
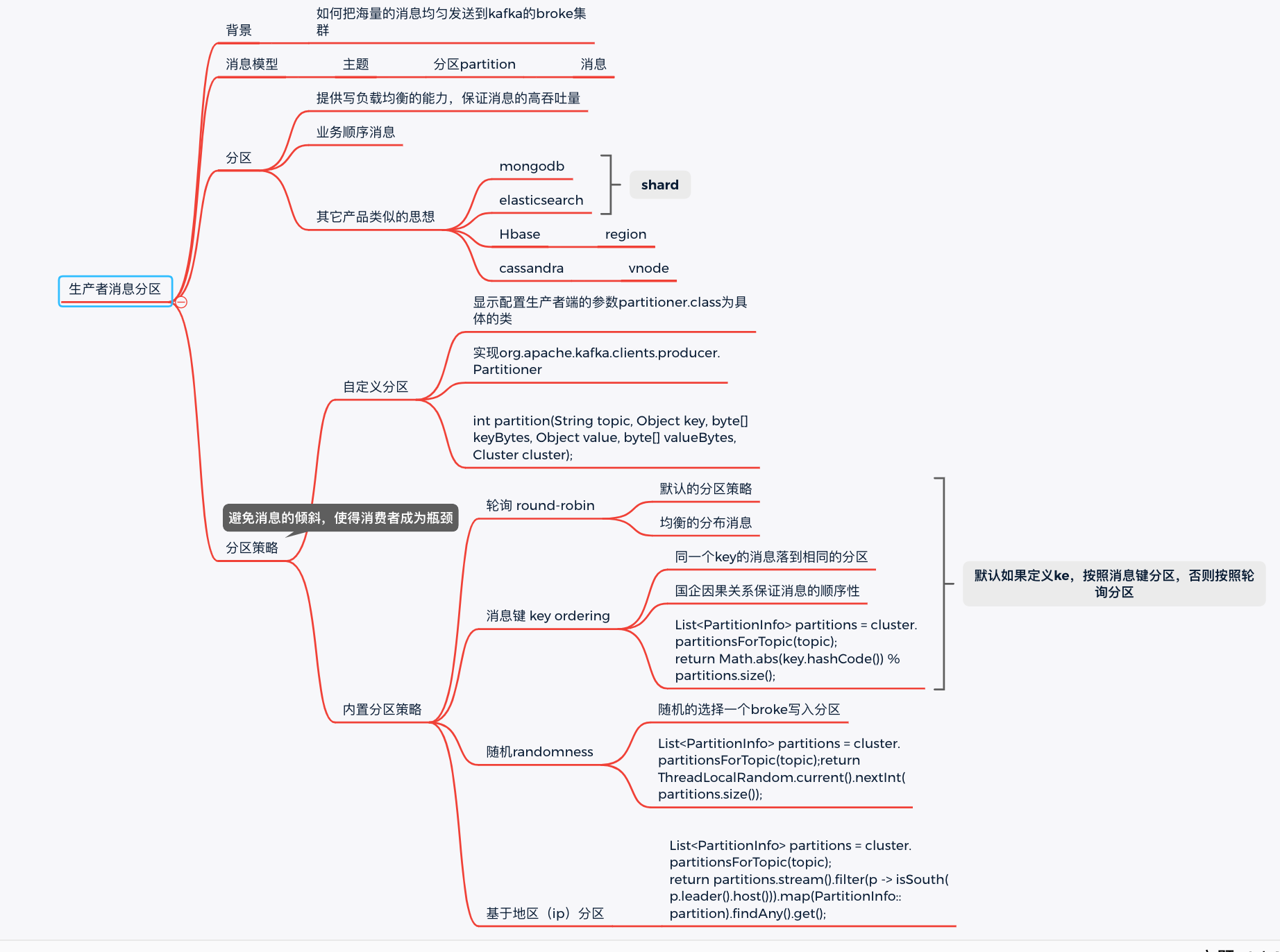
背景 kafka如何支撐海量消息的集中寫入? 答案就是消息分區。 核心思想是:負載均衡,採用合適的分區策略把消息寫到不同的broker上的分區中; 其它的產品中有類似的思想。 比如monogodb, es 裡面叫做 shard; hbase叫region, cassdra叫vnode; 消息的三層結 ...
背景
kafka如何支撐海量消息的集中寫入?
