
Kafaka connect 是一種用於在Kafka和其他系統之間可擴展的、可靠的流式傳輸數據的工具。它使得能夠快速定義將大量數據集合移入和移出Kafka的連接器變得簡單。Kafka Connect可以從資料庫或應用程式伺服器收集數據到Kafka topic,使數據可用於低延遲的流處理。導出作業可以 ...
Kafaka connect 是一種用於在Kafka和其他系統之間可擴展的、可靠的流式傳輸數據的工具。它使得能夠快速定義將大量數據集合移入和移出Kafka的連接器變得簡單。Kafka Connect可以從資料庫或應用程式伺服器收集數據到Kafka topic,使數據可用於低延遲的流處理。導出作業可以將數據從Kafka topic傳輸到二次存儲和查詢系統,或者傳遞到批處理系統以進行離線分析。
Kafaka connect的核心組件:
Source:負責將外部數據寫入到kafka的topic中。
Sink:負責從kafka中讀取數據到自己需要的地方去,比如讀取到HDFS,hbase等。
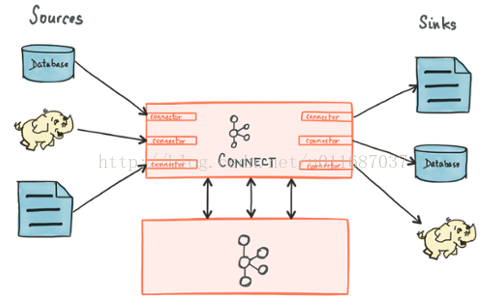
Connectors :通過管理任務來協調數據流的高級抽象
Tasks:數據寫入kafk和從kafka中讀出數據的具體實現,source和sink使用時都需要Task

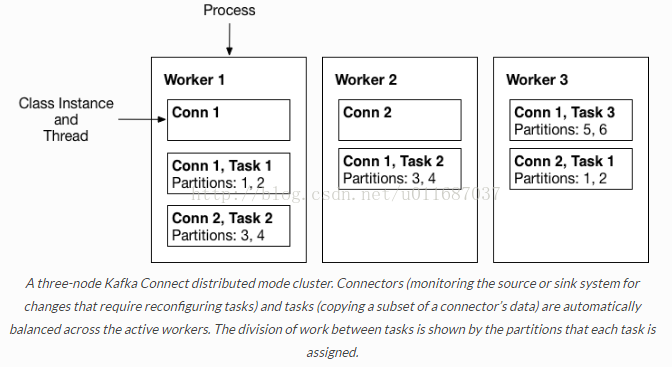
Workers:運行connectors和tasks的進程
Converters:kafka connect和其他存儲系統直接發送或者接受數據之間轉換數據,
converter會把bytes數據轉換成kafka connect內部的格式,也可以把kafka connect內部存儲格式的數據轉變成bytes,converter對connector來說是解耦的,所以其他的connector都可以重用,例如,使用了avro converter,那麼jdbc connector可以寫avro格式的數據到kafka,當然,hdfs connector也可以從kafka中讀出avro格式的數據。

Transforms:一種輕量級數據調整的工具
Kafka connect 工作模式:
Kafka connect 有兩種工作模式:
standalone:在standalone模式中,所有的worker都在一個獨立的進程中完成。
distributed:distributed模式具有高擴展性,以及提供自動容錯機制。你可以使用一個group.ip來啟動很多worker進程,在有效的worker進程中它們會自動的去協調執行connector和task,如果你新加了一個worker或者掛了一個worker,其他的worker會檢測到然後在重新分配connector和task。
本文作者:張永清,轉載請註明出處:https://www.cnblogs.com/laoqing/p/11927958.html
在分散式模式下通過rest api來管理connector。
connector的常見管理操作API:
GET /connectors – 返回所有正在運行的connector名。
POST /connectors – 新建一個connector; 請求體必須是json格式並且需要包含name欄位和config欄位,name是connector的名字,config是json格式,必須包含你的connector的配置信息。
GET /connectors/{name} – 獲取指定connetor的信息。
GET /connectors/{name}/config – 獲取指定connector的配置信息。
PUT /connectors/{name}/config – 更新指定connector的配置信息。
GET /connectors/{name}/status – 獲取指定connector的狀態,包括它是否在運行、停止、或者失敗,如果發生錯誤,還會列出錯誤的具體信息。
GET /connectors/{name}/tasks – 獲取指定connector正在運行的task。
GET /connectors/{name}/tasks/{taskid}/status – 獲取指定connector的task的狀態信息。
PUT /connectors/{name}/pause – 暫停connector和它的task,停止數據處理知道它被恢復。
PUT /connectors/{name}/resume – 恢復一個被暫停的connector。
POST /connectors/{name}/restart – 重啟一個connector,尤其是在一個connector運行失敗的情況下比較常用
POST /connectors/{name}/tasks/{taskId}/restart – 重啟一個task,一般是因為它運行失敗才這樣做。
DELETE /connectors/{name} – 刪除一個connector,停止它的所有task並刪除配置。
如何開發自己的Connector:
1、引入maven依賴。
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>connect-api</artifactId>
<version>${kafka.version}</version>
</dependency>
2、開發自定義的Source
開發自定義的Source 需要繼承實現SourceConnector和SourceTask這兩個抽象類,實現抽象類中的未實現的方法或者重寫抽象類中的方法。
本文作者:張永清,轉載請註明出處:https://www.cnblogs.com/laoqing/p/11927958.html
A、開發自定義的SourceConnector
/**
*
*/
public class ExampleSourceConnector extends SourceConnector{
@Override
public void start(Map<String, String> map) {
}
//返回需要指定的TASK
@Override
public Class<? extends Task> taskClass() {
return ExampleSourceTask.class;
}
//TASK的配置
@Override
public List<Map<String, String>> taskConfigs(int i) {
return null;
}
@Override
public void stop() {
}
@Override
public ConfigDef config() {
return null;
}
@Override
public String version() {
return AppInfoParser.getVersion();
}
}
B、開發Source對應的Task
public class ExampleSourceTask extends SourceTask {
@Override
public String version() {
return new ExampleSourceConnector().version();
}
//任務啟動
@Override
public void start(Map<String, String> map) {
}
//需要發送到kafka的數據。
@Override
public List<SourceRecord> poll() throws InterruptedException {
return null;
}
//任務停止
@Override
public void stop() {
}
}
3、開發自定義的Sink
開發自定義的Sink 需要繼承實現SinkConnector和SinkTask這兩個抽象類,實現抽象類中的未實現的方法或者重寫抽象類中的方法。
A、開發自定義的SinkConnector
/**
*
*/
public class ExampleSinkConnector extends SinkConnector{
