
一、什麼是架構 我想這個問題,十個人回答得有十一個答案,因為另外的那一個是大家妥協的結果,哈哈,我理解,架構就是骨架,如下圖所示: 人類的身體的支撐是主要由骨架來承擔的,然後是其上面的肌肉、神經、皮膚。架構對於軟體的重要性不亞於骨架對人類身體的重要性。 二、什麼是設計模式 這個問題我問過的面試者不下 ...
一、什麼是架構
我想這個問題,十個人回答得有十一個答案,因為另外的那一個是大家妥協的結果,哈哈,我理解,架構就是骨架,如下圖所示:
人類的身體的支撐是主要由骨架來承擔的,然後是其上面的肌肉、神經、皮膚。架構對於軟體的重要性不亞於骨架對人類身體的重要性。
二、什麼是設計模式
這個問題我問過的面試者不下數十次,回答五花八門,在我看來,模式就是經驗,涉及模式就是涉及經驗,有了這些經驗,我們就能在特定情況下使用特定的設計、組合設計。這樣可以大大節省我們的設計時間,提高工作效率。
作為一個老碼農,經理的系統架構設計也不算少,接下來,我會把工作中用到的一些架構方面的設計模式分享給大家,望大家少走彎路。總體而言,有八種,分別是:
1、單庫單應用模式:最簡單的,可能大家都見過
2、內容分發模式:目前用的比較多
3、查詢分類模式:對於大併發的查詢、業務。
4、微服務模式:適用於複雜的業務模式的拆解
5、多級緩存模式:可以把緩存玩的很好
6、分庫分表模式:解決單及資料庫瓶頸
7、彈性伸縮模式:解決波峰波谷業務的流量不均勻的方法之一
8、多機房模式:解決高可用、高性能的一種方法
三、單庫單應用模式
這是最簡單的一種設計模式,我們的大部分本科畢業設計、一些小的應用,基本上都是這種模式,這種模式的一般設計見下圖:
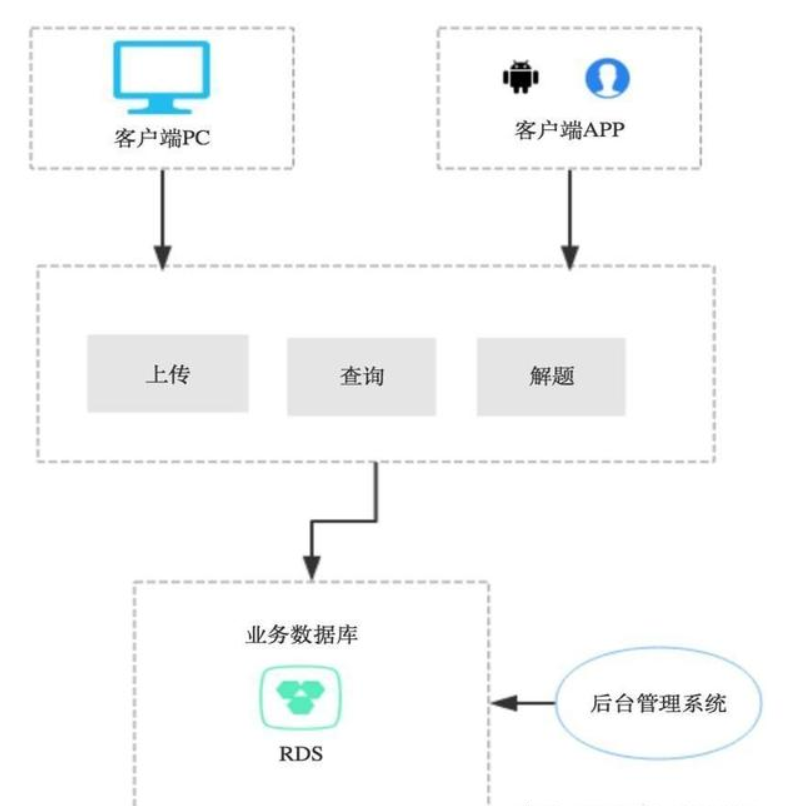
如上圖所示,這種模式一般只有一個資料庫,一個業務應用層,一個後臺管理系統,所有的業務都是用業務層完成的,所有的數據也都是存儲在一個資料庫中,好一點會由資料庫的同步,雖然簡單,但是也並不是一無是處。
優點:結構簡單、開發速度快、實現簡單,可用於產品的第一版等有原型驗證需求。
缺點:性能差、基本沒有高可用、擴展性查,不適合用於大規模部署、應用等生產環境。
四、內容分發模式
基本上所有的大型的網站都有或多或少的採用這一種設計模式,常見的應用場景是採用CDN技術把網頁、圖片、CSS、JS等這些靜態資源分發到離用戶最近的伺服器,這種模式的一般設計見下圖:

如上圖所示,這種模式較單庫單應用的模式多了一個CDN、一個雲存儲OSS(七牛、又拍等雷同)。一個經典的應用流程(以用戶上傳、查看圖片需求為例如下:)
