
一、總體設計 初來公司時,公司還沒有大數據,我是作為大數據架構師招入的,結合公司的線上和線下業務,制定瞭如下的大數據架構路線圖。 二、大數據任務開發和調度平臺架構設計 在設計完總體架構後,並且搭建完hadoop/yarn的大數據底層計算平臺後, 按照總體架構設計思路, 首先需要構建的就是大數據開發平 ...
一、總體設計
初來公司時,公司還沒有大數據,我是作為大數據架構師招入的,結合公司的線上和線下業務,制定瞭如下的大數據架構路線圖。
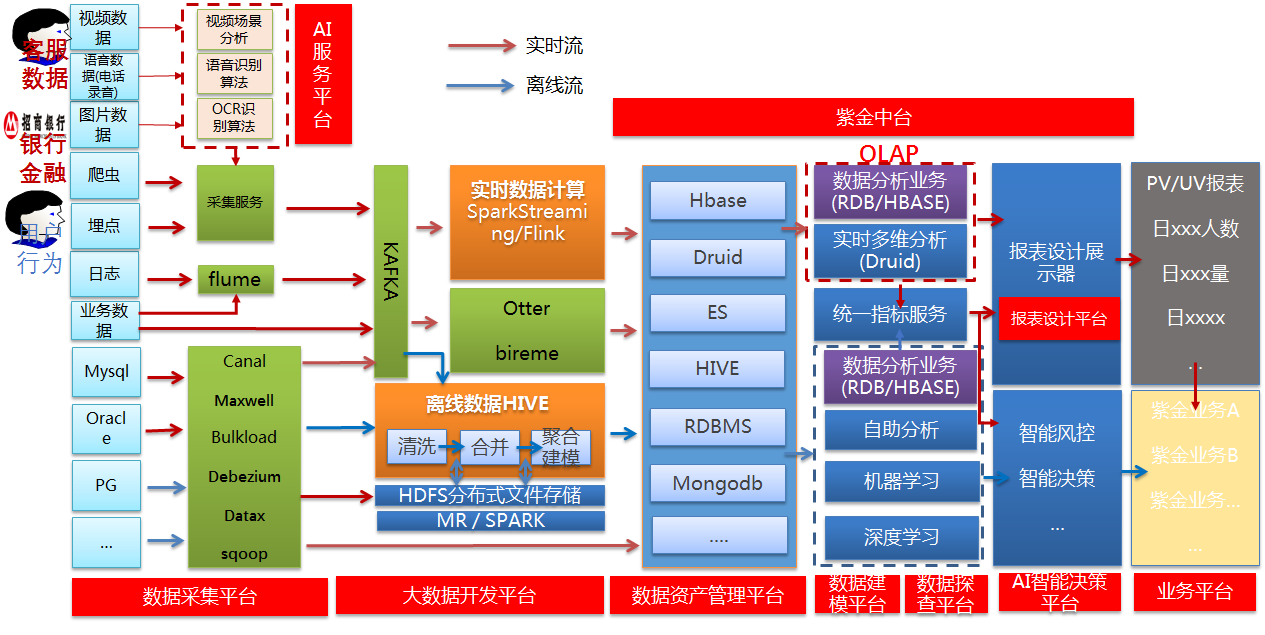
二、大數據任務開發和調度平臺架構設計
在設計完總體架構後,並且搭建完hadoop/yarn的大數據底層計算平臺後, 按照總體架構設計思路, 首先需要構建的就是大數據開發平臺。這也是一個非常核心的平臺,也是最基礎最重要的一個環節。
一開始設計的架構圖如下所示。
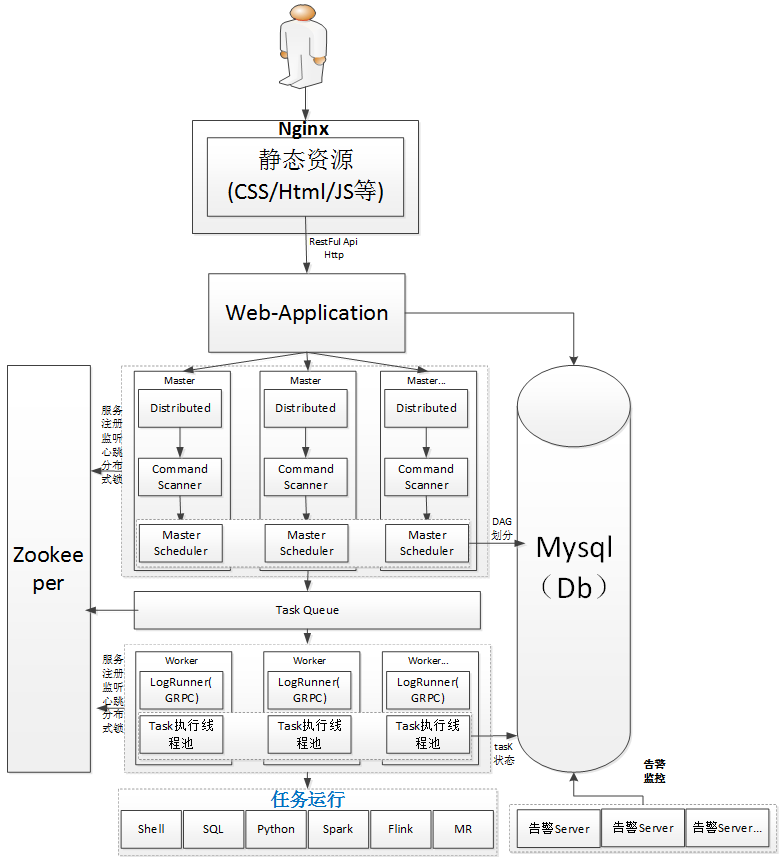
架構設計解釋說明如下:
MasterServer:
MasterServer採用分散式無中心設計理念,MasterServer主要負責 DAG 任務切分、任務提交監控,並同時監聽其它MasterServer和WorkerServer的健康狀態。 MasterServer服務啟動時向Zookeeper註冊臨時節點,通過監聽Zookeeper臨時節點變化來進行容錯處理。
該服務內主要包含:
Distributed 分散式調度組件,主要負責定時任務的啟停操作,當Distributed調起任務後,Master內部會有線程池具體負責處理任務的後續操作
MasterScheduler是一個掃描線程,定時掃描資料庫中的 command 表,根據不同的命令類型進行不同的業務操作
MasterExecThread主要是負責DAG任務切分、任務提交監控、各種不同命令類型的邏輯處理
MasterTaskExecThread主要負責任務的持久化
WorkerServer:
WorkerServer同樣也採用分散式無中心設計理念,WorkerServer主要負責任務的執行和提供日誌服務。WorkerServer服務啟動時向Zookeeper註冊臨時節點,並維持心跳。
