
一 初識索引 為什麼要有索引? 一般的應用系統,讀寫比例在10:1左右,而且插入操作和一般的更新操作很少出現性能問題,在生產環境中,我們遇到最多的,也是最容易出問題的,還是一些複雜的查詢操作,因此對查詢語句的優化顯然是重中之重。說起加速查詢,就不得不提到索引了。 什麼是索引? 索引在MySQL中也叫 ...
一 初識索引
為什麼要有索引?
一般的應用系統,讀寫比例在10:1左右,而且插入操作和一般的更新操作很少出現性能問題,在生產環境中,我們遇到最多的,也是最容易出問題的,還是一些複雜的查詢操作,因此對查詢語句的優化顯然是重中之重。說起加速查詢,就不得不提到索引了。
什麼是索引?
索引在MySQL中也叫是一種“鍵”,是存儲引擎用於快速找到記錄的一種數據結構。索引對於良好的性能
非常關鍵,尤其是當表中的數據量越來越大時,索引對於性能的影響愈發重要。
索引優化應該是對查詢性能優化最有效的手段了。索引能夠輕易將查詢性能提高好幾個數量級。
索引相當於字典的音序表,如果要查某個字,如果不使用音序表,則需要從幾百頁中逐頁去查。
你是否對索引存在誤解?
索引是應用程式設計和開發的一個重要方面。若索引太多,應用程式的性能可能會受到影響。而索引太少,對查詢性能又會產生影響,要找到一個平衡點,這對應用程式的性能至關重要。一些開發人員總是在事後才想起添加索引----我一直認為,這源於一種錯誤的開發模式。如果知道數據的使用,從一開始就應該在需要處添加索引。開發人員往往對資料庫的使用停留在應用的層面,比如編寫SQL語句、存儲過程之類,他們甚至可能不知道索引的存在,或認為事後讓相關DBA加上即可。DBA往往不夠瞭解業務的數據流,而添加索引需要通過監控大量的SQL語句進而從中找到問題,這個步驟所需的時間肯定是遠大於初始添加索引所需的時間,並且可能會遺漏一部分的索引。當然索引也並不是越多越好,我曾經遇到過這樣一個問題:某台MySQL伺服器iostat顯示磁碟使用率一直處於100%,經過分析後發現是由於開發人員添加了太多的索引,在刪除一些不必要的索引之後,磁碟使用率馬上下降為20%。可見索引的添加也是非常有技術含量的。
二 索引的原理
一 索引原理
索引的目的在於提高查詢效率,與我們查閱圖書所用的目錄是一個道理:先定位到章,然後定位到該章下的一個小節,然後找到頁數。相似的例子還有:查字典,查火車車次,飛機航班等
本質都是:通過不斷地縮小想要獲取數據的範圍來篩選出最終想要的結果,同時把隨機的事件變成順序的事件,也就是說,有了這種索引機制,我們可以總是用同一種查找方式來鎖定數據。
資料庫也是一樣,但顯然要複雜的多,因為不僅面臨著等值查詢,還有範圍查詢(>、<、between、in)、模糊查詢(like)、並集查詢(or)等等。資料庫應該選擇怎麼樣的方式來應對所有的問題呢?我們回想字典的例子,能不能把數據分成段,然後分段查詢呢?最簡單的如果1000條數據,1到100分成第一段,101到200分成第二段,201到300分成第三段......這樣查第250條數據,只要找第三段就可以了,一下子去除了90%的無效數據。但如果是1千萬的記錄呢,分成幾段比較好?稍有演算法基礎的同學會想到搜索樹,其平均複雜度是lgN,具有不錯的查詢性能。但這裡我們忽略了一個關鍵的問題,複雜度模型是基於每次相同的操作成本來考慮的。而資料庫實現比較複雜,一方面數據是保存在磁碟上的,另外一方面為了提高性能,每次又可以把部分數據讀入記憶體來計算,因為我們知道訪問磁碟的成本大概是訪問記憶體的十萬倍左右,所以簡單的搜索樹難以滿足複雜的應用場景。
二 磁碟IO與預讀
前面提到了訪問磁碟,那麼這裡先簡單介紹一下磁碟IO和預讀,磁碟讀取數據靠的是機械運動,每次讀取數據花費的時間可以分為尋道時間、旋轉延遲、傳輸時間三個部分,尋道時間指的是磁臂移動到指定磁軌所需要的時間,主流磁碟一般在5ms以下;旋轉延遲就是我們經常聽說的磁碟轉速,比如一個磁碟7200轉,表示每分鐘能轉7200次,也就是說1秒鐘能轉120次,旋轉延遲就是1/120/2 = 4.17ms;傳輸時間指的是從磁碟讀出或將數據寫入磁碟的時間,一般在零點幾毫秒,相對於前兩個時間可以忽略不計。那麼訪問一次磁碟的時間,即一次磁碟IO的時間約等於5+4.17 = 9ms左右,聽起來還挺不錯的,但要知道一臺500 -MIPS(Million Instructions Per Second)的機器每秒可以執行5億條指令,因為指令依靠的是電的性質,換句話說執行一次IO的時間可以執行約450萬條指令,資料庫動輒十萬百萬乃至千萬級數據,每次9毫秒的時間,顯然是個災難。下圖是電腦硬體延遲的對比圖,供大家參考:

