
HashSet and HashMap "本文github地址" 總體介紹 之所以把 HashSet 和 HashMap 放在一起講解,是因為二者在Java里有著相同的實現,前者僅僅是對後者做了一層包裝,也就是說 HashSet 裡面有一個 HashMap (適配器模式) 。因此本文將重點分析 Ha ...
HashSet and HashMap
總體介紹
之所以把HashSet和HashMap放在一起講解,是因為二者在Java里有著相同的實現,前者僅僅是對後者做了一層包裝,也就是說HashSet裡面有一個HashMap(適配器模式)。因此本文將重點分析HashMap。
HashMap實現了Map介面,允許放入null元素,除該類未實現同步外,其餘跟Hashtable大致相同,跟TreeMap不同,該容器不保證元素順序,根據需要該容器可能會對元素重新哈希,元素的順序也會被重新打散,因此不同時間迭代同一個HashMap的順序可能會不同。
根據對衝突的處理方式不同,哈希表有兩種實現方式,一種開放地址方式(Open addressing),另一種是衝突鏈表方式(Separate chaining with linked lists)。Java HashMap採用的是衝突鏈表方式。

從上圖容易看出,如果選擇合適的哈希函數,put()和get()方法可以在常數時間內完成。但在對HashMap進行迭代時,需要遍歷整個table以及後面跟的衝突鏈表。因此對於迭代比較頻繁的場景,不宜將HashMap的初始大小設的過大。
有兩個參數可以影響HashMap的性能:初始容量(inital capacity)和負載繫數(load factor)。初始容量指定了初始table的大小,負載繫數用來指定自動擴容的臨界值。當entry的數量超過capacity*load_factor時,容器將自動擴容並重新哈希。對於插入元素較多的場景,將初始容量設大可以減少重新哈希的次數。
方法剖析
get()
get(Object key)方法根據指定的key值返回對應的value,該方法調用了getEntry(Object key)得到相應的entry,然後返回entry.getValue()。因此getEntry()是演算法的核心。
