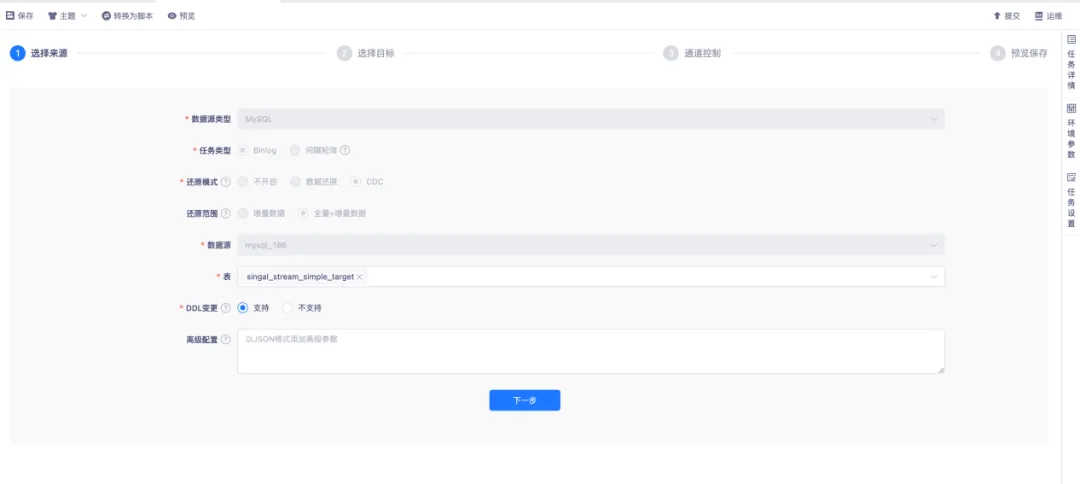
● 採集配置 Flink CDC 來源
實時採集配置 Flink CDC 來源為 MySQL 時,嚮導模式配置還原範圍採用全量+增量模式。
首先,對資料庫表進行全表快照讀取,生成數據的一致性快照,以同步來源表的歷史全量數據。在全量快照讀取完成後,會自動切換至增量模式,對資料庫的增量變化進行採集。表選擇的方式多樣,支持整庫同步、分庫分表同步、單表選擇同步,同時也支持通過正則的方式選擇表。
對於 DDL 變更,當上游產生 DDL 操作時,若選擇支持,下游會自動執行;若選擇不支持,則對上游產生的 DDL 做異常捕獲,此時任務會失敗。搭配告警功能,可及時告知出現異常的情況。出現異常後,需要手動執行 DDL 操作,任務才能恢復正常運行。
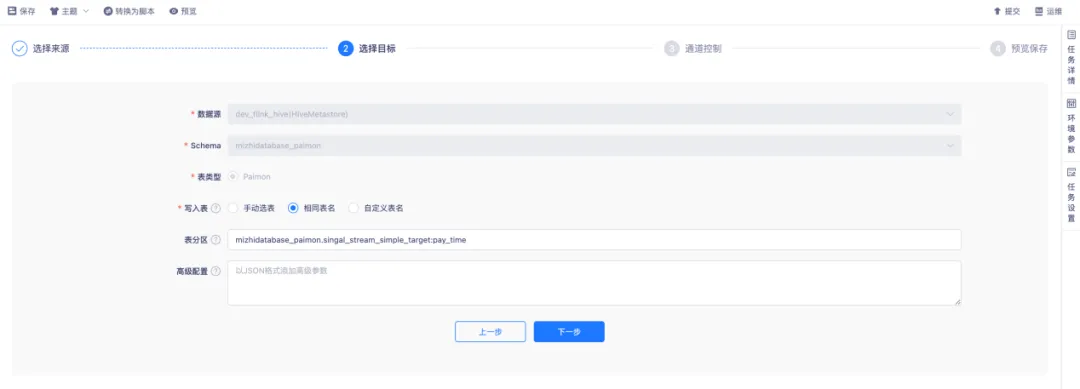
● 採集配置目標端