答案就是消息分區。
核心思想是:負載均衡,採用合適的分區策略把消息寫到不同的broker上的分區中;
其它的產品中有類似的思想。
比如monogodb, es 裡面叫做 shard; hbase叫region, cassdra叫vnode;
消息的三層結構
如下圖:
即 topic -> partition -> message ;
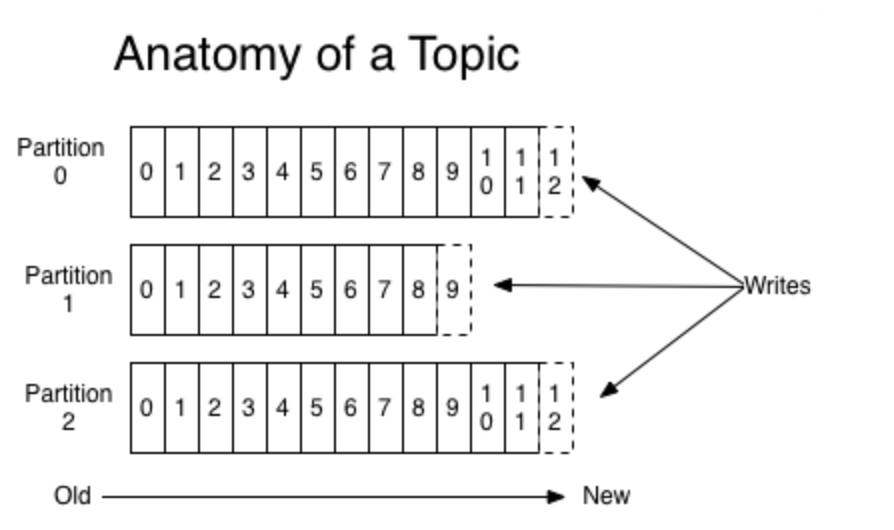
topic是邏輯上的消息容器;
partition實際承載消息,分佈在不同的kafka的broke上;
message即具體的消息。
分區策略
round-robin輪詢
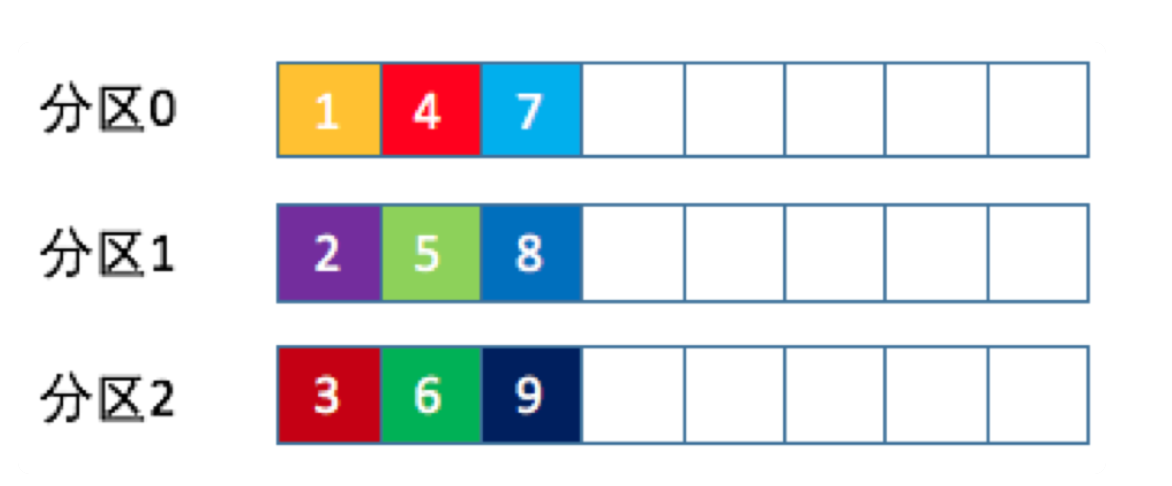
消息按照分區挨個的寫。
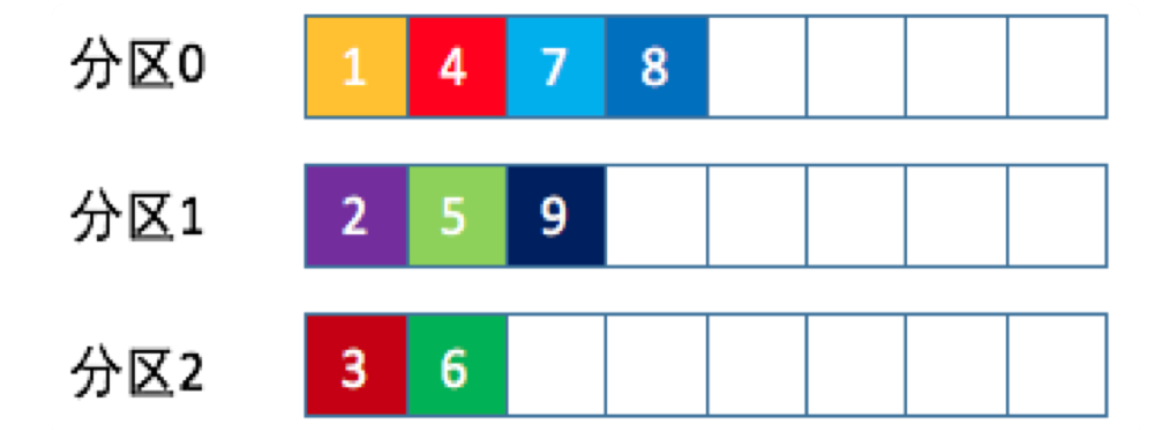
randomness隨機分區
隨機的找一個分區寫入,代碼如下:
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return ThreadLocalRandom.current().nextInt(partitions.size());
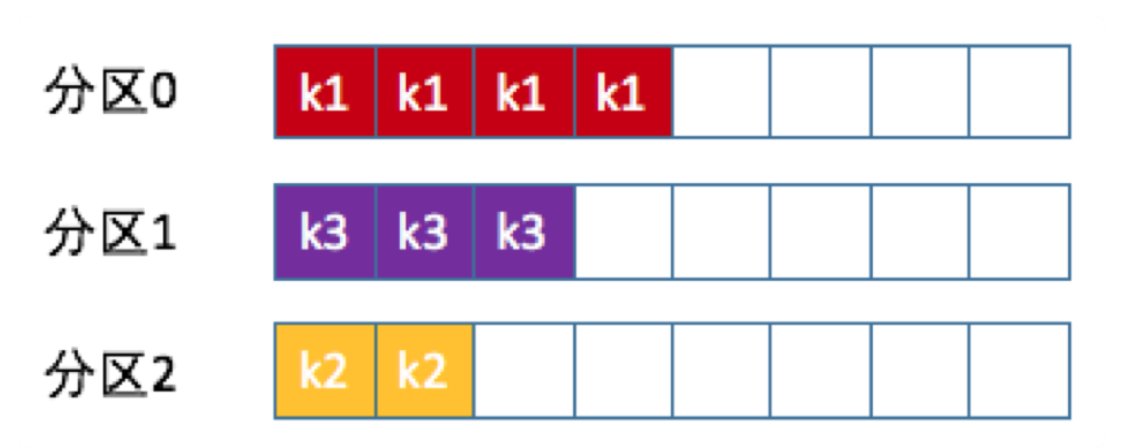
key
相同的key的消息寫到固定的分區中
自定義分區
必須完成兩步:
1,自定義分區實現類,需要實現org.apache.kafka.clients.producer.Partitioner介面。
主要是實現下麵的方法:
int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster);
比如按照區域分區。
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return partitions.stream().filter(p -> isSouth(p.leader().host()))
.map(PartitionInfo::partition).findAny().get();
2,顯示配置生產者端的參數partitioner.class為具體的類
系統預設:如果消息有key,按照key分區策略,否則按照輪詢策略。
小結
kafka的分區實現消息的高吞吐量的主要依托,主要是實現了寫的負載均衡。可以指定各種負載均衡演算法。
負載均衡演算法非常重要,需要極力避免消息分區不均的情況,可能給消費者帶來性能瓶頸。
小結如下:
原創不易,點贊關註支持一下吧!轉載請註明出處,讓我們互通有無,共同進步,歡迎溝通交流。
我會持續分享Java軟體編程知識和程式員發展職業之路,歡迎關註,我整理了這些年編程學習的各種資源,關註公眾號‘李福春持續輸出’,發送'學習資料'分享給你!



