
前言 雖然前端開發作為 GUI 開發的一種,但是存在其特殊性,前端的特殊性就在於“動態”二字,傳統 GUI 開發,不管是桌面應用還是移動端應用都是需要預先下載的,只有先下載應用程式才會在本地操作系統運行,而前端不同,它是“動態增量”式的,我們的前端應用往往是實時載入執行的,並不需要預先下載,這就造成 ...
前言
雖然前端開發作為 GUI 開發的一種,但是存在其特殊性,前端的特殊性就在於“動態”二字,傳統 GUI 開發,不管是桌面應用還是移動端應用都是需要預先下載的,只有先下載應用程式才會在本地操作系統運行,而前端不同,它是“動態增量”式的,我們的前端應用往往是實時載入執行的,並不需要預先下載,這就造成了一個問題,前端開發中往往最影響性能的不是什麼計算或者渲染,而是載入速度,載入速度會直接影響用戶體驗和網站留存。
《Designing for Performance》的作者 Lara Swanson在2014年寫過一篇文章《Web性能即用戶體驗》,她在文中提到“網站頁面的快速載入,能夠建立用戶對網站的信任,增加回訪率,大部分的用戶其實都期待頁面能夠在2秒內載入完成,而當超過3秒以後,就會有接近40%的用戶離開你的網站”。
值得一提的是,GUI 開發依然有一個共同的特殊之處,那就是 體驗性能 ,體驗性能並不指在絕對性能上的性能優化,而是回歸用戶體驗這個根本目的,因為在 GUI 開發的領域,絕大多數情況下追求絕對意義上的性能是沒有意義的.
比如一個動畫本來就已經有 60 幀了,你通過一個弔炸天的演算法優化到了 120 幀,這對於你的 KPI 毫無用處,因為這個優化本身沒有意義,因為除了少數特異功能的異人,沒有人能分得清 60 幀和 120 幀的區別,這對於用戶的體驗沒有任何提升,相反,一個首屏載入需要 4s 的網站,你沒有任何實質意義上的性能優化,只是加了一個設計姐姐設計的 loading 圖,那這也是十分有意義的優化,因為好的 loading 可以減少用戶焦慮,讓用戶感覺沒有等太久,這就是用戶體驗級的性能優化.
因此,我們要強調即使沒有對性能有實質的優化,通過設計提高用戶體驗的這個過程,也算是性能優化,因為 GUI 開發直面用戶,你讓用戶有了性能快的 錯覺,這也叫性能優化了,畢竟用戶覺得快,才是真的快...
文章目錄
- 首屏載入優化
- 路由跳轉載入優化
1.首屏載入
首屏載入是被討論最多的話題,一方面web 前端首屏的載入性能的確普遍較差,另一方面,首屏的載入速度至關重要,很多時候過長的白屏會導致用戶還沒有體驗到網站功能的時候就流失了,首屏速度是用戶留存的關鍵點。
以用戶體驗的角度來解讀首屏的關鍵點,如果作為用戶我們從輸入網址之後的心裡過程是怎樣的呢?
當我們敲下回車後,我們第一個疑問是:
"它在運行嗎?"
這個疑問一直到用戶看到頁面第一個繪製的元素為止,這個時候用戶才能確定自己的請求是有效的(而不是被牆了...),然後第二個疑問:
"它有用嗎?"
如果只繪製出無意義的各種亂序的元素,這對於用戶是不可理解的,此時雖然頁面開始載入了,但是對於用戶沒有任何價值,直到文字內容、交互按鈕這些元素載入完畢,用戶才能理解頁面,這個時候用戶會嘗試與頁面交互,會有第三個疑問:
"它能使用了嗎?"
直到用戶成功與頁面互動,這才算是首屏載入完畢了.
在第一個疑問和第二個疑問之間的等待期,會出現白屏,這是優化的關鍵.
1.1 白屏的定義
不管是我們如何優化性能,首屏必然是會出現白屏的,因為這是前端開發這項技術的特點決定的。
那麼我們先定義一下白屏,這樣才能方便計算我們的白屏時間,因為白屏的計算邏輯說法不一,有人說要從首次繪製(First Paint,FP)算起到首次內容繪製(First Contentful Paint,FCP)這段時間算白屏,我個人是不同意的,我個人更傾向於是從路由改變起(即用戶再按下回車的瞬間)到首次內容繪製(即能看到第一個內容)為止算白屏時間,因為按照用戶的心理,在按下回車起就認為自己發起了請求,而直到看到第一個元素被繪製出來之前,用戶的心裡是焦慮的,因為他不知道這個請求會不會被響應(網站掛了?),不知道要等多久才會被響應到(網站慢?),這期間為用戶首次等待期間。
白屏時間 = firstPaint - performance.timing.navigationStart
以webapp 版的微博為例(微博為數不多的的良心產品),經過 Lighthouse(谷歌的網站測試工具)它的白屏載入時間為 2s,是非常好的成績。
1.2 白屏載入的問題分析
在現代前端應用開發中,我們往往會用 webpack 等打包器進行打包,很多情況下如果我們不進行優化,就會出現很多體積巨大的 chunk,有的甚至在 5M 左右(我第一次用 webpack1.x 打包的時候打出了 8M 的包),這些 chunk 是載入速度的殺手。
瀏覽器通常都有併發請求的限制,以 Chrome 為例,它的併發請求就為 6 個,這導致我們必須在請求完前 6 個之後,才能繼續進行後續請求,這也影響我們資源的載入速度。

當然了,網路、帶寬這是自始至終都影響載入速度的因素,白屏也不例外.
