
前言 為了避免單點故障,我們需要將數據複製多份部署在多台不同的伺服器上,即使有一臺伺服器出現故障其他伺服器依然可以繼續提供服務 作用: 數據備份 擴展讀性能(讀寫分離) 複製方式: 全量複製 部分複製 實現方式 1、一主二撲 A(B、C) 一個Master兩個Slave 2、薪火相傳(去中心化) A ...
前言
為了避免單點故障,我們需要將數據複製多份部署在多台不同的伺服器上,即使有一臺伺服器出現故障其他伺服器依然可以繼續提供服務
作用:
數據備份
擴展讀性能(讀寫分離)
複製方式:
全量複製
部分複製
實現方式
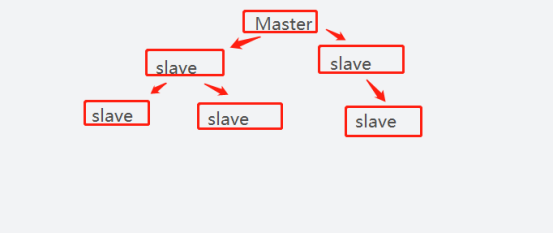
1、一主二撲 A(B、C) 一個Master兩個Slave
2、薪火相傳(去中心化) A-B-C,B既是主節點(C的主節點),又是從節點(A的從節點)
3、反客為主(主節點down掉後,手動操作升級從節點為主節點)
4、哨兵模式(後臺監控主機是否故障,如果故障了根據投票數自動將從庫轉換為主庫)
一主多從
配置:
Master:6379埠 requirepass 123456 slave1: 6380埠 port 6380 slaveof 127.0.0.1 6379 masterauth 123456 Slave2: 6381埠 port 6381 slaveof 127.0.0.1 6379 masterauth 123456
啟動
開啟Master
redis-server.exe redis.windows.conf
開啟slave1

開啟slave2
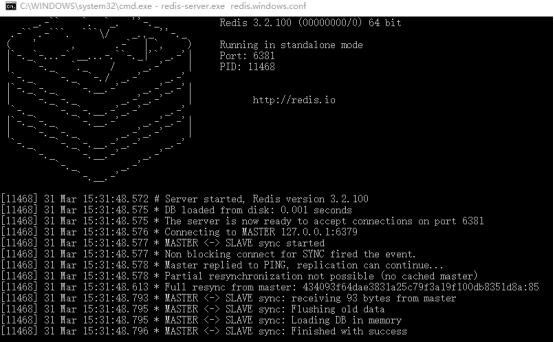
查看master

測試
連接三個redis
向master寫入數據

查看slave1


可能出現的問題
啟動服務,127.0.0.1java.net.SocketTimeoutException:connect time out超時和ping不通埠
解決:關閉防火牆
哨兵模式sentinel
哨兵模式的任務:
監控(Monitoring):Sentinel會不斷地檢查你的主伺服器和從伺服器是否允許正常。
提醒(Notification):當被監控的某個Redis伺服器出現問題時,Sentinel可以通過API向管理員或者其他應用程式發送通知。
自動故障遷移(Automatic failover):
(1)當一個主伺服器不能正常工作時,Sentinel會開始一次自動故障遷移操作,他會將失效主伺服器的其中一個從伺服器升級為新的主伺服器,並讓失效主伺服器的其他從伺服器改為複製新的主伺服器;
(2)客戶端試圖連接失敗的主伺服器時,集群也會向客服端返回新主伺服器的地址,是的集群可以使用新主伺服器代替失效伺服器
新建配置sentinel.conf
三個redis配置只有埠port不一樣
#埠區別不同 #當前Sentinel服務運行的埠 port 26379 # 哨兵監聽的主伺服器 mymaster名稱(可以自定義),1票 sentinel monitor mymaster 127.0.0.1 6379 1 sentinel auth-pass mymaster 123456 # 10s內mymaster無響應,則認為master宕機了 sentinel down-after-milliseconds mymaster 10000 #如果20秒後,mysater仍沒啟動過來,則啟動failover sentinel failover-timeout mymaster 20000 # 執行故障轉移時, 最多有1個從伺服器同時對新的主伺服器進行同步,數字越小, 完成故障轉移所需的時間就越長 sentinel parallel-syncs mymaster 1 bind 127.0.0.1 protected-mode yes
可能出現的問題
redis 主從切換失敗