1、上傳的時候,用戶選擇本地機器上的一個圖片進行上傳
2、程式會把這個圖片上傳到雲存儲OSS上,並返回該圖片的一個URL
3、程式把這個URL字元串存儲在業務資料庫中,上傳完成
4、查看的時候,程式從業務資料庫得到該圖片的URL
5、程式通過DNS查詢到這個URL的圖片伺服器
6、智能DNS會解析這個URL,得到於用戶最近的伺服器(或集群)的地址A
7、然後把伺服器A上的圖片返回給程式
8、程式顯示該圖片,查看完成
由上可知,這個模式的關鍵是智能DNS,他能夠解析出離用戶最近的伺服器,運行原理大致是:根據請求者的IP得到請求地點B,然後通過計算或者配置得到與B最近或通訊時間最短的伺服器C,然後把C的IP地址返回給請求者。這種模式的優缺點如下:
優點:資源下載快,無需過多的開發與配置,同時也減輕了後端伺服器對資源的存儲壓力,減少帶寬的使用。
缺點:目前來說OSS、CDN的加個還是稍微優點貴的,只適用於中小規模的應用,另外由於網路傳輸延遲、CDN的同步策略等,會有一些一致性、更新慢方面的問題。
五、查詢分離模式
這種模式主要解決單及資料庫壓力過大,從而導致業務緩慢甚至超時,查詢影響時間變長的問題,也包括需要大量資料庫伺服器計算資源的查詢請求,這個可以說是單庫應用模式的升級版本,也是技術架構迭代演進過程中的必經之路。
這種模式的一般設計如下圖:
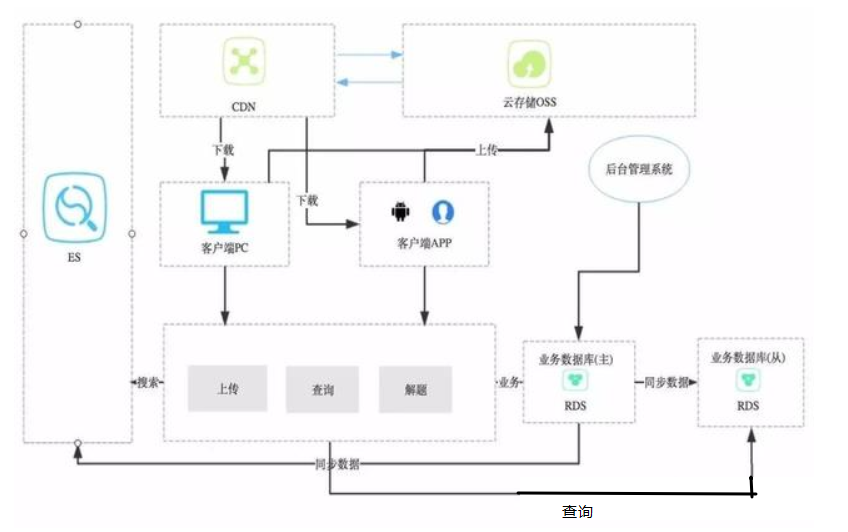
如上圖所示,這種模式較單庫但應用模式與內容分發模式多了幾個部分,一個是業務資料庫的主從分離,一個是引入ES,為什麼要這樣?都解決的哪些痛點,下麵具體結合業務需求場景進行敘述。
場景一:全文關鍵詞檢索
我想這個需求,絕大多數應用都會有,如果使用傳統的資料庫技術,大部分可能會使用like這種sql語句,高級一點的是先分詞,然後通分詞index相關的記錄。sql語句的性能問題與全表掃描機制導致了非常嚴重的性能問題,現在基本上很少見到。
ES較Solr配置簡單、使用方便,所以這裡選用了他。另外,ES支持橫向擴展,理論上沒有性能的瓶頸。同時,還支持各種插件、自定義分詞器等,可擴展性較強。在這裡,使用ES不僅可以替代資料庫完成全檢索功能,還可以實現諸如分頁、排序、分組、分面等功能。具體的,請同學們自行學習之,那怎麼使用呢?一個一般的流程是這樣的:
1、服務端把一條業務數據落庫
2、伺服器非同步把該條數據發送到ES
3、ES把該條記錄按照規則、配置放入自己的索引庫
4、客戶端查詢的時候,由服務端把這個請求發送到ES,得到數據後,根據需求拼裝、組合數據,返回給客戶端
