
作者:友盟+數據技術專家 譚純 簡介: 2020年註定是不同尋常的,突如其來的疫情按下了人們生活的暫停鍵。對於用戶激增的App而言有喜有憂,如何快速沉澱數據資產,因為疫情是脈衝式的需求,等疫情結束之後,如何把這些激增的用戶轉化為留存是很大的挑戰。對於非利好的App,如何讓數據成為護城河。回答這兩個問 ...
作者:友盟+數據技術專家 譚純
簡介: 2020年註定是不同尋常的,突如其來的疫情按下了人們生活的暫停鍵。對於用戶激增的App而言有喜有憂,如何快速沉澱數據資產,因為疫情是脈衝式的需求,等疫情結束之後,如何把這些激增的用戶轉化為留存是很大的挑戰。對於非利好的App,如何讓數據成為護城河。回答這兩個問題,數據智能平臺的建設尤其重要。
背景
從友盟+公開的移動互聯網數據報告來看,疫情期間移動互聯網設備活躍度穩步提升。其中游戲行業增幅15%,是2019年的2倍;影視增幅8%,是去年的3倍左右;辦公通訊上漲明顯,增幅150%,網上藥店活躍設備增幅由負轉正,增幅61%;旅游與汽車的降幅是去年的3-4倍,分別下跌55%及29%。
疫情後的機會點:
1.拉新變留存。對於用戶激增的App而言有喜有憂,因為疫情是一個脈衝式的需求,等疫情結束之後,如何把這些激增的用戶轉化為留存是一個很大的挑戰。實時化的數據資產的沉澱成為挑戰。這時候需要修煉好數據的內功,重視數據資產的沉澱,運營好自己的私域數據池。
2.智能化運營。有的數據的底料,我們可以更加的進行精細化的一些運營。比如分層運營,智能營銷,實現業務的數據化,並且讓數據指導業務的發展提供前提。
3.練好數據的內功。建設數據智能平臺。數據也是資產,數據智能平臺的建設,好比把礦石煉成98號的汽油,再通過清潔的能源向業務不斷賦能的過程。
什麼是數據智能平臺
數據智能研發平臺,是基於數據基礎能力,打造專業、高效、安全的一站式智能研發平臺。支持實時與離線數據集成、開發運維、工作流調度、數據質量、數據安全的全鏈路數據管理,滿足數據治理、數據血緣、數據質量、安全管控,標簽應用的需求。
面臨的挑戰
挑戰主要集中在4個方面,從算力、數據、演算法以及業務:
- 基礎設施的建設不是一觸而就的,需要大量的人力物力財力。主要是機房、機架、網路、帶寬。