考慮到磁碟IO是非常高昂的操作,電腦操作系統做了一些優化,當一次IO時,不光把當前磁碟地址的數據,而是把相鄰的數據也都讀取到記憶體緩衝區內,因為局部預讀性原理告訴我們,當電腦訪問一個地址的數據的時候,與其相鄰的數據也會很快被訪問到。每一次IO讀取的數據我們稱之為一頁(page)。具體一頁有多大數據跟操作系統有關,一般為4k或8k,也就是我們讀取一頁內的數據時候,實際上才發生了一次IO,這個理論對於索引的數據結構設計非常有幫助。
三 索引的數據結構
樹
樹狀圖是一種數據結構,它是由n(n>=1)個有限結點組成一個具有層次關係的集合。把它叫做“樹”是因為它看起來像一棵倒掛的樹,也就是說它是根朝上,而葉朝下的。 它具有以下的特點:每個結點有零個或多個子結點;沒有父結點的結點稱為根結點;每一個非根結點有且只有一個父結點;除了根結點外,每個子結點可以分為多個不相交的子樹 根結點 : A
父節點 : A是B,C的父節點
葉子節點:D,E是葉子節點
樹的深度/樹的高度:高度為3
根結點 : A
父節點 : A是B,C的父節點
葉子節點:D,E是葉子節點
樹的深度/樹的高度:高度為3
B+樹
前面講了索引的基本原理,資料庫的複雜性,又講了操作系統的相關知識,目的就是讓大家瞭解,任何一種數據結構都不是憑空產生的,一定會有它的背景和使用場景,我們現在總結一下,我們需要這種數據結構能夠做些什麼,其實很簡單,那就是:每次查找數據時把磁碟IO次數控制在一個很小的數量級,最好是常數數量級。那麼我們就想到如果一個高度可控的多路搜索樹是否能滿足需求呢?就這樣,b+樹應運而生(B+樹是通過二叉查找樹,再由平衡二叉樹,B樹演化而來)。

