
✍寫在前面 : 歡迎加入純乾貨技術交流群Disaster Army:317784952 接到5月25日之前要交稿的任務我就一門心思想寫一篇爬蟲入門的文章,可是我並不會。還好有將近一個月的時間去學習,於是我每天鑽在書和視頻教程里。其實並不難的,我只是想做到能夠很好的理解它並用自己的語言較好的表達出來, ...

✍寫在前面:
歡迎加入純乾貨技術交流群Disaster Army:317784952
接到5月25日之前要交稿的任務我就一門心思想寫一篇爬蟲入門的文章,可是我並不會。還好有將近一個月的時間去學習,於是我每天鑽在書和視頻教程里。其實並不難的,我只是想做到能夠很好的理解它並用自己的語言較好的表達出來,也許你將看到的是史上最不專業的技術交流文章,沒錯這就是我想要的。我力求能讓沒有編程基礎同我一樣愛黑客技術卻苦於看不到出路的同學們在24小時之內明白爬蟲是怎麼一回事。我想這才是我加入中國紅客聯盟太極實驗室在紅客精神的號召下做的有意義的事。學習技術一定要學會付出、開源、共用、互助,很多大牛似乎不願意這麼做了,我們入門小菜鳥只要夠團結,樂於奉獻就一定可以達到1+1>2的雙贏效果。總之共同努力吧!
☝第一章
0x00 python的認識、安裝
官面上的話自行去百度,這裡我只介紹我所掌握到的、最重要的信息。
特點:
(1)跨平臺開發
(2)以語法簡潔清晰著稱
(3)縮進控制嚴格
至於說爬蟲需不需要編程基礎,不用多說,君不見本屌在這個月之前的n多個月里是多麼苦苦的啃教程,對麽下三賴的求指點。其實自學的進步速度太慢了,此文也希望看到的碼闊多多提點!
更多信息:
安裝也是極易的,只是有python2.7和python3需要糾結選一下。菜菜也不多做建議了,各有所長,python是任性的,不顧及老用戶感受強行不相容更代,足以見得其魄力和自信。2.7的用戶較多一點,初學者想用大神的exp不得已會選擇它,3的用戶逐日增加,人家既然更代自然有好的原因。不必擔心,到最後基本上差異在哪裡都會知道的。
