
背景 By 魯迅 By 高爾基 說明: 1. Kernel版本:4.14 2. ARM64處理器,Contex A53,雙核 3. 使用工具:Source Insight 3.5, Visio 1. 概述 組調度( )是使用Linux 的cpu子系統來實現的,可以將進程進行分組,按組來分配CPU資源 ...
背景
Read the fucking source code!--By 魯迅A picture is worth a thousand words.--By 高爾基
說明:
- Kernel版本:4.14
- ARM64處理器,Contex-A53,雙核
- 使用工具:Source Insight 3.5, Visio
1. 概述
組調度(task_group)是使用Linux cgroup(control group)的cpu子系統來實現的,可以將進程進行分組,按組來分配CPU資源等。
比如,看一個實際的例子:
A和B兩個用戶使用同一臺機器,A用戶16個進程,B用戶2個進程,如果按照進程的個數來分配CPU資源,顯然A用戶會占據大量的CPU時間,這對於B用戶是不公平的。組調度就可以解決這個問題,分別將A、B用戶進程劃分成組,並將兩組的權重設置成占比50%即可。
帶寬(bandwidth)控制,是用於控制用戶組(task_group)的CPU帶寬,通過設置每個用戶組的限額值,可以調整CPU的調度分配。在給定周期內,當用戶組消耗CPU的時間超過了限額值,該用戶組內的任務將會受到限制。
由於組調度和帶寬控制緊密聯繫,因此本文將探討這兩個主題,本文的討論都基於CFS調度器,開始吧。
2. task_group
- 組調度,在內核中是通過
struct task_group來組織的,task_group本身支持cfs組調度和rt組調度,本文主要分析cfs組調度。 - CFS調度器管理的是
sched_entity調度實體,task_struct(代表進程)和task_group(代表進程組)中分別包含sched_entity,進而來參與調度;
關於組調度的相關數據結構,組織如下:
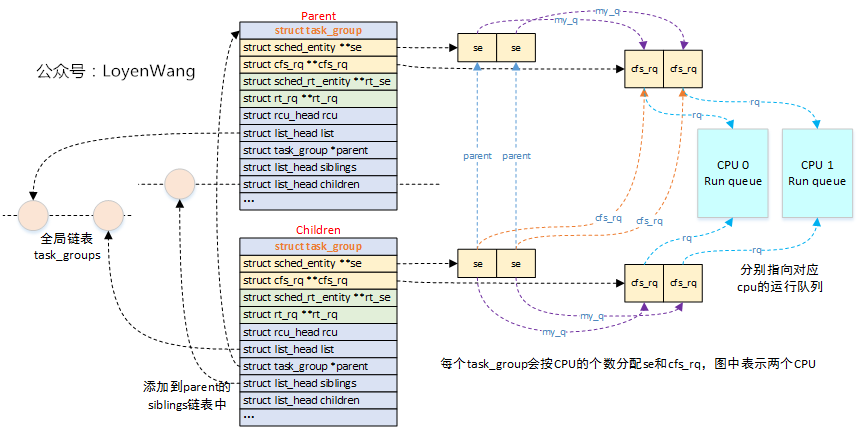
- 內核維護了一個全局鏈表
task_groups,創建的task_group會添加到這個鏈表中; - 內核定義了
root_task_group全局結構,充當task_group的根節點,以它為根構建樹狀結構; struct task_group的子節點,會加入到父節點的siblings鏈表中;- 每個
struct task_group會分配運行隊列數組和調度實體數組(以CFS為例,RT調度類似),其中數組的個數為系統CPU的個數,也就是為每個CPU都分配了運行隊列和調度實體;
對應到實際的運行中,如下:
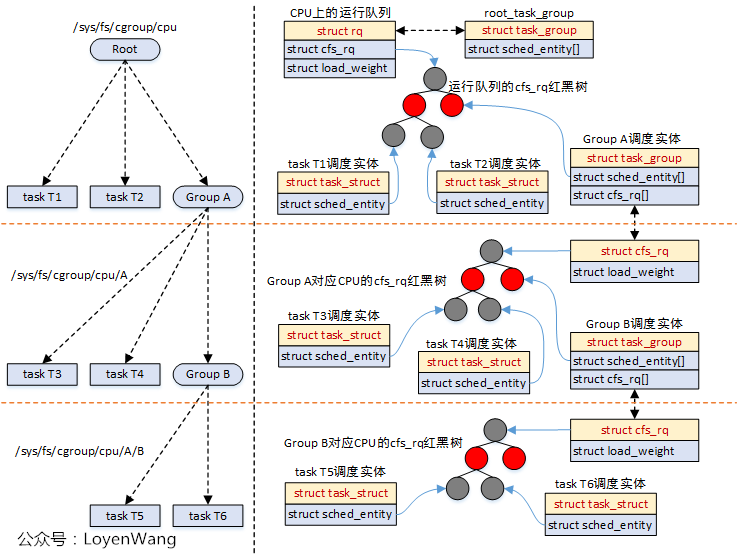
