[TOC] 下麵介紹pandas常見的基本功能,和python的基本數據類型進行比較可以看到pandas在操作大型數據集中的優勢。 1.重建索引 (1)函數:reindex (2)作用:創建一個符合新索引的新對象。 (3)內容: Series調用reindex方法時,會將數組按照新的索引進行排列,如 ...
目錄
下麵介紹pandas常見的基本功能,和python的基本數據類型進行比較可以看到pandas在操作大型數據集中的優勢。
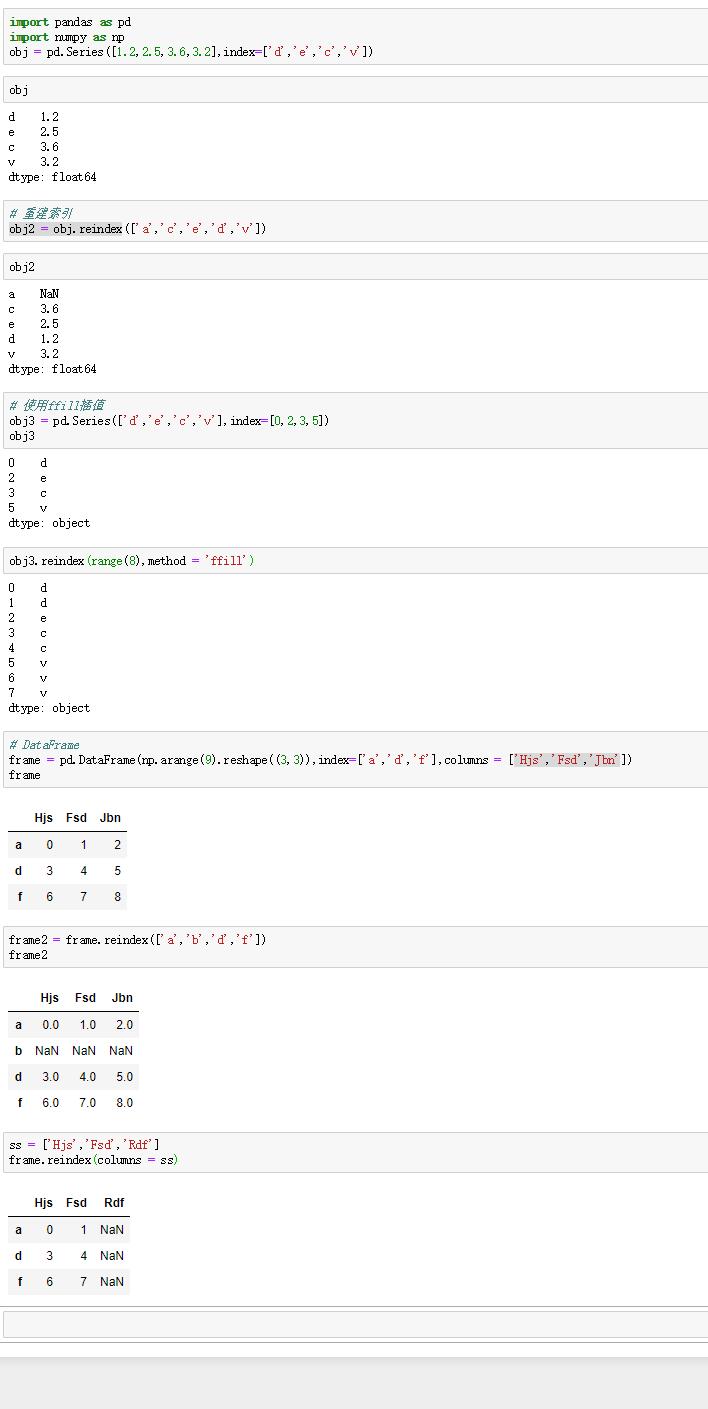
1.重建索引
(1)函數:reindex
(2)作用:創建一個符合新索引的新對象。
(3)內容:
Series調用reindex方法時,會將數組按照新的索引進行排列,如果之前並不存在,則會引入缺失值NaN。
DataFrame調用reindex方法時,會改變行和列索引。只傳入一個序列時,行會重建索引;傳入columns關鍵字參數時,列會重建索引。
(4)重要參數:ffill