還是那句話,官面上可以查到的就不多聊,交流文章多寫作者的看法,意見不統一的噴過來就是。很多教程會建議一開始的時候用python自帶的IDLE寫代碼,簡潔沒有代碼補全提示,適合初學者!我差點就信了!你會覺得怎麼打都有一種好TM業餘的感覺有沒有?我的觀點是:不是武功練到什麼程度用什麼劍,而是有適合自己的絕世好劍就絕對不用絕世第二劍。所以用了一段時間的IDLE我就決定換一款炫酷的編譯器,於是我選擇了Atom(這個時候有一個認識上的錯誤。)然後一個字都沒寫就安裝activate-power-mode插件,開始震屏,冒泡,好不炫酷。
安裝好了python,有了編譯器,我們開始編程了,打開編譯器輸入
print (“Hello Word”),保存文件名為1.py,就把它保存在桌面上。然後cmd
cd /d C:\\Users\Administrator\Desktop
python 1.py如果列印:Hello word,那麼恭喜你,你學會編程了!(我的天!)如果列印失敗,那麼你和兄弟我起初時犯了一樣的錯誤:沒有設置環境變數。
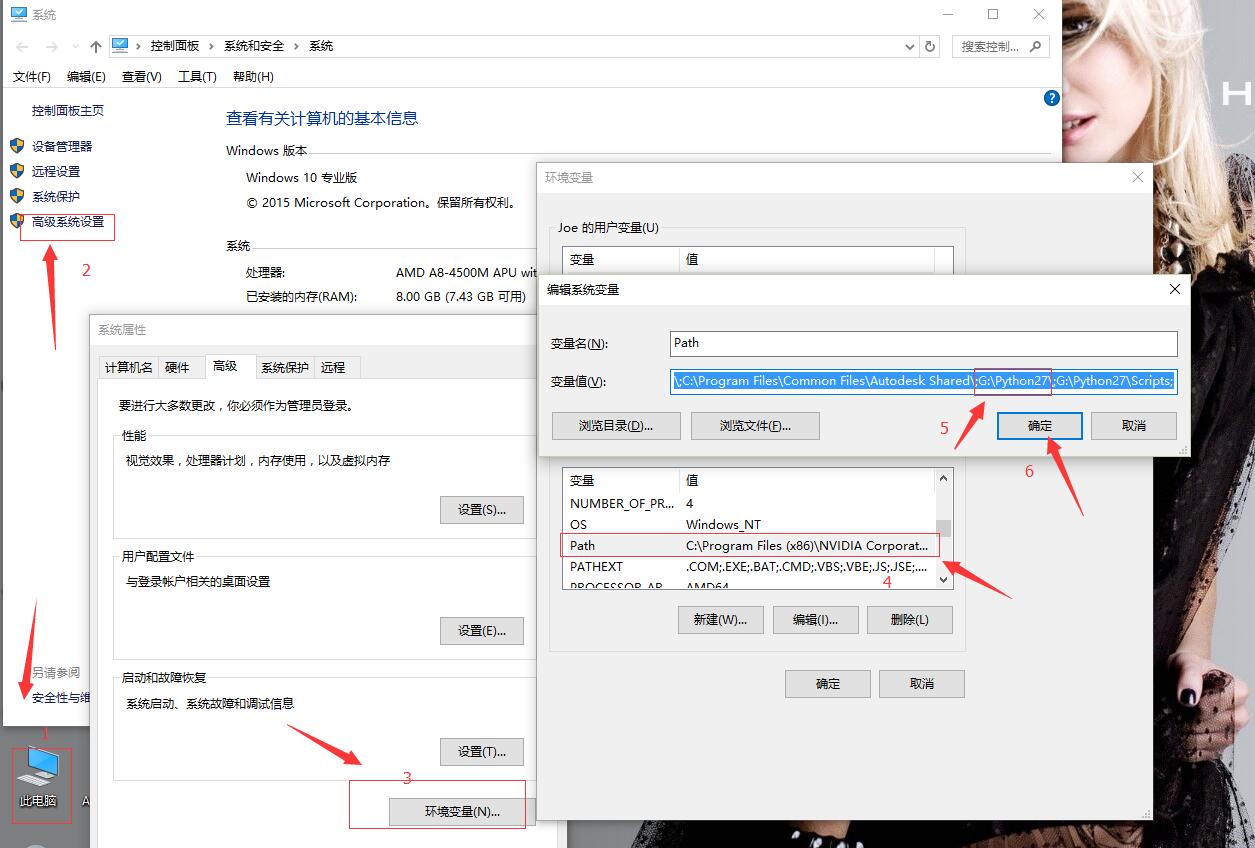
這張圖應該可以說明問題了,我的電腦>屬性>高級系統設置>環境變數>pach>最後面加;G:\python27(根據自己安裝路徑來改)。
這回就可以列印了,好吧你也學會編程了!(我天哪!)
0x001 將網頁下載到本地
我們要用到python的標準模塊urllib,具體下麵的多種方法可以dir打開查看的,代碼如下,供您消遣。大多數同學都會覺得太小兒科的,不太懂得不必細究,只需知道用這麼個模塊,這麼個方法可以乾這麼個事情!