###b+樹性質
1.索引欄位要儘量的小:通過上面的分析,我們知道IO次數取決於b+數的高度h,假設當前數據表的數據為N,每個磁碟塊的數據項的數量是m,則有h=㏒(m+1)N,當數據量N一定的情況下,m越大,h越小;而m = 磁碟塊的大小 / 數據項的大小,磁碟塊的大小也就是一個數據頁的大小,是固定的,如果數據項占的空間越小,數據項的數量越多,樹的高度越低。這就是為什麼每個數據項,即索引欄位要儘量的小,比如int占4位元組,要比bigint8位元組少一半。這也是為什麼b+樹要求把真實的數據放到葉子節點而不是內層節點,一旦放到內層節點,磁碟塊的數據項會大幅度下降,導致樹增高。當數據項等於1時將會退化成線性表。
2.索引的最左匹配特性:當b+樹的數據項是複合的數據結構,比如(name,age,sex)的時候,b+數是按照從左到右的順序來建立搜索樹的,比如當(張三,20,F)這樣的數據來檢索的時候,b+樹會優先比較name來確定下一步的所搜方向,如果name相同再依次比較age和sex,最後得到檢索的數據;但當(20,F)這樣的沒有name的數據來的時候,b+樹就不知道下一步該查哪個節點,因為建立搜索樹的時候name就是第一個比較因數,必須要先根據name來搜索才能知道下一步去哪裡查詢。比如當(張三,F)這樣的數據來檢索時,b+樹可以用name來指定搜索方向,但下一個欄位age的缺失,所以只能把名字等於張三的數據都找到,然後再匹配性別是F的數據了, 這個是非常重要的性質,即索引的最左匹配特性。
四 聚集索引與輔助索引
在資料庫中,B+樹的高度一般都在2~4層,這也就是說查找某一個鍵值的行記錄時最多只需要2到4次IO,這倒不錯。因為當前一般的機械硬碟每秒至少可以做100次IO,2~4次的IO意味著查詢時間只需要0.02~0.04秒。
資料庫中的B+樹索引可以分為聚集索引(clustered index)和輔助索引(secondary index),
聚集索引與輔助索引相同的是:不管是聚集索引還是輔助索引,其內部都是B+樹的形式,即高度是平衡的,葉子結點存放著所有的數據。
聚集索引與輔助索引不同的是:葉子結點存放的是否是一整行的信息
1、聚集索引

#InnoDB存儲引擎表是索引組織表,即表中數據按照主鍵順序存放。
而聚集索引(clustered index)就是按照每張表的主鍵構造一棵B+樹,同時葉子結點存放的即為整張表的行記錄數據,也將聚集索引的葉子結點稱為數據頁。
聚集索引的這個特性決定了索引組織表中數據也是索引的一部分。同B+樹數據結構一樣,每個數據頁都通過一個雙向鏈表來進行鏈接。 #如果未定義主鍵,MySQL取第一個唯一索引(unique)而且只含非空列(NOT NULL)作為主鍵,InnoDB使用它作為聚簇索引。 #如果沒有這樣的列,InnoDB就自己產生一個這樣的ID值,它有六個位元組,而且是隱藏的,使其作為聚簇索引。 #由於實際的數據頁只能按照一棵B+樹進行排序,因此每張表只能擁有一個聚集索引。
在多數情況下,查詢優化器傾向於採用聚集索引。因為聚集索引能夠在B+樹索引的葉子節點上直接找到數據。
此外由於定義了數據的邏輯順序,聚集索引能夠特別快地訪問針對範圍值得查詢。

聚集索引的好處之一:它對主鍵的排序查找和範圍查找速度非常快,葉子節點的數據就是用戶所要查詢的數據。如用戶需要查找一張表,查詢最後的10位用戶信息,由於B+樹索引是雙向鏈表,所以用戶可以快速找到最後一個數據頁,並取出10條記錄