演算法思想是首先通過hash()函數得到對應bucket的下標,然後依次遍歷衝突鏈表,通過key.equals(k)方法來判斷是否是要找的那個entry。
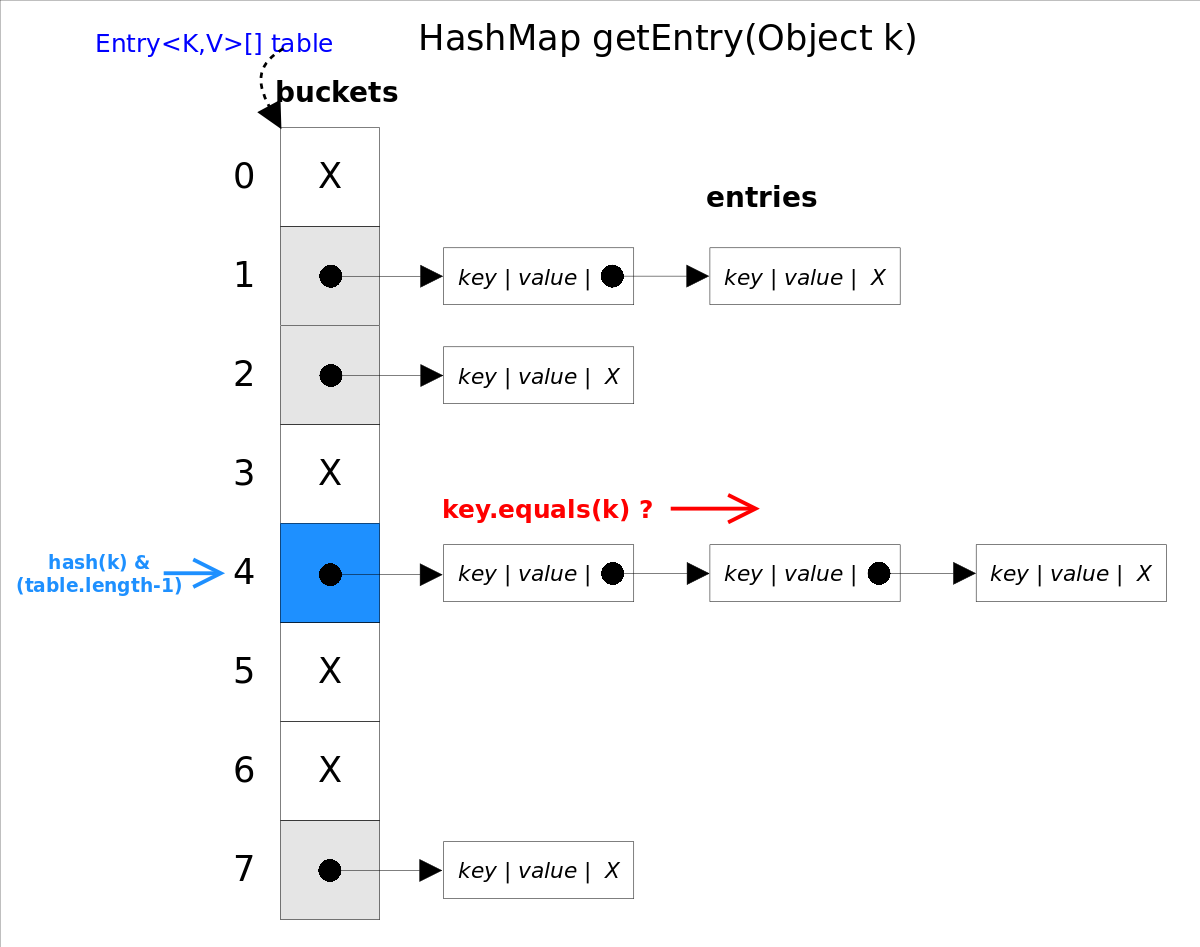
上圖中hash(k)&(table.length-1)等價於hash(k)%table.length,原因是HashMap要求table.length必須是2的指數,因此table.length-1就是二進位低位全是1,跟hash(k)相與會將哈希值的高位全抹掉,剩下的就是餘數了。
//getEntry()方法
final Entry<K,V> getEntry(Object key) {
......
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[hash&(table.length-1)];//得到衝突鏈表
e != null; e = e.next) {//依次遍歷衝突鏈表中的每個entry
Object k;
//依據equals()方法判斷是否相等
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}put()
put(K key, V value)方法是將指定的key, value對添加到map里。該方法首先會對map做一次查找,看是否包含該元組,如果已經包含則直接返回,查找過程類似於getEntry()方法;如果沒有找到,則會通過addEntry(int hash, K key, V value, int bucketIndex)方法插入新的entry,插入方式為頭插法。
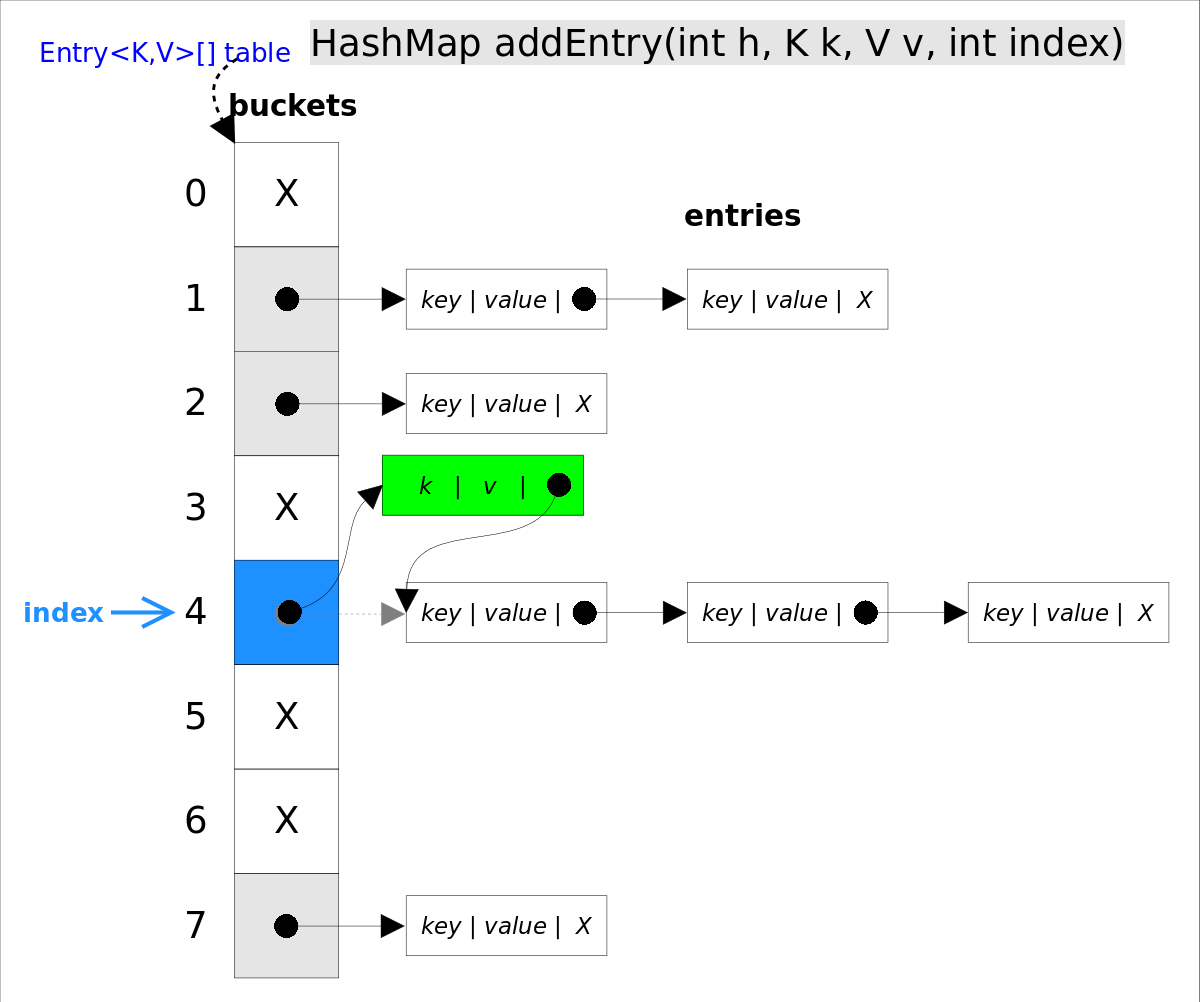
//addEntry()
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);//自動擴容,並重新哈希
hash = (null != key) ? hash(key) : 0;
bucketIndex = hash & (table.length-1);//hash%table.length
}
//在衝突鏈表頭部插入新的entry
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}remove()
