
yarn-site.xml 配置介紹yarn.scheduler.minimum-allocation-mb yarn.scheduler.maximum-allocation-mb說明:單個容器可申請的最小與最大記憶體,應用在運行申請記憶體時不能超過最大值,小於最小值則分配最小值,從這個角度看,最小值 ...
yarn-site.xml 配置介紹
yarn.scheduler.minimum-allocation-mb
yarn.scheduler.maximum-allocation-mb
說明:單個容器可申請的最小與最大記憶體,應用在運行申請記憶體時不能超過最大值,小於最小值則分配最小值,從這個角度看,最小值有點想操作系統中的頁。最小值還有另外一種用途,計算一個節點的最大container數目註:這兩個值一經設定不能動態改變(此處所說的動態改變是指應用運行時)。
預設值:1024/8192
yarn.scheduler.minimum-allocation-vcores
yarn.scheduler.maximum-allocation-vcores
參數解釋:單個可申請的最小/最大虛擬CPU個數。比如設置為1和4,則運行MapRedce作業時,每個Task最少可申請1個虛擬CPU,最多可申請4個虛擬CPU。
預設值:1/32
yarn.nodemanager.resource.memory-mb
yarn.nodemanager.vmem-pmem-ratio
說明:每個節點可用的最大記憶體,RM中的兩個值不應該超過此值。此數值可以用於計算container最大數目,即:用此值除以RM中的最小容器記憶體。虛擬記憶體率,是占task所用記憶體的百分比,預設值為2.1倍;註意:第一個參數是不可修改的,一旦設置,整個運行過程中不可動態修改,且該值的預設大小是8G,即使電腦記憶體不足8G也會按著8G記憶體來使用。
預設值:8G /2.1
yarn.nodemanager.resource.cpu-vcores
參數解釋:NodeManager總的可用虛擬CPU個數。
預設值:8
AM記憶體配置相關參數,此處以MapReduce為例進行說明(這兩個值是AM特性,應在mapred-site.xml中配置),如下:
mapreduce.map.memory.mb
mapreduce.reduce.memory.mb
說明:這兩個參數指定用於MapReduce的兩個任務(Map and Reduce task)的記憶體大小,其值應該在RM中的最大最小container之間。如果沒有配置則通過如下簡單公式獲得:
max(MIN_CONTAINER_SIZE, (Total Available RAM) / containers))
一般的reduce應該是map的2倍。註:這兩個值可以在應用啟動時通過參數改變;
AM中其它與記憶體相關的參數,還有JVM相關的參數,這些參數可以通過,如下選項配置:
mapreduce.map.java.opts
mapreduce.reduce.java.opts
說明:這兩個參主要是為需要運行JVM程式(java、scala等)準備的,通過這兩個設置可以向JVM中傳遞參數的,與記憶體有關的是,-Xmx,-Xms等選項。此數值大小,應該在AM中的map.mb和reduce.mb之間。
我們對上面的內容進行下總結,當配置Yarn記憶體的時候主要是配置如下三個方面:每個Map和Reduce可用物理記憶體限制;對於每個任務的JVM對大小的限制;虛擬記憶體的限制;
下麵通過一個具體錯誤實例,進行記憶體相關說明,錯誤如下:
Container[pid=41884,containerID=container_1405950053048_0016_01_000284] is running beyond virtual memory limits. Current usage: 314.6 MB of 2.9 GB physical memory used; 8.7 GB of 6.2 GB virtual memory used. Killing container.
配置如下:
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>100000</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>10000</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>3000</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2000</value>
</property>
通過配置我們看到,容器的最小記憶體和最大記憶體分別為:3000m和10000m,而reduce設置的預設值小於2000m,map沒有設置,所以兩個值均為3000m,也就是log中的“2.9 GB physical memory used”。而由於使用了預設虛擬記憶體率(也就是2.1倍),所以對於Map Task和Reduce Task總的虛擬記憶體為都為3000*2.1=6.2G。而應用的虛擬記憶體超過了這個數值,故報錯 。解決辦法:在啟動Yarn是調節虛擬記憶體率或者應用運行時調節記憶體大小.