1.3 白屏的性能優化
我們先梳理下白屏時間內發生了什麼:
- 回車按下,瀏覽器解析網址,進行 DNS 查詢,查詢返回 IP,通過 IP 發出 HTTP(S) 請求
- 伺服器返回HTML,瀏覽器開始解析 HTML,此時觸發請求 js 和 css 資源
- js 被載入,開始執行 js,調用各種函數創建 DOM 並渲染到根節點,直到第一個可見元素產生
1.3.1 loading 提示
如果你用的是以 webpack 為基礎的前端框架工程體系,那麼你的index.html 文件一定是這樣的:
<div id="root"></div>我們將打包好的整個代碼都渲染到這個 root 根節點上,而我們如何渲染呢?當然是用 JavaScript 操作各種 dom 渲染,比如 react 肯定是調用各種 _React_._createElement_(),這是很耗時的,在此期間雖然 html 被載入了,但是依然是白屏,這就存在操作空間,我們能不能在 js 執行期間先加入提示,增加用戶體驗呢?
是的,我們一般有一款 webpack 插件叫html-webpack-plugin ,在其中配置 html 就可以在文件中插入 loading 圖。
webpack 配置:
const HtmlWebpackPlugin = require('html-webpack-plugin')
const loading = require('./render-loading') // 事先設計好的 loading 圖
module.exports = {
entry: './src/index.js',
output: {
path: __dirname + '/dist',
filename: 'index_bundle.js'
},
plugins: [
new HtmlWebpackPlugin({
template: './src/index.html',
loading: loading
})
]
}
1.3.2 (偽)服務端渲染
那麼既然在 HTML 載入到 js 執行期間會有時間等待,那麼為什麼不直接服務端渲染呢?直接返回的 HTML 就是帶完整 DOM 結構的,省得還得調用 js 執行各種創建 dom 的工作,不僅如此還對 SEO 友好。
正是有這種需求 vue 和 react 都支持服務端渲染,而相關的框架Nuxt.js、Next.js也大行其道,當然對於已經採用客戶端渲染的應用這個成本太高了。
於是有人想到了辦法,谷歌開源了一個庫Puppeteer,這個庫其實是一個無頭瀏覽器,通過這個無頭瀏覽器我們能用代碼模擬各種瀏覽器的操作,比如我們就可以用 node 將 html 保存為 pdf,可以在後端進行模擬點擊、提交表單等操作,自然也可以模擬瀏覽器獲取首屏的 HTML 結構。
prerender-spa-plugin就是基於以上原理的插件,此插件在本地模擬瀏覽器環境,預先執行我們的打包文件,這樣通過解析就可以獲取首屏的 HTML,在正常環境中,我們就可以返回預先解析好的 HTML 了。
1.3.3 開啟 HTTP2
我們看到在獲取 html 之後我們需要自上而下解析,在解析到 script 相關標簽的時候才能請求相關資源,而且由於瀏覽器併發限制,我們最多一次性請求 6 次,那麼有沒有辦法破解這些困境呢?
http2 是非常好的解決辦法,http2 本身的機制就足夠快:
- http2採用二進位分幀的方式進行通信,而 http1.x 是用文本,http2 的效率更高
- http2 可以進行多路復用,即跟同一個功能變數名稱通信,僅需要一個 TCP 建立請求通道,請求與響應可以同時基於此通道進行雙向通信,而 http1.x 每次請求需要建立 TCP,多次請求需要多次連接,還有併發限制,十分耗時

http2 可以頭部壓縮,能夠節省消息頭占用的網路的流量,而HTTP/1.x每次請求,都會攜帶大量冗餘頭信息,浪費了很多帶寬資源
例如:下圖中的兩個請求, 請求一發送了所有的頭部欄位,第二個請求則只需要發送差異數據,這樣可以減少冗餘數據,降低開銷
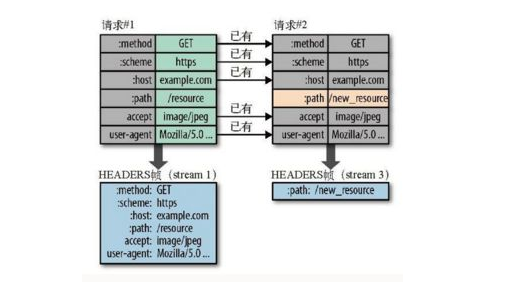
- http2可以進行服務端推送,我們平時解析 HTML 後碰到相關標簽才會進而請求 css 和 js 資源,而 http2 可以直接將相關資源直接推送,無需請求,這大大減少了多次請求的耗時
我們可以點擊此網站 進行 http2 的測試
我曾經做個一個測試,http2 在網路通暢+高性能設備下的表現沒有比 http1.1有明顯的優勢,但是網路越差,設備越差的情況下 http2 對載入的影響是質的,可以說 http2 是為移動 web 而生的,反而在光纖加持的高性能PC 上優勢不太明顯.
