
索引是一種加快查詢速度的數據結構,常用索引結構有hash、B Tree和B+Tree。本節通過分析三者的數據結構來說明為啥Mysql選擇用B+Tree數據結構。 數據結構 Hash hash是基於哈希表完成索引存儲,哈希表特性是數據存放是散列的。 優點: 等值查詢快,通過hash值直接定位到具體的數 ...
索引是一種加快查詢速度的數據結構,常用索引結構有hash、B-Tree和B+Tree。本節通過分析三者的數據結構來說明為啥Mysql選擇用B+Tree數據結構。
數據結構
Hash
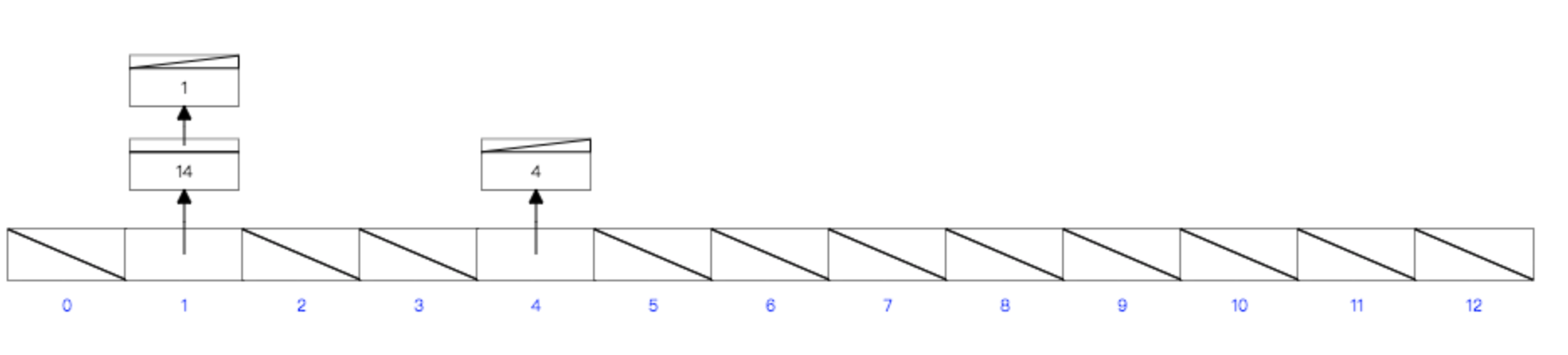
hash是基於哈希表完成索引存儲,哈希表特性是數據存放是散列的。
優點:
等值查詢快,通過hash值直接定位到具體的數據。
缺點:
- 範圍查詢效率低(表中的數據是無序數據,在日常開發中通常需要範圍查詢,該情況下hash需要一個一個查找後合併返回)