實際中怎麼用,還請同學們根據實際情況做組合、取捨
場景二:大量的普通查詢
這個場景是指我們的業務中的大部分輔助性的查詢,如:取錢的時候先查詢一下餘額,根據用戶的ID查詢用戶的記錄,取得該用戶最新的一條取錢記錄等,我們肯定是要天天用到的,而且用的還非常多。同時呢,我們的寫入請求也是非常多的,導致大量的寫入、查詢操作壓向同一資料庫,然後,資料庫掛了,系統掛了,領導生氣了,被開除了,還不起房貸了,露宿街頭了,老婆跟別人跑了……
不敢想,所以要求我們必須分散資料庫的壓力,一個業界較成熟的方案就是資料庫的讀寫分離,寫的時候入主庫,讀的時候讀分庫。這樣就把壓力分散到不同的資料庫了,如果一個讀庫性能不行,扛不住的話,可以一主多從,橫向擴展,可謂是一劑良藥啊!那麼怎麼使用呢?一個一般的流程是這樣的:
1、服務端把一條數據落庫
2、資料庫同步或非同步或半同步把這條數據複製到從庫
3、服務端讀取數據的時候直接去從庫讀相應的數據
比較簡單吧,一些聰明的、愛思考的、上進的同學可能發現問題了,也包括上面介紹的場景一,就是延遲問題,如:數據還沒到從庫,我就馬上讀,那麼是讀不到的,會發生問題的。對於這個問題,各家公司解決的思路也是不一樣的,方法不盡相同,一個普遍的解決方案是:讀不到就讀主庫,當然這麼說也是有前提條件的,但具體的方案就不在這裡一一展開了,我可能會在接下來的分享中詳解各種方案。
另外,關於資料庫複製模式,還請同學們自行學習,太多了,這裡說不清,該總結一下這種模式的優缺點了,如下:
優點:減少資料庫的壓力,理論上提供無限高的讀性能,簡介提高業務(寫)的性能,專用的查詢、索引、全文(分詞)解決方案。
缺點:數據延遲,數據一致性的保證。
六、微服務模式
上面的模式看似不錯,解決了性能問題,我可以不用魯肅街頭了、老婆還是我的,哈哈,但是軟體系統天生的複雜性決定了,出了性能,還有其他諸如高可用、健壯性等大量問題等待我們去解決,在加上各個部門的撕逼、扯皮,更讓我們碼農雪上加霜,所以,繼續吧……
微服務模式可以說是最近的熱點,花花綠綠、大大小小、國內國外的公司都在鼓吹,實踐這個模式,可是大部分都沒有弄清為什麼要這麼做,也並不知道這麼做有什麼好處、壞處,在這裡,我將以我自己的親身實踐說一下我對這個模式的看法,不喜勿噴,隨著業務與人員的增加,遇到的問題如下:
1、單及資料庫寫請求量大量增加,導致資料庫壓力變大
2、資料庫一旦掛了,那麼整個業務都掛了
3、業務代碼越來越多,都在一個GIT里,越來越難以維護
4、代碼腐化嚴重,臭味越來越濃
5、上線越來越頻繁,經常是一個小功能的修改,就要整個大項目重新編譯