1.3.4 開啟瀏覽器緩存
既然 http 請求如此麻煩,能不能我們避免 http 請求或者降低 http 請求的負載來實現性能優化呢?
利用瀏覽器緩存是很好的辦法,他能最大程度上減少 http 請求,在此之前我們要先回顧一下 http 緩存的相關知識.
我們先羅列一下和緩存相關的請求響應頭。
Expires
響應頭,代表該資源的過期時間。
Cache-Control
請求/響應頭,緩存控制欄位,精確控制緩存策略。
If-Modified-Since
請求頭,資源最近修改時間,由瀏覽器告訴伺服器。
Last-Modified
響應頭,資源最近修改時間,由伺服器告訴瀏覽器。
Etag
響應頭,資源標識,由伺服器告訴瀏覽器。
If-None-Match
請求頭,緩存資源標識,由瀏覽器告訴伺服器。
配對使用的欄位:
- If-Modified-Since 和 Last-Modified
- Etag 和 If-None-Match
當無本地緩存的時候是這樣的: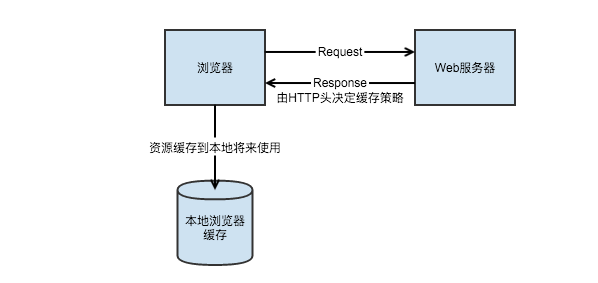
當有本地緩存但沒過期的時候是這樣的: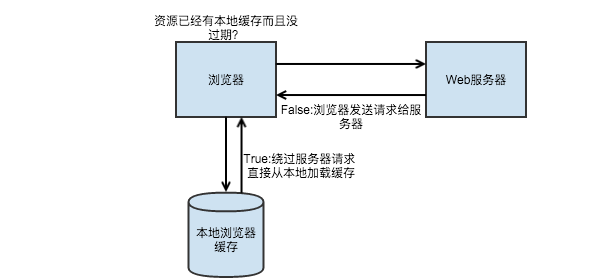
當緩存過期了會進行協商緩存: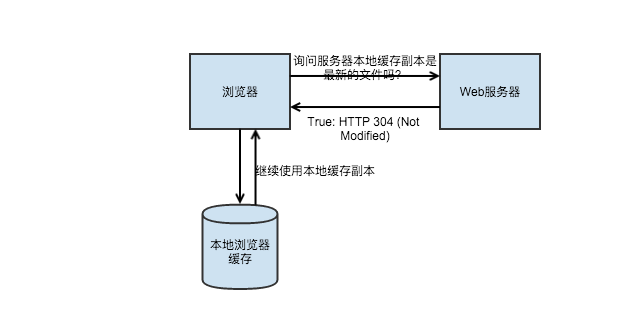
瞭解到了瀏覽器的基本緩存機制我們就好進行優化了.
通常情況下我們的 WebApp 是有我們的自身代碼和第三方庫組成的,我們自身的代碼是會常常變動的,而第三方庫除非有較大的版本升級,不然是不會變的,所以第三方庫和我們的代碼需要分開打包,我們可以給第三方庫設置一個較長的強緩存時間,這樣就不會頻繁請求第三方庫的代碼了。
那麼如何提取第三方庫呢?在 webpack4.x 中, SplitChunksPlugin 插件取代了 CommonsChunkPlugin 插件來進行公共模塊抽取,我們可以對SplitChunksPlugin 進行配置進行 拆包 操作。
SplitChunksPlugin配置示意如下:
optimization: {
splitChunks: {
chunks: "initial", // 代碼塊類型 必須三選一: "initial"(初始化) | "all"(預設就是all) | "async"(動態載入)
minSize: 0, // 最小尺寸,預設0
minChunks: 1, // 最小 chunk ,預設1
maxAsyncRequests: 1, // 最大非同步請求數, 預設1
maxInitialRequests: 1, // 最大初始化請求書,預設1
name: () => {}, // 名稱,此選項課接收 function
cacheGroups: { // 緩存組會繼承splitChunks的配置,但是test、priorty和reuseExistingChunk只能用於配置緩存組。
priority: "0", // 緩存組優先順序,即權重 false | object |
vendor: { // key 為entry中定義的 入口名稱
chunks: "initial", // 必須三選一: "initial"(初始化) | "all" | "async"(預設就是非同步)
test: /react|lodash/, // 正則規則驗證,如果符合就提取 chunk
name: "vendor", // 要緩存的 分隔出來的 chunk 名稱
minSize: 0,
minChunks: 1,
enforce: true,
reuseExistingChunk: true // 可設置是否重用已用chunk 不再創建新的chunk
}
}
}
}
SplitChunksPlugin 的配置項很多,可以先去官網瞭解如何配置,我們現在只簡單列舉了一下配置元素。
如果我們想抽取第三方庫可以這樣簡單配置
splitChunks: {
chunks: 'all', // initial、async和all
minSize: 30000, // 形成一個新代碼塊最小的體積
maxAsyncRequests: 5, // 按需載入時候最大的並行請求數
maxInitialRequests: 3, // 最大初始化請求數
automaticNameDelimiter: '~', // 打包分割符
name: true,
cacheGroups: {
vendor: {
name: "vendor",
test: /[\\/]node_modules[\\/]/, //打包第三方庫