- 數據分成兩個部分,基礎數據以及標簽的數據,那麼基礎數據存在的問題是缺乏統一的建設標準以及質量的評估。我們知道歐盟有很多的成員國,成員國之前是各自發行貨幣的,不利於整體經濟的發展。數據也是一樣,需要同樣的標準去建設,促進數據的一個流通,這是基礎數據存在的問題。對於標簽數據而言,我們的生產管理服務應用整個鏈路是斷裂的,無法最大的提高一個標簽生產的效率。
- 演算法工程上,煙囪式的垂直類的一個開發,比如說廣告和搜索,它在特征到工程上面都是重覆開發的。
- 業務上,數據的建設周期比較長,趕不上業務的一個發展。
體系介紹
底料篇以友盟+為例。經過了9年專業的大數據的服務,積累下了PC網站的 APP的數據以及廣告監測類的數據。面臨的一個問題,如何把大體量的數據穩定高質量的同步到計算平臺,自研的一鍵的數據同步的工具,打通業務系統到大數據之間的元數據平臺,同時業務系統的增刪改也會通知到大數據測,
** 建設篇:**
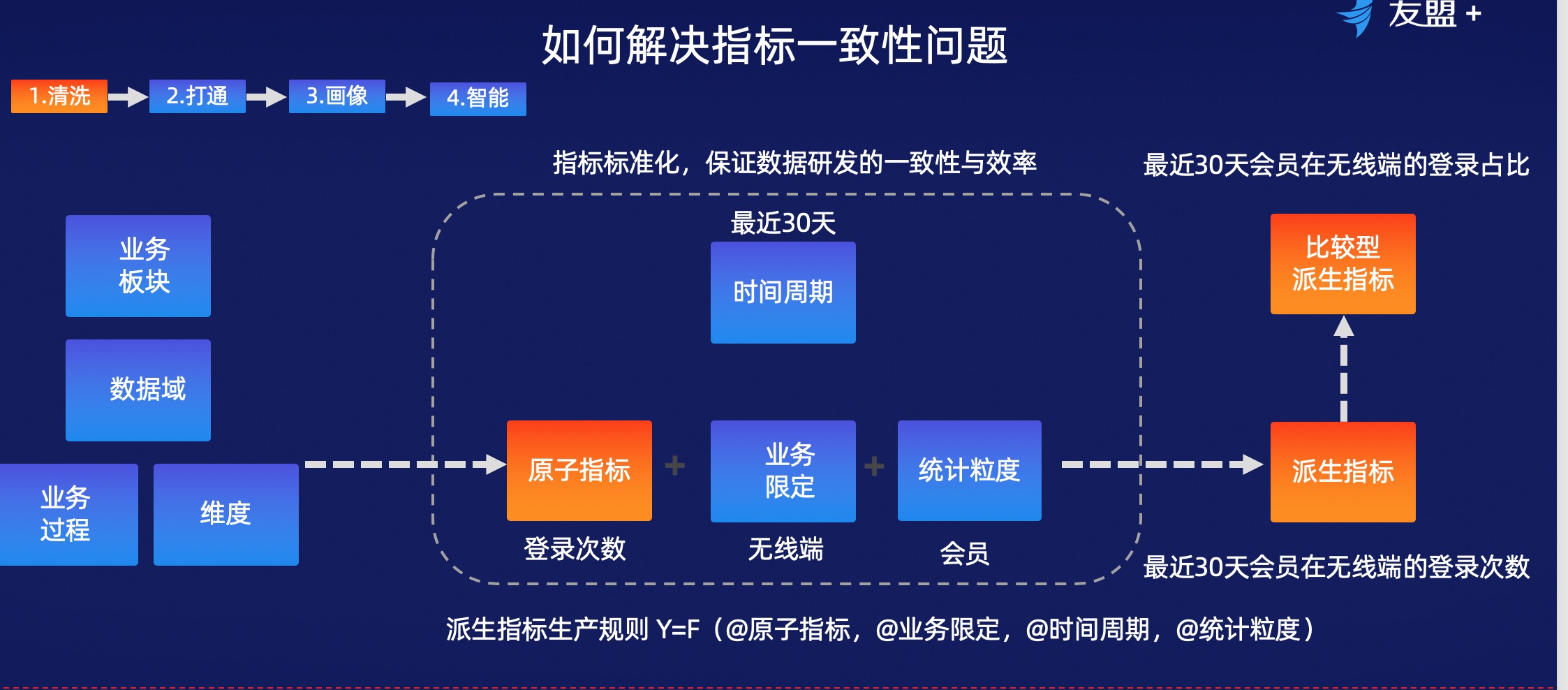
公共數據中心的建設,核心是為瞭解決指標一致性的問題
按業務域和分析維度構建公共數據中心。什麼叫業務板塊?比如亞馬遜,它是有電商和雲兩塊業務的,那麼這兩塊業務其實就是業務板塊,我們一個抽取電商業務來看,有日誌、交易、物流、廣告等最基礎的一些數據組成,這就叫做數據域。數據域是業務過程的集合,以交易為例,分付款,退拍下和退款,這三個業務過程共用的一個訂單ID,所以在一張事實表裡。交易的過程有維度刻畫,有商品、買家、賣家這些維度構成了維表,比如買家的昵稱、註冊的時間。維表冗餘在實時表中的好處是減少大數據量的join,保證數據的穩定高效的產出。通過建設可以讓由礦石變成92號的汽油,這個時候數據就可以被使用了,這是基礎數據建設的部分。
所有的運營產品、市場等業務的同學使用的數據全部叫做指標,這些指標全部是派生指標。跟大家一起拆解一個指標,叫最近30天會員在無線端的登錄次數,那麼最近30天就是時間周期,會員是統計粒度,統計粒度對應的最左邊的維度信息。無線端就是業務限定,登錄的次數就是原子指標。登錄次數加業務限定就等於上面圖表中最左邊的業務過程。那這個指標拆解的過程怎麼去映射到我們的技術數據,怎麼關聯呢?