mapred-site.xml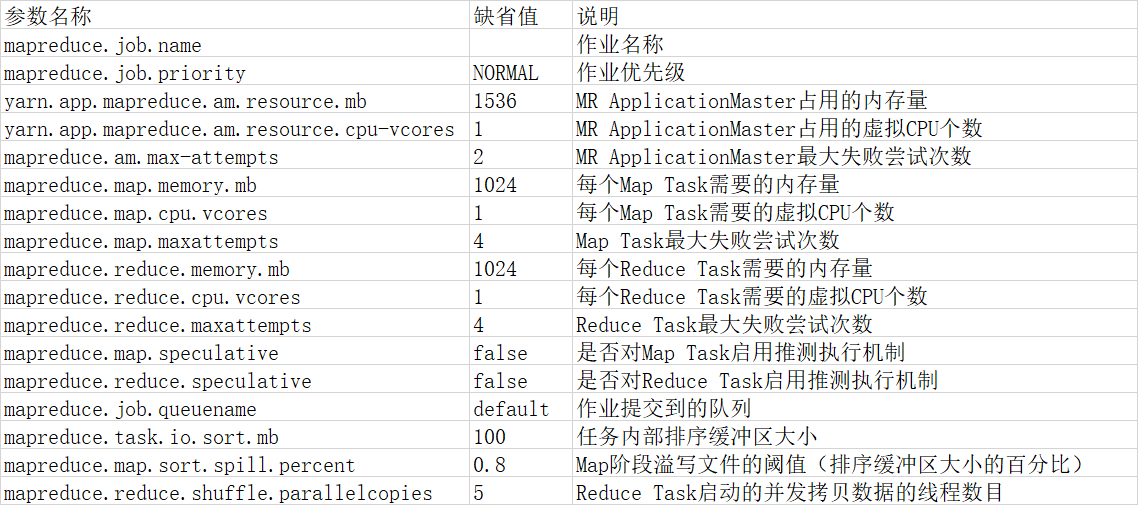
在上Yarn的框架管理中,無論是AM從RM申請資源,還是NM管理自己所在節點的資源,都是通過container進行的。Container是Yarn的資源抽象,此處的資源包括記憶體和cup等。下麵對container,進行比較詳細的介紹。為了是大家對container有個比較形象的認識,首先看下圖: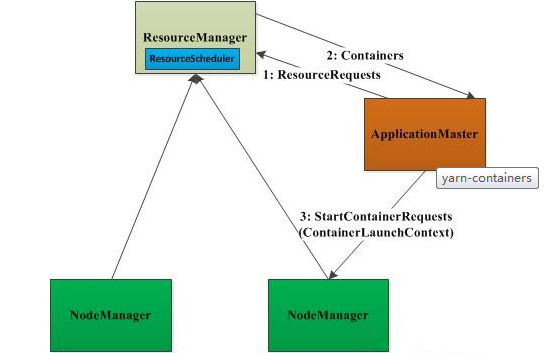
從上圖中我們可以看到,首先AM通過請求包ResourceRequest從RM申請資源,當獲取到資源後,AM對其進行封裝,封裝成ContainerLaunchContext對象,通過這個對象,AM與NM進行通訊,以便啟動該任務。下麵通過ResourceRequest、container和ContainerLaunchContext的protocol
ResourceRequest結構如下:
message ResourceRequestProto {
optional PriorityProto priority = 1; // 資源優先順序
optional string resource_name = 2; // 期望資源所在的host
optional ResourceProto capability = 3; // 資源量(mem、cpu)
optional int32 num_containers = 4; // 滿足條件container個數
optional bool relax_locality = 5 ; //default = true;
}
對上面結構進行簡要按序號說明:
2:在提交申請時,期望從哪台主機上獲得,但最終還是AM與RM協商決定;
3:只包含兩種資源,即:記憶體和cpu,申請方式:
註:1、由於2與4並沒有限制資源申請量,則AP在資源申請上是無限的。2、Yarn採用覆蓋式資源申請方式,即:AM每次發出的資源請求會覆蓋掉之前在同一節點且優先順序相同的資源請求,也就是說同一節點中相同優先順序的資源請求只能有一個。
container結構:
message ContainerProto {
optional ContainerIdProto id = 1; //container id
optional NodeIdProto nodeId = 2; //container(資源)所在節點
optional string node_http_address = 3;
optional ResourceProto resource = 4; //分配的container數量
optional PriorityProto priority = 5; //container的優先順序
optional hadoop.common.TokenProto container_token = 6; //container token,用於安全認證
}
註:每個container一般可以運行一個任務,當AM收到多個container時,將進一步分給某個人物。如:MapReduce
ContainerLaunchContext結構:
message ContainerLaunchContextProto {
repeated StringLocalResourceMapProto localResources = 1; //該Container運行的程式所需的在資源,例如:jar包
optional bytes tokens = 2;//Security模式下的SecurityTokens
repeated StringBytesMapProto service_data = 3;
repeated StringStringMapProto environment = 4; //Container啟動所需的環境變數
repeated string command = 5; //該Container所運行程式的命令,比如運行的為java程式,即$JAVA_HOME/bin/java org.ourclassrepeated ApplicationACLMapProto application_ACLs = 6;//該Container所屬的Application的訪問控制列表
}
下麵結合一段代碼,僅以ContainerLaunchContext為例進行描述(本應該寫個簡單的有限狀態機的,便於大家理解,但時間不怎麼充分):
申請一個新的ContainerLaunchContext:
ContainerLaunchContext ctx = Records.newRecord(ContainerLaunchContext.class);
填寫必要的信息:
ctx.setEnvironment(...);
childRsrc.setResource(...);
ctx.setLocalResources(...);
ctx.setCommands(...);
啟動任務:
startReq.setContainerLaunchContext(ctx);
最後對container進行如下總結:container是Yarn的資源抽象,封裝了節點上的一些資源,主要是CPU與記憶體;container是AM向NM申請的,其運行是由AM向資源所在NM發起的,並最終運行
的。有兩類container:一類是AM運行需要的container;另一類是AP為執行任務向RM申請的。
每個slave可以運行
map的數據<=yarn.nodemanager.resource.memory-mb/mapreduce.map.memory.mb,
reduce任務的數量<=yarn.nodemanager.resource.memory-mb/mapreduce.reduce.memory.mb