目標源通過 HiveMetastore 方式配置目標 Paimon 表。寫入表的方式具有一定靈活性,支持手動選擇表。對於上游存在多表寫入同一下游表的場景,有一定要求,必須保證上下游表結構保持一致。
同時,支持使用相同表名、自定義表名的方式。在同步前,會先創建寫入的目標表,如果已存在,則直接使用現成表。表分區方面,通過輸入固定的語法,將對應上游的主鍵表欄位作為目標 Piamon 表的分區欄位。
● 調度運行採集任務
實時採集任務在通過語法檢查後,提交至調度運維中運行。採集任務的指標包括 Mertic 輸入輸出指標展示、臟數據指標以及數據血緣解析等。
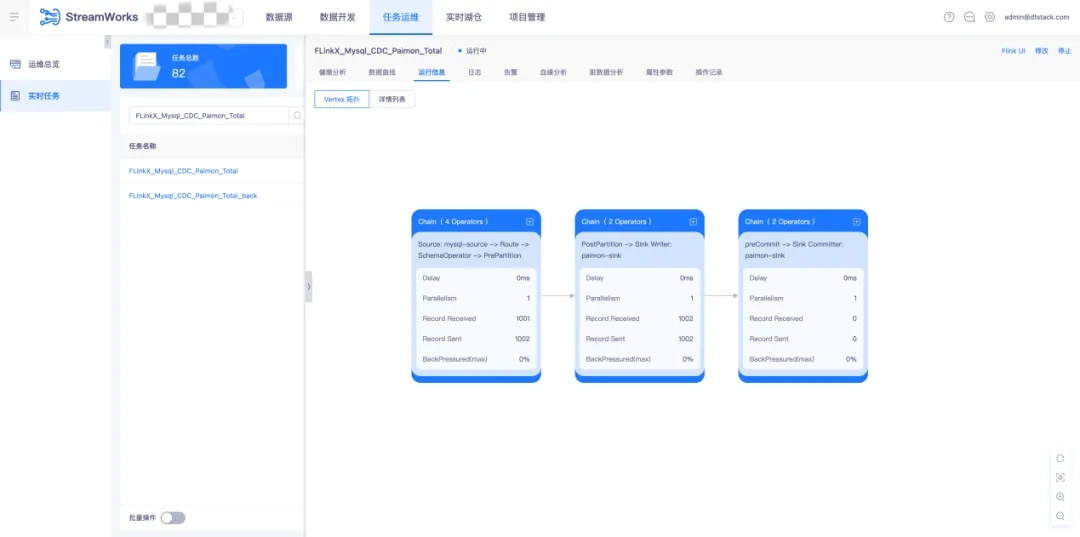
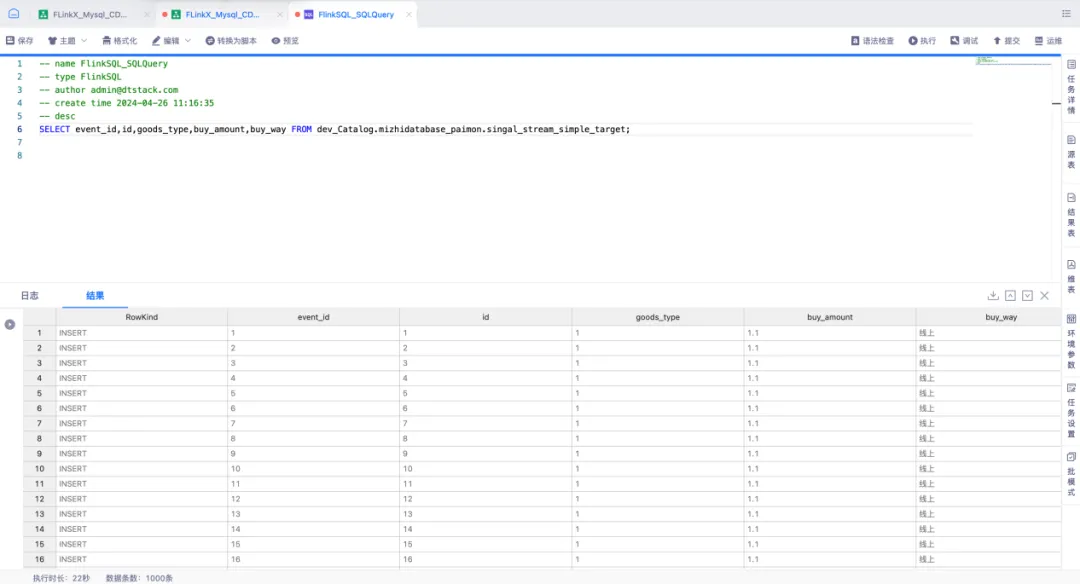
● 查詢入湖數據
通過實時平臺中 FlinkSQL 任務所提供的功能,對 Paimon 表進行查詢並插入數據。利用 FlinkSQL 的 SqlQuery 功能構建 Select 查詢語句,並採用流模式實時查詢 Paimon 表,以採集插入數據的情況。