再舉兩個例子。很多人可能簡單自學SQL後,就可以自己跑數據:通常情況下,SQL質量無法保證,如果查詢的數據量非常大,可能後臺幾千台機器就轉起來了。為避免類似情況發生,我們會在提交任務過程中做代碼校驗,對於性能問題、規範問題、代碼質量問題都會給出必要的提示,比如SQL代碼對於除數為0沒有做代碼相容,比如我們的DDL語句中沒有做數據生命周期的設置,比如SQL的QUERY中沒有做分區的條件限制,甚至你的SQL代碼別人已經計算過,可以復用結果不需要重新計算這些問題,我們都會給出精確到提示。
在數據研發過程中,代碼編寫可能只占工作量的20%,那麼大部分時間都去幹嗎了?是數據驗證,代碼修改前和代碼修改後,數據到底差多少,差在哪兒?過去如果沒有工具只能寫一堆腳本,再去驗證,效率極其低下,而且極易出錯。現在有了“數據對比”工具,就可以通過簡單的勾勾選選知道前後差異到底在哪?然後迅速給測試報告,保證整個研發過程的數據質量是有保障的。有了工具的建設,最後是運維。核心是要用最優的資源保障最重要的數據及時的產出。
標準化篇
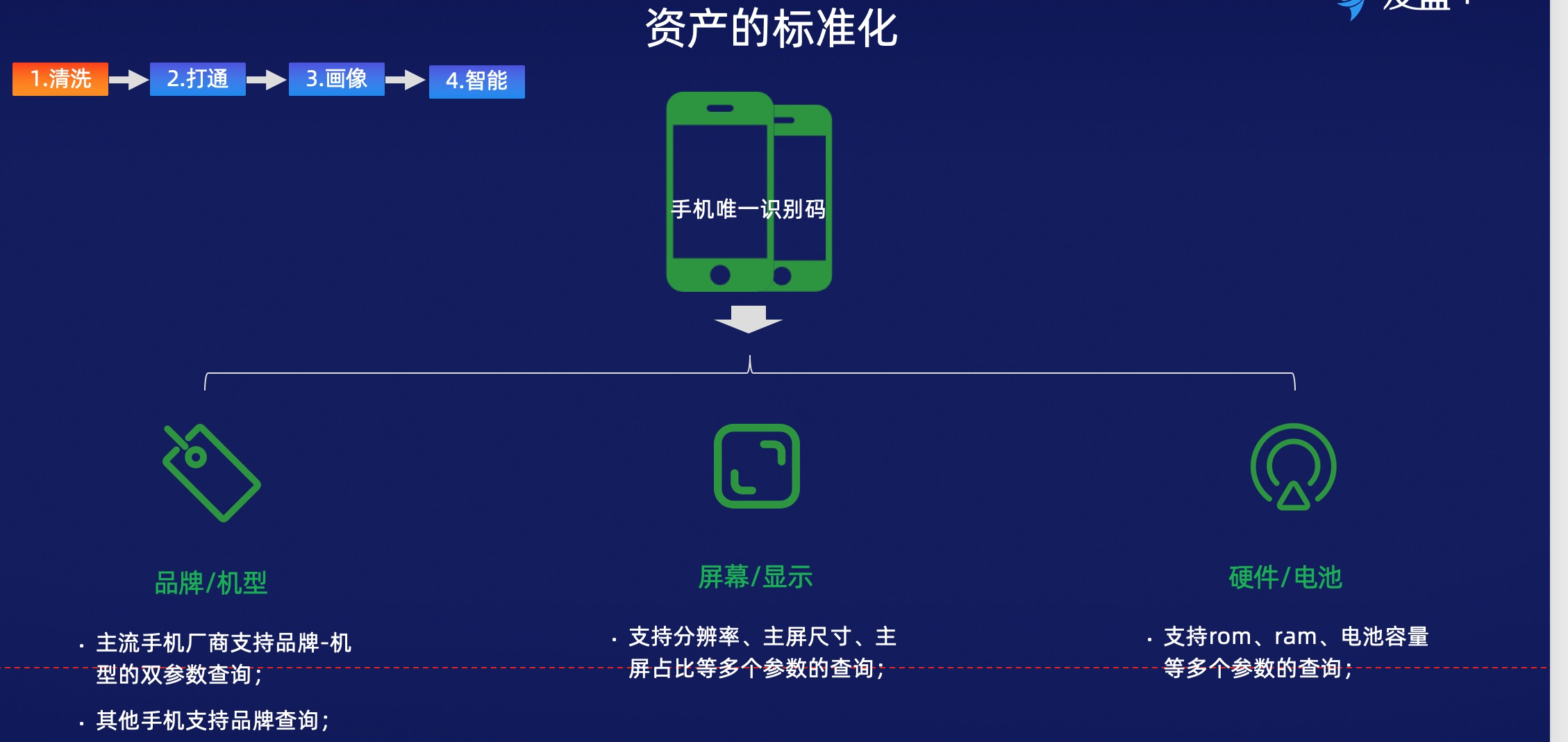
以IP to 地域為例,有閱讀類的App做本地的資訊,這個服務在市場上面是很普遍的,但準確度只能做到65%;再以游戲App為例,比如說品牌/機型代表購買力,屏幕/記憶體容量供開發者優化迭代產品。這些參數要是開發者去採集的話,會遇到特別多的問題,比如手機機型是0011X, 0011X代表iPhone11,那麼集合於這兩類的需求,這個時候就需要運用全域數據的能力,在高維的空間精準識別匹配信息。
反作弊篇