@Override
public void start(Map<String, String> map) {
}
//指定Task執行的類
@Override
public Class<? extends Task> taskClass() {
return ExampleSinkTask.class;
}
//task對應的config
@Override
public List<Map<String, String>> taskConfigs(int i) {
return null;
}
@Override
public void stop() {
}
//配置定義
@Override
public ConfigDef config() {
return null;
}
@Override
public String version() {
return AppInfoParser.getVersion();
}
}
B、開發Sink對應的Task
/**
*
*/
public class ExampleSinkTask extends SinkTask {
@Override
public String version() {
return new ExampleSinkConnector().version();
}
//task啟動
@Override
public void start(Map<String, String> map) {
}
//數據put
@Override
public void put(Collection<SinkRecord> collection) {
}
@Override
public void flush(Map<TopicPartition, OffsetAndMetadata> offsets){
//Task停止。
}
@Override
public void stop() {
}
}
Kafka Connect Configs

開源的實現的比較好的connector項目:
https://github.com/debezium/debezium
https://github.com/confluentinc
https://docs.confluent.io/current/connect/managing/connectors.html
這裡我們以https://github.com/debezium/debezium 中的debezium-connector-mongodb 為例配置connector的standalone模式運行
從github中獲取debezium-connector-mongodb-0.9.5.Final.jar 包,放到kafka的libs目錄下,並且把mongodb相關的jar包一起放入到libs下。

在config目錄下新建對應的mongodb.properties 屬性配置文件
name=mongodb connector.class=io.debezium.connector.mongodb.MongoDbConnector mongodb.hosts=configs/10.100.xx.xx:27017 tasks.max=1 mongodb.name=mongo-test #mongodb.user=root #mongodb.password=123456 database.whitelist=kafkaTest collection.whitelist=kafkaTest.kafkaTest connect.max.attempts=12 max.queue.size=8192 max.batch.size=2048 poll.interval.ms=1000 connect.backoff.initial.delay.ms=1000 connect.backoff.max.delay.ms=2000 mongodb.ssl.enabled=false mongodb.ssl.invalid.hostname.allowed=false snapshot.mode=initial initial.sync.max.threads=2 tombstones.on.delete=true mongodb.members.auto.discover=true source.struct.version=v2
配置解釋如下:
詳情參考:https://debezium.io/documentation/reference/0.10/connectors/mongodb.html
| Property | Default | Description |
|---|---|---|
|
|
Unique name for the connector. Attempting to register again with the same name will fail. (This property is required by all Kafka Connect connectors.) |
|
|
|
The name of the Java class for the connector. Always use a value of |
|
|
|
The comma-separated list of hostname and port pairs (in the form 'host' or 'host:port') of the MongoDB servers in the replica set. The list can contain a single hostname and port pair. If |
|
|
|
A unique name that identifies the connector and/or MongoDB replica set or sharded cluster that this connector monitors. Each server should be monitored by at most one Debezium connector, since this server name prefixes all persisted Kafka topics emanating from the MongoDB replica set or cluster. |
|
|
|
Name of the database user to be used when connecting to MongoDB. This is required only when MongoDB is configured to use authentication. |
|
|
|
Password to be used when connecting to MongoDB. This is required only when MongoDB is configured to use authentication. |
|
|
|
|
Connector will use SSL to connect to MongoDB instances. |
|
|
|
When SSL is enabled this setting controls whether strict hostname checking is disabled during connection phase. If |
|
|
empty string |
An optional comma-separated list of regular expressions that match database names to be monitored; any database name not included in the whitelist will be excluded from monitoring. By default all databases will be monitored. May not be used with |
|