湖倉一體治理 Paimon 實踐
在構建和維護數據湖與數據倉庫(湖倉)的一體化架構進程中,袋鼠雲憑藉湖倉治理機制,不斷推進實時數據湖的優化與完備。
然而,Paimon 在數據處理期間可能會引發數據碎片化的問題,像小文件的急劇增多、過時快照的持續累積以及孤兒文件的出現,這些狀況均有可能給數據湖表的讀寫效率帶來極為顯著的不良影響。
為有效應對這一挑戰,袋鼠雲於數棧湖倉一體中引入了文件治理機制,支持定期開展數據整理操作,例如合併小文件、清理過期的數據快照以及清除孤兒文件等。此類治理活動旨在增強數據湖的整體讀寫性能,保障數據流的高效運行和分析工作的順利開展。藉由這些數據治理手段,袋鼠雲能夠為湖倉架構的穩定性和性能提供穩固支撐,進而助力企業在大數據時代實現敏捷決策和深度洞察。
元數據管理
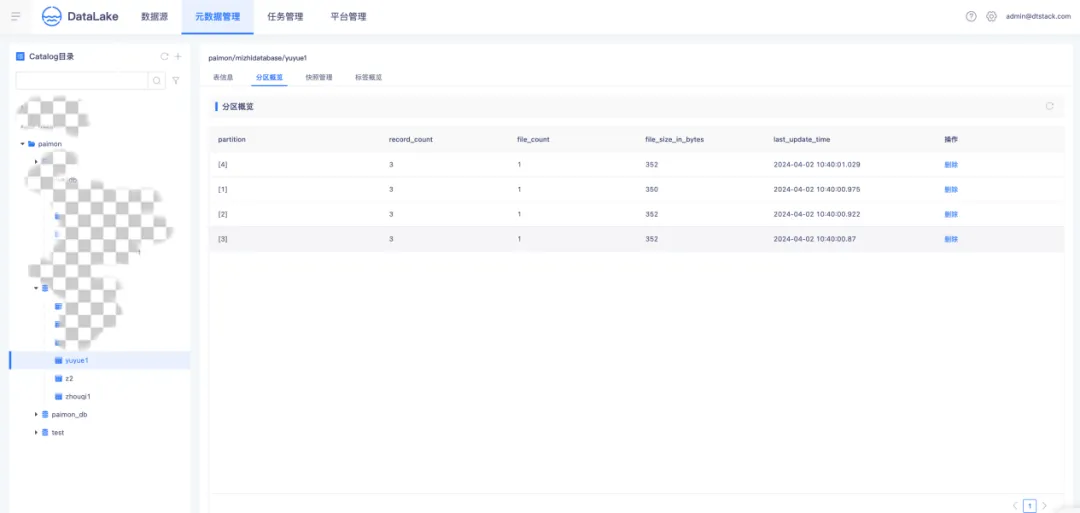
● Paimon 分區概覽