#參照第六小結測試索引的準備階段來創建出表s1 mysql> desc s1; #最開始沒有主鍵 +--------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +--------+-------------+------+-----+---------+-------+ | id | int(11) | NO | | NULL | | | name | varchar(20) | YES | | NULL | | | gender | char(6) | YES | | NULL | | | email | varchar(50) | YES | | NULL | | +--------+-------------+------+-----+---------+-------+ rows in set (0.00 sec) mysql> explain select * from s1 order by id desc limit 10; #Using filesort,需要二次排序 +----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+----------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+----------------+ | 1 | SIMPLE | s1 | NULL | ALL | NULL | NULL | NULL | NULL | 2633472 | 100.00 | Using filesort | +----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+----------------+ row in set, 1 warning (0.11 sec) mysql> alter table s1 add primary key(id); #添加主鍵 Query OK, 0 rows affected (13.37 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> explain select * from s1 order by id desc limit 10; #基於主鍵的聚集索引在創建完畢後就已經完成了排序,無需二次排序 +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------+ | 1 | SIMPLE | s1 | NULL | index | NULL | PRIMARY | 4 | NULL | 10 | 100.00 | NULL | +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------+ row in set, 1 warning (0.04 sec)View Code
聚集索引的好處之二:範圍查詢(range query),即如果要查找主鍵某一範圍內的數據,通過葉子節點的上層中間節點就可以得到頁的範圍,之後直接讀取數據頁即可
mysql> alter table s1 drop primary key; Query OK, 2699998 rows affected (24.23 sec) Records: 2699998 Duplicates: 0 Warnings: 0 mysql> desc s1; +--------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +--------+-------------+------+-----+---------+-------+ | id | int(11) | NO | | NULL | | | name | varchar(20) | YES | | NULL | | | gender | char(6) | YES | | NULL | | | email | varchar(50) | YES | | NULL | | +--------+-------------+------+-----+---------+-------+ rows in set (0.12 sec) mysql> explain select * from s1 where id > 1 and id < 1000000; #沒有聚集索引,預估需要檢索的rows數如下 +----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+ | 1 | SIMPLE | s1 | NULL | ALL | NULL | NULL | NULL | NULL | 2690100 | 11.11 | Using where | +----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+ row in set, 1 warning (0.00 sec) mysql> alter table s1 add primary key(id); Query OK, 0 rows affected (16.25 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> explain select * from s1 where id > 1 and id < 1000000; #有聚集索引,預估需要檢索的rows數如下 +----+-------------+-------+------------+-------+---------------+---------+---------+------+---------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+---------+---------+------+---------+----------+-------------+ | 1 | SIMPLE | s1 | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 1343355 | 100.00 | Using where | +----+-------------+-------+------------+-------+---------------+---------+---------+------+---------+----------+-------------+ row in set, 1 warning (0.09 sec)View Code
2、輔助索引
表中除了聚集索引外其他索引都是輔助索引(Secondary Index,也稱為非聚集索引),與聚集索引的區別是:輔助索引的葉子節點不包含行記錄的全部數據。
葉子節點除了包含鍵值以外,每個葉子節點中的索引行中還包含一個書簽(bookmark)。該書簽用來告訴InnoDB存儲引擎去哪裡可以找到與索引相對應的行數據。
由於InnoDB存儲引擎是索引組織表,因此InnoDB存儲引擎的輔助索引的書簽就是相應行數據的聚集索引鍵。如下圖

輔助索引的存在並不影響數據在聚集索引中的組織,因此每張表上可以有多個輔助索引,但只能有一個聚集索引。當通過輔助索引來尋找數據時,InnoDB存儲引擎會遍歷輔助索引並通過葉子級別的指針獲得只想主鍵索引的主鍵,然後再通過主鍵索引來找到一個完整的行記錄。
舉例來說,如果在一棵高度為3的輔助索引樹種查找數據,那需要對這個輔助索引樹遍歷3次找到指定主鍵,如果聚集索引樹的高度同樣為3,那麼還需要對聚集索引樹進行3次查找,最終找到一個完整的行數據所在的頁,因此一共需要6次邏輯IO訪問才能得到最終的一個數據頁。

