
這篇文章主要是介紹生成器和IO多路復用機制, 算是學習asyncio需要的預備知識. 這個系列還有另外兩篇文章: 從零開始學asyncio(中) 從零開始學asyncio(下) 一. 簡單爬蟲實例 首先創建一個crawler.py文件, 寫入以下代碼: import socket req = 'GE ...
這篇文章主要是介紹生成器和IO多路復用機制, 算是學習asyncio需要的預備知識. 這個系列還有另外兩篇文章:
一. 簡單爬蟲實例
首先創建一個crawler.py文件, 寫入以下代碼:
import socket req = 'GET / HTTP/1.0\r\nHost:cn.bing.com\r\n\r\n'.encode('utf8') address = ('cn.bing.com', 80) db = [] def simple_crawler(): sock = socket.socket() sock.connect(address) sock.send(req) response = b'' while 1: chunk = sock.recv(1024) if chunk == b'': sock.close() break else: response += chunk db.append(response) if __name__ == '__main__': print('開始爬取...') simple_crawler() print('獲取到{}條數據'.format(len(db)))
運行crawler.py文件, 結果如下:

其中, simple_crawler函數做瞭如下幾件事:
- 創建一個socket對象
- 連接伺服器
- 向伺服器發送http請求
- 接收服務端的響應內容
- 處理和儲存響應內容
通過這五個步驟, 我們實現了一個最基本的爬蟲實例.


這裡的請求之所以使用HTTP1.0協議, 是因為HTTP1.0預設不是長連接, 伺服器在發送完數據後會自己斷開. 因此當socket接收到空位元組的時候, 就說明伺服器已經斷開了, 也就是說數據已經接收完了.
如果要使用HTTP1.1協議, 那麼在請求頭中加上Connection:close就行.
補充說明
二. IO操作
1. 爬蟲實例中的耗時操作
首先測試一下simple_crawler獲取一次數據的用時:
import time print('開始爬取...') start=time.time() simple_crawler() print('獲取到{}條數據'.format(len(db))) print('本次用時:{:.2f}秒'.format(time.time()-start))
運行幾次crawler.py文件, 結果如下:
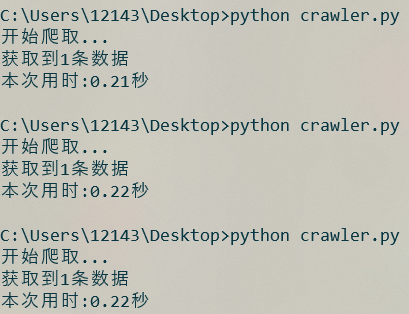
相比電腦的計算速度而言, 這段代碼的運行速度是相當慢的, 如果現在需要獲取100個數據, 那麼就需要大約三分半鐘的時間.
現在修改一下crawler.py的代碼, 看看各個步驟的執行時間:
import socket import time req = 'GET / HTTP/1.0\r\nHost:cn.bing.com\r\n\r\n'.encode('utf8') address = ('cn.bing.com', 80) db = [] def simple_crawler(): print('開始運行',time.time()) sock = socket.socket() print('已創建socket對象',time.time()) sock.connect(address) print('已連接伺服器',time.time()) sock.send(req) print('已發送請求',time.time()) response = b'' while 1: chunk = sock.recv(1024) if chunk == b'': sock.close() break else: response += chunk print('已接收響應',time.time()) db.append(response) print('已處理響應',time.time()) if __name__ == '__main__': simple_crawler()
代碼運行結果如下:

可以看到, 在這個程式中, 創建socket對象, 發送http請求, 處理響應結果, 基本都是不耗時的, 耗時操作在於連接伺服器和接收響應.
socket對象的send方法只是將數據寫入到內核態, 由系統將數據發送到伺服器. 因此, 如果socket對應的內核位置的可寫緩衝區還沒裝滿, 並且還能裝下本次send的數據, 就不會阻塞, 否則, send操作也會是阻塞的.補充說明
2. 阻塞IO
現在運行下麵一段代碼:
input('按回車退出>>>') exit()
顯然, 如果不按回車或者ctrl+c, 程式就會一直卡在input這一行. 在這段時間, 程式沒有做任何事, 只是單純地等待用戶按回車而已, 就像下麵這張圖:

IO的全稱是input/output, 即向/從電腦傳輸數據的操作, 在針對文件和網路操作中比較常見. 其特點是需要花費一定的等待時間才能完成操作, 上一節的代碼中, sock.connect和sock.recv就是IO操作, 花費了大量的時間在等待伺服器響應上, 因此用時較長.
一般情況下, 這些基本的IO操作是阻塞式的, 也就是程式會卡在等待的期間, 直到IO操作完成. 比如input語句, 在用戶按下回車之前, 程式處於'死機'狀態.
3. 非阻塞IO
現在運行如下代碼:
import socket import time sock = socket.socket() sock.setblocking(0) print('開始連接伺服器', time.time()) try: sock.connect(('cn.bing.com', 80)) except BlockingIOError: pass print('完成連接伺服器', time.time())
然後運行:

可以看到, 原本耗時的連接操作變得不耗時了.
調用socket對象的setblocking方法, 傳入False, 就可以將這個socket對象設置為非阻塞式的, 這時再調用該對象涉及到IO操作的方法, 程式將不會阻塞, 但如果操作不能立即完成, 就會拋出異常.
現在將剛纔寫的爬蟲改為非阻塞的形式:
import socket req = 'GET / HTTP/1.0\r\nHost:cn.bing.com\r\n\r\n'.encode('utf8') address = ('cn.bing.com', 80) db = [] def noblocking_crawler(): sock = socket.socket() sock.setblocking(0) # connect_ex與connect類似,但在這種情況下不會拋出異常,而是返回錯誤碼 # 因此,這裡使用connect_ex來省略一個try語句 sock.connect_ex(address) while 1: try: sock.send(req) break except OSError: pass response = b'' while 1: try: chunk = sock.recv(1024) if chunk == b'': sock.close() break else: response += chunk except BlockingIOError: pass db.append(response) if __name__ == '__main__': print('開始爬取...') noblocking_crawler() print('獲取到{}條數據'.format(len(db)))
非阻塞式IO並非意味著不需要等待時間, 而是說程式不會卡在這裡, 但這並不代表IO操作的等待時間會消失. 因此, 在使用connect方法之後, 需要在while迴圈中一直重覆send, 如果捕獲到OSError異常, 就說明還沒有連接成功, 也就是IO操作還未結束, 於是繼續迴圈, 直到IO結束為止. 這一部分的流程如下:

recv方法同理.
對函數的運行時間進行測試, 會發現耗時並沒有減少, 這是因為IO操作中的等待時間並不會消失. 因此, 單純將程式設置為非阻塞並不能提高效率, 只有利用等待時間執行其它任務, 程式的整體效率才會提高.
三. 生成器
在上一節中, 非阻塞IO之所以沒有體現出優勢, 是因為沒有利用好IO操作的等待時間去執行其他程式. 假如現在有ABC三個任務, 而有一種機制, 能讓任務A遇到IO操作時, 切換到任務B, 任務B遇到IO操作時, 再切換到任務C, 最後就可以充分利用IO操作的等待時間, 從而提升程式的整體運行效率.
定義一個如下函數:
def gen(): print('這裡是gen函數內部, 現在執行step1') yield print('這裡是gen函數內部, 現在執行step2') yield print('這裡是gen函數內部, 現在執行step3') return
現在查看這個函數的返回值:
g = gen() print(type(g))
結果如下:

在函數中加入yield語句後, 調用這個函數, 函數內的語句就不會執行, 而是返回一個generator對象, 即生成器.
如果想執行這個函數內部的語句, 可以調用python內置的next函數對生成器進行驅動:
g = gen() for i in range(1, 4): print('這裡是gen函數外部,現在是第%s次驅動生成器' % i) next(g)
結果如下:
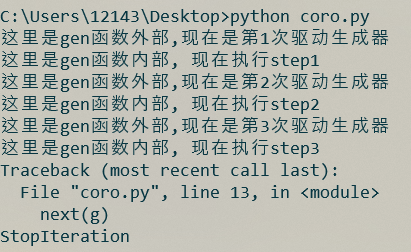
對於生成器, 在外部調用next對其驅動, 就能執行其內部的代碼, 如果執行到yield語句, 就會切換回外部, 下次再驅動, 會從上次結束的地方繼續. 程式的執行流程如下:
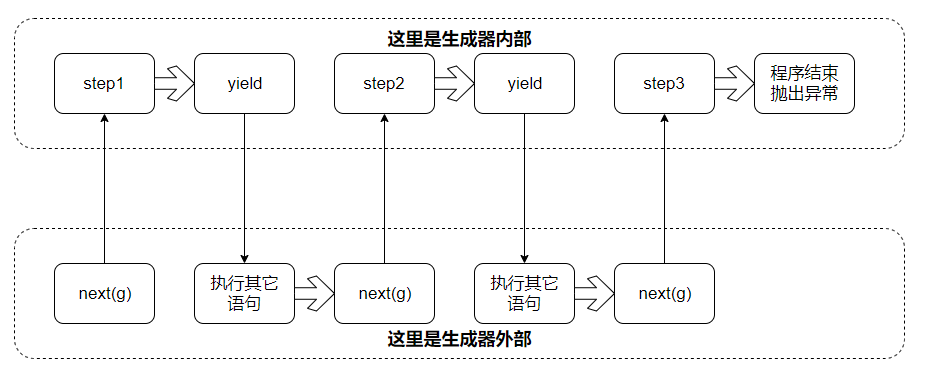
只要調用next函數驅動生成器, 程式就會切換到生成器的內部, 從上次停下來的位置開始繼續運行, 運行過程中如果遇到yield語句, 再切換回調用next函數的位置. 因此, 使用next和yield, 就可以方便地在不同程式中來回切換. 需要註意的是, 如果生成器內部的程式執行結束, 會拋出StopIteration異常.
這樣看來, 生成器就滿足了我們的需求: 即在不同的程式之間切換, 對於一個任務, 在IO操作的時候使用yield語句切換到其它任務, 然後在特定時間再用next函數切換回來, 這樣就能利用IO操作的等待時間.
yield語句除了能暫停程式的執行外, 它還是個生成器內部與外部的雙向通道. 需要向外部傳值時, yield的用法等於return; 如果要向生成器內部傳值, 那麼就在生成器內部寫成a=yield的形式, 然後在外部調用生成器的send方法將值傳給a(此方法同時會驅動生成器) 舉個例子: def gen(): first_sentence = '天王蓋地虎' second_sentence = yield first_sentence print('生成器從外部獲取的值:', second_sentence) yield g = gen() first_sentence = next(g) print('外部從生成器獲取的值:', first_sentence) g.send('小雞燉蘑菇') 有關python生成器的更多內容, 可以參考https://www.python.org/dev/peps/pep-0342/補充說明
四. IO多路復用
程式之間切換的問題解決了, 現在的問題是, IO操作的等待時間是不確定的, 如果在操作還未結束的時候, 就調用next對生成器進行驅動, 比如還沒連接成功時就調用send語句, 顯然得不到想要的結果. 因此, 需要一種機制, 能夠在IO操作完成的時候進行通知, 這時候再驅動生成器進行後續的操作.
使用python自帶的select模塊可以對多個socket對象進行監聽, 當觸發到可讀, 可寫或者錯誤事件時, 返回觸發事件的socket對象列表.
基於IO多路復用和生成器等功能寫的爬蟲代碼如下:
import select import socket import time req = 'GET / HTTP/1.0\r\nHost:cn.bing.com\r\n\r\n'.encode('utf8') address = ('cn.bing.com', 80) db = [] class GenCrawler: ''' 這裡使用一個類將生成器封裝起來,如果要驅動生成器,就調用next_step方法 另外,這個類還可以獲取到使用的socket對象 ''' def __init__(self): self.sock = socket.socket() self.sock.setblocking(0) self._gen = self._crawler() def next_step(self): next(self._gen) def _crawler(self): self.sock.connect_ex(address) yield self.sock.send(req) response = b'' while 1: yield chunk = self.sock.recv(1024) if chunk == b'': self.sock.close() break else: response += chunk db.append(response) def