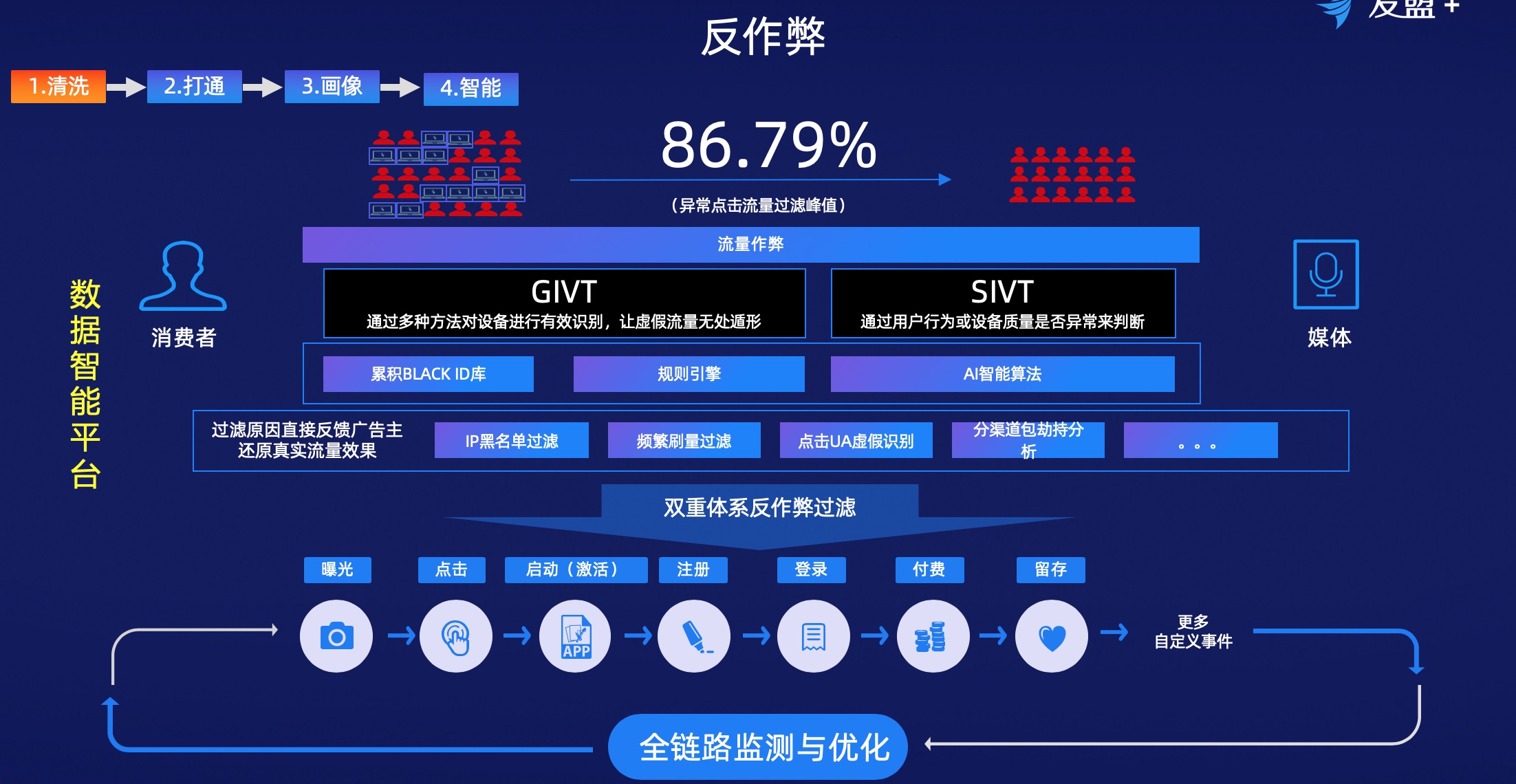
整個過程的反作弊怎麼做?比如有一款視頻類的App在做用戶分層,一共5層,大多數精細化運營同學都會這麼去做。第1層是超級用戶,第2層是黑產設備。作弊數據對標簽也是一種雜訊,對於簡單的機刷,用規則就可以識別出來。比如IP的黑名單庫,設備的黑名單庫。但是隨著這些技術的日新月異,對於模擬器而言,要採用機器學習的方式,從行為數據中加以判斷。還有種是“群控”,也就是羊毛黨。第3層--第5層分別是高質量、中質量和低質量。
規則,IP的黑名單庫,設備的黑名單庫。對於模擬器,採用機器學習的方式,從行為數據中加以判斷,對於群控羊毛黨採用圖演算法。多管齊下,濾掉86%的一個假量。
打通篇
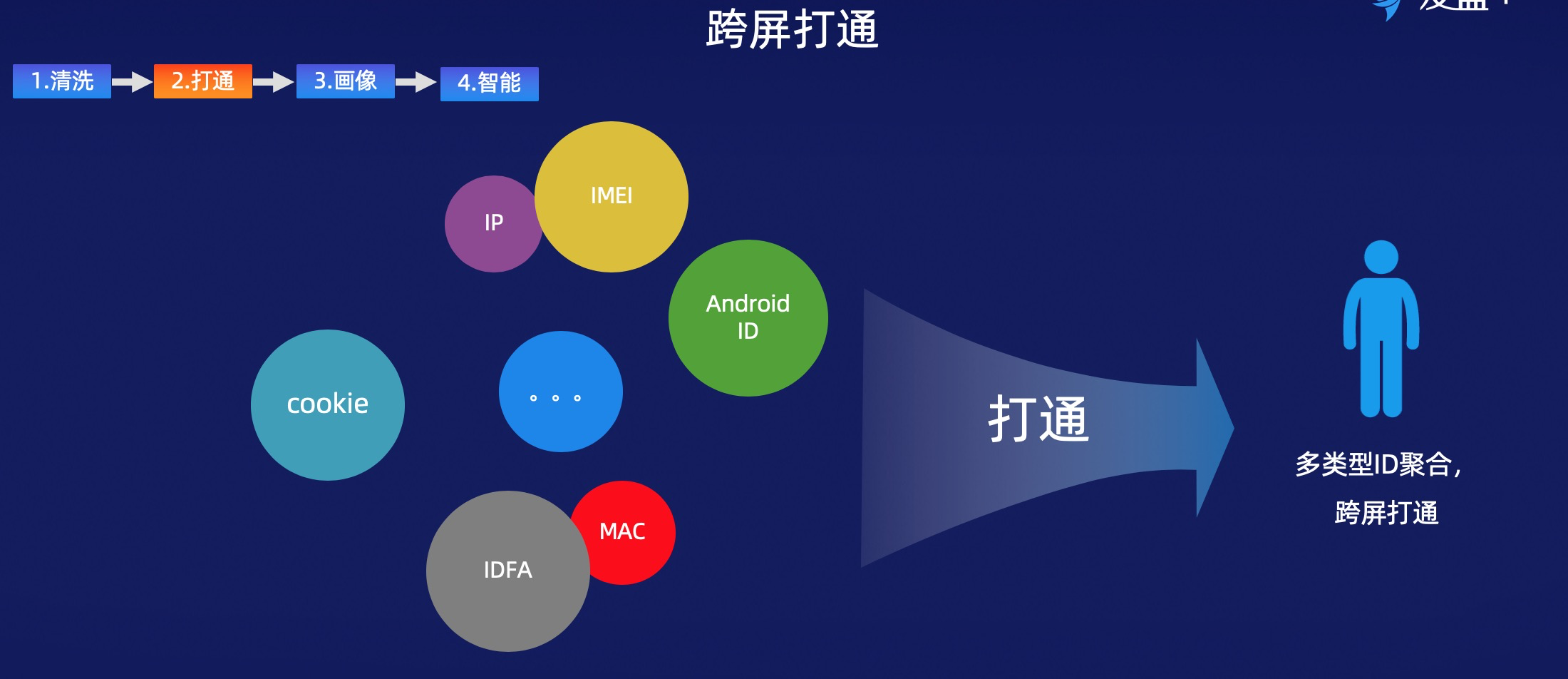