Paimon 運用了與 Apache Hive 相同的分區理念來對數據進行分離。分區屬於一種可選的形式,能夠依據日期、城市和部門等特定列的值,將表劃分成相關的部分。每個表能夠擁有一個或多個分區鍵,以識別某一特定的分區。分區概覽會展示分區的數據記錄、文件數量以及文件的大小,並且支持對分區的刪除操作。
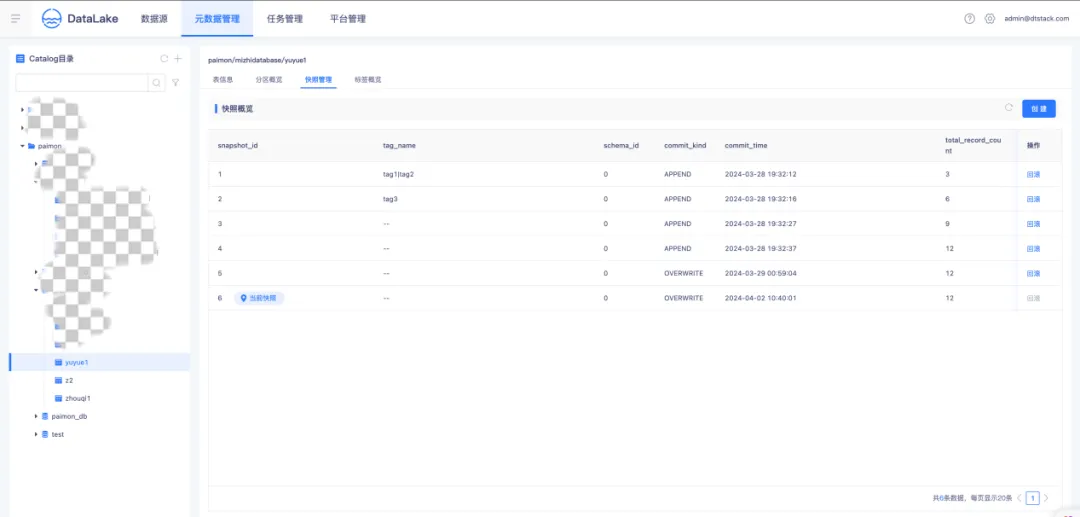
● Paimon 快照概覽
快照記錄了一個表在某一特定時間點的狀態。用戶能夠藉助最新的快照獲取一個表的最新數據。利用時間旅行,用戶還可以通過較早的快照訪問表的先前狀態。快照概覽展示了當前表的所有快照、最新 snapshot,支持手動創建標簽併在列表中展示引用關係,同時支持快照的刪除和回滾操作。
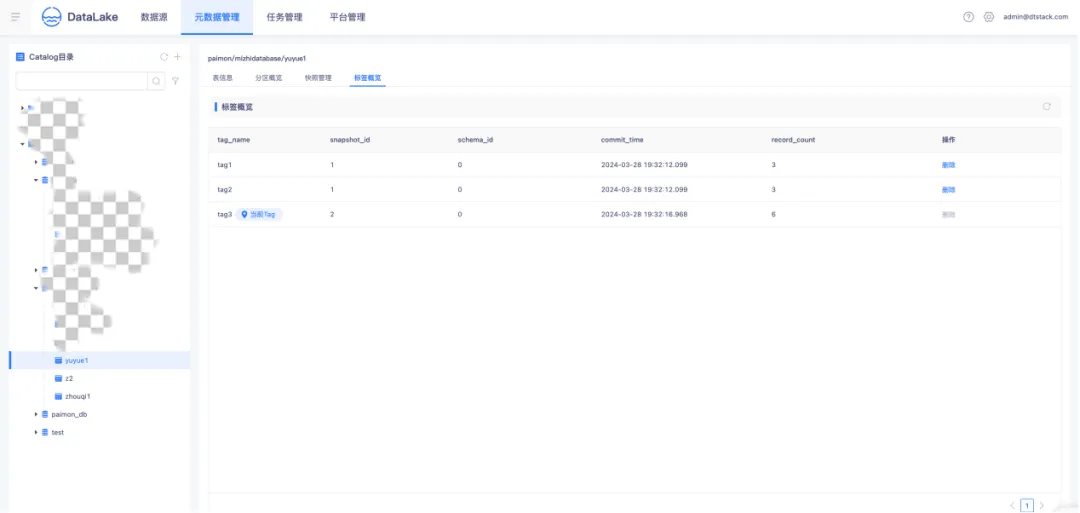
● Paimon 標簽概覽
標簽是對快照的引用,能夠基於某個特定快照創建。用戶能夠在特定的快照上添加標簽,如此一來,即便快照過期且被刪除,只要標簽仍然存在,就能夠通過標簽訪問到相應的數據。標簽概覽展示了表的所有歷史標簽版本、標簽與快照的引用關係,並且支持標簽的刪除操作。