6、部門越來越多,該哪個部門改動大項目中的哪個東西,撕逼的厲害
7、其他一些外圍系統直接連資料庫,導致一旦資料庫結構發生變化,所有的相關係統都要通知,甚至對修改不敏感的系統也要通知
8、每個應用伺服器需要開通所有許可權、網路、FTP、各種各樣的,因為每個伺服器部署的應用都是一樣的。
9、作為架構師,我已經屎去了對這個系統的把控……
為瞭解決上述問題,我司使用了微服務模式,這種模式的一般設計如下圖:
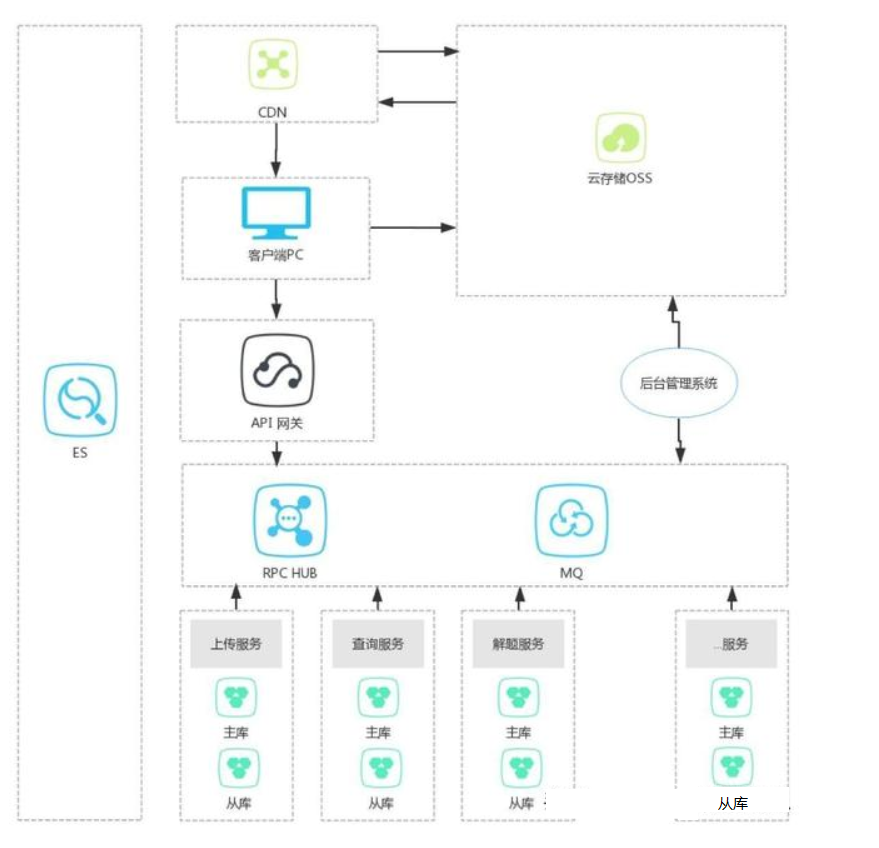
如上圖所示,我把業務分塊,做了垂直切分,切成一個個獨立的系統,每個系統各子衍化,有自己的庫、緩存、ES等輔助系統,系統之間的實時交互通過RPC,非同步交互通過MQ,通過這種組合,共同完成整個系統功能。
那麼,這麼做是否真的能解決上述問題了呢?不玩虛的,一個一個來說。
對於問題一,由於拆分成多個子系統,系統的壓力被分散了,而各個子系統都有自己的資料庫實例,所以資料庫的壓力變小。
對於問題二,一個子系統A的資料庫掛了,只是影響到系統A和使用系統A的那些功能,不會所有的功能不可用,從而解決一個資料庫掛了,導致所有的功能都不可用的情況。
對於問題三、四,也因為拆分得到瞭解決,各個子系統都有自己獨立的GIT代碼庫,不會相互影響。通用的模塊可通過庫、服務、平臺的形式解決。
對於問題五,子系統A發生改變,需要上線,那麼我們只需要編譯A,然後上線就可以了,不需要其他系統做通向的事情。
對於問題六,順應了康威定律,我部門該乾什麼事,輸出什麼,也通過服務的形式暴露出來,我部門只管把我部的職責、軟體功能做好就可以。
對於問題七,所有需要我部數據的需求,都通過介面的形式發不出去,客戶通過介面獲取數據,從而屏蔽了底層資料庫結構,甚至數據來源,我部只需保證我部的介面契約沒有發生變化即可,新的需求增加新的介面,不會影響老的介面。
對於問題八,不同的子系統需要不同的許可權,這個問題也優雅的解決了。
對於問題九,暫時控制住複雜性,我只需要控制好大方面,定義好系統邊界、介面、大的流程,然後再分而治之、逐個擊破、合縱連橫。
目前來說,所有問題得到解決!bingo!
但是,還有許多其他的副作用會隨之產生,如RPC、MQ的超高穩定性、超高性能,網路延遲,數據一致性等問題,這個就不展開來講了,太多了,一本書都講不完。
另外,對於這個模式來說,最難把握的是度,切記不要切分過細,我見過一個功能一個子系統,上百個方法分成上百個子系統的,真的是太過度了。實踐中,一個比較可行的方法是:能不分就不分,除非有非常必要的理由!