該服務包含:
FetchTaskThread主要負責不斷從Task Queue中領取任務,並根據不同任務類型調用TaskScheduleThread對應執行器。
LoggerServer是一個GRPC服務,提供日誌分片查看、刷新和下載等功能
ZooKeeper:
ZooKeeper服務,系統中的MasterServer和WorkerServer節點都通過ZooKeeper來進行集群管理和容錯。另外系統還基於ZooKeeper進行事件監聽和分散式鎖。 也曾經想過基於Redis實現過隊列,不過還是想依賴到的組件儘量地少,減少研發的學習成本,所以最後還是去掉了Redis實現。
Task Queue:
提供任務隊列的操作,隊列也是基於Zookeeper來實現。由於隊列中存的信息較少,不必擔心隊列里數據過多的情況,對系統穩定性和性能沒影響。
告警服務:
提供告警相關介面,介面主要包括告警兩種類型的告警數據的存儲、查詢和通知功能。其中通知功能又有郵件通知和SNMP(暫未實現)兩種。
API(web App 應用動態請求處理)
API介面層,主要負責處理前端UI層的請求。該服務統一提供RESTful api向外部提供請求服務。 介面包括工作流的創建、定義、查詢、修改、發佈、下線、手工啟動、停止、暫停、恢復、從該節點開始執行等等。
UI(web app前端)
系統的前端頁面,提供系統的各種可視化操作界面,詳見系統使用手冊部分。
web application採用前後端分離的方式, UI(web app前端) 中的靜態資源採用nginx進行管理。
nginx.conf中的配置(前後端分離配置):
server {
listen 8888;# 監聽埠
server_name bigdata-manager;
#charset koi8-r;
access_log /var/log/nginx/access.log main;
location / {
root /opt/app/dist; 靜態資源文件的路徑
index index.html index.html;
}
location /webPortal{
proxy_pass http://127.0.0.1:12345;# 動態請求處理,請求後端的API