湖表治理
● Paimon 小文件合併
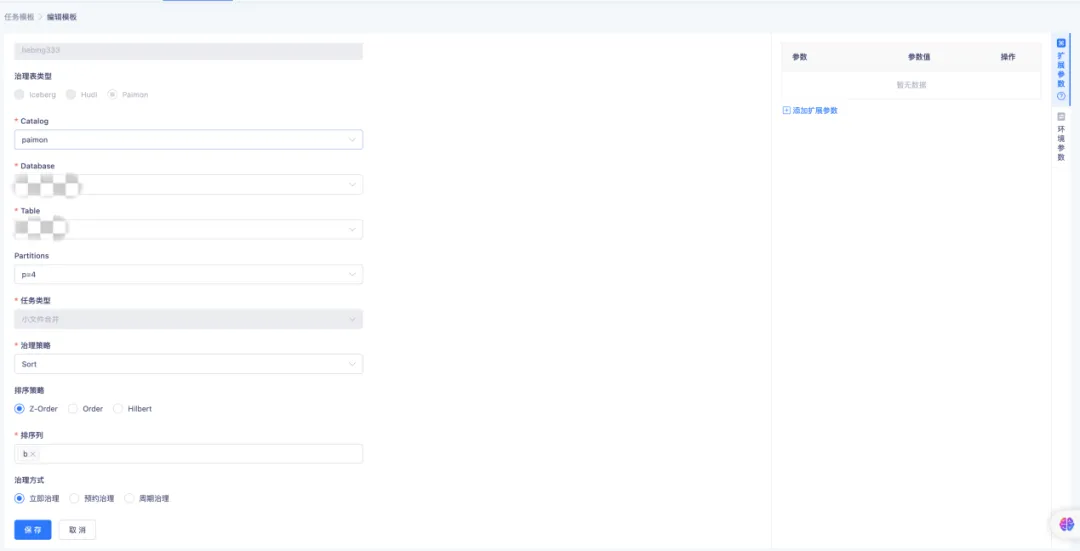
隨著時間的不斷推移,持續的寫入操作或許會產生大量的小文件,這將致使查詢性能降低,原因在於系統需要打開並讀取更多的文件。Compaction 能夠通過合併這些小文件,從而減少文件的總數。在數據文件治理中,支持對 Paimon Table、Database 的小文件進行治理。
Compaction Table 支持三種排序策略,通過配置不同的治理方式,支持周期性地對錶進行治理。Compaction Database 支持對單個或者多個庫執行文件的合併操作。
● Paimon 孤兒文件清理
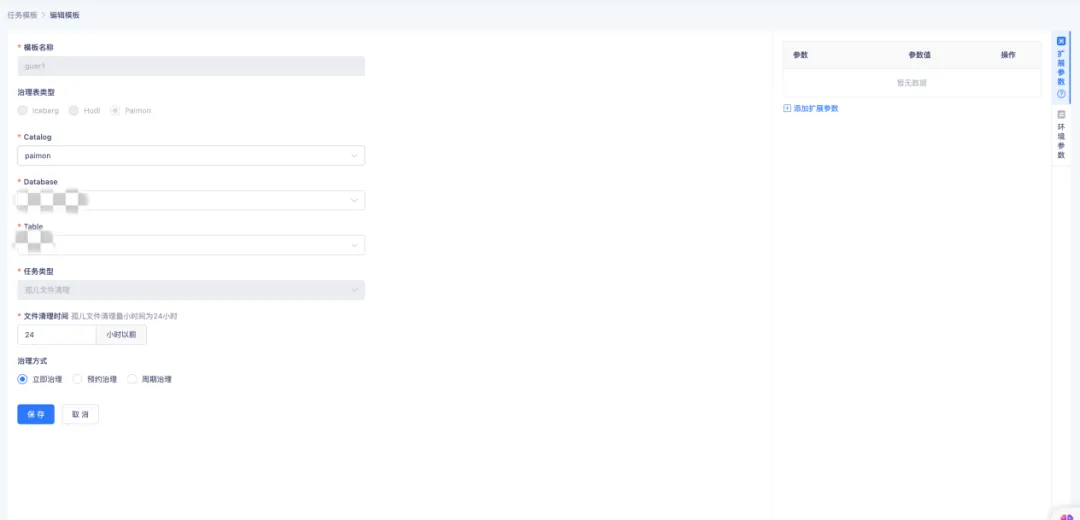
孤兒文件指的是那些不再被任何快照所引用的文件,其可能因異常的寫入操作、未完成的事務或者錯誤的刪除操作而出現。清理此類孤兒文件是維繫數據湖健康狀態的關鍵環節,畢竟它們會占據存儲空間。