chunks: "all",
priority: 10 // 優先順序
},
common: { // 打包其餘的的公共代碼
minChunks: 2, // 引入兩次及以上被打包
name: 'common', // 分離包的名字
chunks: 'all',
priority: 5
},
}
},
這樣似乎大功告成了?並沒有,我們的配置有很大的問題:
- 我們粗暴得將第三方庫一起打包可行嗎? 當然是有問題的,因為將第三方庫一塊打包,只要有一個庫我們升級或者引入一個新庫,這個 chunk 就會變動,那麼這個chunk 的變動性會很高,並不適合長期緩存,還有一點,我們要提高首頁載入速度,第一要務是減少首頁載入依賴的代碼量,請問像 react vue reudx 這種整個應用的基礎庫我們是首頁必須要依賴的之外,像 d3.js three.js這種特定頁面才會出現的特殊庫是沒必要在首屏載入的,所以我們需要將應用基礎庫和特定依賴的庫進行分離。
當 chunk 在強緩存期,但是伺服器代碼已經變動了我們怎麼通知客戶端?上面我們的示意圖已經看到了,當命中的資源在緩存期內,瀏覽器是直接讀取緩存而不會向伺服器確認的,如果這個時候伺服器代碼已經變動了,怎麼辦?這個時候我們不能將 index.html 緩存(反正webpack時代的 html 頁面小到沒有緩存的必要),需要每次引入 script 腳本的時候去伺服器更新,並開啟 hashchunk,它的作用是當 chunk 發生改變的時候會生成新的 hash 值,如果不變就不發生變動,這樣當 index 載入後續 script資源時如果 hashchunk 沒變就會命中緩存,如果改變了那麼會重新去服務端載入新資源。
下圖示意瞭如何將第三方庫進行拆包,基礎型的 react 等庫與工具性的 lodash 和特定庫 Echarts 進行拆分
cacheGroups: {
reactBase: {
name: 'reactBase',
test: (module) => {
return /react|redux/.test(module.context);
},
chunks: 'initial',
priority: 10,
},
utilBase: {
name: 'utilBase',
test: (module) => {
return /rxjs|lodash/.test(module.context);
},
chunks: 'initial',
priority: 9,
},
uiBase: {
name: 'chartBase',
test: (module) => {
return /echarts/.test(module.context);
},
chunks: 'initial',
priority: 8,
},
commons: {
name: 'common',
chunks: 'initial',
priority: 2,
minChunks: 2,
},
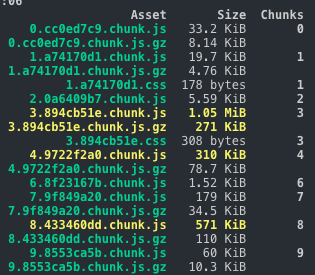
}我們對 chunk 進行 hash 化,正如下圖所示,我們變動 chunk2 相關的代碼後,其它 chunk 都沒有變化,只有 chunk2 的 hash 改變了
output: {
filename: mode === 'production' ? '[name].[chunkhash:8].js' : '[name].js',
chunkFilename: mode === 'production' ? '[id].[chunkhash:8].chunk.js' : '[id].js',
path: getPath(config.outputPath)
}
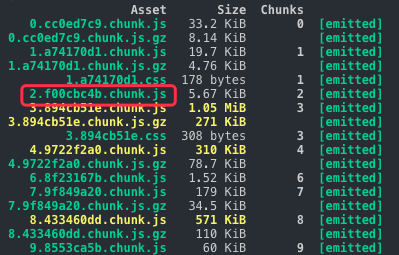
我們通過 http 緩存+webpack hash 緩存策略使得前端項目充分利用了緩存的優勢,但是 webpack 之所以需要傳說中的 webpack配置工程師 是有原因的,因為 webpack 本身是玄學,還是以上圖為例,如果你 chunk2的相關代碼去除了一個依賴或者引入了新的但是已經存在工程中依賴,會怎麼樣呢?
我們正常的期望是,只有 chunk2 發生變化了,但是事實上是大量不相干的 chunk 的 hash 發生了變動,這就導致我們緩存策略失效了,下圖是變更後的 hash,我們用紅圈圈起來的都是 hash 變動的,而事實上我們只變動了 chunk2 相關的代碼,為什麼會這樣呢?