作用:重建索引時插值,按順序把沒有數據的標簽補充數據。
(5)實例
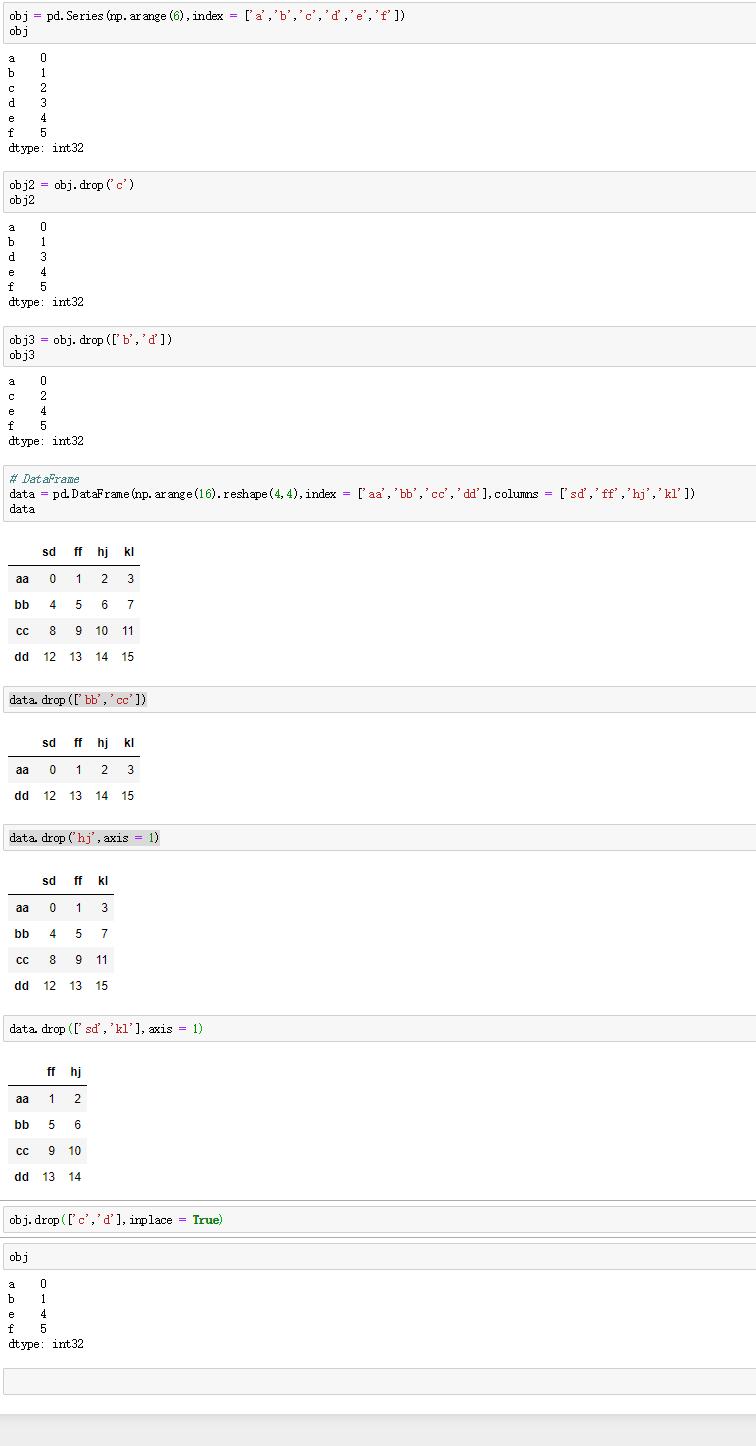
2.軸向上刪除條目
(1)函數:drop
(2)作用:在軸向上刪除一個或更多的條目。
(3)內容:
返回一個含有指示值或軸向上刪除值的新對象。
Series調用drop方法時,把字元串或者字元串序列列表當作參數傳入並返回對象。
DataFrame調用drop方法時,傳入字元串序列列表會根據行標簽刪除值(軸0),傳入axis=1或者axis='columns'會根據列標簽刪除值。
(4)重要參數:inplace
作用:清除被刪除的數據,並返回刪除後的數據。
(5)實例
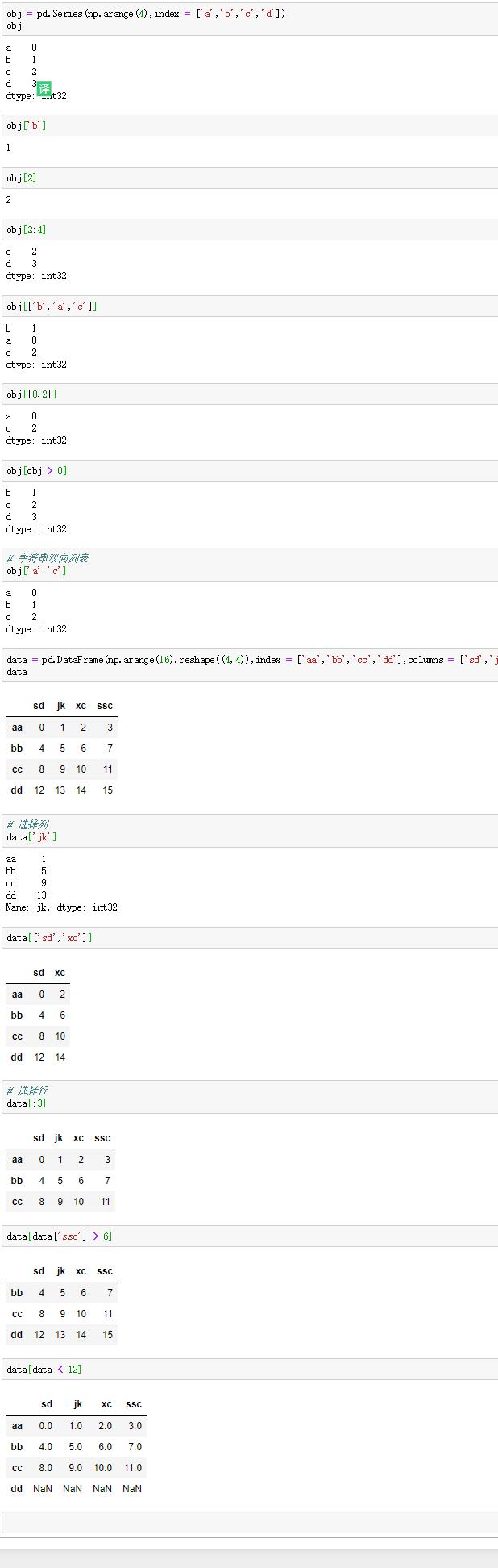
3.索引,選擇與過濾
(1)索引
Series的索引可以不只是整數,也可以是小數,字元串,切片,字元串索引列表,布爾值索引。還可以是字元串雙向切片。
DataFrame的索引可以是字元串,字元串索引列表選擇列,切片和布爾值索引選擇行。