struct cfs_rq包含了紅黑樹結構,sched_entity調度實體參與調度時,都會掛入到紅黑樹中,task_struct和task_group都屬於被調度對象;task_group會為每個CPU再維護一個cfs_rq,這個cfs_rq用於組織掛在這個任務組上的任務以及子任務組,參考圖中的Group A;- 調度器在調度的時候,比如調用
pick_next_task_fair時,會從遍歷隊列,選擇sched_entity,如果發現sched_entity對應的是task_group,則會繼續往下選擇; - 由於
sched_entity結構中存在parent指針,指向它的父結構,因此,系統的運行也能從下而上的進行遍歷操作,通常使用函數walk_tg_tree_from進行遍歷;
2.2 task_group權重
- 進程或進程組都有權重的概念,調度器會根據權重來分配CPU的時間。
- 進程組的權重設置,可以通過
/sys文件系統進行設置,比如操作/sys/fs/cgoup/cpu/A/shares;
調用流程如下圖:
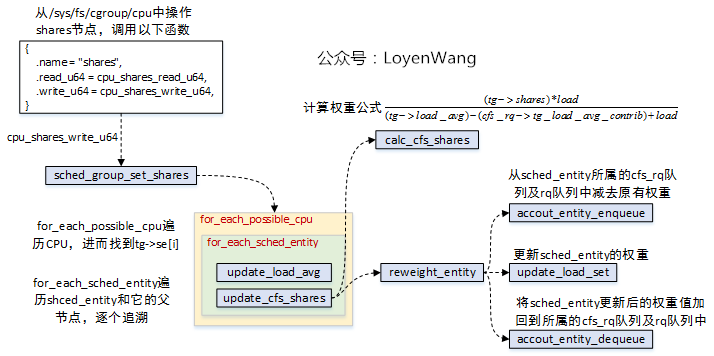
sched_group_set_shares來完成最終的設置;task_group為每個CPU都分配了一個sched_entity,針對當前sched_entity設置更新完後,往上對sched_entity->parent設置更新,直到根節點;shares的值計算與load相關,因此也需要調用update_load_avg進行更新計算;
看一下實際的效果圖吧:
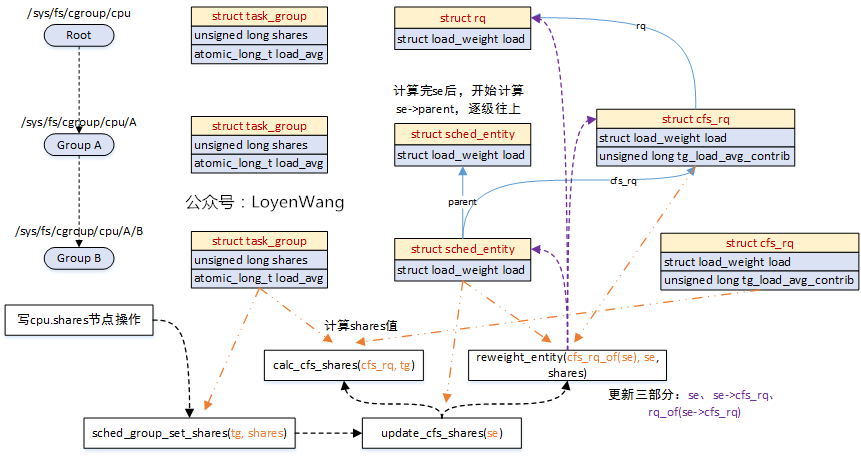
- 寫節點操作可以通過
echo XXX > /sys/fs/cgroup/cpu/A/B/cpu.shares; - 橙色的線代表傳入參數指向的對象;
- 紫色的線代表每次更新涉及到的對象,包括三個部分;
- 處理完
sched_entity後,繼續按同樣的流程處理sched_entity->parent;
3. cfs_bandwidth
先看一下/sys/fs/cgroup/cpu下的內容吧:

- 有兩個關鍵的欄位:
cfs_period_us和cfs_quota_us,這兩個與cfs_bandwidth息息相關; period表示周期,quota表示限額,也就是在period期間內,用戶組的CPU限額為quota值,當超過這個值的時候,用戶組將會被限制運行(throttle),等到下一個周期開始被解除限制(unthrottle);
來一張圖直觀理解一下:

- 在每個周期內限制在
quota的配額下,超過了就throttle,下一個周期重新開始;
3.1 數據結構
內核中使用struct cfs_bandwidth來描述帶寬,該結構包含在struct task_group中。
此外,struct cfs_rq中也有與帶寬控制相關的欄位。
還是來看一下代碼吧:
struct cfs_bandwidth {
#ifdef CONFIG_CFS_BANDWIDTH
raw_spinlock_t lock;
ktime_t period;
u64 quota, runtime;