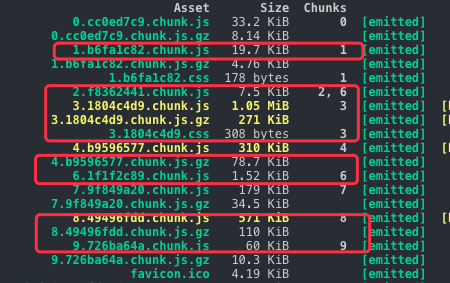
原因是 webpack 會給每個 chunk 搭上 id,這個 id 是自增的,比如 chunk 0 中的id 為 0,一旦我們引入新的依賴,chunk 的自增會被打亂,這個時候又因為 hashchunk 根據內容生成 hash,這就導致了 id 的變動致使 hashchunk 發生巨變,雖然代碼內容根本沒有變化。
這個問題我們需要額外引入一個插件HashedModuleIdsPlugin,他用非自增的方式進行 chunk id 的命名,可以解決這個問題,雖然 webpack 號稱 0 配置了,但是這個常用功能沒有內置,要等到下個版本了。
webpack hash緩存相關內容建議閱讀此文章 作為拓展
1.4 FMP(首次有意義繪製)
在白屏結束之後,頁面開始渲染,但是此時的頁面還只是出現個別無意義的元素,比如下拉菜單按鈕、或者亂序的元素、導航等等,這些元素雖然是頁面的組成部分但是沒有意義.
什麼是有意義?
對於搜索引擎用戶是完整搜索結果
對於微博用戶是時間線上的微博內容
對於淘寶用戶是商品頁面的展示
那麼在FCP 和 FMP 之間雖然開始繪製頁面,但是整個頁面是沒有意義的,用戶依然在焦慮等待,而且這個時候可能出現亂序的元素或者閃爍的元素,很影響體驗,此時我們可能需要進行用戶體驗上的一些優化。
Skeleton是一個好方法,Skeleton現在已經很開始被廣泛應用了,它的意義在於事先撐開即將渲染的元素,避免閃屏,同時提示用戶這要渲染東西了,較少用戶焦慮。
比如微博的Skeleton就做的很不錯
在不同框架上都有相應的Skeleton實現
React: antd 內置的骨架圖Skeleton方案
Vue: vue-skeleton-webpack-plugin
以 vue-cli 3 為例,我們可以直接在vue.config.js 中配置
//引入插件
const SkeletonWebpackPlugin = require('vue-skeleton-webpack-plugin');
module.exports = {
// 額外配置參考官方文檔
configureWebpack: (config)=>{
config.plugins.push(new SkeletonWebpackPlugin({
webpackConfig: {
entry: {
app: path.join(__dirname, './src/Skeleton.js'),
},
},
minimize: true,
quiet: true,
}))
},
//這個是讓骨架屏的css分離,直接作為內聯style處理到html里,提高載入速度
css: {
extract: true,
sourceMap: false,
modules: false
}
}然後就是基本的 vue 文件編寫了,直接看文檔即可。
1.5 TTI(可交互時間)
當有意義的內容渲染出來之後,用戶會嘗試與頁面交互,這個時候頁面並不是載入完畢了,而是看起來頁面載入完畢了,事實上這個時候 JavaScript 腳本依然在密集得執行.
我們看到在頁面已經基本呈現的情況下,依然有大量的腳本在執行
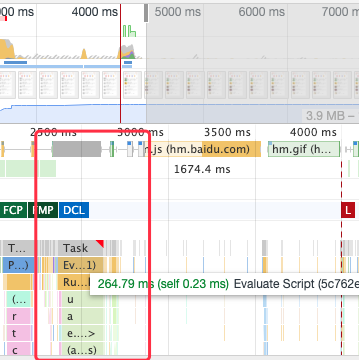
這個時候頁面並不是可交互的,直到TTI 的到來,TTI 到來之後用戶就可以跟頁面進行正常交互的,TTI 一般沒有特別精確的測量方法,普遍認為滿足FMP && DOMContentLoader事件觸發 && 頁面視覺載入85%這幾個條件後,TTI 就算是到來了。
在頁面基本呈現到可以交互這段時間,絕大部分的性能消耗都在 JavaScript 的解釋和執行上,這個時候決定 JavaScript 解析速度的無非一下兩點:
- JavaScript 腳本體積
- JavaScript 本身執行速度
JavaScript 的體積問題我們上一節交代過了一些,我們可以用SplitChunksPlugin拆庫的方法減小體積,除此之外還有一些方法,我們下文會交代。
1.5.1 Tree Shaking
Tree Shaking雖然出現很早了,比如js基礎庫的事實標準打包工具 rollup 就是Tree Shaking的祖師爺,react用 rollup 打包之後體積減少了 30%,這就是Tree Shaking的厲害之處。
Tree Shaking的作用就是,通過程式流分析找出你代碼中無用的代碼並剔除,如果不用Tree Shaking那麼很多代碼雖然定義了但是永遠都不會用到,也會進入用戶的客戶端執行,這無疑是性能的殺手,Tree Shaking依賴es6的module模塊的靜態特性,通過分析剔除無用代碼.