聚集索引 1.紀錄的索引順序與無力順序相同 因此更適合between and和order by操作 2.葉子結點直接對應數據 從中間級的索引頁的索引行直接對應數據頁 3.每張表只能創建一個聚集索引 非聚集索引 1.索引順序和物理順序無關 2.葉子結點不直接指向數據頁 3.每張表可以有多個非聚集索引,需要更多磁碟和內容 多個索引會影響insert和update的速度聚集索引和非聚集索引的區別
五 MySQL索引管理
一 功能
#1. 索引的功能就是加速查找 #2. mysql中的primary key,unique,聯合唯一也都是索引,這些索引除了加速查找以外,還有約束的功能
二 MySQL常用的索引
普通索引INDEX:加速查找 唯一索引: -主鍵索引PRIMARY KEY:加速查找+約束(不為空、不能重覆) -唯一索引UNIQUE:加速查找+約束(不能重覆) 聯合索引: -PRIMARY KEY(id,name):聯合主鍵索引 -UNIQUE(id,name):聯合唯一索引 -INDEX(id,name):聯合普通索引
舉個例子來說,比如你在為某商場做一個會員卡的系統。 這個系統有一個會員表 有下列欄位: 會員編號 INT 會員姓名 VARCHAR(10) 會員身份證號碼 VARCHAR(18) 會員電話 VARCHAR(10) 會員住址 VARCHAR(50) 會員備註信息 TEXT 那麼這個 會員編號,作為主鍵,使用 PRIMARY 會員姓名 如果要建索引的話,那麼就是普通的 INDEX 會員身份證號碼 如果要建索引的話,那麼可以選擇 UNIQUE (唯一的,不允許重覆) #除此之外還有全文索引,即FULLTEXT 會員備註信息 , 如果需要建索引的話,可以選擇全文搜索。 用於搜索很長一篇文章的時候,效果最好。 用在比較短的文本,如果就一兩行字的,普通的 INDEX 也可以。 但其實對於全文搜索,我們並不會使用MySQL自帶的該索引,而是會選擇第三方軟體如Sphinx,專門來做全文搜索。 #其他的如空間索引SPATIAL,瞭解即可,幾乎不用 各個索引的應用場景各個索引的應用場景
三 索引的兩大類型hash與btree
#我們可以在創建上述索引的時候,為其指定索引類型,分兩類 hash類型的索引:查詢單條快,範圍查詢慢 btree類型的索引:b+樹,層數越多,數據量指數級增長(我們就用它,因為innodb預設支持它) #不同的存儲引擎支持的索引類型也不一樣 InnoDB 支持事務,支持行級別鎖定,支持 B-tree、Full-text 等索引,不支持 Hash 索引; MyISAM 不支持事務,支持表級別鎖定,支持 B-tree、Full-text 等索引,不支持 Hash 索引; Memory 不支持事務,支持表級別鎖定,支持 B-tree、Hash 等索引,不支持 Full-text 索引; NDB 支持事務,支持行級別鎖定,支持 Hash 索引,不支持 B-tree、Full-text 等索引; Archive 不支持事務,支持表級別鎖定,不支持 B-tree、Hash、Full-text 等索引;
四 創建/刪除索引的語法
#方法一:創建表時 CREATE TABLE 表名 ( 欄位名1 數據類型 [完整性約束條件…], 欄位名2 數據類型 [完整性約束條件…], [UNIQUE | FULLTEXT | SPATIAL ] INDEX | KEY [索引名] (欄位名[(長度)] [ASC |DESC]) ); #方法二:CREATE在已存在的表上創建索引 CREATE [UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名 ON 表名 (欄位名[(長度)] [ASC |DESC]) ; #方法三:ALTER TABLE在已存在的表上創建索引 ALTER TABLE 表名 ADD [UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名 (欄位名[(長度)] [ASC |DESC]) ; #刪除索引:DROP INDEX 索引名 ON 表名字;
#方式一 create table t1( id int, name char, age int, sex enum('male','female'), unique key uni_id(id), index ix_name(name) #index沒有key ); create table t1( id int, name char, age int, sex enum('male','female'), unique key uni_id(id), index(name) #index沒有key ); #方式二 create index ix_age on t1(age); #方式三 alter table t1 add index ix_sex(sex); alter table t1 add index(sex); #查看 mysql> show create table t1; | t1 | CREATE TABLE `t1` ( `id` int(11) DEFAULT NULL, `name` char(1) DEFAULT NULL, `age` int(11) DEFAULT NULL, `sex` enum('male','female') DEFAULT NULL, UNIQUE KEY `uni_id` (`id`), KEY `ix_name` (`name`), KEY `ix_age` (`age`), KEY `ix_sex` (`sex`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1示範
六 測試索引
一 準備
#1. 準備表 create table s1( id int, name varchar(20), gender char(6), email varchar(50) ); #2. 創建存儲過程,實現批量插入記錄 delimiter $$ #聲明存儲過程的結束符號為$$ create procedure auto_insert1() BEGIN declare i int default 1; while(i<3000000)do insert into s1 values(i,'eva','female',concat('eva',i,'@oldboy')); set i=i+1; end while; END$$ #$$結束 delimiter ; #重新聲明分號為結束符號 #3. 查看存儲過程 show create procedure auto_insert1\G #4. 調用存儲過程 call auto_insert1();數據準備
二 在沒有索引的前提下測試查詢速度
#無索引:mysql根本就不知道到底是否存在id等於333333333的記錄,只能把數據表從頭到尾掃描一遍,此時有多少個磁碟塊就需要進行多少IO操作,所以查詢速度很慢 mysql> select * from s1 where id=333333333; Empty set (0.33 sec)
三 在表中已經存在大量數據的前提下,為某個欄位段建立索引,建立速度會很慢