}
}
DAG: 全稱Directed Acyclic Graph,簡稱DAG。工作流中的Task任務以有向無環圖的形式組裝起來,從入度為零的節點進行拓撲遍歷,直到無後繼節點為止。
本文作者:張永清 轉載請註明來源博客園:https://www.cnblogs.com/laoqing/p/12692566.html
三、架構設計思想
1、中心化還是去中心化設計的選擇
中心化思想:中心化的設計理念比較簡單,分散式集群中的節點按照角色分工,大體上分為兩種角色:
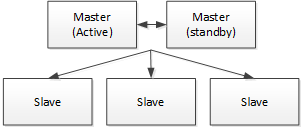
- Master的角色主要負責任務分發並監督Slave的健康狀態,可以動態的將任務均衡到Slave上,以致Slave節點不至於“忙死”或”閑死”的狀態。
- Worker的角色主要負責任務的執行工作並維護和Master的心跳,以便Master可以分配任務給Slave。
中心化思想設計存在的不足:
- 一旦Master出現了問題,則集群就會癱瘓,甚至整個集群就會崩潰。為瞭解決這個問題,大多數Master/Slave架構模式都採用了主備Master的設計方案,可以是熱備或者冷備,也可以是自動切換或手動切換,而且越來越多的新系統都開始具備自動選舉切換Master的能力,以提升系統的可用性。
- 另外一個問題是如果Scheduler在Master上,雖然可以支持一個DAG中不同的任務運行在不同的機器上,但是會產生Master的過負載。如果Scheduler在Slave上,則一個DAG中所有的任務都只能在某一臺機器上進行作業提交,則並行任務比較多的時候,Slave的壓力可能會比較大。
去中心化思想:
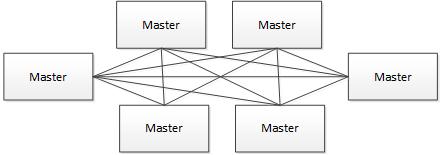
- 在去中心化設計里,通常沒有Master/Slave的概念,所有的角色都是一樣的,地位是平等的,任意節點設備down機,都只會影響很小範圍的功能。
- 去中心化設計的核心設計在於整個分散式系統中不存在一個區別於其他節點的”管理者”,因此不存在單點故障問題。但由於不存在” 管理者”節點所以每個節點都需要跟其他節點通信才得到必須要的機器信息,而分散式系統通信的不可靠行,則大大增加了上述功能的實現難度。
