在如今併發的環境下,對大數據量的查詢採用緩存是最好不過的了,本文使用redis搭建集群 (個人喜歡redis,對memcache不感冒) redis是3.0後增加的集群功能,非常強大 集群中應該至少有三個節點,每個節點有一備份節點。這樣算下來至少需要6台伺服器 考慮到有些朋友的電腦配置不是很高,跑多 ...
在如今併發的環境下,對大數據量的查詢採用緩存是最好不過的了,本文使用redis搭建集群
(個人喜歡redis,對memcache不感冒)
redis是3.0後增加的集群功能,非常強大
集群中應該至少有三個節點,每個節點有一備份節點。這樣算下來至少需要6台伺服器
考慮到有些朋友的電腦配置不是很高,跑多個虛擬機就會卡,這邊放出偽分散式和分散式
(2年前的配置)

前提先裝好一個單例情況下的redis(這裡就不多說了)
需要6個redis實例
搭建集群的步驟:
在/usr/local下 創建文件夾
 這個我是把原來的單例redis改了個名字做的
這個我是把原來的單例redis改了個名字做的

 進入redis01/bin
刪除dump文件
進入redis01/bin
刪除dump文件

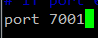
 修改埠
修改埠
 打開註釋
打開註釋
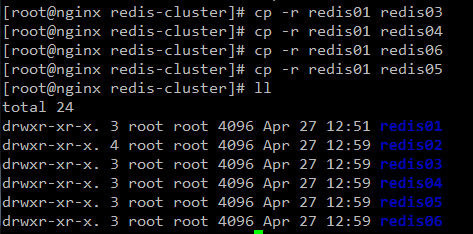
 複製多份
(真實環境下只需要一個就行,然後其餘5台機子重覆以上操作)
複製多份
(真實環境下只需要一個就行,然後其餘5台機子重覆以上操作)
 指定埠從7001到7006
這是真實環境下的
指定埠從7001到7006
這是真實環境下的
 占用率
占用率
 在redis源碼文件夾下的src目錄下。redis-trib.rb,這個ruby腳本
在redis源碼文件夾下的src目錄下。redis-trib.rb,這個ruby腳本
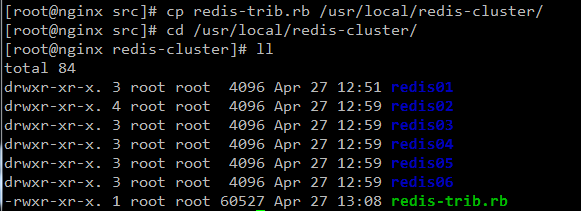
 第四步:把redis-trib.rb文件複製到到redis-cluster目錄下。
(真實環境下,只需要放在你某個節點機子上就行,他會自動遍歷到其他的節點上的,我做的時候放在了01上)
第四步:把redis-trib.rb文件複製到到redis-cluster目錄下。
(真實環境下,只需要放在你某個節點機子上就行,他會自動遍歷到其他的節點上的,我做的時候放在了01上)
 執行ruby腳本之前,需要安裝ruby環境,不然裝不了
yum install ruby
執行ruby腳本之前,需要安裝ruby環境,不然裝不了
yum install ruby

 yum install rubygems
yum install rubygems

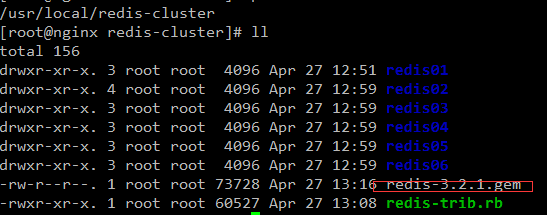
 安裝redis-trib.rb運行依賴的ruby的包
這個gem可以網上下載,很多
安裝redis-trib.rb運行依賴的ruby的包
這個gem可以網上下載,很多
 (真實環境下只需要在其中一臺機子上運行就行了)
(真實環境下只需要在其中一臺機子上運行就行了)