目前在 webpack4.x 版本之後在生產環境下已經預設支持Tree Shaking了,所以Tree Shaking可以稱得上開箱即用的技術了,但是並不代表Tree Shaking真的會起作用,因為這裡面還是有很多坑.
坑 1: Babel 轉譯,我們已經提到用Tree Shaking的時候必須用 es6 的module,如果用 common.js那種動態module,Tree Shaking就失效了,但是 Babel 預設狀態下是啟用 common.js的,所以需要我們手動關閉.
坑 2: 第三方庫不可控,我們已經知道Tree Shaking的程式分析依賴 ESM,但是市面上很多庫為了相容性依然只暴露出了ES5 版本的代碼,這導致Tree Shaking對很多第三方庫是無效的,所以我們要儘量依賴有 ESM 的庫,比如之前有一個 ESM 版的 lodash(lodash-es),我們就可以這樣引用了import { dobounce } from 'lodash-es'
1.5.2 polyfill動態載入
polyfill是為了瀏覽器相容性而生,是否需要 polyfill 應該有客戶端的瀏覽器自己決定,而不是開發者決定,但是我們在很長一段時間里都是開發者將各種 polyfill 打包,其實很多情況下導致用戶載入了根本沒有必要的代碼.
解決這個問題的方法很簡單,直接引入 <script src="https://cdn.polyfill.io/v2/polyfill.min.js"></script> 即可,而對於 Vue 開發者就更友好了,vue-cli 現在生成的模板就自帶這個引用.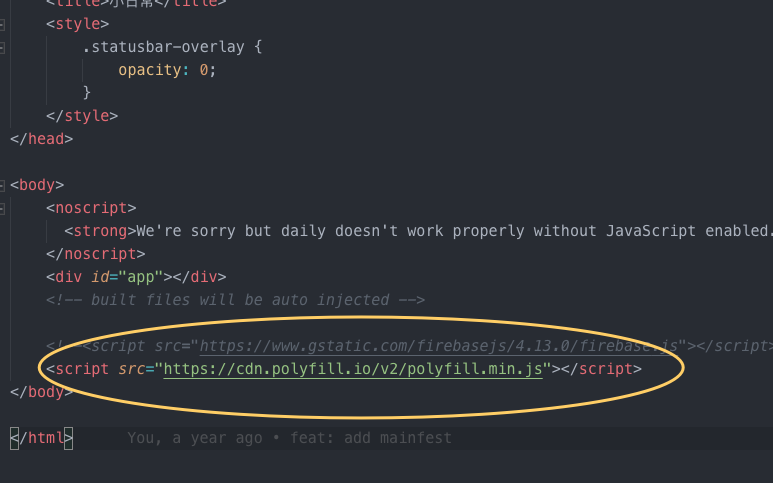
這個原理就是服務商通過識別不同瀏覽器的瀏覽器User Agent,使得伺服器能夠識別客戶使用的操作系統及版本、CPU 類型、瀏覽器及版本、瀏覽器渲染引擎、瀏覽器語言、瀏覽器插件等,然後根據這個信息判斷是否需要載入 polyfill,開發者在瀏覽器的 network 就可以查看User Agent。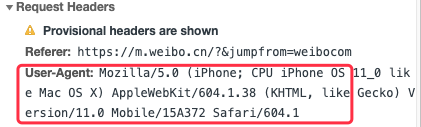
1.5.3 動態載入 ES6 代碼
既然 polyfill 能動態載入,那麼 es5 和 es6+的代碼能不能動態載入呢?是的,但是這樣有什麼意義呢?es6 會更快嗎?
我們得首先明確一點,一般情況下在新標準發佈後,瀏覽器廠商會著重優化新標準的性能,而老的標準的性能優化會逐漸停滯,即使面向未來編程,es6 的性能也會往越來越快的方向發展.
其次,我們平時編寫的代碼可都es6+,而發佈的es5是經過babel 或者 ts 轉譯的,在大多數情況下,經過工具轉譯的代碼往往被比不上手寫代碼的性能,這個性能對比網站 的顯示也是如此,雖然 babel 等轉譯工具都在進步,但是仍然會看到轉譯後代碼的性能下降,尤其是對 class 代碼的轉譯,其性能下降是很明顯的.
最後,轉譯後的代碼體積會出現代碼膨脹的情況,轉譯器用了很多奇技淫巧將 es6 轉為 es5 導致了代碼量劇增,使用 es6就代表了更小的體積.
那麼如何動態載入 es6 代碼呢?秘訣就是<script type="module">這個標簽來判斷瀏覽器是否支持 es6,我之前在掘金上看到了一篇翻譯的文章 有詳細的動態打包過程,可以拓展閱讀.