s64 hierarchical_quota;
u64 runtime_expires;
int idle, period_active;
struct hrtimer period_timer, slack_timer;
struct list_head throttled_cfs_rq;
/* statistics */
int nr_periods, nr_throttled;
u64 throttled_time;
#endif
};- period:周期值;
- quota:限額值;
- runtime:記錄限額剩餘時間,會使用quota值來周期性賦值;
- hierarchical_quota:層級管理任務組的限額比率;
- runtime_expires:每個周期的到期時間;
- idle:空閑狀態,不需要運行時分配;
- period_active:周期性計時已經啟動;
- period_timer:高精度周期性定時器,用於重新填充運行時間消耗;
- slack_timer:延遲定時器,在任務出列時,將剩餘的運行時間返回到全局池裡;
- throttled_cfs_rq:限流運行隊列列表;
- nr_periods/nr_throttled/throttled_time:統計值;
struct cfs_rq結構中相關欄位如下:
struct cfs_rq {
...
#ifdef CONFIG_CFS_BANDWIDTH
int runtime_enabled;
u64 runtime_expires;
s64 runtime_remaining;
u64 throttled_clock, throttled_clock_task;
u64 throttled_clock_task_time;
int throttled, throttle_count;
struct list_head throttled_list;
#endif /* CONFIG_CFS_BANDWIDTH */
...
}- runtime_enabled:周期計時器使能;
- runtime_expires:周期計時器到期時間;
- runtime_remaining:剩餘的運行時間;
3.2 流程分析
3.2.1 初始化流程
先看一下初始化的操作,初始化函數init_cfs_bandwidth本身比較簡單,完成的工作就是將struct cfs_bandwidth結構體進程初始化。
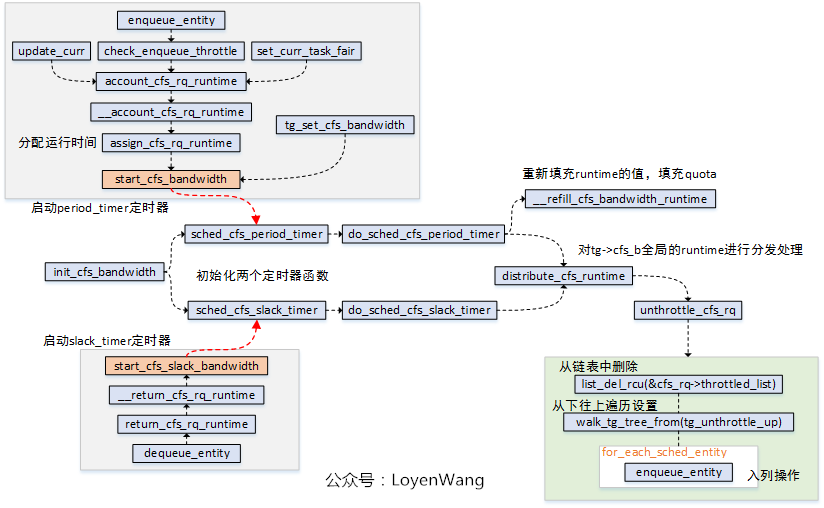
- 註冊兩個高精度定時器:
period_timer和slack_timer; period_timer定時器,用於在時間到期時重新填充關聯的任務組的限額,併在適當的時候unthrottlecfs運行隊列;slack_timer定時器,slack_period周期預設為5ms,在該定時器函數中也會調用distribute_cfs_runtime從全局運行時間中分配runtime;start_cfs_bandwidth和start_cfs_slack_bandwidth分別用於啟動定時器運行,其中可以看出在dequeue_entity的時候會去利用slack_timer,將運行隊列的剩餘時間返回給tg->cfs_b這個runtime