
什麼是索引? “索引”是為了能夠更快地查詢數據。比如一本書的目錄,就是這本書的內容的索引,讀者可以通過在目錄中快速查找自己想要的內容,然後根據頁碼去找到具體的章節。 資料庫也是一樣,如果查詢語句使用到了索引,會先去索引裡面查詢,取得數據所在行的物理地址,進而訪問數據。 索引的優缺點 優勢:以快速檢索 ...
什麼是索引?
“索引”是為了能夠更快地查詢數據。比如一本書的目錄,就是這本書的內容的索引,讀者可以通過在目錄中快速查找自己想要的內容,然後根據頁碼去找到具體的章節。 資料庫也是一樣,如果查詢語句使用到了索引,會先去索引裡面查詢,取得數據所在行的物理地址,進而訪問數據。 索引的優缺點 優勢:以快速檢索,減少I/O次數,加快檢索速度;根據索引分組和排序,可以加快分組和排序; 劣勢:索引本身也是表,因此會占用存儲空間。索引的維護和創建需要時間成本,這個成本隨著數據量增大而增大;構建索引會降低數據表的修改操作(刪除,添加,修改)的效率,因為在修改數據表的同時還需要修改索引表。
索引的分類 在MySQL中,常見的索引類型有:主鍵索引、唯一索引、普通索引、全文索引、組合索引。創建語法分別為:
其中,組合索引又稱為多列索引,上述代碼中最後一個例子就是建立了3列的索引。MySQL在根據索引查詢時,會遵循“最左匹配”原則,即先根據col1的條件查,再根據col2的條件查,然後再根據col3的條件去查。 如果跳過了一個列直接查後面的列,比如下麵的語句,就不能使用上面創建的索引了:

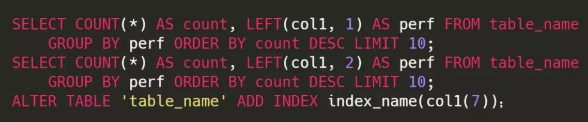
這裡有一個小技巧,如果你前面的列是一個簡單的枚舉類型,比如性別等,可以用在where語句中加 col1 in(MALE, FEMALE) 來“跳過” col1 列,並使用上述索引。 對於某列如果是字元串且比較長(比如UUID),推薦使用首碼索引,即匹配前n個字元。具體這個n取值多少是根據你的數據來的,通過使用 LEFT 函數查詢,從1開始,不斷增加n的值,直到查詢結果的行數接近完整列的查詢結果的行數,就是合適的n的值。
索引的實現原理
MySQL的索引是由存儲引擎來實現的。由於存儲引擎不同,所以具有不同的索引類型,如BTree索引,B+Tree索引,哈希索引,全文索引等。這裡由於主要介紹BTree索引和B+Tree索引,我們平時使用最多的InnoDB引擎就是基於B+Tree索引的。 目前版本的MySQL InnoDB引擎已經支持全文索引,但不支持中文,可以通過使用ngram插件開始支持中文。 從二叉搜索樹開始
瞭解過數據結構的應該知道一種叫二叉樹的數據結構。二叉樹根據用途不同,衍生了不同的變種,比如堆,比如二叉搜索樹。
而二叉搜索樹中,為了防止極端情況樹的高度過大影響查詢效率,所以衍生出了一些平衡二叉查找樹,最典型的就是AVL和紅黑樹。
但二叉樹在數據量較大時,深度過深,不太適合資料庫的查詢,所以資料庫使用了多叉樹。
BTree
BTree(又稱為B-Tree)是一個平衡搜索多叉樹。BTree的結構如下圖:
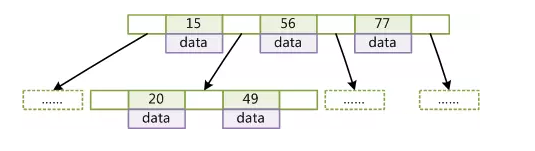
設樹的度為2d(d>1),高度為h,那麼BTree有以下性質: 每個葉子結點的高度一樣,等於h; 每個非葉子結點由n-1個key和n個指針組成,key和指針相互隔離,結點兩端一定是key; 葉子結點指針為null; 非葉子結點的key都是[key,data]二元組,其中key表示作為索引的鍵,data為鍵值所在行的其它列的數據; 在BTree中,對索引列是順序存儲的,所以很適合查找範圍數據和ORDER BY操作。
B+Tree
B+Tree是BTree的一種變種。B+Tree和BTree的不同主要在於: B+Tree中的非葉子結點不存儲數據,只存儲鍵值; B+Tree的葉子結點沒有指針,所有鍵值都會出現在葉子結點上,且key存儲的鍵值對應data數據的物理地址; B+Tree的每個非葉子節點由n個鍵值key和n個指針point組成; 結構圖:
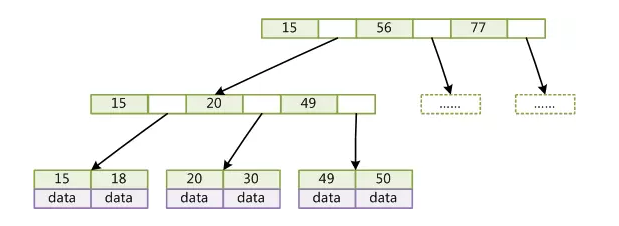
B+Tree對比BTree的優點:
一般來說B+Tree比BTree更適合實現外存的索引結構,因為存儲引擎的設計專家巧妙的利用了外存(磁碟)的存儲結構。
磁碟的最小存儲單位是扇區(sector),而操作系統的塊(block)通常是整數倍的sector,操作系統以頁(page)為單位管理記憶體,一頁(page)通常預設為4K,資料庫的頁通常設置為操作系統頁的整數倍,因此索引結構的節點被設計為一個頁的大小,然後利用外存的“預讀取”原則,每次讀取的時候,把整個節點的數據讀取到記憶體中,然後在記憶體中查找。
已知記憶體的讀取速度是外存讀取I/O速度的幾百倍,那麼提升查找速度的關鍵就在於儘可能少的磁碟I/O,那麼可以知道,每個節點中的key個數越多,那麼樹的高度越小,需要I/O的次數越少,因此一般來說B+Tree比BTree更快,因為B+Tree的非葉節點中不存儲data,就可以存儲更多的key。
帶順序索引的B+Tree
一般在資料庫系統或文件系統中使用的B+Tree結構都在經典B+Tree的基礎上進行了優化,增加了順序訪問指針。

在B+Tree的每個葉子節點增加一個指向相鄰葉子節點的指針,就形成了帶有順序訪問指針的B+Tree。做這個優化的目的是為了提高區間訪問的性能,例如如果要查詢key為從18到49的所有數據記錄,當找到18後,只需順著節點和指針順序遍歷就可以一次性訪問到所有數據節點,不用從頭再查詢一次,極大提到了區間查詢效率。
聚簇索引和非聚簇索引
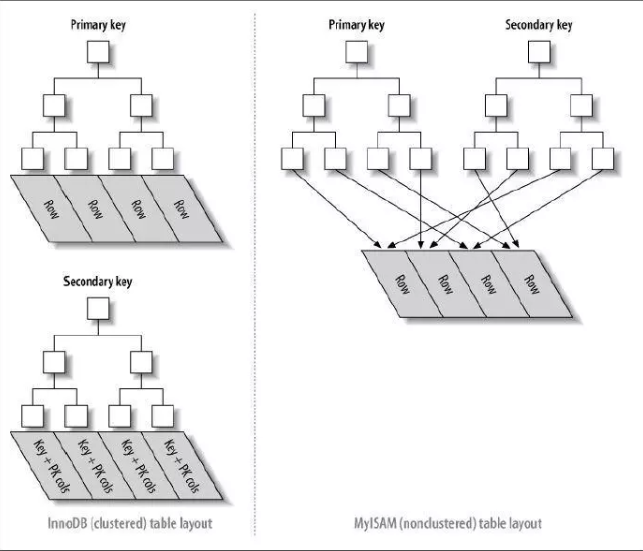
MySQL中最常見的兩種存儲引擎分別是MyISAM和InnoDB,分別實現了非聚簇索引和聚簇索引。
前段時間看到一個問題:“你知道為什麼InnoDB非主鍵索引普遍比主鍵索引要慢嗎?”答案是InnoDB使用了聚簇索引,主鍵索引主需要查詢一次,而非主鍵索引需要查詢兩次。
為什麼非主鍵索引需要查詢兩次呢?且看接下來的內容。
主索引與輔助索引
首先介紹一下基礎的概念。在索引的分類中,我們可以按照索引的鍵是否為主鍵來分為“主索引”和“輔助索引”,使用主鍵鍵值建立的索引稱為“主索引”,其它的稱為“輔助索引”。因此主索引只能有一個,輔助索引可以有很多個。
為什麼需要用到輔助索引?因為前面我們介紹了,查詢語句如果想要使用索引,是需要滿足最左匹配原則的。有時候我們的查詢並不會使用到主鍵列,所以需要在其它列建立索引,即輔助索引。
非聚簇索引
非聚簇索引的主索引和輔助索引幾乎是一樣的,只是主索引不允許重覆,不允許空值,他們的葉子結點的key都存儲指向鍵值對應的數據的物理地址。
非聚簇索引的數據表和索引表是分開存儲的。非聚簇索引中的數據是根據數據的插入順序保存。因此非聚簇索引更適合單個數據的查詢。插入順序不受鍵值影響。
聚簇索引
聚簇索引的主索引的葉子結點存儲的是鍵值對應的數據本身,輔助索引的葉子結點存儲的是鍵值對應的數據的主鍵鍵值。因此主鍵的值長度越小越好,類型越簡單越好。
聚簇索引的數據和主鍵索引存儲在一起。
聚簇索引的數據是根據主鍵的順序保存。因此適合按主鍵索引的區間查找,可以有更少的磁碟I/O,加快查詢速度。但是也是因為這個原因,聚簇索引的插入順序最好按照主鍵單調的順序插入,否則會頻繁的引起頁分裂(BTree插入時的一個操作),嚴重影響性能。 在InnoDB中,如果只需要查找索引的列,就儘量不要加入其它的列,這樣會提高查詢效率。 聚簇索引與非聚簇索引的區別:
 對於很多資料庫的索引原理的分析還有查找判斷方案還有很多細節的東西,鑒於實際問題比較多,可以加QQ:647617935 進行交流
對於很多資料庫的索引原理的分析還有查找判斷方案還有很多細節的東西,鑒於實際問題比較多,可以加QQ:647617935 進行交流