- 真正去中心化的分散式系統並不多見。反而動態中心化分散式系統正在不斷涌出。在這種架構下,集群中的管理者是被動態選擇出來的,而不是預置的,並且集群在發生故障的時候,集群的節點會自發的舉行"會議"來選舉新的"管理者"去主持工作。最典型的案例就是ZooKeeper及Go語言實現的Etcd。
- 我們設計的去中心化是Master/Worker註冊到Zookeeper中,實現Master集群和Worker集群無中心,並使用Zookeeper分散式鎖來選舉其中的一臺Master或Worker為“管理者”來執行任務。
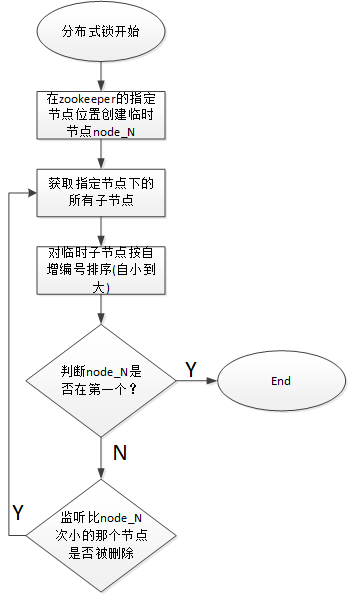
2、分散式鎖的設計
使用ZooKeeper實現分散式鎖來實現同一時刻集群中只有一臺Master執行Scheduler,或者只有一臺Worker執行任務的提交處理。
獲取分散式鎖的核心流程演算法如下:
本文作者:張永清 轉載請註明來源博客園:https://www.cnblogs.com/laoqing/p/12692566.html
線程分散式鎖實現流程圖:
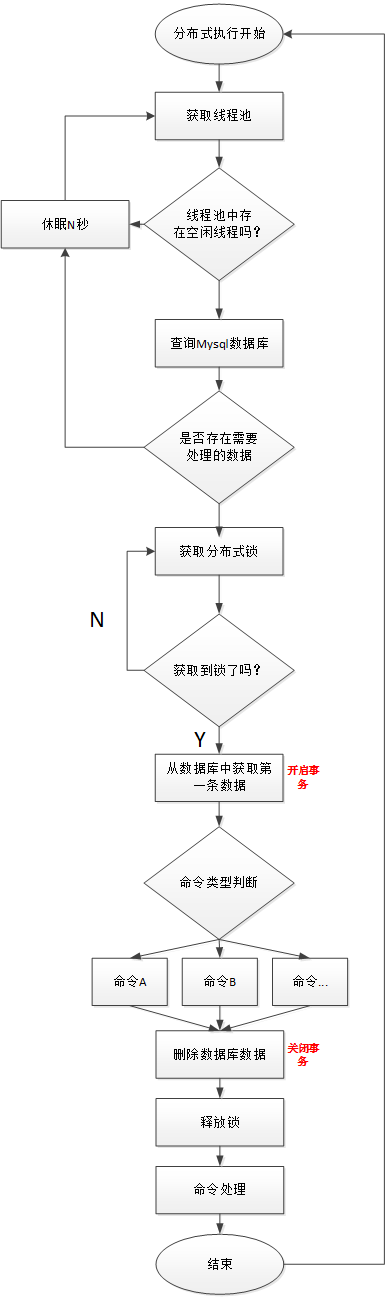
線程不足,迴圈等待問題:
-
如果一個DAG中沒有子流程,則如果Command中的數據條數大於線程池設置的閾值,則直接流程等待或失敗。
-
如果一個大的DAG中嵌套了很多子流程,如下圖:

則會產生“死等”狀態。MainFlowThread等待SubFlowThread1結束,
SubFlowThread1等待SubFlowThread2結束,SubFlowThread2等待SubFlowThread3結束,而SubFlowThread3等待線程池有新線程,則整個DAG流程不能結束,從而其中的線程也不能釋放。這樣就形成的子父流程迴圈等待的狀態。此時除非啟動新的Master來增加線程來打破這樣的”僵局”,否則調度集群將不能再使用。
對於啟動新Master來打破僵局,似乎有點差強人意,於是我們提出了以下三種方案來降低這種風險:
-