pool;unthrottle_cfs_rq函數,會將throttled_list中的對應cfs_rq刪除,並且從下往上遍歷任務組,針對每個任務組調用tg_unthrottle_up處理,最後也會根據cfs_rq對應的sched_entity從下往上遍歷處理,如果sched_entity不在運行隊列上,那就重新enqueue_entity以便參與調度運行,這個也就完成瞭解除限制的操作;
do_sched_cfs_period_timer函數與do_sched_cfs_slack_timer()函數都調用了distrbute_cfs_runtime(),該函數用於分發tg->cfs_b的全局運行時間runtime,用於在該task_group中平衡各個CPU上的cfs_rq的運行時間runtime,來一張示意圖:
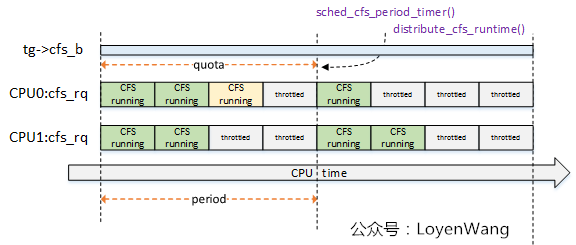
- 系統中兩個CPU,因此
task_group針對每個cpu都維護了一個cfs_rq,這些cfs_rq來共用該task_group的限額運行時間; - CPU0上的運行時間,淺黃色模塊表示超額了,那麼在下一個周期的定時器點上會進行彌補處理;
3.2.2 用戶設置流程
用戶可以通過操作/sys中的節點來進行設置:

- 操作
/sys/fs/cgroup/cpu/下的cfs_quota_us/cfs_period_us節點,最終會調用到tg_set_cfs_bandwidth函數; tg_set_cfs_bandwidth會從root_task_group根節點開始,遍歷組調度樹,並逐個設置限額比率 ;- 更新
cfs_bandwidth的runtime信息; - 如果使能了
cfs_bandwidth功能,則啟動帶寬定時器; - 遍歷
task_group中的每個cfs_rq隊列,設置runtime_remaining值,如果cfs_rq隊列限流了,則需要進行解除限流操作;
3.2.3 throttle限流操作
cfs_rq運行隊列被限制,是在throttle_cfs_rq函數中實現的,其中調用關係如下圖:

- 調度實體
sched_entity入列時,進行檢測是否運行時間已經達到限額,達到則進行限制處理; pick_next_task_fair/put_prev_task_fair在選擇任務調度時,也需要進行檢測判斷;
3.2.4 總結
總體來說,帶寬控制的原理就是通過task_group中的cfs_bandwidth來管理一個全局的時間池,分配給屬於這個任務組的運行隊列,當超過限額的時候則限制隊列的調度。同時,cfs_bandwidth維護兩個定時器,一個用於周期性的填充限額併進行時間分發處理,一個用於將未用完的時間再返回到時間池中,大抵如此。
組調度和帶寬控制就先分析到此,下篇文章將分析CFS調度器了,敬請期待。