# -*-coding:utf-8 -*-
# 首先進行編碼申明
import urllib
# 導入urllib模塊
url = "http://www.xxoo.com/"
# 變數賦值
urllib.urlretrieve(url, "C:\\Users\\用戶名\\Desktop\\g00gle.txt")
# urlretrieve方法下載到本地這樣就將網頁下載到本地了


0x002 判斷網頁是否可以抓取以及抓取進度
思路是這樣的:我們針對一個網頁首先要看它是否可以爬取,如果可以我們抓取他的什麼?抓取它的內容、頭部信息、狀態碼、傳入網址等,代碼如下:
# -*-coding:utf-8 -*-
import urllib
url = "http://www.163.com/"
html = urllib.urlopen(url)
# content = html.read().decode('gbk','ignore').encode(''utf-8)
# print(content)
code = html.getcode()
# 網頁狀態碼,變數code是一個整形
if code == 200:
print html.read()
print html.info()
else:
print "不明飛行物."
# if判斷語句判斷網頁返回是否正常,如果正常返回他的內容、頭部信息、狀態碼、傳入網址等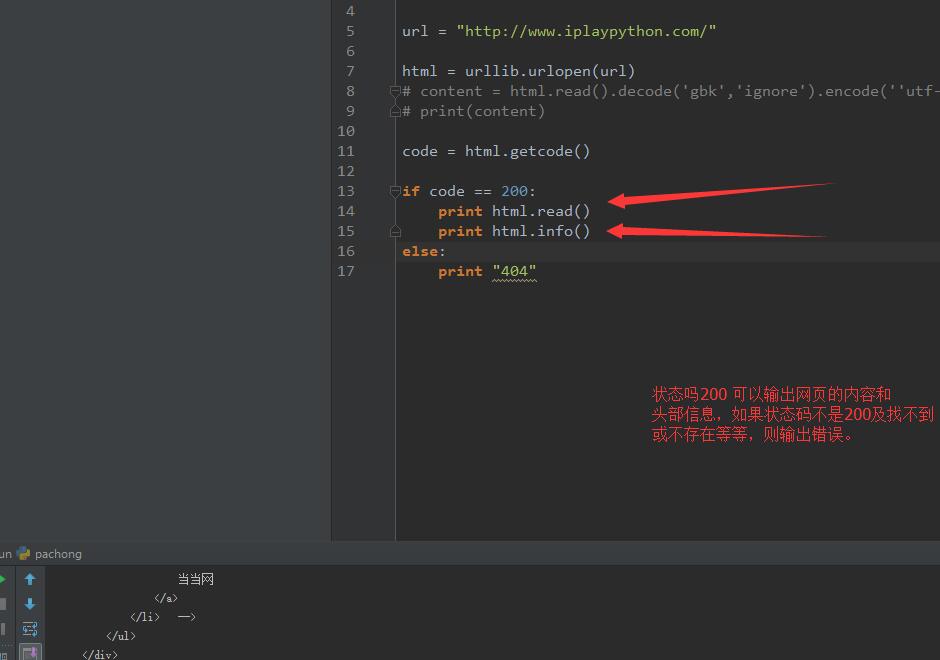
這裡,urllib中用的的方法:
# urlopen()
#獲取類文件對象
# read()
#讀取文件內容
# infor
# 獲取頭部信息Header
#Getcode
#獲取網頁狀態碼
#geturl
#傳入網址舉一個例子:
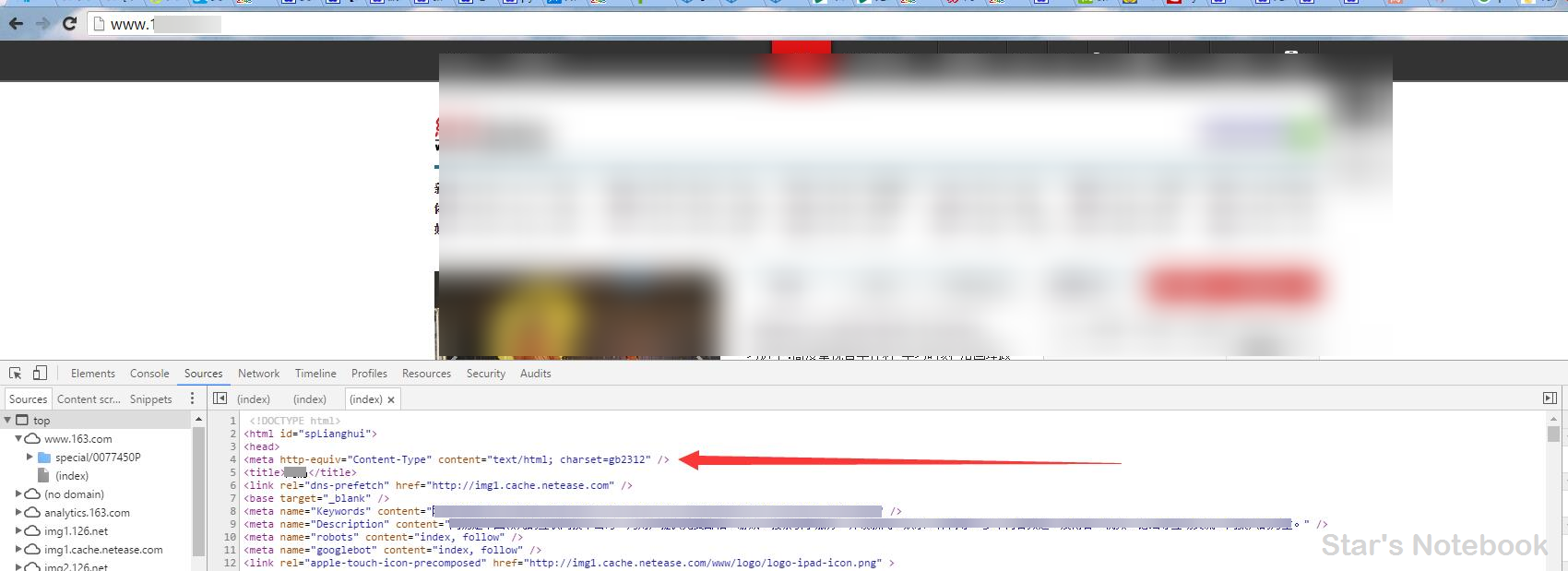
這是某站的Header、Sever、Content-Type、Last-Modified
用上面代碼抓取列印的結果:

然後我們用回調函數的方法寫一段有讀取進度的抓取網頁的代碼。
# -*-coding:utf-8 -*-
import urllib