優點:相對高性能,可擴展性強,高可用,適用於中等以上規模公司架構。
缺點:複雜、度不好把握。指不僅需要一個能再高層把控大方向、大流程、總體技術的人,還需要能夠針對各個子系統有針對性的開發。把握不好度或者濫用的話,這個模式適得其反!
七、多級緩存模式
這個模式可以說是應對超高查詢壓力的一種普遍採用的策略,基本的思想就是再所有鏈路的地方,能加緩存的就加緩存,如下圖所示:
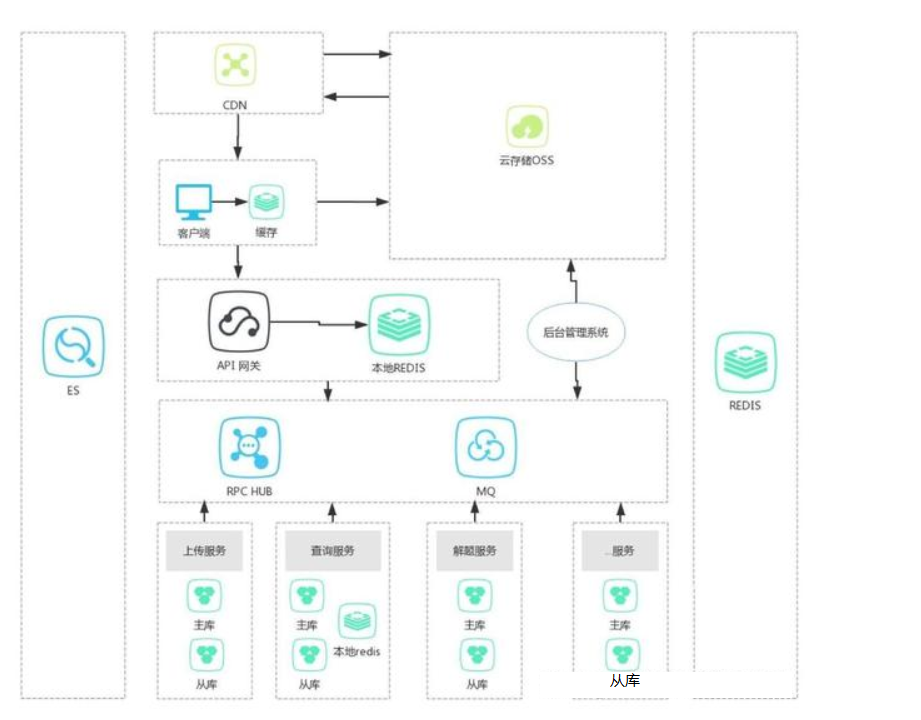
如上圖所示,一般在三個地方加入緩存,一個是客戶端處,一個是API網關處,一個是具體的後端業務處,下麵分別介紹:
客戶端處緩存:這個地方加緩存可以說是效果最好的一個——無延遲。因為不用經過長長的網路鏈條去後端業務處獲取數據,從而導致載入時間過長,客戶流失等損失,雖然有CDN的支持,但是從客戶端到CDN還是有網路延遲的,雖然不大,具體的技術依據不同的客戶端而定,對於WEB來講,有瀏覽器本地緩存、Cookie、Storage、緩存策略等技術;對於APP來講,有本地資料庫,本地文件,本地記憶體,進程內緩存支持,以上提到的各種技術有興趣的同學可以繼續展開學習,如果客戶端緩存沒有命中,那麼會去後端業務拿數據,一般來講,就會有個API網關,在這裡加緩存也是非常重要的。
後端業務處理:這個我就不用多說了,大家應該差不多都知道,什麼Redis、Memcache、Jvm等等,不贅述了。
實踐中,要結合具體的實際情況,綜合利用各級緩存技術,使得各種請求最大程度的在到達後端業務之前就被解決掉,從而減少後端伺服器壓力、減少占用帶寬、增強用戶體驗。至於是否只有這三個地方加緩存,我覺得要活學活用,心法比劍法重要!總結一下這個模式的優缺點:
優點:抗住大量讀請求,減少後端壓力。
缺點:數據一致性問題較為突出,容易發生雪崩,即:如果客戶端緩存失效、API網關緩存失效,那麼所有的大量請求瞬間壓向後端業務系統,後果可想而知。
八、分庫分表模式