與此同時,互聯網和傳統行業一樣都會存在著數據的孤島,因為我們現在客戶的觸點是非常多的,比如說有傳統的PC網站,有App,有小程式。在跨端上面,比如兩個小程式,A上用戶少,成交率高;B上用戶多,成交率低,要進行跨端的數據的運營。有PC和無線數據,PC上面點了一個商品,App上把相應商品或者相應的文章來推薦給用戶,這樣來看用戶的留存將會得到極大的一個提升。設備聚合的主要場景是看小程式和App一共有多少用戶。
標簽篇
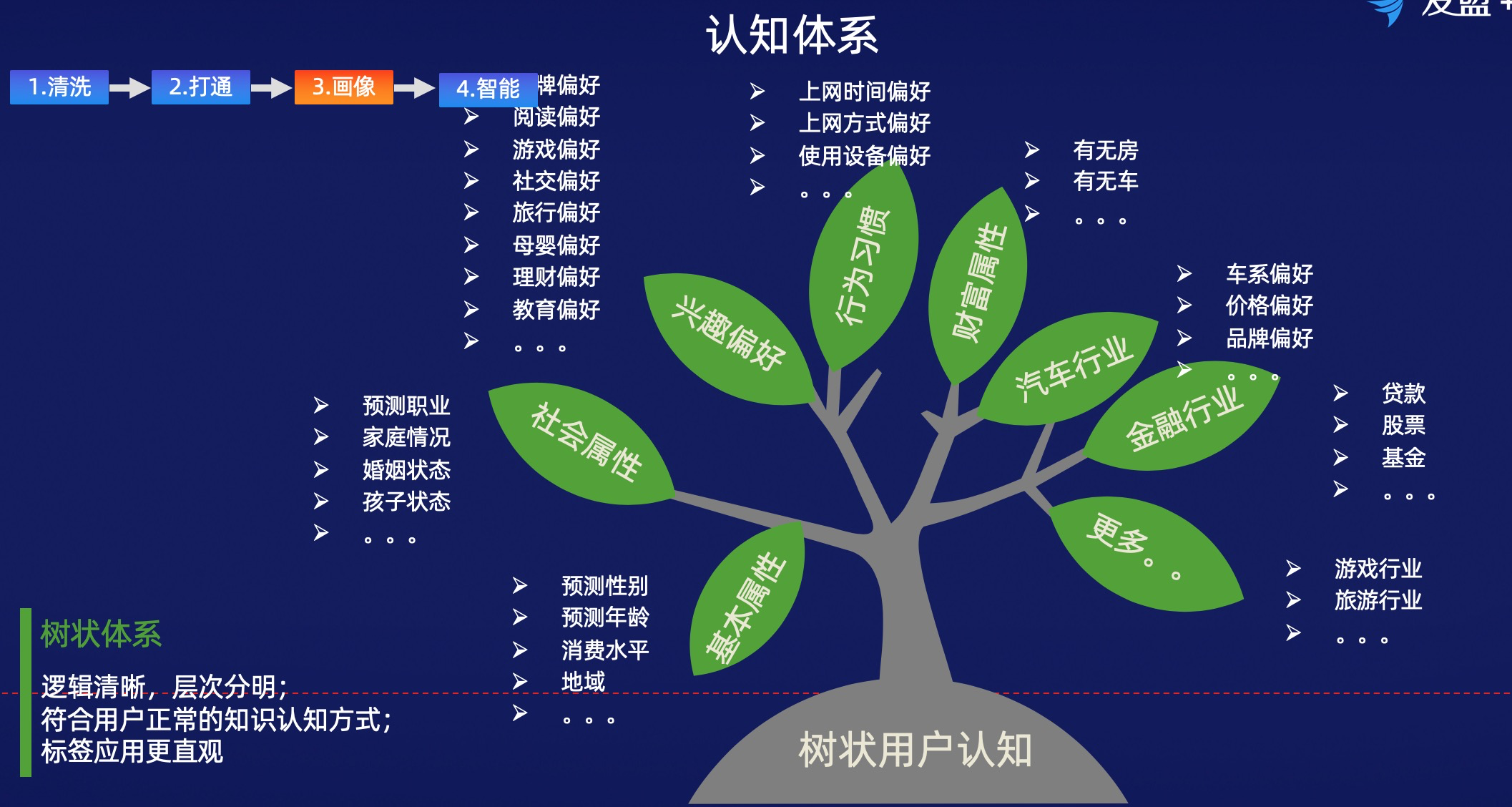
標簽是通過行為分析認知用戶的一個過程。是數據分析的一個起點,比如最近30天來過北京2次的人群,只要有業務價值,它就是一個標簽。標簽的分類,分有統計性和預測性,區別在統計型標簽不需要樣本集和準確度。那標簽有什麼作用呢?