remove(Object key)的作用是刪除key值對應的entry,該方法的具體邏輯是在removeEntryForKey(Object key)里實現的。removeEntryForKey()方法會首先找到key值對應的entry,然後刪除該entry(修改鏈表的相應指針)。查找過程跟getEntry()過程類似。

//removeEntryForKey()
final Entry<K,V> removeEntryForKey(Object key) {
......
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);//hash&(table.length-1)
Entry<K,V> prev = table[i];//得到衝突鏈表
Entry<K,V> e = prev;
while (e != null) {//遍歷衝突鏈表
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {//找到要刪除的entry
modCount++; size--;
if (prev == e) table[i] = next;//刪除的是衝突鏈表的第一個entry
else prev.next = next;
return e;
}
prev = e; e = next;
}
return e;
}HashSet
前面已經說過HashSet是對HashMap的簡單包裝,對HashSet的函數調用都會轉換成合適的HashMap方法,因此HashSet的實現非常簡單,只有不到300行代碼。這裡不再贅述。
//HashSet是對HashMap的簡單包裝
public class HashSet<E>
{
......
private transient HashMap<E,Object> map;//HashSet裡面有一個HashMap
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
......
public boolean add(E e) {//簡單的方法轉換
return map.put(e, PRESENT)==null;
}
......
}