四 在索引建立完畢後,以該欄位為查詢條件時,查詢速度提升明顯
![]()
PS:
1. mysql先去索引表裡根據b+樹的搜索原理很快搜索到id等於333333333的記錄不存在,IO大大降低,因而速度明顯提升
2. 我們可以去mysql的data目錄下找到該表,可以看到占用的硬碟空間多了
3. 需要註意,如下圖

五 總結
#1. 一定是為搜索條件的欄位創建索引,比如select * from s1 where id = 333;就需要為id加上索引 #2. 在表中已經有大量數據的情況下,建索引會很慢,且占用硬碟空間,建完後查詢速度加快 比如create index idx on s1(id);會掃描表中所有的數據,然後以id為數據項,創建索引結構,存放於硬碟的表中。 建完以後,再查詢就會很快了。 #3. 需要註意的是:innodb表的索引會存放於s1.ibd文件中,而myisam表的索引則會有單獨的索引文件table1.MYI MySAM索引文件和數據文件是分離的,索引文件僅保存數據記錄的地址。而在innodb中,表數據文件本身就是按照B+Tree(BTree即Balance True)組織的一個索引結構,這棵樹的葉節點data域保存了完整的數據記錄。這個索引的key是數據表的主鍵,因此innodb表數據文件本身就是主索引。 因為inndob的數據文件要按照主鍵聚集,所以innodb要求表必須要有主鍵(Myisam可以沒有),如果沒有顯式定義,則mysql系統會自動選擇一個可以唯一標識數據記錄的列作為主鍵,如果不存在這種列,則mysql會自動為innodb表生成一個隱含欄位作為主鍵,這欄位的長度為6個位元組,類型為長整型.
七 正確使用索引
一 索引未命中
並不是說我們創建了索引就一定會加快查詢速度,若想利用索引達到預想的提高查詢速度的效果,我們在添加索引時,必須遵循以下問題
1 範圍問題,或者說條件不明確,條件中出現這些符號或關鍵字:>、>=、<、<=、!= 、between...and...、like、
大於號、小於號

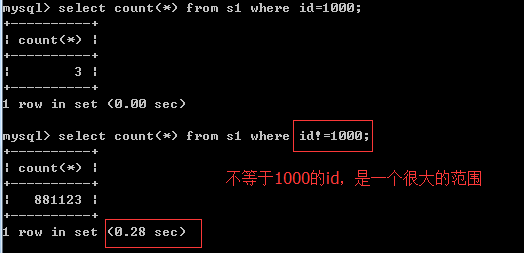
不等於!=
between ...and...

like

2 儘量選擇區分度高的列作為索引,區分度的公式是count(distinct col)/count(*),表示欄位不重覆的比例,比例越大我們掃描的記錄數越少,唯一鍵的區分度是1,而一些狀態、性別欄位可能在大數據面前區分度就是0,那可能有人會問,這個比例有什麼經驗值嗎?使用場景不同,這個值也很難確定,一般需要join的欄位我們都要求是0.1以上,即平均1條掃描10條記錄