def callback(a,b,c):
# 回調函數
# @a:xxx
# @b:xxx
# @c:xxx
down_program = 100.0 * a * b / c
if down_program >100:
down_program =100
print "%.1f%%"% down_program
# 字元串拼接%.4f讓輸出小數點後1位
print ">>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>100%"
url = "http://tieba.baidu.com/"
local = "C:\\Users\\Joe\\Desktop\\papa2.html"
urllib.urlretrieve(url,local,callback)
# 調用了上面封裝的callback函數技術有限,本來想讓它
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>100%這樣讀取的,懶得弄了,沒再深究。
0x003 你發現換了編譯器
對的,至於是為什麼呢?因為到後來我才明白編譯器、文本編譯器、IDE之間的區別,真是愚笨!我是這樣理解的,就像大保健一樣,IDE小姐可以提供陪吃、推拿、跳舞、刮痧、n推背等服務,編譯器呢晚上進屋白天走人,文本編譯器……類似於什麼呢?充氣娃娃?它們不能對比各有所長。Atom嚴格上來說屬於文本編譯器,本身不能斷點測試,但載入插件後可以。還有,Atom想Chrorme一樣任性,自動強制裝在系統盤,其實之前忍了它……現在找到我的絕世好劍了,不能忍,Pycharm取而代之。Sublimetext,人氣之高,自然也不錯。
0x004 本章小結
本章我們安裝了Python環境,配置了環境變數,淺嘗了編程,抓取了網頁內容,並有進度條的下載到了本地。其實都是一些簡單的事情。簡單區分了一下編譯器、文本編譯器、IDE之間的區別。這個過程中我肯定有認識上和方法上不當的地方,歡迎大家批過來!預知後事如何,咱們下回分解!
—————— 
未經溝通轉載,將追究法律責任,請尊重原創勞動成果!