|
empty string |
An optional comma-separated list of regular expressions that match database names to be excluded from monitoring; any database name not included in the blacklist will be monitored. May not be used with |
|
|
empty string |
An optional comma-separated list of regular expressions that match fully-qualified namespaces for MongoDB collections to be monitored; any collection not included in the whitelist will be excluded from monitoring. Each identifier is of the form databaseName.collectionName. By default the connector will monitor all collections except those in the |
|
|
empty string |
An optional comma-separated list of regular expressions that match fully-qualified namespaces for MongoDB collections to be excluded from monitoring; any collection not included in the blacklist will be monitored. Each identifier is of the form databaseName.collectionName. May not be used with |
|
|
|
Specifies the criteria for running a snapshot (eg. initial sync) upon startup of the connector. The default is initial, and specifies the connector reads a snapshot when either no offset is found or if the oplog no longer contains the previous offset. The never option specifies that the connector should never use snapshots, instead the connector should proceed to tail the log. |
|
|
empty string |
An optional comma-separated list of the fully-qualified names of fields that should be excluded from change event message values. Fully-qualified names for fields are of the form databaseName.collectionName.fieldName.nestedFieldName, where databaseName and collectionName may contain the wildcard (*) which matches any characters. |
|
|
empty string |
An optional comma-separated list of the fully-qualified replacements of fields that should be used to rename fields in change event message values. Fully-qualified replacements for fields are of the form databaseName.collectionName.fieldName.nestedFieldName:newNestedFieldName, where databaseName and collectionName may contain the wildcard (*) which matches any characters, the colon character (:) is used to determine rename mapping of field. The next field replacement is applied to the result of the previous field replacement in the list, so keep this in mind when renaming multiple fields that are in the same path. |
|
|
|
The maximum number of tasks that should be created for this connector. The MongoDB connector will attempt to use a separate task for each replica set, so the default is acceptable when using the connector with a single MongoDB replica set. When using the connector with a MongoDB sharded cluster, we recommend specifying a value that is equal to or more than the number of shards in the cluster, so that the work for each replica set can be distributed by Kafka Connect. |
|
|
|
Positive integer value that specifies the maximum number of threads used to perform an intial sync of the collections in a replica set. Defaults to 1. |
|
|
|
Controls whether a tombstone event should be generated after a delete event. |
|
|
An interval in milli-seconds that the connector should wait before taking a snapshot after starting up; |
|
|
|
|
Specifies the maximum number of documents that should be read in one go from each collection while taking a snapshot. The connector will read the collection contents in multiple batches of this size. |
The following advanced configuration properties have good defaults that will work in most situations and therefore rarely need to be specified in the connector’s configuration.
