
正則表達式介紹 前兩章中的過濾例子允許用匹配、比較和通配操作符尋找數據。對 於基本的過濾(或者甚至是某些不那麼基本的過濾),這樣就足夠了。但 隨著過濾條件的複雜性的增加, WHERE 子句本身的複雜性也有必要增加。 這也就是正則表達式變得有用的地方。正則表達式是用來匹配文本 的特殊的串(字元集合)。 ...
正則表達式介紹
前兩章中的過濾例子允許用匹配、比較和通配操作符尋找數據。對
於基本的過濾(或者甚至是某些不那麼基本的過濾),這樣就足夠了。但
隨著過濾條件的複雜性的增加, WHERE 子句本身的複雜性也有必要增加。
這也就是正則表達式變得有用的地方。正則表達式是用來匹配文本
的特殊的串(字元集合)。如果你想從一個文本文件中提取電話號碼,可
以使用正則表達式。如果你需要查找名字中間有數字的所有文件,可以
使用一個正則表達式。如果你想在一個文本塊中找到所有重覆的單詞,
可以使用一個正則表達式。如果你想替換一個頁面中的所有URL為這些
URL的實際HTML鏈接,也可以使用一個正則表達式(對於最後這個例子,
或者是兩個正則表達式)。
所有種類的程式設計語言、文本編輯器、操作系統等都支持正則表
達式。有見識的程式員和網路管理員已經關註作為他們技術工具重要內
容的正則表達式很長時間了。
正則表達式用正則表達式語言來建立,正則表達式語言是用來完成
剛討論的所有工作以及更多工作的一種特殊語言。與任意語言一樣,正
則表達式具有你必須學習的特殊的語法和指令
使用MySQL正則表達式
那麼,正則表達式與MySQL有何關係?已經說過,正則表達式的作
用是匹配文本,將一個模式(正則表達式)與一個文本串進行比較。MySQL
用 WHERE 子句對正則表達式提供了初步的支持,允許你指定正則表達式,
過濾 SELECT 檢索出的數據
僅為正則表達式語言的一個子集 如果你熟悉正則表達式,需
要註意:MySQL僅支持多數正則表達式實現的一個很小的子
集。本章介紹MySQL支持的大多數內容。
基本字元匹配
我們從一個非常簡單的例子開始。下麵的語句檢索列 prod_name 包含
文本 1000 的所有行

除關鍵字 LIKE 被 REGEXP 替代外,這條語句看上去非常像使用
LIKE 的語句(第8章)。它告訴MySQL: REGEXP 後所跟的東西作
為正則表達式(與文字正文 1000 匹配的一個正則表達式)處理
為什麼要費力地使用正則表達式?在剛纔的例子中,正則表達式確
實沒有帶來太多好處(可能還會降低性能),不過,請考慮下麵的例子

這裡使用了正則表達式 .000 。 . 是正則表達式語言中一個特殊
的字元。它表示匹配任意一個字元,因此, 1000 和 2000 都匹配
且返回。
當然,這個特殊的例子也可以用 LIKE 和通配符來完成
LIKE 匹配整個列。如果被匹配的文本在列值
中出現, LIKE 將不會找到它,相應的行也不被返回(除非使用
通配符)。而 REGEXP 在列值內進行匹配,如果被匹配的文本在
列值中出現, REGEXP 將會找到它,相應的行將被返回。這是一
個非常重要的差別。的作用)?答案是肯定的,使用 ^ 和 $ 定位符(anchor)即可,
本章後面介紹。
匹配不區分大小寫 MySQL中的正則表達式匹配(自版本
3.23.4後)不區分大小寫(即,大寫和小寫都匹配)。為區分大
小寫,可使用 BINARY 關鍵字,如 WHERE prod_name REGEXP
BINARY 'JetPack .000'
匹配幾個字元之一
匹配任何單一字元。但是,如果你只想匹配特定的字元,怎麼辦?
可通過指定一組用 [ 和 ] 括起來的字元來完成,如下所示:

這裡,使用了正則表達式 [123] Ton 。 [123] 定義一組字元,它
的意思是匹配 1 或 2 或 3 ,因此, 1 ton 和 2 ton 都匹配且返回(沒
有 3 ton )。
正如所見, [] 是另一種形式的 OR 語句。事實上,正則表達式 [123]Ton
為 [1|2|3]Ton 的縮寫,也可以使用後者。但是,需要用 [] 來定義 OR 語句
查找什麼。為更好地理解這一點,請看下麵的例子:


這並不是期望的輸出。兩個要求的行被檢索出來,但還檢索出
了另外3行。之所以這樣是由於MySQL假定你的意思是 '1' 或
'2' 或 '3 ton' 。除非把字元 | 括在一個集合中,否則它將應用於整個串。
字元集合也可以被否定,即,它們將匹配除指定字元外的任何東西。
為否定一個字元集,在集合的開始處放置一個 ^ 即可。因此,儘管 [123]
匹配字元 1 、 2 或 3 ,但 [^123] 卻匹配除這些字元外的任何東西
匹配範圍
集合可用來定義要匹配的一個或多個字元。例如,下麵的集合將匹
配數字0到9:


這裡使用正則表達式 [1-5] Ton 。 [1-5] 定義了一個範圍,這個
表達式意思是匹配 1 到 5 ,因此返回3個匹配行。由於 5 ton 匹配,
所以返回 .5 ton 。
匹配特殊字元
正則表達式語言由具有特定含義的特殊字元構成。我們已經看到 . 、 [] 、
| 和 - 等,還有其他一些字元。請問,如果你需要匹配這些字元,應該怎麼
辦呢?例如,如果要找出包含 . 字元的值,怎樣搜索?請看下麵的例子
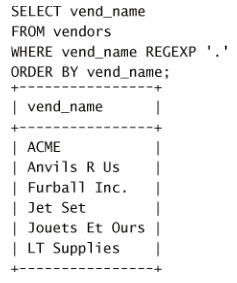
這並不是期望的輸出, . 匹配任意字元,因此每個行都被檢索出
來。為了匹配特殊字元,必須用 \ 為前導。 \- 表示查找 - , \. 表示查找 .

這種處理
就是所謂的轉義(escaping),正則表達式內具有特殊意義的所
有字元都必須以這種方式轉義。這包括 . 、 | 、 [] 以及迄今為止使用過的
其他特殊字元。
\ 也用來引用元字元(具有特殊含義的字元),如表9-1所列。

匹配 為了匹配反斜杠( )字元本身,需要使用 \ 。
或 \? 多數正則表達式實現使用單個反斜杠轉義特殊字元,
以便能使用這些字元本身。但MySQL要求兩個反斜杠(MySQL
自己解釋一個,正則表達式庫解釋另一個)。
匹配字元類
存在找出你自己經常使用的數字、所有字母字元或所有數字字母字
符等的匹配。為更方便工作,可以使用預定義的字元集,稱為字元類
(character class)。表9-2列出字元類以及它們的含義

匹配多個實例
目前為止使用的所有正則表達式都試圖匹配單次出現。如果存在一
個匹配,該行被檢索出來,如果不存在,檢索不出任何行。但有時需要
對匹配的數目進行更強的控制。例如,你可能需要尋找所有的數,不管
數中包含多少數字,或者你可能想尋找一個單詞並且還能夠適應一個尾
隨的 s (如果存在),等等
這可以用表9-3列出的正則表達式重覆元字元來完成

定位符
目前為止的所有例子都是匹配一個串中任意位置的文本。為了匹配特定位置的文本,需要使用表9-4列出的定位符

例如,如果你想找出以一個數(包括以小數點開始的數)開始的所
有產品,怎麼辦?簡單搜索 [0-9\.] (或 [[:digit:]\.] )不行,因為
它將在文本內任意位置查找匹配。解決辦法是使用 ^ 定位符,如下所示
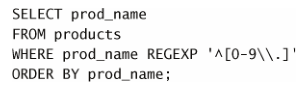
^ 匹配串的開始。因此, ^[0-9\.] 只在 . 或任意數字為串中第
一個字元時才匹配它們。
^ 的雙重用途 ^ 有兩種用法。在集合中(用 [ 和 ] 定義),用它
來否定該集合,否則,用來指串的開始處
使 REGEXP 起類似 LIKE 的作用 本章前面說過, LIKE 和 REGEXP
的不同在於, LIKE 匹配整個串而 REGEXP 匹配子串。利用定位
符,通過用 ^ 開始每個表達式,用 $ 結束每個表達式,可以使
REGEXP 的作用與 LIKE 一樣

本章介紹了正則表達式的基礎知識,學習瞭如何在MySQL的 SELECT
語句中通過 REGEXP 關鍵字使用它們


