
說到數據上報,很多人第一印象是直接點對點的上報數據,優點是簡單直接省事,但是缺點很明顯,侵入性太強,業務中會摻雜很多非業務的事情。當然這裡的簡單省事是短暫的,如果業務以及開發完了,後面追加數據上報功能,再按照這個模式,將帶來空前的壓力,代碼基本上要重新寫、測試。這個任務量也許會很大,因為一時的省事為 ...
說到數據上報,很多人第一印象是直接點對點的上報數據,優點是簡單直接省事,但是缺點很明顯,侵入性太強,業務中會摻雜很多非業務的事情。當然這裡的簡單省事是短暫的,如果業務以及開發完了,後面追加數據上報功能,再按照這個模式,將帶來空前的壓力,代碼基本上要重新寫、測試。這個任務量也許會很大,因為一時的省事為以後埋下大坑,這個是做研發要極力避免的、不能容忍的。此時我們要做的事是如何解耦,將非業務性功能提取出來,做成一個統一的數據上報平臺。因此我們就有了下文的技術方案。
系統設計架構圖:
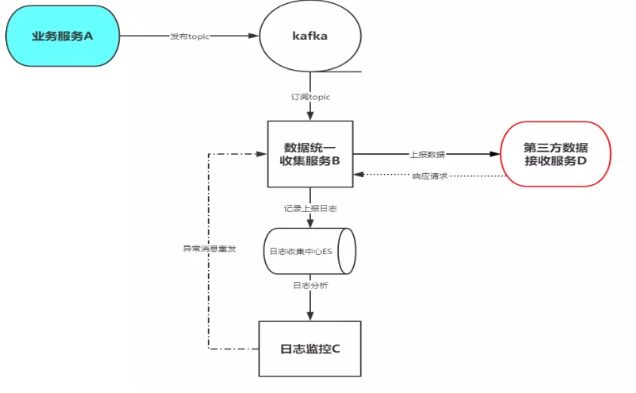
圖示:關於技術選型,a、b、c都是基於springcloud,數據存儲我們選擇Elasticsearch,消息中間件使用kafka。
上圖的業務是將a服務的數據上報到d服務。按照一般的流程我們可以直接將a服務的數據直接發送到d服務,這樣的好處是簡單,但是缺點顯而易見,侵入性、耦合性太強,這不是我們想要的。我們要將與業務無關的服務剝離出來,做成一個統一的數據上報中心也就是上圖中的b服務,在這個服務中只做一件事,那就是業務數據上報,而此時的a服務只管專心的做業務,無需關心其它,二者各司其職,互不影響,做到真正的業務分離。
此時b服務的上報數據從哪兒來,a服務直接發給b服務?很明顯不是,如果這樣做和a服務點對點發送到d服務有什麼區別呢,反而增加了一個中間環節,增加了不穩定因素。那我們該怎麼做?想一想,多個程式如何進行消息傳遞?此時我們會想到消息中間件這個很神奇的一個東西。網上搜索一大堆消息中間件,那麼我們該如何選擇呢?我們這裡選擇的是kafka,原因是我們這裡的數據量大、生態環境非常好,實時數據處理比較好,而且我們之前已經在使用它了,在滿足業務的情況下,沒有必要再額外的維護一個中間件,我們要本著業務、經濟的原則去技術選型,不要為了技術而技術。

在上報數據的時候我們還得考慮很多問題:
1.上報數據日誌監控
我們這裡的日誌量很大,而且需要各種維度的日誌分析這個功能,因此日誌存儲我們採用Elasticsearch。
它是一個分散式搜索引擎,支持海量數據存儲,檢索查詢。在這裡使用它再適合不過。
2.數據丟失。比如服務d宕機、網路堵塞原因會導致上報數據丟失(在a、b服務正常的情況下),那麼如何解決這個?由於我們做了日誌監控,所以會很簡單的解決這個問題,將上報異常的數據重新發送就好了。
使用場景:
本架構使用在互聯網醫院項目中,業務是衛健委要求醫院上報線上看病患者產生的數據,且上報數據不允許丟失,如果對方平臺無法使用,則要求補發丟失數據。
a對應醫院線上看病服務,d對應衛健委數據接收服務。b、c就是內部非業務服務。
最後總結核心點,我們要將業務和非業務相關的東西剝離開來,各司其職,互不影響,這正符合現在流行的微服務理念。
推薦閱讀:
【大廠】基於rabbitMQ消息中心技術方案
【乾貨】一篇文章講透數據挖掘
【乾貨】微服務設計的基礎知識【對話老王】聊聊那數據
【輕鬆話題】閑話程式員
【劃劃重點】論大數據中主數據的重要性
【談大數據】CDH6.x學習筆記(角色簡介)