這種模式主要解決單表寫入、讀取 、存儲壓力過大,從而導致業務緩慢甚至超時,交易失敗,容量不夠的問題。一般有水平切分和垂直切分兩種,這裡主要介紹水平切分。這個模式也是技術架構迭代演進的畢竟之路。
這種模式的一般設計見下圖:
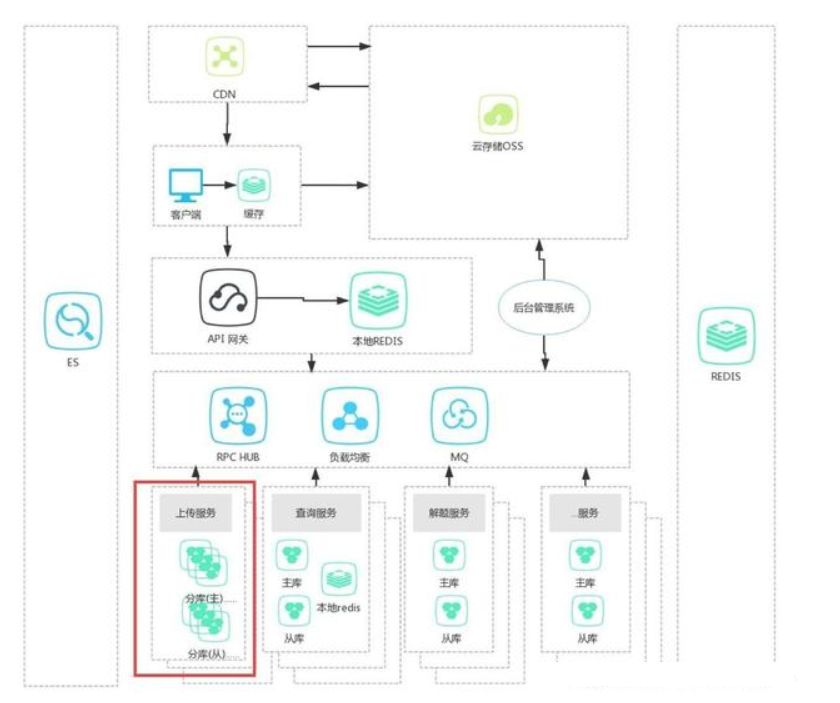
如上圖所示紅色部分,把一張表分到了幾個不同的庫中,從而分擔壓力。是不是很籠統?哈哈,那我們接下來就詳細的講解一下,首先澄清幾個概念,如下:
主機:硬體,指一臺物理機,或虛擬機,有自己的CPU,記憶體,硬碟等。
實例:資料庫實例,如一個MySql服務進程,一個主機可以有多個實例,不同的實例有不同的進程,監聽不同的埠。
庫:指表的集合,如學校庫,可能包含教師表、學生表、食堂表等等,這些表在一個庫中。一個實例中可以有多個庫,庫與庫之間用庫名來區分。
表:庫中的表,不必多說,不懂的就不用往下看了,不解釋。
那麼怎麼把單表分散呢?到底怎麼個分發呢?分發到哪裡呢?以下是幾個工作中的實踐,分享一下:
主機:這是最主要的也是最重要的點,本質上分庫分表是因為計算與存儲資源不夠導致的,而這種資源主要由物理機,主機提供的,畢竟沒有可用的計算資源,怎麼分效果都不是太好。
實例:實例控制著連接數,同時受OS限制,CPU、記憶體、硬碟、網路IO也會受間接影響。會出現熱實例的現象,即:有些實例特別忙,有些實例非常的空閑。一個典型的現象是:由於單表反應慢,導致連接池被拉滿,所以其他的業務都受影響了。這時候,把表分到不同的實例是有一些效果的。
庫:一般是由於單庫中最大單表數量的限制,才採取分庫。
表:單表壓力過大,索引量大,容量大,單表的鎖。據以上,把單表水平切分成不同的表。
大型應用中,都是一臺主機上只有一個實例,一個實例中只有一個庫,庫==實例==主機,所以才有了分庫分表這個簡稱。
既然知道了這個基本理論,那麼具體是怎麼做的呢?邏輯是怎麼跑的呢?接下來以一個例子來講解一下。
這個需求很簡單,用戶表(user),單表數據量1億,查詢、插入、存儲都出現了問題,怎麼辦呢?
