
因為String是非常常用的類, jvm對其進行了優化, jdk7之前jvm維護了很多的字元串常量在方法去的常量池中, jdk後常量池遷移到了堆中 方法區是一個運行時JVM管理的記憶體區域,是一個線程共用的記憶體區域,它用於存儲已被虛擬機載入的類信息、常量、靜態常量等。 使用引號來創建字元串 單獨(註意 ...
因為String是非常常用的類, jvm對其進行了優化, jdk7之前jvm維護了很多的字元串常量在方法去的常量池中, jdk後常量池遷移到了堆中
方法區是一個運行時JVM管理的記憶體區域,是一個線程共用的記憶體區域,它用於存儲已被虛擬機載入的類信息、常量、靜態常量等。
使用引號來創建字元串
- 單獨(註意是單獨)使用引號來創建字元串的方式,字元串都是常量,在編譯期已經確定存儲在常量池中了。
- 用引號創建一個字元串的時候,首先會去常量池中尋找有沒有相等的這個常量對象,沒有的話就在常量池中創建這個常量對象;有的話就直接返回這個常量對象的引用。
所以看這個例子:
String str1 = "hello";
String str2 = "hello";
System.out.println(str1 == str2);//truenew的方式創建字元串
String a = new String("abc");new這個關鍵字,毫無疑問會在堆中分配記憶體,創建一個String類的對象。因此,a這個在棧中的引用指向的是堆中的這個String對象的。
然後,因為"abc"是個常量,所以會去常量池中找,有沒有這個常量存在,沒的話分配一個空間,放這個"abc"常量,並將這個常量對象的空間地址給到堆中String對象裡面;如果常量池中已經有了這個常量,就直接用那個常量池中的常量對象的引用唄,就只需要創建一個堆中的String對象。
new構造方法中傳入字元串常量, 會在堆中創建一個String對象, 但是這個對象不會再去新建字元數組(value) 來存儲內容了, 會直接使用字元串常量對象中字元數組(value)應用,
具體方法參考
/** * Initializes a newly created {@code String} object so that it represents * the same sequence of characters as the argument; in other words, the * newly created string is a copy of the argument string. Unless an * explicit copy of {@code original} is needed, use of this constructor is * unnecessary since Strings are immutable. * * @param original * A {@code String} */ public String(String original) { this.value = original.value; //只是把傳入對象的value和引用傳給新的對象, 兩個對象其實是共用同一個數組 this.hash = original.hash; }value 雖然是private修飾的, 但是構造方法中通過original.value;還是可以直接獲取另外一個對象的值. 因為這兩個對象是相同的類的對象
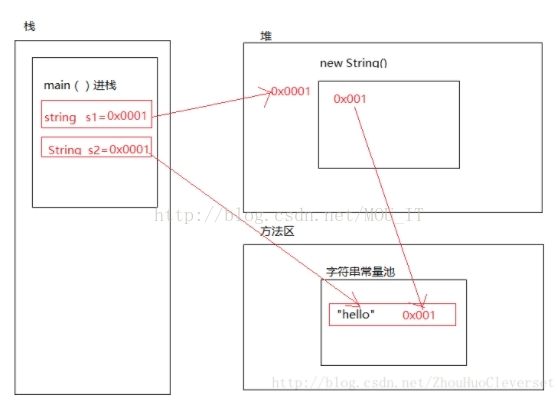
所以有下麵的結果
public static void main(String[] args) {
String s1 = new String("hello");
String s2 = "hello";
String s3 = new String("hello");
System.out.println(s1 == s2);// false
System.out.println(s1.equals(s2));// true
System.out.println(s1 == s3);//false
}關於“+”運算符
常量直接相加:
String s1 = "hello" + "word";
String s2 = "helloword";
System.out,println(s1 == s2);//true這裡的true 是因為編譯期直接就把 s1 優化成了 String s1 = "helloword"; 所以後面相等
非常量直接相加
public static void main(String[] args) {
String s1 = "a";
String s2 = "b";
String s3 = new String("b");
String s4 = s1 + s3;
String s5="ab";
String s6 = s1 + s2;
String s66= s1 + s2;
String s7 = "a" + s2;
String s8 = s1 + "b";
String s9 = "a" + "b";
System.out.println(s2 == s3); //false
System.out.println(s4 == s5); //false s4 是使用了StringBulider來相加了
System.out.println(s4 == s6); //false s4和s6 兩個都是使用了StringBulider來相加了
System.out.println(s6 == s66); //false 兩個都是使用了StringBulider來相加了
System.out.println(s5 == s7); //false s7是使用了StringBulider來相加了
System.out.println(s5 == s8); //false s8是使用了StringBulider來相加了
System.out.println(s7 == s8); //false 兩個都是使用了StringBulider來相加了
System.out.println(s9 == s8); //false 兩個都是使用了StringBulider來相加了
}總結下就是:
兩個或者兩個以上的字元串常量直接相加,在預編譯的時候“+”會被優化,相當於把兩個或者兩個以上字元串常量自動合成一個字元串常量.