體積大小對比
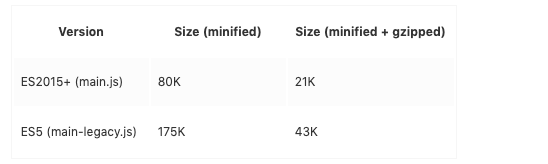
執行時間對比

雙方對比的結果是,es6 的代碼體積在小了一倍的同時,性能高出一倍.
1.5.4 路由級別拆解代碼
我們在上文中已經通過SplitChunksPlugin將第三方庫進行了抽離,但是在首屏載入過程中依然有很多冗餘代碼,比如我們的首頁是個登錄界面,那麼其實用到的代碼很簡單
- 框架的基礎庫例如 vue redux 等等
- ui 框架的部分 form 組件和按鈕組件等等
- 一個簡單的佈局組件
- 其它少量邏輯和樣式
登錄界面的代碼是很少的,為什麼不只載入登錄界面的代碼呢?
這就需要我們進行對代碼在路由級別的拆分,除了基礎的框架和 UI 庫之外,我們只需要載入當前頁面的代碼即可,這就有得用到Code Splitting技術進行代碼分割,我們要做的其實很簡單.
我們得先給 babel 設置plugin-syntax-dynamic-import這個動態import 的插件,然後就可以就函數體內使用 import 了.
對於Vue 你可以這樣引入路由
export default new Router({
routes: [
{
path: '/',
name: 'Home',
component: Home
},
{
path: '/login',
name: 'login',
component: () => import('@components/login')
}
]你的登錄頁面會被單獨打包.
對於react,其內置的 React.lazy() 就可以動態載入路由和組件,效果與 vue 大同小異,當然 lazy() 目前還沒有支持服務端渲染,如果想在服務端渲染使用,可以用React Loadable.
2 組件載入
路由其實是一個大組件,很多時候人們忽略了路由跳轉之間的載入優化,更多的時候我們的精力都留在首屏載入之上,但是路由跳轉間的載入同樣重要,如果載入過慢同樣影響用戶體驗。
我們不可忽視的是在很多時候,首屏的載入反而比路由跳轉要快,也更容易優化。
比如石墨文檔的首頁是這樣的:
一個非常常見的官網首頁,代碼量也不會太多,處理好第三方資源的載入後,是很容易就達到性能要求的頁面類型.
載入過程不過幾秒鐘,而當我跳轉到真正的工作界面時,這是個類似 word 的線上編輯器
我用 Lighthouse 的測試結果是,可交互時間高達17.2s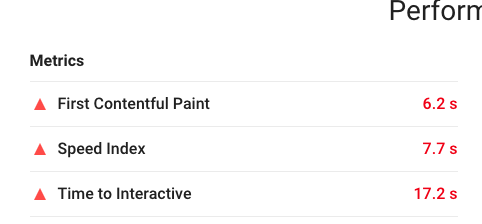
這並不是石墨做得不夠好,而是對於這種應用型網站,相比於首屏,工作頁面的跳轉載入優化難度更大,因為其工作頁面的代碼量遠遠大於一個官網的代碼量和複雜度.
我們看到在載入過程中有超過 6000ms 再進行 JavaScript 的解析和執行
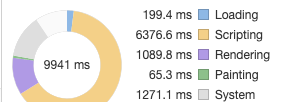
2.1 組件懶載入
Code Splitting不僅可以進行路由分割,甚至可以進行組件級別的代碼分割,當然是用方式也是大同小異,組件的級別的分割帶來的好處是我們可以在頁面的載入中只渲染部分必須的組件,而其餘的組件可以按需載入.
就比如一個Dropdown(下拉組件),我們在渲染初始頁面的時候下拉的Menu(菜單組件)是沒必要渲染的,因為只有點擊了Dropdown之後Menu 才有必要渲染出來.
路由分割 vs 組件分割
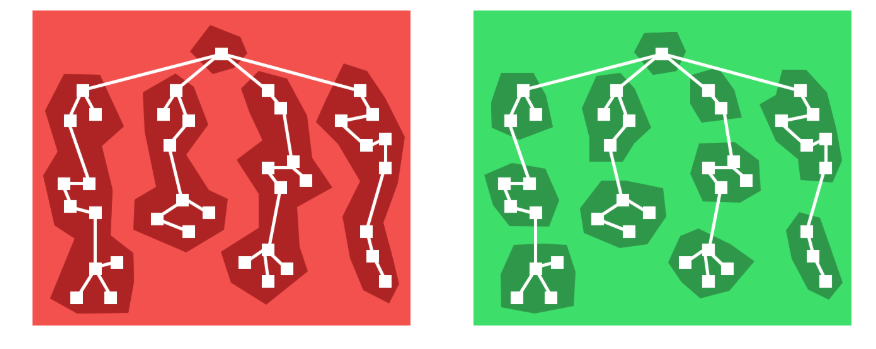
我們可以以一個demo 為例來分析一下組件級別分割的方法與技巧.
我們假設一個場景,比如我們在做一個打卡應用,有一個需求是我們點擊下拉菜單選擇相關的習慣,查看近一周的打卡情況.