一、市場細分和用戶分群:市場營銷領域的重要環節。比如在新品發佈時,定位目標用戶,切分市場。這是營銷研究公司會經常用的方式。
二、數據化運營和用戶分析。後臺PVUV留存等數據,如果能夠結合用戶畫像一起分析就會清晰很多,揭示數據趨勢背後的秘密。
三、精準營銷和定向投放。比如某產品新款上市,目標受眾是白領女性,在廣告投放前,就需要找到符合這一條件的用戶,進行定向廣告投放。四、各種數據應用:例如推薦系統、預測系統。我們認為:未來所有應用一定是個性化的,所有服務都是千人千面的。而個性化的服務,都需要基於對用戶的理解,前提就需要獲得用戶畫像。
常用的一些標簽體系(以下均為大數據預測結果):第一類:人口屬性。比如說性別、年齡、常駐地、籍貫,甚至是身高、血型,這些東西叫做人口屬性。
第二類:社會屬性。因為我們每個人在社會裡都不是一個單獨的個體,一定有關聯關係的,如婚戀狀態、受教育程度、資產情況、收入情況、職業,我們把這些叫做社會屬性。
第三類,興趣偏好。攝影、運動、吃貨、愛美、服飾、旅游、教育等,這部分是最常見的,也是最龐大的,難以一一列舉完。
第四類,意識認知。消費心理、消費動機、價值觀、生活態度、個性等,是內在的和最難獲取的。舉個例子,消費心理/動機。用戶購物是為了炫耀,還是追求品質,還是為了安全感,這些都是不一樣的。如何判斷標簽體系的好壞?
在實際構建標簽體系時,大家經常會遇到很多困惑,我列舉5個常見問題:
第一、怎樣的標簽體系才是正確的?其實每種體系各有千秋,要結合實際應用去評估。
第二、標簽體系需要很豐富麽?標簽是枚舉不完的,可以橫線延展、向下細分。也可以交叉分析,多維分析。如果沒有自動化的方式去挖掘,是很難做分析的,太多的標簽反而會帶來使用上的障礙。