計算所有Master的線程總和,然後對每一個DAG需要計算其需要的線程數,也就是在DAG流程執行之前做預計算。因為是多Master線程池,所以匯流排程數不太可能實時獲取。
-
對單Master線程池進行判斷,如果線程池已經滿了,則讓線程直接失敗。
-
增加一種資源不足的Command類型,如果線程池不足,則將主流程掛起。這樣線程池就有了新的線程,可以讓資源不足掛起的流程重新喚醒執行。
註意:Master Scheduler線程在獲取Command的時候是FIFO的方式執行的。
3、集群節點掛掉等異常容錯處理
容錯設計依賴於Zookeeper的Watcher機制,實現原理如下
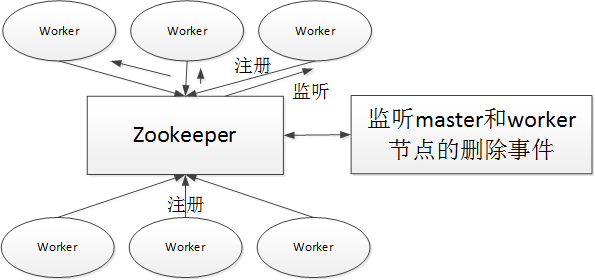
Master監控其他Master和Worker的目錄,如果監聽到remove事件,則會根據具體的業務邏輯進行流程實例容錯或者任務實例容錯。
Master容錯流程圖:
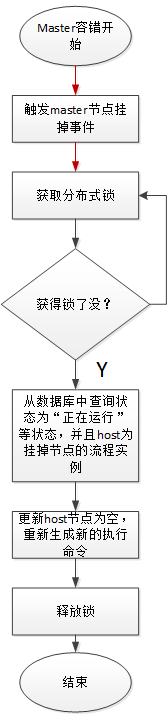
ZooKeeper Master容錯完成之後則重新由EasyScheduler中Scheduler線程調度,遍歷 DAG 找到”正在運行”和“提交成功”的任務,對”正在運行”的任務監控其任務實例的狀態,對”提交成功”的任務需要判斷Task Queue中是否已經存在,如果存在則同樣監控任務實例的狀態,如果不存在則重新提交任務實例。
Worker容錯流程圖:
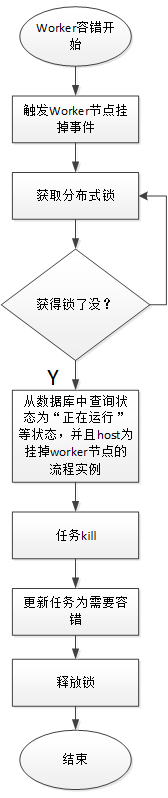
Master Scheduler線程一旦發現任務實例為” 需要容錯”狀態,則接管任務併進行重新提交。
由於“網路抖動”可能會使得節點短時間內失去和zk的心跳,從而發生節點的remove事件。對於這種情況,我們使用最簡單的方式,那就是節點一旦和zk發生超時連接,則直接將Master或Worker服務停掉。
任務失敗重試處理:
失敗分為:任務失敗重試、流程失敗恢復、流程失敗重跑。
- 任務失敗重試是任務級別的,是調度系統自動進行的,比如一個Shell任務設置重試次數為3次,那麼在Shell任務運行失敗後會自己再最多嘗試運行3次
- 流程失敗恢復是流程級別的,是手動進行的,恢復是從只能從失敗的節點開始執行或從當前節點開始執行