| Property | Default | Description |
|---|---|---|
|
|
|
Positive integer value that specifies the maximum size of the blocking queue into which change events read from the database log are placed before they are written to Kafka. This queue can provide backpressure to the oplog reader when, for example, writes to Kafka are slower or if Kafka is not available. Events that appear in the queue are not included in the offsets periodically recorded by this connector. Defaults to 8192, and should always be larger than the maximum batch size specified in the |
|
|
|
Positive integer value that specifies the maximum size of each batch of events that should be processed during each iteration of this connector. Defaults to 2048. |
|
|
|
Positive integer value that specifies the number of milliseconds the connector should wait during each iteration for new change events to appear. Defaults to 1000 milliseconds, or 1 second. |
|
|
|
Positive integer value that specifies the initial delay when trying to reconnect to a primary after the first failed connection attempt or when no primary is available. Defaults to 1 second (1000 ms). |
|
|
|
Positive integer value that specifies the maximum delay when trying to reconnect to a primary after repeated failed connection attempts or when no primary is available. Defaults to 120 seconds (120,000 ms). |
|
|
|
Positive integer value that specifies the maximum number of failed connection attempts to a replica set primary before an exception occurs and task is aborted. Defaults to 16, which with the defaults for |
|
|
|
Boolean value that specifies whether the addresses in 'mongodb.hosts' are seeds that should be used to discover all members of the cluster or replica set ( |
|
|
v2 |
Schema version for the |
|
|
|
Controls how frequently heartbeat messages are sent. Set this parameter to |
|
|
|
Controls the naming of the topic to which heartbeat messages are sent. |
|
|
|
Whether field names will be sanitized to adhere to Avro naming requirements. See Avro namingfor more details. |
這裡以standalone的模式運行,在connect-standalone.properties中做如下配置:
# Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # These are defaults. This file just demonstrates how to override some settings. bootstrap.servers=localhost:9092 rest.port=9093 # The converters specify the format of data in Kafka and how to translate it into Connect data. Every Connect user will # need to configure these based on the format they want their data in when loaded from or stored into Kafka key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter # Converter-specific settings can be passed in by prefixing the Converter's setting with the converter we want to apply # it to key.converter.schemas.enable=false value.converter.schemas.enable=false rest.host.name=0.0.0.0 offset.storage.file.filename=/data4/kafka/connect/connect.offsets # Flush much faster than normal, which is useful for testing/debugging offset.flush.interval.ms=10000 # Set to a list of filesystem paths separated by commas (,) to enable class loading isolation for plugins # (connectors, converters, transformations). The list should consist of top level directories that include # any combination of: # a) directories immediately containing jars with plugins and their dependencies # b) uber-jars with plugins and their dependencies # c) directories immediately containing the package directory structure of classes of plugins and their dependencies # Note: symlinks will be followed to discover dependencies or plugins. # Examples: # plugin.path=/usr/local/share/java,/usr/local/share/kafka/plugins,/opt/connectors, plugin.path=/opt/kafka/kafka_2.11-2.0.0/plugin