編譯期就會優化, 編譯的位元組碼直接就把加號去掉了, 直接定義一個常量
其他方式的字元串相加都會使用到 StringBuilder的.
String的intern()方法.
這是一個native的方法,書上是這樣描述它的作用的:如果字元串常量池中已經包含一個等於此String對象的字元串,則返回代表池中這個字元串的String對象;否則,將此String對象包含的字元添加到常量池中,並返回此String對象的引用。
並提到,在JDK1.6及其之前的版本,由於常量池分配在永久代內,我們可以通過-XX:PermSize和-XX:MaxPermSize限制方法區的大小從而間接限制常量池的容量。
不僅如此,在intern方法返回的引用上,JDK1.6和JDK1.7也有個地方不一樣,來看看書本上給的例子:
public static void main(String[] args) {
String str1 = new StringBuilder("電腦").append("軟體").toString();
System.out.println(str1.intern() == str1);
String str2 = new StringBuilder("ja").append("va").toString();
System.out.println(str2.intern() == str2);
}這段代碼在JDK1.6中,會得到兩個false,在JDK1.7中運行,會得到一個true和一個false。
書上說,產生差異的原因是:在JDK1.6中,intern()方法會把首次遇到的字元串實例複製到永久代中,返回的也是永久代中這個字元串實例的引用,而由StringBuilder創建的字元串實例在Java堆上,所以必然不是同一個引用,將返回false。
而JDK1.7的intern()不會再複製實例,只是在常量池中記錄首次出現的實例的引用,因此intern()返回的引用和StringBuilder創建的那個字元串的實例是同一個。對str2比較返回false是因為"java"這個字元串在執行StringBuilder.toString()之前就已經出現過,字元串常量池中已經有它的引用了,不符合“首次出現”的原則,而“電腦軟體”這個字元串則是首次出現的,因此返回true。
jdk6和7 的差異是因為 7中常量池移動到堆中了, 並且對於常量池的處理也有差異, 6會把堆中的字元串複製一份副本到常量池中,
7 只是把堆中的字元串對象的引用放入常量池中, 所以第一個str1.intern()返回的也只是一個指向堆中對象的引用, 所以第一個出現false.