首先,分析問題,這個明顯是由於數據量太大了而導致的問題。
其次,設計方案,可以分為10個庫,這樣每個庫的數據量就降到了1KW,單表1KW數據量還是有些大,而且不利於以後量的增長,所以每個庫再分100個表,這樣每個單表數據量就為10W了,對於查詢、索引更新、單表文件大小、打開速度,都有一些溢出。接下來,給IT部門打電話,要10太物理機,擴展資料庫……
最後,邏輯實現,這裡應該是最有學問的地方。首先是寫入數據,需要知道寫道哪個分庫分表中,讀也是一樣的,所以,需要有個請求路由曾,負責把請求分發、轉換到不同的庫表中,一般有路由規則的概念。
怎麼樣,簡單吧?哈哈。說說這個模式的問題,主要是帶來了事務上的問題,因為分庫分表,事務完成不了,而分散式事務又太本重,所以這裡需要有一定的策略,保證在這種情況下事務能夠完成。採取的策略如:最終一致性、複製、特殊設計等。再有就是業務代碼的改造,一些關聯查詢要改造,一些單表orderBy的問題需要特殊處理,也包括groupBy語句,如何解決這些副作用不是一句兩句能夠說清楚的,以後有時間,我單獨講講這些。
該總結一下這種模式的優缺點了,如下:
優點:減少資料庫單表的壓力。
缺點:事務保證困難、業務邏輯需要做大量改造。
九、彈性伸縮模式
這種模式主要解決突發流量的到來,導致無法橫向擴展或者橫向擴展太慢,進而影響業務,全站崩潰的問題。這個模式是一種相對來說比較高級的技術,也是各大公司目前都在研究、試用的技術。截至今日,有這種思想的架構師已經是很不錯的了,能夠拿到較高薪資,更別提那些已經實踐過的,甚至實現了底層系統的那些,所以,你懂得……
這種模式的一般設計如下圖:
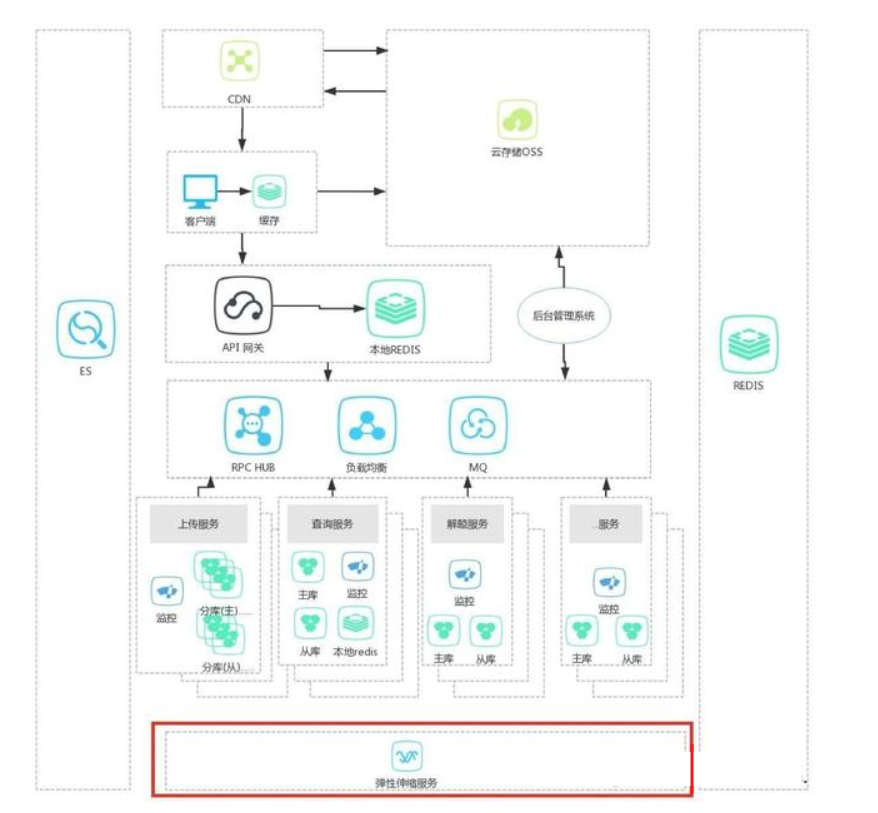
如上圖所示,多了一個彈性伸縮服務,用來動態的增加、減少實例。原理上非常簡單,但是這個模式到底解決了什麼問題呢?先說說由來和意義。
每年的雙11、618或者一些大促銷到來之前,我們都會為大流量的到來做以下幾個方面的工作:提前準備10倍甚至更多的機器,即便用不上也要放在那裡備著,以防萬一,這樣浪費了大量的資源。每台機器配置、調試、引流,以便讓所有的機器都可用,這樣浪費了大量的人力、物力,更容易出錯。如果機器準備不充分,那麼還要加班加點的重覆上面的工作,這樣特別容易出錯,引來領導的不滿,沒時間回家陪老婆,然後你老婆就……哈哈
在雙十一之後,我們還要人工做縮容,非常的辛苦。一般一年中會有多次促銷,那麼我們就會一直這樣,實在是煩!
