
目錄: 一、列表推導式 二、生成器表達式 三、集合生成器 四、生成器面試題 五、解耦簡單介紹 六、函數遞歸相關 一、列表推導式 需求:將[1,3,5]中的每個元素平方 正常思路: 1 new_list = [] 2 for i in [1,3,5]: 3 new_list.append(i*i) 4 ...
目錄:
一、列表推導式
需求:將[1,3,5]中的每個元素平方
正常思路:
1 new_list = []
2 for i in [1,3,5]:
3 new_list.append(i*i)
4 print(new_list) #輸出結果:[1, 9, 25]
列表推導式:以[ ]框住裡面的內容
print([i*i for i in [1,3,5]]) #輸出結果:[1, 9, 25]
列表推導式圖示流程:

可以看出列表推導式的作用就是簡化代碼
列表推導式例題:
print([i*i for i in range(10) if i %3 == 0]) #[0, 9, 36, 81]
2.輸出列表每一個包含‘o’元素的字元串
list_case = [['one','two','three'],['four','five','six']]
正常思路:
1 list_case = [['one','two','three'],['four','five','six']]
2 for i in list_case:
3 for v in i:
4 if v.count('o')>0:
5 print(v)
列表推導式:
list_case = [['one','two','three'],['four','five','six']]
print([v for i in list_case for v in i if v.count('o')>0])
二、生成器表達式:
以( )框住裡面的內容,就是把列表表達式的[ ]改成( ),就是生成器表達式
例如:
1 case = ('第%d個人' %i for i in range(3))
從生成器中取值的三種方法:

生成器表達式作用:節省記憶體,簡化代碼,相比較列表表達式多了一個節省記憶體的作用,那是因為生成器具有惰性求值的特性
生成一個人生成器歸生成,我記憶體不會載入他,只有當你用的時候我才去載入他。
用戶要一個數據,生成器就給一個數據,比如前面例題的range(3),列表表達式就是一下子生成3個,生成器表達式就是你要一個我生成一個。
三、集合生成器:
以{ }框住裡面的內容,自帶去重功能
lis_case = [-1,1,2,3]
print({i*i for i in lis_case}) #輸出結果{1, 4, 9}
在以後工作中,列表推導式最常用,但是儘量把列表推導式變成生成器推導式,因為這樣節省記憶體,節省記憶體的思想應該處處體現在代碼里,這樣才能體現水平。
四、生成器表達式面試題:
有如下代碼:問輸出的結果是什麼?
1 def demo():
2 for i in range(4):
3 yield i
4 g=demo()
5 g1=(i for i in g)
6 g2=(i for i in g1)
7 print(list(g1))
8 print(list(g2))
答案:
[0, 1, 2, 3]
[]
考點:
記憶體載入第5行和第6行的時候是不會載入裡面的內容的,然後第7行調用g1的時候記憶體才會去載入g1的內容
g1本質上是一個生成器推導式,只能用一次,所以第7行print一次之後,g1就是空列表了
生成器練習題:問輸出結果是啥?
1 def add(n,i):
2 return n+i
3 def test():
4 for i in range(4):
5 yield i
6 g=test()
7 for n in [1,10,5]:
8 g=(add(n,i) for i in g)
9 print(list(g))
上面的代碼可以這樣理解:
1 # def add(n,i):
2 # return n+i
3 # def test():
4 # for i in range(4):
5 # yield i
6 # g=test()
7 # n = 1:
8 # g=(add(n,i) for i in g)
9 # n = 10:
10 # g=(add(n,i) for i in (add(n,i) for i in g))
11 # n = 5:
12 # g=(add(n,i) for i in (add(n,i) for i in (add(n,i) for i in g)))
13 # print(list(g))
代碼解釋:
7~12行代碼還是會運行,但只是計算 g=什麼 ,並不會計算=後面的具體內容,只有後面真正調用g的時候,即(list(g)),這個時候才會回去執行g=後面的內容。
五、解耦簡單介紹:
先看一個需求:
寫函數,將“從前有座山,山裡有個廟,廟裡有個老和尚講故事,講的什麼呀?”列印10遍
一般寫法:
def func_case():
for i in range(10):print('從前有座山,山裡有個廟,廟裡有個老和尚講故事,講的什麼呀?')
func_case()
解耦思想寫法:
1 def func_case():
2 print('從前有座山,山裡有個廟,廟裡有個老和尚講故事,講的什麼呀?')
3 for i in range(10):
4 func_case()
這樣寫的好處就可以在不動第一個函數的情況下,修改列印的次數,一般寫法中如果要修改列印次數是直接修改的是函數內部的內容,這樣會影響代碼質量。
解耦的定義:
要完成一個完整的功能,但這個功能的規模要儘量小,並且和這個功能無關的其他代碼應該和這個函數分離
解耦的作用:
1.增強代碼的重用性
2.減少代碼變更的相互影響
六、函數遞歸:
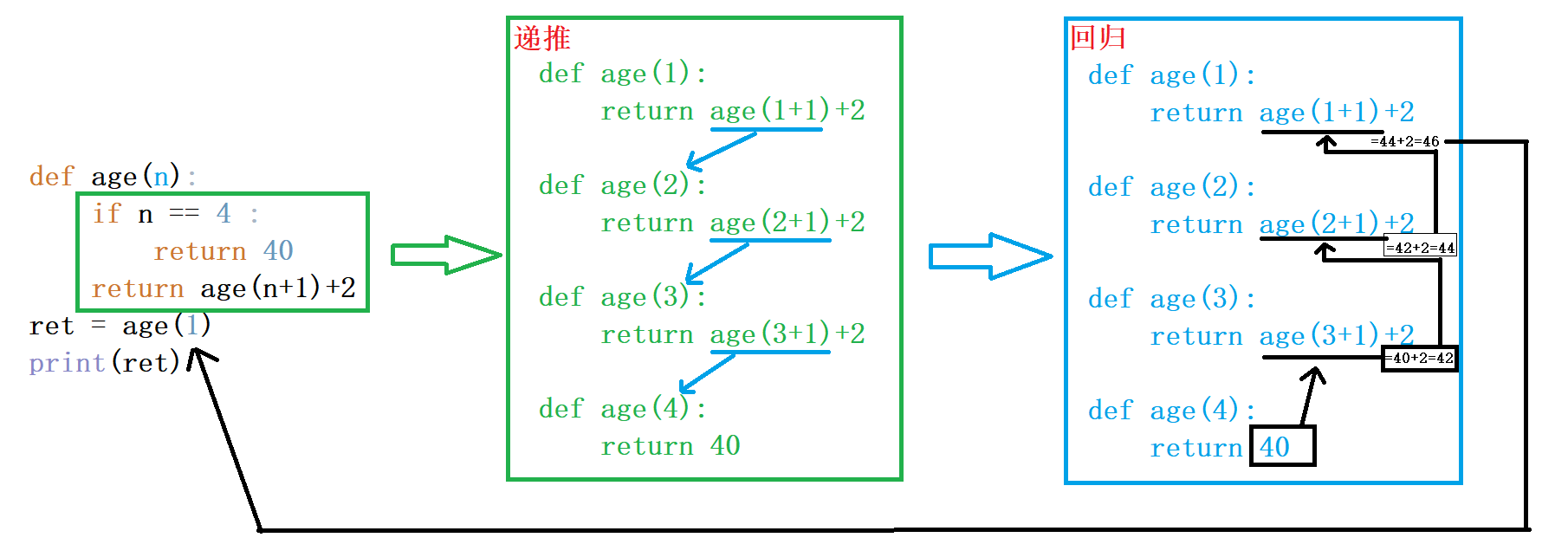
遞歸:一個函數在內部調用自己就叫做遞歸,遞歸在函數內部分為遞推、回歸兩個流程,python解釋器規定遞歸層數是有限制的(一般為997層),寫遞歸函數時必須要有一個結束條件。
例如需求:1的年齡比2大兩歲,2的年齡比3大兩歲,3的年齡比4大兩歲,4的年齡是40歲,用函數方式計算1的年齡。
這個需求就是典型的遞歸問題,下麵是代碼示例:
1 def age(n):
2 if n == 4 :
3 return 40
4 return age(n+1)+2
5 ret = age(1)
6 print(ret)
代碼解釋:
遞歸實例:
用戶輸入數字n,求n的階乘:
1 n = int(input(">>>:"))
2 def func(n):
3 if n == 1:return 1
4 return n*func(n-1)
5 print(func(n))
斐波那契:
1 n = int(input(">>>:"))
2 def fib(n):
3 if n == 1 or n == 2:return 1
4 return fib(n-1)+fib(n-2)
5 print(fib(n))
二分法查找索引位置:(需要背過)
1 def search(num,l,start=None,end=None):
2 start = start if start else 0
3 end = end if end else len(l) - 1
4 mid = (end - start)//2 + start
5 if start > end:
6 return None
7 elif l[mid] > num : #17,17
8 return search(num,l,start,mid-1)
9 elif l[mid] < num:
10 return search(num,l,mid+1,end)
11 elif l[mid] == num:
12 return mid
13 l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88]
14 print(search(66,l))
三級菜單:


menu = { '北京': { '海澱': { '五道口': { 'soho': {}, '網易': {}, 'google': {} }, '中關村': { '愛奇藝': {}, '汽車之家': {}, 'youku': {}, }, '上地': { '百度': {}, }, }, '昌平': { '沙河': { '老男孩': {}, '北航': {}, }, '天通苑': {}, '回龍觀': {}, }, '朝陽': {}, '東城': {}, }, '上海': { '閔行': { "人民廣場": { '炸雞店': {} } }, '閘北': { '火車戰': { '攜程': {} } }, '浦東': {}, }, '山東': {}, }menu內容
1 def Three_Level_Menu(menu):
2 while True:
3 for k in menu:print(k)
4 key = input('>>>(輸入q退出,輸入b返回上一層):')
5 if key == 'q':return 'q'
6 elif key == 'b':break
7 elif key in menu:
8 ret = Three_Level_Menu(menu[key])
9 if ret == 'q': return 'q'
10 Three_Level_Menu(menu)