[12248] 31 Mar 17:09:26.726 # +try-failover master mymaster 127.0.0.1 6379 [12248] 31 Mar 17:09:26.728 # +vote-for-leader 2fe3a13e25190364c193e71b6d89257323d694ce 11 [12248] 31 Mar 17:09:26.728 # +elected-leader master mymaster 127.0.0.1 6379 [12248] 31 Mar 17:09:26.728 # +failover-state-select-slave master mymaster 127.0.0.1 6379 [12248] 31 Mar 17:09:26.803 # -failover-abort-no-good-slave master mymaster 127.0.0.1 6379 [12248] 31 Mar 17:09:26.864 # Next failover delay: I will not start a failover before Tue Mar 31 17:10:17 2020 [12248] 31 Mar 17:10:17.170 # +new-epoch 12 [12248] 31 Mar 17:10:17.171 # +try-failover master mymaster 127.0.0.1 6379 [12248] 31 Mar 17:10:17.179 # +vote-for-leader 2fe3a13e25190364c193e71b6d89257323d694ce 12 [12248] 31 Mar 17:10:17.179 # +elected-leader master mymaster 127.0.0.1 6379 [12248] 31 Mar 17:10:17.181 # +failover-state-select-slave master mymaster 127.0.0.1 6379 [12248] 31 Mar 17:10:17.265 # -failover-abort-no-good-slave master mymaster 127.0.0.1 6379 [12248] 31 Mar 17:10:17.349 # Next failover delay: I will not start a failover before Tue Mar 31 17:11:07 2020 [12248] 31 Mar 17:11:07.279 # +new-epoch 13 [12248] 31 Mar 17:11:07.279 # +try-failover master mymaster 127.0.0.1 6379 [12248] 31 Mar 17:11:07.284 # +vote-for-leader 2fe3a13e25190364c193e71b6d89257323d694ce 13 [12248] 31 Mar 17:11:07.285 # +elected-leader master mymaster 127.0.0.1 6379 [12248] 31 Mar 17:11:07.288 # +failover-state-select-slave master mymaster 127.0.0.1 6379 [12248] 31 Mar 17:11:07.351 # -failover-abort-no-good-slave master mymaster 127.0.0.1 6379 [12248] 31 Mar 17:11:07.443 # Next failover delay: I will not start a failover before Tue Mar 31 17:11:57 2020View Code
問題是:配置錯誤重新配置
分別啟動三個哨兵
redis-server.exe sentinel.conf --sentinel
測試
關閉mster
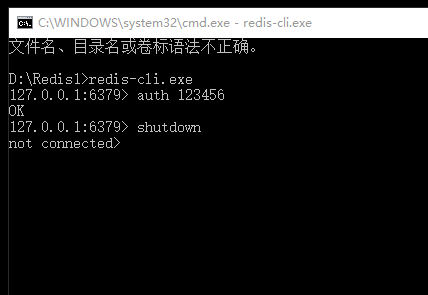
查看
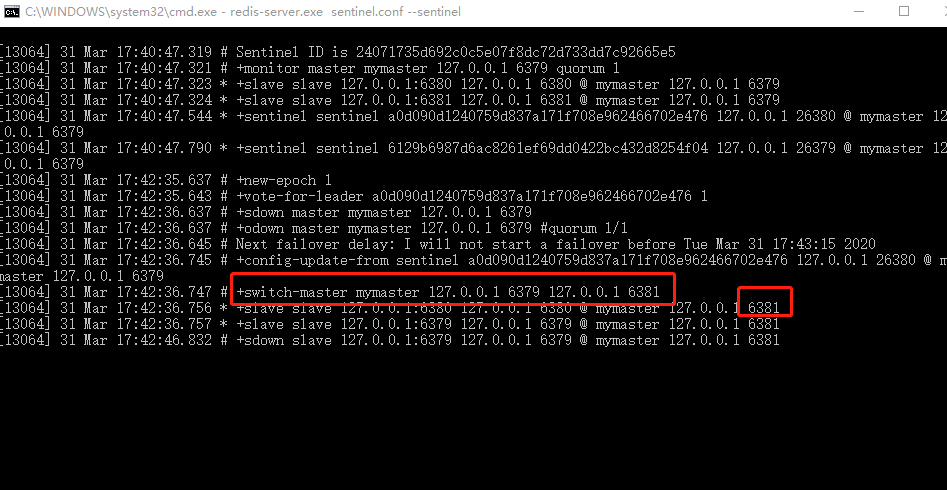
slave2(6381)升為master
重新開啟之前的master(6379),這時候master還是之前的slave2(6381)
常見問題
讀寫分離
複製數據存在延遲(如果從節點發生阻塞)
從節點可能發生故障
主從配置不一致
例如maxmemory不一致,可能會造成丟失數據
例如數據結構優化參數不一致:造成主從記憶體不一致
規避全量複製
第一次全量複製不可避免,所以分片的maxmemory減小,同時選擇在低峰(夜間)時,做全量複製。
複製積壓緩衝區不足
增大複製緩衝區配置rel_backlog_size
例如如果網路中斷的平均時間是60s,而主節點平均每秒產生的寫命令(特定協議格式)所占的位元組數為100KB,則複製積壓緩衝區的平均需求為6MB,保險起見,可以設置為12MB,來保證絕大多數斷線情況都可以使用部分複製。
複製風暴
master節點重啟,master節點生成一份rdb文件,但是要給所有從節點發送rdb文件。對cpu,記憶體,帶寬都造成很大的壓力
參考:https://www.jianshu.com/p/4aa9591c3153