最嚴重的,突然間的大流量爆發,會讓我們猝不及防,半夜起來擴容是正常不過的事情,為此,我們偷懶起來,要更多的機器備著,也就出現了大量CPU利用率為1%的機器。
相信我,如果你是老闆一定很震驚吧!
哈哈,那麼如何改變這種情況呢?請接著看
為此,首先把所有的計算資源整合成資源池的概念,然後通過一些策略、監控、服務,動態的從資源池中獲取資源,用完後再放回到池子中,供其他系統試用。具體實現上比較成熟的兩種資源池方案是VM、docker,每個都有著自己強大的生態。監控點有CPU、記憶體、硬碟、網路IO、服務質量等,根據這些,再配合一些預留、擴張、收縮策略,就可以簡單的實現自動收縮。怎麼樣?是不是很神奇?深入的內容我會在後面的文章中詳細的講述,該總結以下這種模式的優缺點了。如下:
優點:彈性、隨需計算,充分優化企業計算資源。
缺點:應用要從架構層做到可橫向擴展化改造、依賴的底層配套比較多,對技術水平、實力、應用規模要求比較高。
十、多機房模式
這種模式主要解決不同地區高性能、高可用的問題
隨著應用用戶的不斷增加,用戶群體分佈在全球各地,如果把伺服器都部署在一個地方,一個機房,比如北京,那麼美國的用戶使用應用的時候會特別慢,因為每個請求都需要通過海底光纜走上那麼一秒鐘左右,這樣對用戶體檢及其不好,怎麼辦?使用多機房部署。這種模式一般設計如下圖所示:
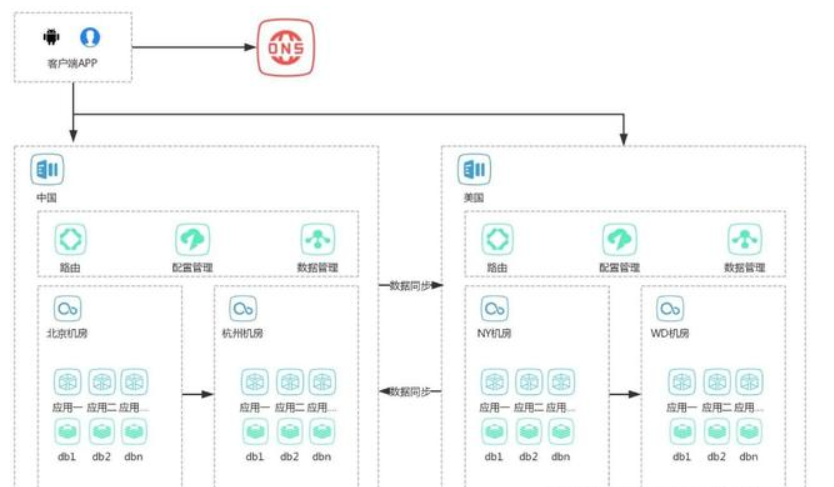
如上圖所示,一個典型的用戶請求流程如下:
用戶請求一個連接A
通過DNS智能解析到離用戶最近的機房B
使用B機房服務連接A
是不是覺得很簡單,沒啥?其實這裡面的問題沒有錶面這麼簡單,下麵一一道來,
首先是數據同步問題,在中國產生的數據要同步到美國,美國的也一樣,數據同步就會涉及數據版本、一致性、更新丟棄、刪除等問題。
其次是一地多機房的請求路由問題,典型的是如上圖,中國的北京機房和杭州機房,如果北京機房掛了,那麼要能夠通過路由把所有發往北京機房的請求轉發到杭州機房,異地也存在這個問題。
所以,多機房模式,也就是異地多活並不是那麼的簡單,這裡只是起了個頭,具體的有哪些坑,會在後面的文章中介紹。
該總結以下這種模式的優缺點了,如下:
優點:高可用、高性能、異地多活。
缺點:數據同步、數據一致性、請求路由。
至此,整個關於八種架構設計模式及其優缺點的概述就介紹完了,最後,我想說的是,沒有銀彈、靈活運用,共勉!