- hash表在使用的時會將所有數據載入到記憶體,比較消耗記憶體
- hash演算法不好會出現hash碰撞的情況
- 哈希索引只包含哈希值和行指針,而不存儲欄位值,索引不能使用索引中的值來避免讀取行
- 哈希索引不支持部分列匹配查找,哈希索引是使用索引列的全部內容來計算哈希值
B-Tree
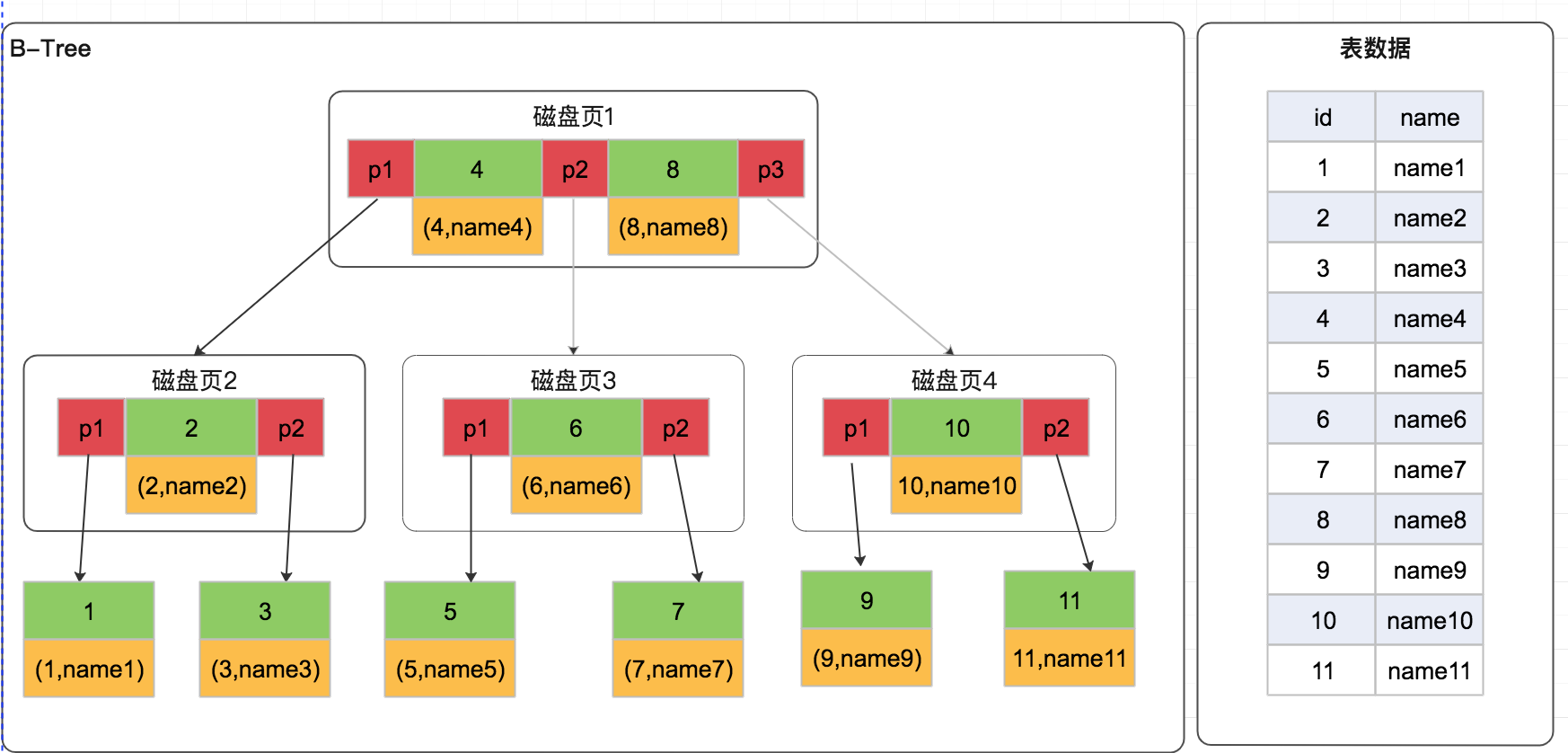
B-Tree特點:
- 所有鍵值數據分佈在整棵樹各個節點中
- 搜索有可能在非節點結束,在關鍵字全集內查找,類似二分查找
- 所有葉子節點都在同一層,並且以升序排列
B+Tree
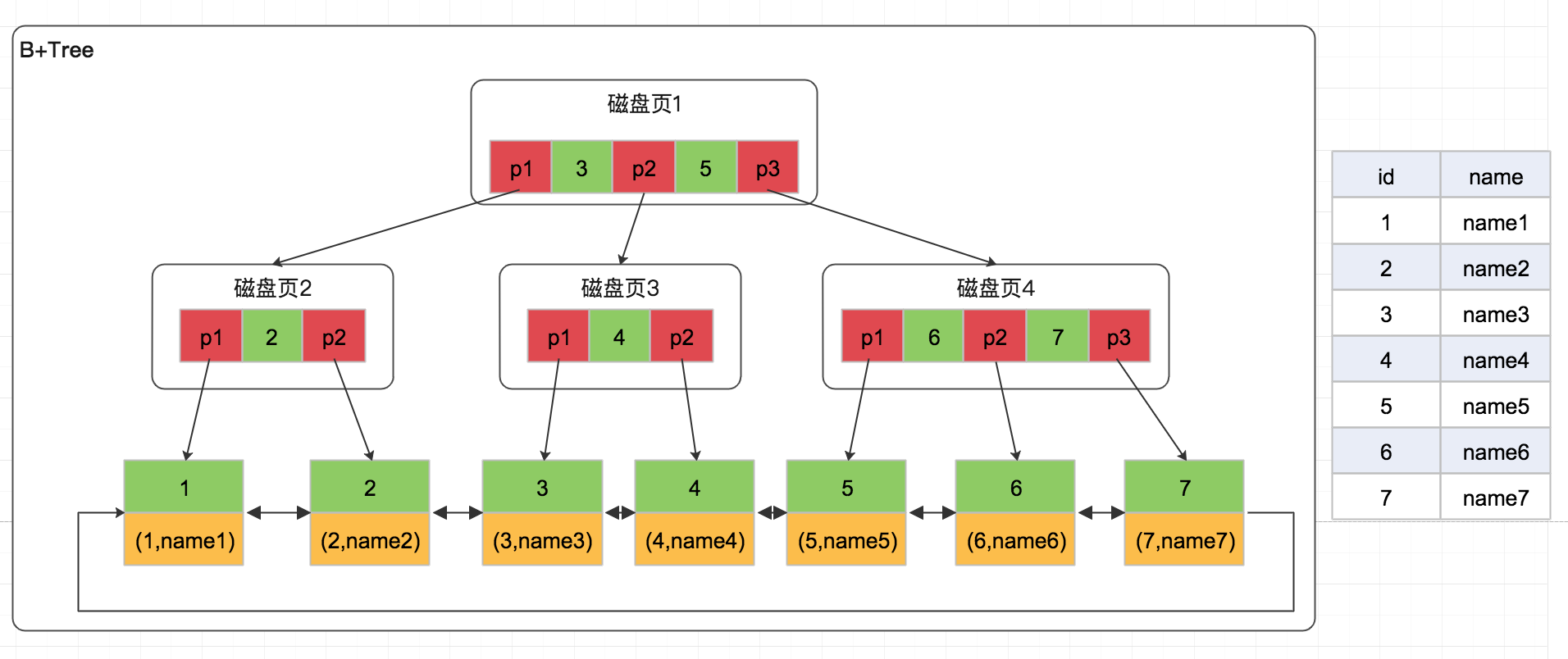
B+Tree 是在B-Tree的基礎之上做的一種優化,變化如下:
- B+Tree 非葉子節點不存放數據
- 葉子節點存儲關鍵字和數據,非葉子節點的關鍵字也會沉到葉子節點,並且排序
- 葉子節點兩兩指針相互連接,形成一個雙向環形鏈表(符合磁碟的預讀特性),順序查詢性能更高
Mysql為什麼選擇B+Tree

Mysql官網文檔中寫到InnoDB索引用的是 B-tree,但是底層用的是B+Tree。Mysql存儲數據是以頁為單位,預設一個頁可以存放16K數據。假設B-Tree和B+Tree都是3層深度,表中每個記錄為1K(假設的,一般不會這麼大,別較真),那麼三層深度的B-Tree存儲 16 x 16 x 16 = 4096(比這個數還要少,因為每個頁中還要存放指針和其它的數據)。B+Tree第一、二層存放的是key,假設是Long類型的主鍵,那麼第一、二層每頁存放數據約為 16 x 1024 / 8 = 2048,三層深度可以存放 2048 x 2048 x 16 = 6700W。MySQL查詢過程是按頁載入數據的,每載入一頁就是一次IO操作,B+Tree進行三次IO可以查詢6700W數據量。從這裡也可以知道Mysql一般設置三層深度就足夠了。