我們的 demo 是這樣子:
我們先對比一下有組件分割和無組件分割的資源載入情況(開發環境下無壓縮)
無組件分割,我們看到有一個非常大的chunk,因為這個組件除了我們的代碼外,還包含了 antd 組件和 Echarts 圖表以及 React 框架部分代碼
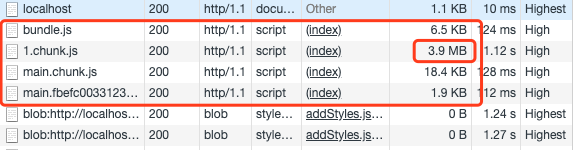
組件分割後,初始頁面體積下降明顯,路由間跳轉的初始頁面載入體積變小意味著更快的載入速度

其實組件分割的方法跟路由分割差不多,也是通過 lazy + Suspense 的方法進行組件懶載入
// 動態載入圖表組件
const Chart = lazy(() => import(/* webpackChunkName: 'chart' */'./charts'))
// 包含著圖表的 modal 組件
const ModalEchart = (props) => (
<Modal
title="Basic Modal"
visible={props.visible}
onOk={props.handleOk}
onCancel={props.handleCancel}
>
<Chart />
</Modal>
)2.2 組件預載入
我們通過組件懶載入將頁面的初始渲染的資源體積降低了下來,提高了載入性能,但是組件的性能又出現了問題,還是上一個 demo,我們把初始頁面的 3.9m 的體積減少到了1.7m,頁面的載入是迅速了,但是組件的載入卻變慢了.
原因是其餘的 2m 資源的壓力全部壓在了圖表組件上(Echarts 的體積緣故),因此當我們點擊菜單載入圖表的時候會出現 1-2s 的 loading 延遲,如下:

我們能不能提前把圖表載入進來,避免圖表渲染中載入時間過長的問題?這種提前載入的方法就是組件的預載入.
原理也很簡單,就是在用戶的滑鼠還處於 hover 狀態的時候就開始觸發圖表資源的載入,通常情況下當用戶點擊結束之後,載入也基本完成,這個時候圖表會很順利地渲染出來,不會出現延遲.
/**
* @param {*} factory 懶載入的組件
* @param {*} next factory組件下麵需要預載入的組件
*/
function lazyWithPreload(factory, next) {
const Component = lazy(factory);
Component.preload = next;
return Component;
}
...
// 然後在組件的方法中觸發預載入
const preloadChart = () => {
Modal.preload()
}
2.3 keep-alive
對於使用 vue 的開發者 keep-alive 這個 API 應該是最熟悉不過了,keep-alive 的作用是在頁面已經跳轉後依然不銷毀組件,保存組件對應的實例在記憶體中,當此頁面再次需要渲染的時候就可以利用已經緩存的組件實例了。
如果大量實例不銷毀保存在記憶體中,那麼這個 API 存在記憶體泄漏的風險,所以要註意調用deactivated銷毀
但是在 React 中並沒有對應的實現,而官方 issue 中官方也明確不會添加類似的 API,但是給出了兩個自行實現的方法
- 利用全局狀態管理工具例如 redux 進行狀態緩存
- 利用
style={{display: 'none'}}進行控制
如果你看了這兩個建議就知道不靠譜,redux 已經足夠啰嗦了,我們為了緩存狀態而利用 redux 這種全局方案,其額外的工作量和複雜度提升是得不償失的,用 dispaly 控制顯示是個很簡單的方法,但是也足夠粗暴,我們會損失很多可操作的空間,比如動畫。
react-keep-alive 在一定程度上解決這個問題,它的原理是利用React 的 Portals API 將緩存組件掛載到根節點以外的 dom 上,在需要恢復的時候再將緩存組件掛在到相應節點上,同時也可以在額外的生命周期 componentWillUnactivate 進行銷毀處理。
小結
當然還有很多常見的性能優化方案我們沒有提及:
- 圖片懶載入方案,這是史前前端就開始用的技術,在 JQuery 或者各種框架都有成熟方案
- 資源壓縮,現在基本上用反向代理工具都是自動開啟的
- cdn,已經見不到幾個web 產品不用 cdn 了,尤其是雲計算廠商崛起後 cdn 很便宜了
- 功能變數名稱收斂或者功能變數名稱發散,這種情況在 http2 使用之後意義有限,因為一個功能變數名稱可以直接建立雙向通道多路復用了
- 雪碧圖,很古老的技術了,http2 使用後也是效果有限了
- css 放頭,js 放最後,這種方式適合工程化之前,現在基本都用打包工具代替了
- 其它...
我們著重整理了前端載入階段的性能優化方案,很多時候只是給出了方向,真正要進行優化還是需要在實際項目中根據具體情況進行分析挖掘才能將性能優化做到最好.
參考鏈接:
公眾號
想要實時關註筆者最新的文章和最新的文檔更新請關註公眾號程式員面試官,後續的文章會優先在公眾號更新.
簡歷模板: 關註公眾號回覆「模板」獲取
《前端面試手冊》: 配套於本指南的突擊手冊,關註公眾號回覆「fed」獲取

本文由博客一文多發平臺 OpenWrite 發佈!