第三、標簽體系需要保持穩定麽?不是完全必要,標簽體系就是產品/應用的一部分,要適應產品的發展,與時俱進。比如, “新冠”這個詞,今天卻很熱。我們是不是要增加一個標簽,分析哪些人有購買新冠相關的防疫藥品。 有一種情況下,標簽要保持穩定。如果你生產的標簽有下游模型訓練的依賴,即我們模型建完後,它的輸入是要保持穩定的,不能今天是ABC,明天是BCD。在這種情況下,是不能輕易對標簽體系做更改的。
第四個,樹狀結構or網狀結構?樹狀結構和網狀結構從名字上就可以看出其分別。網狀結構,更符合現實,但是層次關係很複雜,對數據的管理和存儲都有更高要求。知乎,如果仔細去看它的話題設置,其實是網狀的。
網狀的特點就是一個子話題,父級可以不止一個,可能有兩個。比如兒童玩具,既可以是母嬰下分分類,也可以是玩具下的分類,它就會存在兩個父節點之下。樹狀結構相對簡單,也是我們最常用的。網狀結構在一些特定場景下,我們也會去用。但是實現和維護的成本都比較高。比如,有一個節點是第四級的,但它的兩個父節點一個是二級,一個是三級,結構異化帶來處理上的麻煩。
第五個,何為一個好的標簽體系?應用為王,不忘初心。標簽是為了用的,並不是為了好玩,最好保證標簽體系的靈活和細緻性。
智能篇:
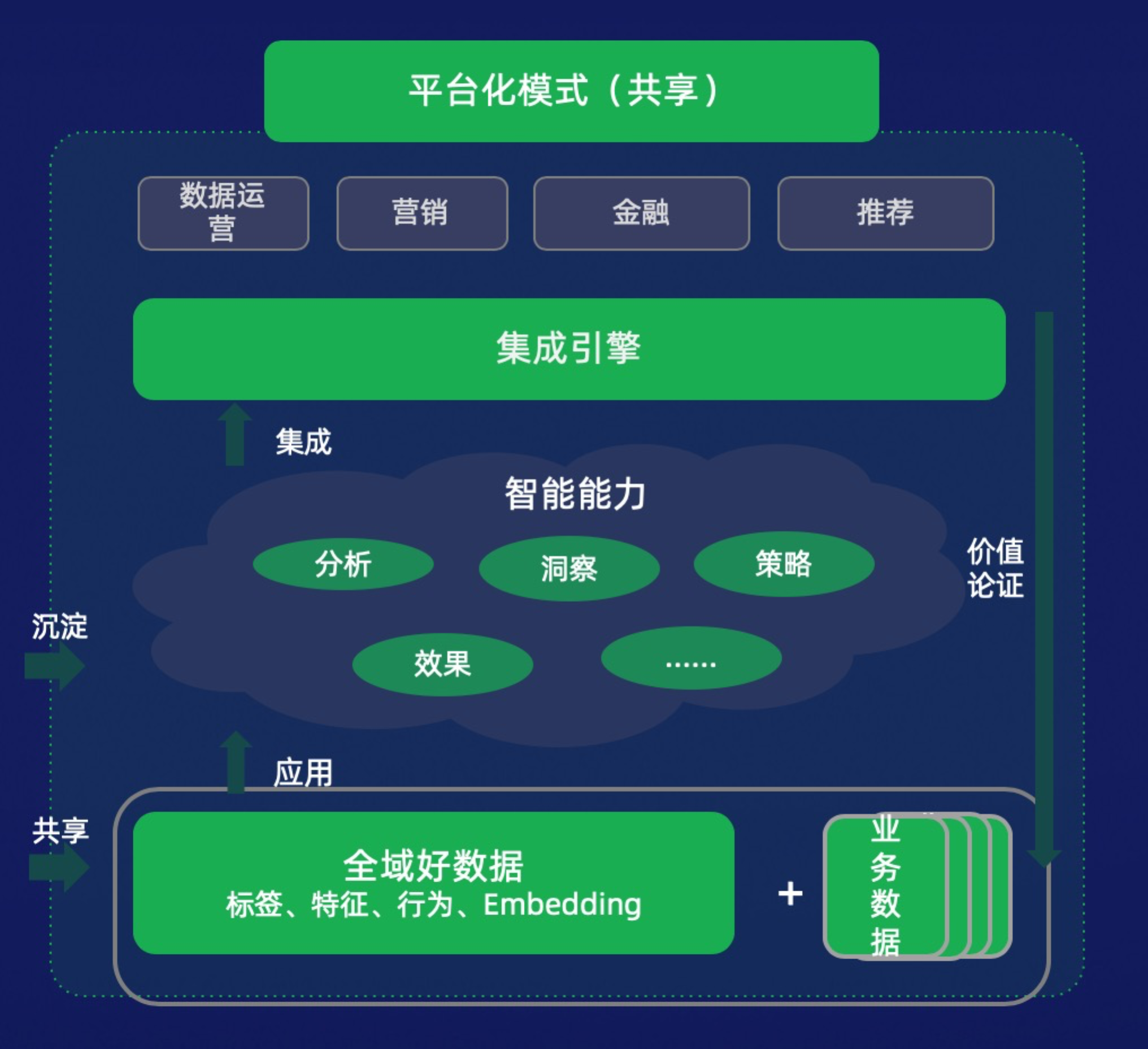
數據智能的建設指分析、洞察、策略、效果的工程化能力,有了這些智能的工程化能力,就能通過引擎向外暴露介面的方式來支持百花齊放的業務,支持所有開發者的業務,這就是友盟+採建管用一站式服務平臺的整個建設過程,開發者可以藉此為例,快速自建、或依靠友盟+的技術能力,豐富自己的數據智能平臺/數據銀行的建設。
規劃和感想
第一,快速建模的能力。實時自動的標簽產出,或者結合業務場景的實時化,能最大保障智能化運營的及時性;第二,不能只說這個用戶對汽車感興趣,而是需要細分到車型、價位,甚至他去買車時,會關註駕駛乘坐的舒適性、操控的靈活性,還是內飾的細節。