standalone模式下啟動方式如下:
bin/connect-standalone.sh config/connect-standalone.properties connector1.properties[connector2.properties ...] 一次可以啟動多個connector,只需要在參數中加上connector的配置文件路徑即可。
例如:connect-standalone.sh config/connect-standalone.properties mongodb.properties
distribute模式部署:
1、修改配置connect-distributed.properties
# broker列表 bootstrap.servers=10.120.241.1:9200 # 同一集群中group.id需要配置一致,且不能和別的消費者同名 group.id=connect-cluster # The converters specify the format of data in Kafka and how to translate it into Connect data. Every Connect user will # need to configure these based on the format they want their data in when loaded from or stored into Kafka key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter # 使用json數據同樣配置成false key.converter.schemas.enable=false value.converter.schemas.enable=false ····
2、手動創建集群模式所必須的kafka的幾個topic
# config.storage.topic=connect-configs $ bin/kafka-topics --create --zookeeper localhost:2181 --topic connect-configs --replication-factor 3 --partitions 1 --config cleanup.policy=compact # offset.storage.topic=connect-offsets $ bin/kafka-topics --create --zookeeper localhost:2181 --topic connect-offsets --replication-factor 3 --partitions 50 --config cleanup.policy=compact # status.storage.topic=connect-status $ $ bin/kafka-topics --create --zookeeper localhost:2181 --topic connect-status --replication-factor 3 --partitions 10 --config cleanup.policy=compact
- config.storage.topic:topic用於存儲connector和任務配置;註意,這應該是一個單個的partition,多副本的topic
- offset.storage.topic:用於存儲offsets;這個topic應該配置多個partition和副本。
- status.storage.topic:用於存儲狀態;這個topic 可以有多個partitions和副本
3、 啟動worker
啟動distributed模式命令如下:
./bin/connect-distributed ./etc/kafka/connect-distributed.properties
4、使用restful啟動connect
curl 'http://localhost:8083/connectors' -X POST -i -H "Content-Type:application/json" -d
'{ "name":"elasticsearch-sink",
"config":{"connector.class":"io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"tasks.max":10,
"topics":"estest1012",
"key.ignore":true,
"schema.ignore":true,
"connection.url":"http://10.120.241.194:9200",
"type.name":"kafka-connect"}
}'
常見問題:
1、在啟動的過程中出現各種各樣的java.lang.ClassNotFoundException。
在啟動connector的時候,一開始總是會報各個各樣的ClassNotFoundException,不是這個包就是那個包,查找問題一直說要麼缺少包要麼是包衝突,那麼要排除依賴衝突或者看下是不是少了jar包。
2、在connector.properties中的key.converter.schemas.enable=false和value.converter.schemas.enable=false的問題。
這個選項預設在connect-standalone.properties中是true的,這個時候發送給topic的Json格式是需要使用avro格式。例如:
{
"schema": {
"type": "struct",
"fields": [{
"type": "int32",
"optional": true,
"field": "c1"
}, {
"type": "string",
"optional": true,
"field": "c2"
}, {
"type": "int64",
"optional": false,
"name": "org.apache.kafka.connect.data.Timestamp",
"version": 1,
"field": "create_ts"
}, {
"type": "int64",
"optional": false,
"name": "org.apache.kafka.connect.data.Timestamp",
"version": 1,
"field": "update_ts"
}],
"optional": false,
"name": "foobar"
},
"payload": {
"c1": 10000,
"c2": "bar",
"create_ts": 1501834166000,
"update_ts": 1501834166000
}
}
如果想發送普通的json格式而不是avro格式的話,很簡單key.converter.schemas.enable和value.converter.schemas.enable設置為false就行。這樣就能發送普通的json格式數據。