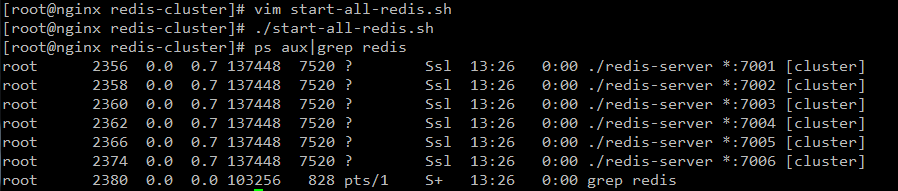
 進入各自的redis文件夾,分別啟動所有的redis實例
進入各自的redis文件夾,分別啟動所有的redis實例
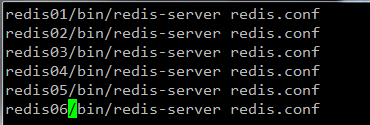 啟動成功
啟動成功
 使用redis-trib.rb創建集群
不管是不是偽分散式,這隻需要啟動一次
使用redis-trib.rb創建集群
不管是不是偽分散式,這隻需要啟動一次
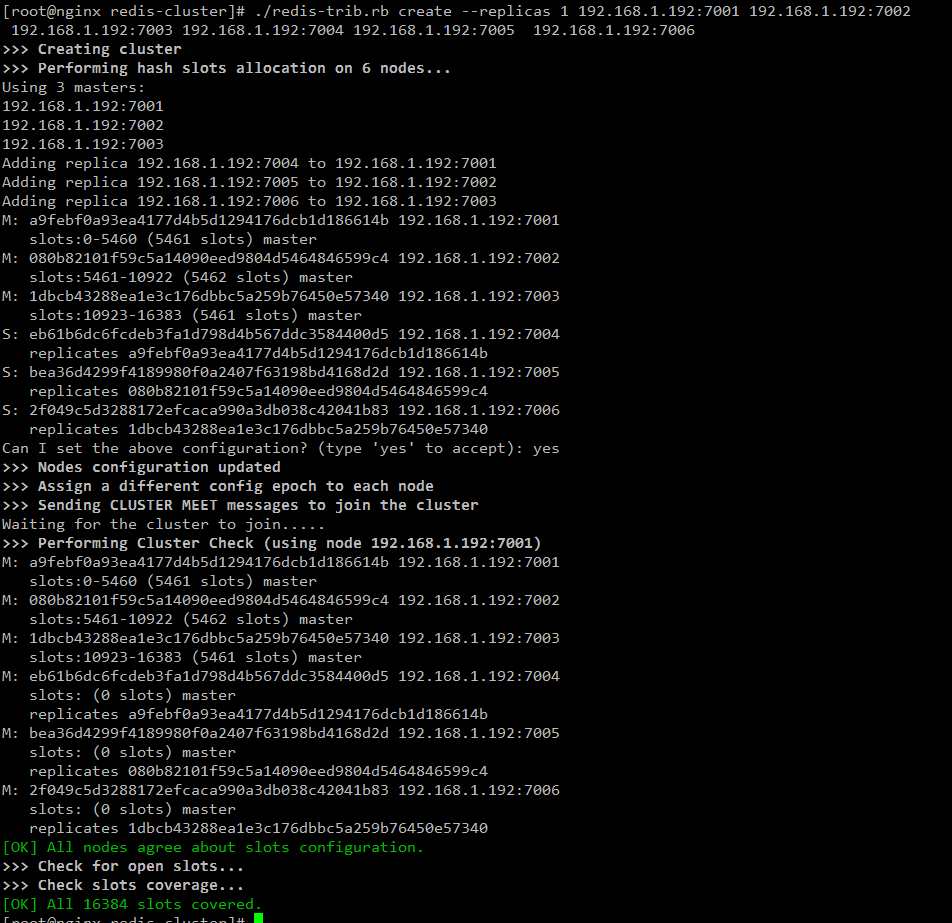 成功~!
鏈接第一個節點
成功~!
鏈接第一個節點
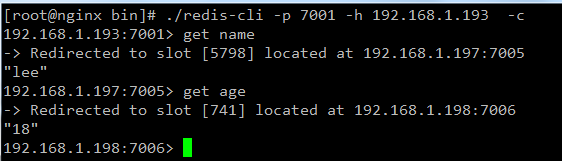
 下麵演示使用jedis來讀寫緩存
當然加入spring中一定要使用單例
下麵演示使用jedis來讀寫緩存
當然加入spring中一定要使用單例
1 @Test 2 public void testCluster() throws Exception { 3 Set<HostAndPort> nodes = new HashSet<>(); 4 nodes.add(new HostAndPort("192.168.1.193", 7001)); 5 nodes.add(new HostAndPort("192.168.1.194", 7002)); 6 nodes.add(new HostAndPort("192.168.1.195", 7003)); 7 nodes.add(new HostAndPort("192.168.1.196", 7004)); 8 nodes.add(new HostAndPort("192.168.1.197", 7005)); 9 nodes.add(new HostAndPort("192.168.1.198", 7006)); 10 JedisCluster jedisCluster = new JedisCluster(nodes); 11 jedisCluster.set("name", "lee"); 12 jedisCluster.set("age", "18"); 13 String name = jedisCluster.get("name"); 14 String value = jedisCluster.get("age"); 15 System.out.println(name); 16 System.out.println(value); 17 jedisCluster.close(); 18 }
運行結果:
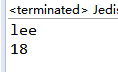
可以看到redis客戶端上取數據的時候IP是不一樣的