- 流程失敗重跑也是流程級別的,是手動進行的,重跑是從開始節點進行
我們將工作流中的任務節點分了兩種類型。
-
一種是業務節點,這種節點都對應一個實際的腳本或者處理語句,比如Shell節點,MR節點、Spark節點、依賴節點等。
-
還有一種是邏輯節點,這種節點不做實際的腳本或語句處理,只是整個流程流轉的邏輯處理,比如子流程節等。
每一個業務節點都可以配置失敗重試的次數,當該任務節點失敗,會自動重試,直到成功或者超過配置的重試次數。邏輯節點不支持失敗重試。但是邏輯節點里的任務支持重試。
如果工作流中有任務失敗達到最大重試次數,工作流就會失敗停止,失敗的工作流可以手動進行重跑操作或者流程恢復操作
4、日誌查看實現
由於Web Application和Worker不一定在同一臺機器上,所以查看日誌不能像查詢本地文件那樣。有兩種方案:
-
將日誌放到ES搜索引擎上存儲,通過對es進行查詢。
-
通過gRPC通信獲取遠程日誌信息
介於考慮到儘可能的系統設計的輕量級性,所以選擇了gRPC實現遠程訪問日誌信息。

GRPC的傳輸的性能以及I/O都比較高,日誌查詢起來也很快。
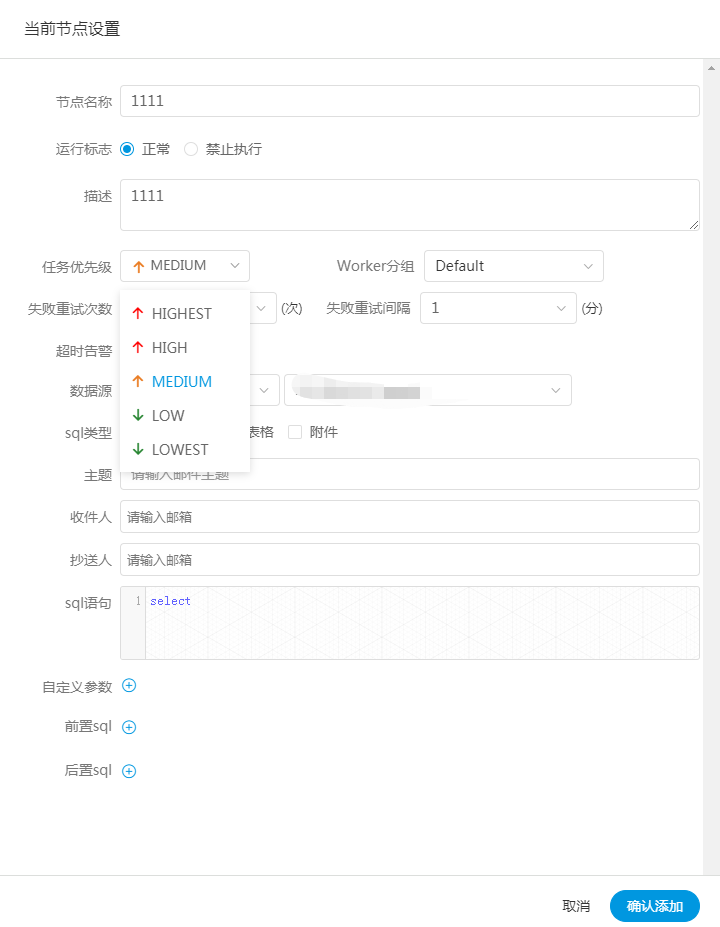
5、任務優先順序設計
如果沒有優先順序設計,採用公平調度設計的話,會遇到先行提交的任務可能會和後繼提交的任務同時完成的情況,而不能做到設置流程或者任務的優先順序,因此我們對此進行了重新設計,目前我們設計如下:
-
按照不同流程實例優先順序優先於同一個流程實例優先順序優先於同一流程內任務優先順序優先於同一流程內任務提交順序依次從高到低進行任務處理。
-
具體實現是根據任務實例的json解析優先順序,然後把流程實例優先順序流程實例id任務優先順序_任務id信息保存在ZooKeeper任務隊列中,當從任務隊列獲取的時候,通過字元串比較即可得出最需要優先執行的任務。
- 流程定義的優先順序是考慮到有些流程需要先於其他流程進行處理,這個可以在流程啟動或者定時啟動時配置,共有5級,依次為HIGHEST、HIGH、MEDIUM、LOW、LOWEST
- 任務的優先順序也分為5級,依次為HIGHEST、HIGH、MEDIUM、LOW、LOWEST,如下圖所示
-