event_loop(crawlers): # 首先,建立sock與crawler對象的映射關係,便於由socket對象找到對應的crawler對象 # 建立映射的同時順便調用crawler的next_step方法,讓內部的生成器運行起來 sock_to_crawler = {} for crawler in crawlers: sock_to_crawler[crawler.sock] = crawler crawler.next_step() # select.select需要傳入三個列表,分別對應要監聽的可讀,可寫和錯誤事件的socket對象集合 readable = [] writeable = [crawler.sock for crawler in crawlers] errors = [] while 1: rs, ws, es = select.select(readable, writeable, errors) for sock in ws: # 當socket對象連接到伺服器時,會創建可讀緩衝區和可寫緩衝區 # 由於可寫緩衝區創建時為空,因此連接成功時,就觸發可寫事件 # 這時再轉為監聽可讀事件,接收到數據時,就可以觸發可讀事件了 writeable.remove(sock) readable.append(sock) sock_to_crawler[sock].next_step() for sock in rs: try: sock_to_crawler[sock].next_step() except StopIteration: # 如果生成器結束了,就說明對應的爬蟲任務已經結束,不需要監聽事件了 readable.remove(sock) # 所有的事件都結束後,就退出迴圈 if not readable and not writeable: break if __name__ == '__main__': start = time.time() n = 10 print('開始爬取...') event_loop([GenCrawler() for _ in range(n)]) print('獲取到{}條數據,用時{:.2f}秒'.format(len(db), time.time()-start))
首先看看Crawler._crawler部分的代碼, 在調用connect_ex方法之後, 程式並不能確定什麼時候能連接到伺服器, 在調用recv方法之前, 程式也不能確定什麼時候能收到伺服器的數據, 因此, 在這兩個位置插入yield語句, 來使程式掛起. 這樣, 一個基於生成器的爬蟲程式就做好了.
然後是event_loop部分, 首先, 由於select監聽到事件後, 返回的是socket對象, 因此先建立一個socket對象映射crawler對象的字典, 這樣當監聽到事件時, 就可以馬上找到對應的crawler並對其驅動. 映射建立後, 就可以在while迴圈中持續監聽socket對象, 監聽到結果時, 就驅動對應的crawler, 直到所有的爬蟲任務都結束為止.
在程式末尾分別設置n=1以及 n=10, 運行程式, 結果如下 :
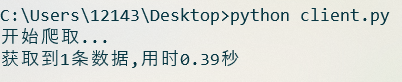 n=1
n=1
 n=10
n=10
程式的執行流程如下:

event_loop負責對多個爬蟲任務進行調度, 在這個流程圖中, 首先監聽到某個事件, 於是驅動對應的crawler2, 而crawler2遇到IO操作後, 就使用yield掛起自己, 在crawlerr2的IO操作結束之前, event_loop又可以去驅動crawler1, 不同的crawler任務和event_loop穿插運行, 減少了IO操作中的時間浪費.
五. 總結
- IO在對文件和網路的操作中較常見. 特點是需要花費一定的等待時間才能完成操作;
- 在函數中加入yield關鍵字, 這個函數就能夠返回一個生成器. 生成器的特點是運行到yield時會暫停, 而調用next函數由可以將其繼續驅動;
- IO多路復用機制可以同時監聽多個socket對象. 在本文最後的實例中, 使用IO多路復用機制監聽socket對象, 觸發到事件時, 驅動對應的生成器運行, 當生成器運行到IO操作時, 再使用yield語句切換回事件監聽, 這樣一方面利用了IO操作中的等待時間, 提高的運行效率, 一方面實現了多個任務併發的效果.