袋鼠雲實時湖倉能夠通過配置表的孤兒文件清理策略,支持清理 24 小時以前的孤兒文件,同時還能夠通過配置周期治理,實現周期性地對孤兒文件進行治理。
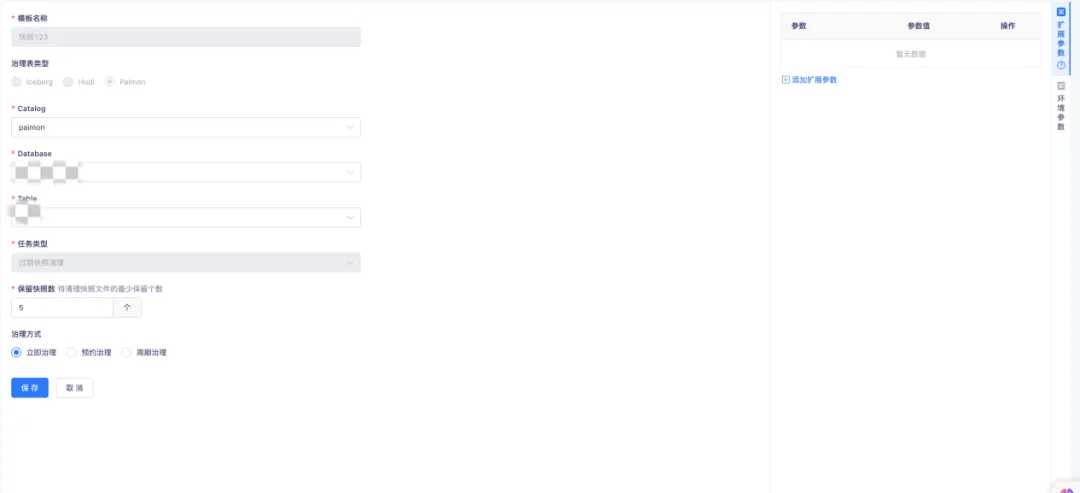
● Paimon 過期快照清理
Paimon Writer 在每次提交數據時,會生成一個或兩個快照。這些快照可能包含新增的數據文件,也可能將一些舊的數據文件標記為刪除。需要註意的是,即使數據文件被標記為刪除,它們也不會立即從物理存儲中真正刪除。通過配置過期快照清理和過期快照保留數量,可以對快照進行物理存儲的刪除操作。
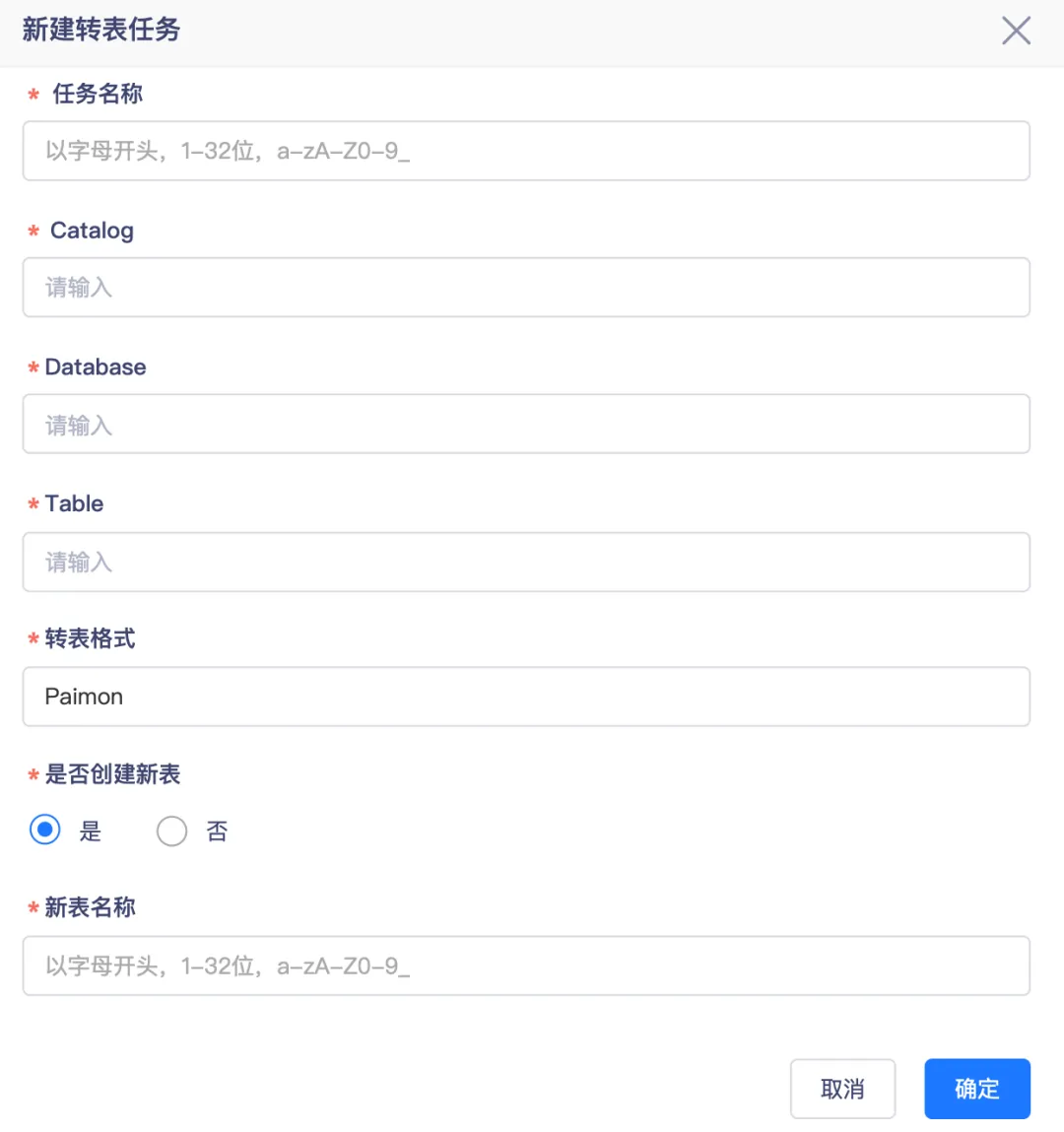
一鍵 Hive 表轉 Paimon 表
● 原地轉表
使用 Spark 內置的 migrate_table 進行表遷移時,會先創建一個臨時的 Paimon 表,然後將源表的文件直接移動到該臨時表中,接著對臨時 Paimon 表進行 rename 操作,使其表名與源表一致,這樣原來的 Hive 表就不再存在。
● New 新表
袋鼠雲實時湖倉自定義了一個全新的存儲過程 migrate_to_target_table ,該存儲過程會讀取源表的數據,創建目標 Target 表,並把源表的數據寫入到新創建的 Target 表中,在此過程中原有的 Hive 表依然得以保留。
《行業指標體系白皮書》下載地址:https://www.dtstack.com/resources/1057?src=szsm
《數棧產品白皮書》下載地址:https://www.dtstack.com/resources/1004?src=szsm
《數據治理行業實踐白皮書》下載地址:https://www.dtstack.com/resources/1001?src=szsm
想瞭解或咨詢更多有關大數據產品、行業解決方案、客戶案例的朋友,瀏覽袋鼠雲官網:https://www.dtstack.com/?src=szbky