7的第二個false 是因為常量池中已經有了"Java"對象了, 所以str2.intern()返回的是指向常量池中對象的引用, str2是指向堆中對象的引用, 所以false
stringTable的小說明
只是為了提高速度, 把常量池中的字元串常量維護了一個hashTable. 方便查找常量
這裡先再提一下字元串常量池,實際上,為了提高匹配速度,也就是為了更快地查找某個字元串是否在常量池中,Java在設計常量池的時候,還搞了張stringTable,這個有點像我們的hashTable,根據字元串的hashCode定位到對應的桶,然後遍曆數組查找該字元串對應的引用。如果找得到字元串,則返回引用,找不到則會把字元串常量放到常量池中,並把引用保存到stringTable了裡面。
在JDK7、8中,可以通過-XX:StringTableSize參數StringTable大小
jdk1.6及其之前的intern()方法
在JDK6中,常量池在永久代分配記憶體,永久代和Java堆的記憶體是物理隔離的,執行intern方法時,如果常量池不存在該字元串,虛擬機會在常量池中複製該字元串,並返回引用;如果已經存在該字元串了,則直接返回這個常量池中的這個常量對象的引用。所以需要謹慎使用intern方法,避免常量池中字元串過多,導致性能變慢,甚至發生PermGen記憶體溢出。
看一個圖片來理解下:(圖片來自https://blog.csdn.net/soonfly/article/details/70147205)
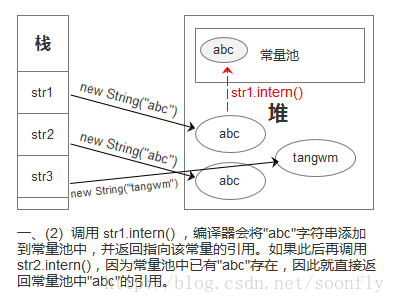
當然,這個常量池和堆是物理隔離的。
總之就是,要抓住“複製”這個字眼,常量池中存的是內容為"abc"的常量對象。
看個詳細點的例子:
public static void main(String[] args) {
String a = new String("haha");
System.out.println(a.intern() == a);//false
}首先,見到"haha",產量池中沒有這個常量,所以會在常量池中放下這個常量對象,底層是通過ldc命令,"haha"被添加到字元串常量池,然後在stringTable中添加該常量的引用(引用好像是這個String對象中的char數組的地址),而a這個引用指向的是堆中這個String對象的地址,所以肯定是不同的。(而且一個在堆,一個在方法區中)。
jdk1.7的intern()方法
JDK 1.7後,intern方法還是會先去查詢常量池中是否有已經存在,如果存在,則返回常量池中的引用,這一點與之前沒有區別,區別在於,如果在常量池找不到對應的字元串,則不會再將字元串拷貝到常量池,而只是在常量池中生成一個對原字元串的引用。簡單的說,就是往常量池放的東西變了:原來在常量池中找不到時,複製一個副本放到常量池,1.7後則是將在堆上的地址引用複製到常量池。
當然這個時候,常量池被從方法區中移出來到了堆中。
看個圖:
(圖片來自https://blog.csdn.net/soonfly/article/details/70147205)
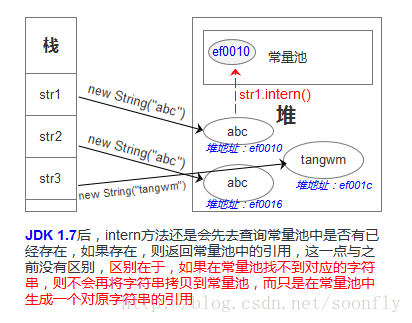
所以再看回我們書上的那個例子
public static void main(String[] args) {
String str1 = new StringBuilder("電腦").append("軟體").toString();
System.out.println(str1.intern() == str1);
String str2 = new StringBuilder("ja").append("va").toString();
System.out.println(str2.intern() == str2);再看一個例子:
String str2 = new String("str")+new String("01");
str2.intern();
String str1 = "str01";
System.out.println(str2==str1);//true這個返回true的原因也一樣,str2的時候,只有一個堆的String對象,然後調用intern,常量池中沒有“str01”這個常量對象,於是常量池中生成了一個對這個堆中string對象的引用。
然後給str1賦值的時候,因為是帶引號的,所以去常量池中找,發現有這個常量對象,就返回這個常量對象的引用,也就是str2引用所指向的堆中的String對象的地址。
所以str2和str1指向的是同一個東西,所以為true。
jdk7中雖然是把引用複製到常量池中, 但是不影響常量池的功能, 常量池就是減少常量的創建, 增加性能. 常量池中是引用還是能起到減少常量的作用, 因為引用最終還是會指向真實的對象.
參考博客
https://www.cnblogs.com/wangshen31/p/10404353.html


